当前位置:网站首页>干货!神经网络中的隐性稀疏正则效应
干货!神经网络中的隐性稀疏正则效应
2022-07-23 18:23:00 【AITIME论道】
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

本文研究了梯度下降算法在过度参数化下的隐式稀疏正则效应。我们研究了一类特殊的神经网络,也就是对角线性神经网络。我们将之前在网络深度为2的理论结果拓展到了一般的深度为N的网络, 并且进一步说明了深度对于隐式稀疏正则效应的影响。我们发现更大的深度,可以允许更大的初始化值和更大的早停时间窗口,在真实模型是稀疏的情况,更深的模型反而更容易找到一个可以泛化的模型。我们希望本工作可以加深对于梯度下降算法在训练深度神经网络时的隐式正则效应的理解。
首先,我们将介绍一下为何要关注这个问题。众所周知,深度神经网络在很多问题的处理上都有着优秀的表现,然而对于DNN这样模型的泛化性质却一直没有很深入的研究。难点主要集中在两个方面,一方面是模型高度相似化,复杂度很高则会导致其所代表的行数空间复杂度也会很高;另一方面,经验风险最小化的优化问题往往是一个复杂的非凸问题。所以我们得到理论上的泛化性质保证是很难的。
但是,实际中我们已经观察到了这些高度参数化的DNN模型泛化能力是非常好的,只是训练起来很麻烦。我们需要设计一个很巧妙的、且和我们任务高度契合的架构。这些训练中的小技巧也是在帮助我们从这个非凸问题的很多解之中选择泛化能力较好的那个解,也就是说模型的机构和训练方法一起提供了一个隐性正则效应。对于这种效应,也存在着许多种解读。
本期AI TIME PhD直播间,我们邀请到美国德州农工大学统计系博士生—李江元,为我们带来报告分享《神经网络中的隐性稀疏正则效应》。

李江元:
美国德州农工大学统计系四年级博士生,导师是Raymond Wong。在此之前,他于2018年在德州农工大学获得应用数学硕士学位,导师为Simon Foucart,2017年在北京航空航天大学华罗庚班获得数学学士学位。他的研究方向是压缩感知,矩阵补全,非凸优化以及统计机器学习理论。相关工作发表于Acta Applicandae Mathematicae, ICASSP, NeurIPS等。
Incremental Learning
● 一种是说这些训练方法倾向于光滑的解, 这方面的代表工作有关于double descent curve和representation cost的一些文章。
● 一种可能的解释是“增量学习”incremental learning——基于梯度的方法学到的东西也是从简单到复杂的。就比如说矩阵的话,大的奇异值会被首先学习出来,对于向量而言呢,绝对值大的地方也会被首先学习到。这样的话,如果应用早停法,我们就可以轻松得到一个低秩或者稀疏的解。
我们研究的最终目标是理解深度神经网络的泛化能力,但是目前对于复杂的网络很难有一个统一的模型去研究。因此,我们选择从简单的模型出发,去理解其中存在的隐性正则效应,如线性模型、矩阵分解和张量分析。在本研究中,我们选择从稀疏线性模型的角度来理解人工神经网络的隐性正则效应。
Setup
我们的设定也是一个标准的线性模型设定,真实模型也是一个稀疏模型w*。我们想要获取对于w*的学习和恢复。

一般的思路是有一个显式的正则项,无论是从0范数还是1范数去构建一个显性正则项,以获得一个稀疏的求解。但是在本研究之中,我们选择去研究这个隐性正则项,直接进行求解,而不用任何显式正则的方法。
我们首先做的不是对w进行求解,而是把w写成一个如下形式:

u和v是我们的两个参数,也是两个向量。该表达也等价于权重共享的对角线性网络。
目标函数Unpenalized squared loss如下式:

初始化:u0 = v0 = α1
Implicit Sparse Regularization
首先,我们能否得到一个隐性稀疏的正则效应呢?在深度为2的情境下,梯度下降可以得到稀疏信号求解的——当N = 2时,梯度下降提前停止恢复稀疏信号。我们要做的就在前人研究的基础上将结果拓展到一般深度N上。
Theorem
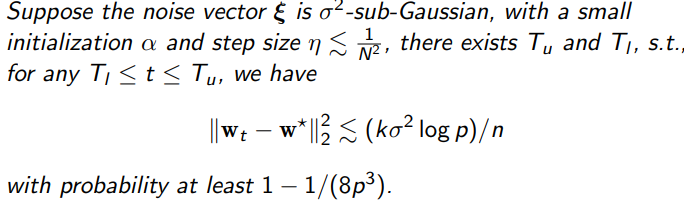
我们证明了存在一个迭代次数的上界和下界,对于任何满足条件的迭代次数都会有最优恢复的信号效果。
The Efficacy of Different Depth-N
我们之后在MNIST上验证了一下上述方法的可行性,得到了如下图的图像,可以看到对于不同深度都可以获得一个不同程度的图像恢复。

为了了解是如何实现的这一效果,我们进行了以下探究。
Gradient Dynamics梯度动力学
关于公平的综合性,我们学习到的表示应该符合以下特性:不应该暴露用户的敏感

The Impact of Depth and Early-Stopping 深度和早停法的影响
在将深度为2的神经网络上的隐性正则效应推广到一般的深度为N的神经网络上之后,我们也想要进一步去研究深度和初始化对于隐性正则效应的影响。基于我们的定理,我们获得了以下三个推论。
Decreasing Initialization Enlarges Early-Stopping Window
首先是,对于初始化的尺度发生变化,如果初始化尺度减小,之前所提到的早停法的上界和下界的差值是增大的。这样的结论对于深度为2的网络是已经存在的,基于我们的定理,我们把它推广到了一般的深度为N的网络。
Increasing Depth Enlarges the Early-Stopping Window
其次,我们也证明了对于同样的初始化和步长,早停法的上下界之间的差是随着深度的增加而增加的。其基本的想法是基于迭代中额外的项能加速信号支集上的收敛速度,以及减缓支集外的误差累计速度。

上图是对于真实信号大小为1时,每一坐标的解随着训练次数的展示。

上图是信号恢复的误差大小随训练次数的展示。从这两张图可以看出:在确定所有N的初始化α和步长η值时,早期停止窗口大小随深度N的增加而增大。
Increasing Depth Allows Larger Initialization

我们证明了的最后一个推论是关于深度和初始化之间的关系。做初始化的时候,我们都需要在0附近找一个较小的值。而随着深度的增加,对于初始化的大小会更加宽松,即获得更大的初始化,这也意味着更快的收敛。
Empirically Observed Phenomena
与此同时,我们也有一些观察到但没有在论文中证明的现象,主要集中在以下两个方面。

首先,关于增量学习。
● 精确的增量学习仍然有效。
● 理论上的论证依赖于对噪声(误差)更仔细的描述。

● 大的初始化意味着隐含的2-范数正则化(核机制)。
我们发现如果我们增大初始化,会看到对于不同深度也可以获得一个类似于隐性2-范数的正则化,只是没有证明。之前的证明都是基于没有噪音和深度为2的条件,深度为N和有噪音的情形还需要一种不同的框架来证明这样的结果。
Conclusions
● 我们重点研究的是梯度下降算法的隐性稀疏正则效应,即初始化较小的类型。我们将已有的隐性稀疏正则效应从深度为2的对角线性网络推广到一般的深度为N的对角线性网络。
● 我们证明了早停窗口大小可以随着深度- n的增加而增加,而且增加的深度允许更大的初始化尺度。
● 我们希望此工作能够提供对隐式稀疏正则化的更多理解。
提
醒
论文题目:
Implicit Sparse Regularization: The Impact of Depth and Early Stopping
论文链接:
https://proceedings.neurips.cc/paper/2021/file/ee188463935a061dee6df8bf449cb882-Paper.pdf
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:李江元
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾300场活动,超260万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
边栏推荐
- R language ggplot2 visualization: use ggplot2 to visualize the scatter diagram, and use the theme of ggpubr package_ The classic2 function sets the visual image to classic theme with axis lines
- R language filters the data columns specified in dataframe, and R language excludes (deletes) the specified data columns (variables) in dataframe
- R language uses the gather function of tidyr package to convert a wide table to a long table (wide table to long table), the first parameter specifies the name of the new data column generated from th
- 入门数据库days1
- 三维点云课程(七)——特征点描述
- Leetcode - the nearest sum of three numbers
- Element positioning in selenium is correct, but the operation fails. Six solutions are all finalized
- Calculation of structure size (structure memory alignment)
- Search 2D matrix
- Summary of smart data corresponding to some topics
猜你喜欢

PC performance monitoring tool is an indispensable helper for software testers

Publish the local image to Alibaba cloud warehouse

【开发经验】开发项目踩坑集合【持续更新】

入门数据库days1

为啥一问 JVM 就 懵B ?
三维点云课程(六)——三维目标检测

MySQL master-slave replication

Redux summation case explanation version tutorial

Basic process of process scheduling
![Atcoder regular contest 144 [VP record]](/img/8c/bcffb95cb709087103bb79b8a358d1.png)
Atcoder regular contest 144 [VP record]
随机推荐
能量原理与变分法笔记16:虚位移原理的求解
[hero planet July training leetcode problem solving daily] 23rd dictionary tree
MySQL 啥时候用表锁,啥时候用行锁?
入门数据库Days3
项目实战第九讲--运营导入导出工具
能量原理与变分法笔记15:微元法的求解
Exch:POP3 和 IMAP4 操作指南
PowerCLi 添加esxi主机到vCenter
Monotonic queue optimization DP
能量原理与变分法笔记14:总结+问题的求解
安全停止nodeos
搭建自己的目标检测环境,模型配置,数据配置 MMdetection
R language uses dwilcox function to generate Wilcoxon rank sum statistical distribution density function data, and uses plot function to visualize Wilcoxon rank sum statistical distribution density fu
BoundsChecker用法「建议收藏」
Codeforces round 809 (Div. 2) [VP record]
Powercli management VMware vCenter one click batch deployment OVA
PowerCLi 管理VMware vCenter 一键批量部署OVF
R语言使用dwilcox函数生成Wilcoxon秩和统计分布密度函数数据、使用plot函数可视化Wilcoxon秩和统计分布密度函数数据
Usage of formatdatetime
R language mapping: coordinate axis setting