当前位置:网站首页>Onnxoptimizer, onnxsim usage records
Onnxoptimizer, onnxsim usage records
2022-06-23 05:19:00 【Ten thousand miles' journey to】
onnxoptimizer、onnxsim Known as the onnx Optimization tool of , among onnxsim Constants can be optimized ,onnxoptimizer Nodes can be compressed . To this end, the resnet18 For example , test onnxoptimizer、onnxsim For the optimization effect of the model .onnxoptimizer、onnxsim The installation code for is as follows :
pip install onnxoptimizer
pip install onnxsim
1、resnet18 Structure
resnet18 The structure of is as follows , It can be seen as multiple CBR Component composition
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)2、 establish onnx Model
import torch
from torchvision import models
model = models.resnet18()
dummy_input=torch.ones((1,3,256,256))
input_names=['input']
output_names=['output']
ONNX_name="resnet18.onnx"
torch.onnx.export(model.eval(), dummy_input, ONNX_name, verbose=True, input_names=input_names,opset_version=16,
dynamic_axes={'input': {0: 'batch',1:'width',2:'height'}, },
output_names=output_names)#,example_outputs=example_outputsAt this time, the model structure is as follows , The following figure is only partial . Please run the code by yourself , And upload the model to Netron The website is visualized . In the picture Identity Node is BN operation .

2、onnxoptimizer Optimize
import onnx
import onnxoptimizer
model = onnx.load(ONNX_name)
new_model = onnxoptimizer.optimize(model)
onnx.save(new_model,"resnet18_optimize.onnx")
# use model_simp as a standard ONNX model objectresnet18_optimize.onnx The structure of is as follows , Intuitively feel and resnet18.onnx It doesn't make any difference . And the memory size of the two models is the same , in other words onnxoptimizer No optimization BN operation .

3、onnxsim Optimize
import onnx
from onnxsim import simplify
onnx_model = onnx.load(ONNX_name) # load onnx model
model_simp, check = simplify(onnx_model)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, "resnet18_simplify.onnx")resnet18_simplify.onnx The structure of is as follows , Intuitively feel and resnet18.onnx There's a difference ,BN Operations are incorporated into the model .

4、 Run time vs. video memory usage
import onnxruntime
import numpy as np
import time
import pynvml
import ctypes
import os
#os.environ['Path']+=r'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin'
#python3.7 Versions above use the following code to add dependencies dll The path of
os.add_dll_directory(r'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin')
lib = ctypes.cdll.LoadLibrary(os.getcwd()+ "/dll_export.dll")
#win32api.FreeLibrary(libc._handle) # It is found that the program cannot exit normally at the end of running dll, You need to explicitly release dll
lib.reset_cuda()
pynvml.nvmlInit()
def get_cuda_msg(tag=""):
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(tag, ", used:",meminfo.used / 1024**2,"Mib","free:",meminfo.free / 1024**2,"Mib")
onnx_path=["resnet18.onnx","resnet18_optimize.onnx","resnet18_simplify.onnx"]
for ONNX_name in onnx_path:
#session = onnxruntime.InferenceSession("traced_sp_model.onnx")
get_cuda_msg("\nStart run")
session = onnxruntime.InferenceSession(ONNX_name, providers=[ 'CUDAExecutionProvider'])#'TensorrtExecutionProvider', 'CPUExecutionProvider'
#print("Input node name:");[print(x.name) for x in session.get_inputs()]
#print("Output node name:");[print(x.name) for x in session.get_outputs()]
# Note the value type and shape, This should be related to torch It's the same
data={
"input":np.ones((1,3,256,256),dtype=np.float32)
}
st=time.time()
for i in range(100):
outputs = session.run(None,data)
print(ONNX_name,outputs[0].shape,(time.time()-st)/100)
get_cuda_msg("End run")
# You need to delete objects that occupy video memory , Can be cleared cuda cache . If it is pytorch You need to del model
del session
lib.reset_cuda()
The comparison results are as follows , There's basically no difference . After optimization , It's a little faster , but cuda There is no significant advantage in occupation
Start run , used: 11289.984375 Mib free: 998.015625 Mib resnet18.onnx (1, 1000) 0.03594543933868408 End run , used: 12257.984375 Mib free: 30.015625 Mib Start run , used: 11289.984375 Mib free: 998.015625 Mib resnet18_optimize.onnx (1, 1000) 0.024863476753234862 End run , used: 12183.984375 Mib free: 104.015625 Mib Start run , used: 11289.984375 Mib free: 998.015625 Mib resnet18_simplify.onnx (1, 1000) 0.026698846817016602 End run , used: 12239.984375 Mib free: 48.015625 Mib
边栏推荐
- A compiler related bug in rtklib2.4.3 B34
- 树莓派网络远程访问
- 【微服务|Nacos】Nacos实现多环境和多租户的数据隔离
- MVC三层架构
- Hard core, become a high-quality tester: learn to communicate with products
- HCIP 交换机实验
- Missing essential plugin
- In unity, how to read and write a scriptableobject object in editor and runtime
- BGP第二次试验
- Event日志关键字:EventLogTags.logtags
猜你喜欢

PRCS-1016 : Failed to resolve Single Client Access Name

代码片段管理器SnippetsLab
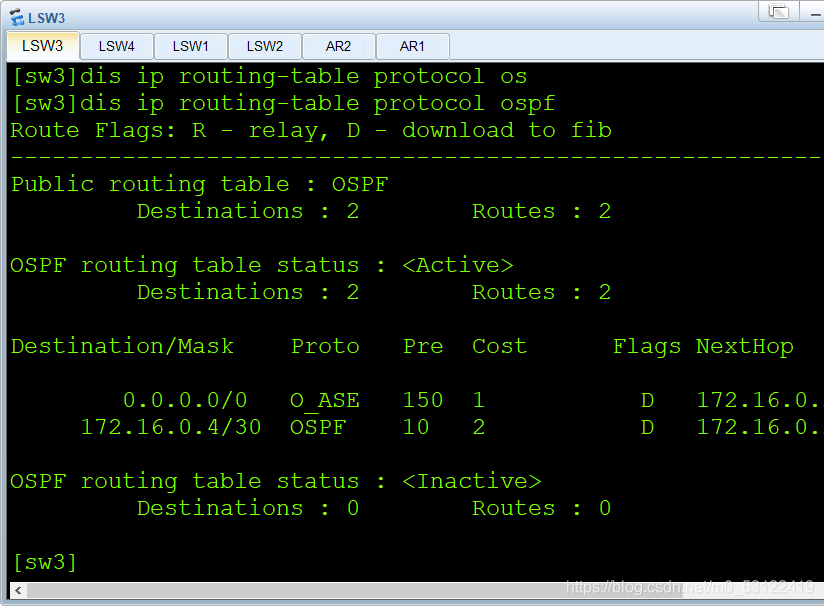
三层架构实验

(IntelliJ) plug in background image plus
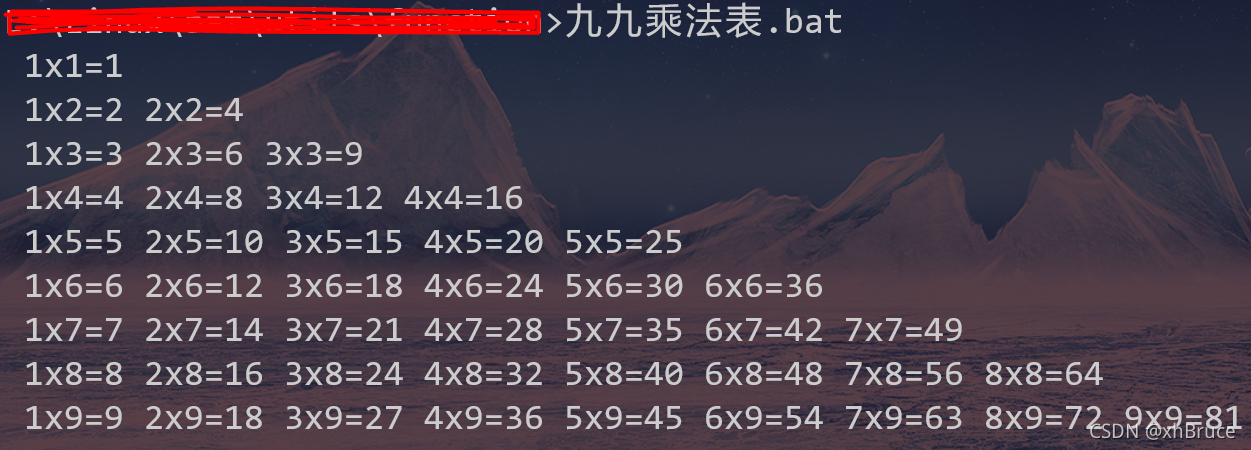
九九乘法表.bat
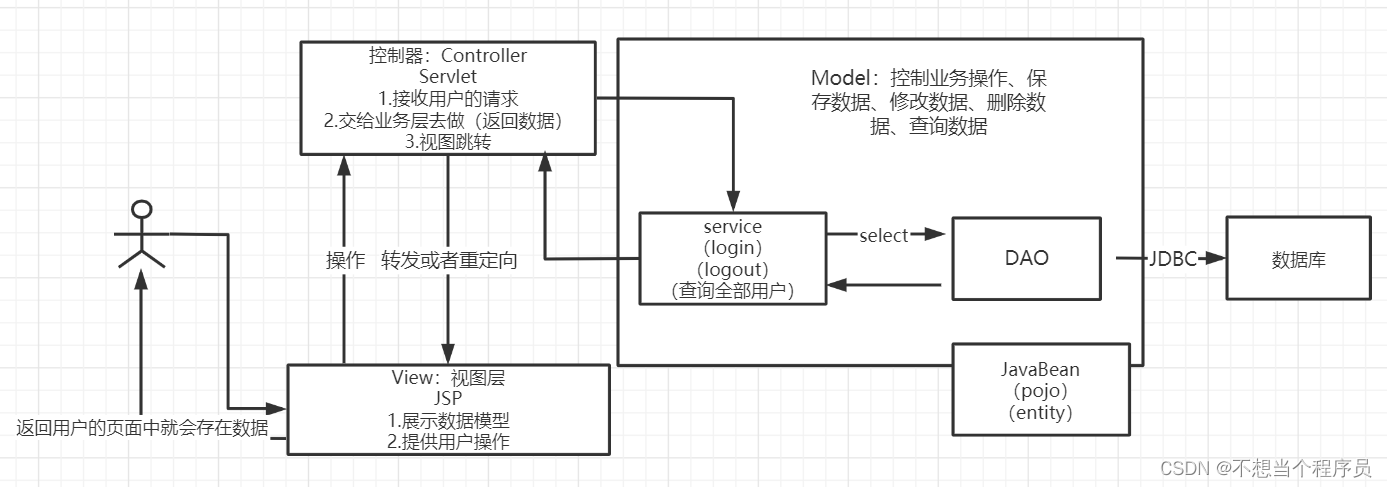
Architecture à trois niveaux MVC

Master shell, one article is enough!

如何进行探索性数据分析

Visual display of TEQC quality analysis results using teqcplot
(IntelliJ)插件一 Background Image Plus
随机推荐
The technological advance of new employees? Journey
618 how to break through the siege? Haier Zhijia: do a good job in digitalization of users
单行或多行文本溢出,省略号代替
飞桨框架v2.3发布高可复用算子库PHI!重构开发范式,降本增效
PHP move_ uploaded_ File failed to upload mobile pictures
Post processing of multisensor data fusion using Px4 ECL
Event log keyword: eventlogtags logtags
强推,软件测试快速入门,一看就会
gis利器之Gdal(三)gdb数据读取
8 years' experience: monthly salary of 3000 to 30000, the change of Test Engineer
MySQl基础
Ams:startactivity desktop launch application
Swiftui 2.0 course notes Chapter 5
1010 Radix
硬核,成为高素质测试人员:学会和产品沟通需求
Zygote进程
Event日志关键字:EventLogTags.logtags
【opencv450】帧间差分法
【微服务|Nacos】Nacos版本相关问题一览
树莓派网络远程访问