当前位置:网站首页>Crawler scheduling framework of scratch+scratch+grammar
Crawler scheduling framework of scratch+scratch+grammar
2022-06-25 11:07:00 【AJ~】
List of articles
One 、scrapy
1.1 summary
Scrapy,Python A fast development 、 High level screen grabs and web Grabbing framework , Used to grab web Site and extract structured data from the page .Scrapy A wide range of uses , Can be used for data mining 、 Monitoring and automated testing .
It was originally for page crawling ( More specifically , Network capture ) Designed by , The background application is also used to obtain API Data returned ( for example Amazon Associates Web Services ) Or general purpose web crawlers .
Scrapy The attraction is that it's a framework , Anyone can modify it conveniently according to their needs . It also provides a base class for many types of reptiles , Such as BaseSpider、sitemap Reptiles, etc , The latest version offers web2.0 Reptile support .
1.2 constitute
Scrapy The frame is mainly composed of five components , They are the scheduler (Scheduler)、 Downloader (Downloader)、 Reptiles (Spider) And physical pipes (Item Pipeline)、Scrapy engine (Scrapy Engine). Let's introduce the functions of each component .
(1)、 Scheduler (Scheduler):
Scheduler , To put it bluntly, assume it's a URL( Grab the web address or link ) Priority queue for , It decides that the next URL to grab is what , Remove duplicate URLs at the same time ( Don't do useless work ). Users can customize the scheduler according to their own requirements .
(2)、 Downloader (Downloader):
Downloader , It's the most burdensome of all the components , It's used to download resources on the Internet at high speed .Scrapy The downloader code is not too complicated , But it's efficient , The main reason is Scrapy The Downloader is built on twisted On this efficient asynchronous model ( In fact, the whole framework is based on this model ).
(3)、 Reptiles (Spider):
Reptiles , Is the most concerned part of the user . Users customize their own crawler ( By customizing syntax such as regular expressions ), Used to extract the information you need from a specific web page , The so-called entity (Item). Users can also extract links from it , Give Way Scrapy Continue to grab next page .
(4)、 Physical pipeline (Item Pipeline):
Physical pipeline , Used to deal with reptiles (spider) Extracted entities . The main function is to persist entities 、 Verify the validity of the entity 、 Clear unwanted information .
(5)、Scrapy engine (Scrapy Engine):
Scrapy The engine is at the heart of the whole framework . It's used to control the debugger 、 Downloader 、 Reptiles . actually , The engine is the equivalent of a computer CPU, It controls the whole process .
1.3 Installation and use
install
pip install scrapy( or pip3 install scrapy)
Use
Create a new project :scrapy startproject Project name
Create a new crawler :scrapy genspider Reptile name domain name
Start the crawler : scrapy crawl Reptile name
Two 、scrapyd
2.1 brief introduction
scrapyd Is one for deployment and operation scrapy Crawler program , It allows you to go through JSON API To deploy the crawler project and control the running of the crawler ,scrapyd Is a Daemons , Monitor the running and requests of the crawler , Then start the process to execute them
2.2 Installation and use
install
pip install scrapyd( or pip3 install scrapyd)
pip install scrapyd-client( or pip3 install scrapyd-client)
File configuration
vim /usr/local/python3/lib/python3.7/site-packages/scrapyd/default_scrapyd.conf

start-up
scrapyd

visit ip:6800, When this page appears, the startup succeeds 
3、 ... and 、gerapy
3.1 brief introduction
Gerapy Is a distributed crawler management framework , Support Python 3, be based on Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js Development ,Gerapy Can help us :
- Easily control the operation of the crawler
- Visually view crawler status
- View crawling results in real time
- Simply implement project deployment
- Unified host management
- Easily write crawler code
3.2 Install and use
install
pip install gerapy( or pip3 install gerapy)

Set up a soft link after installation
ln -s /usr/local/python3/bin/gerapy /usr/bin/gerapy
initialization
gerapy init

Initialize database
cd gerapy
gerapy migrate
Report errors sqllite Version is too low 
terms of settlement : upgrade sqllite
download
wget https://www.sqlite.org/2019/sqlite-autoconf-3300000.tar.gz --no-check-certificate
tar -zxvf sqlite-autoconf-3300000.tar.gz
install
mkdir /opt/sqlite
cd sqlite-autoconf-3300000
./configure --prefix=/opt/sqlite
make && make install
Establish a soft connection
mv /usr/bin/sqlite3 /usr/bin/sqlite3_old
ln -s /opt/sqlite/bin/sqlite3 /usr/bin/sqlite3
echo “/usr/local/lib” > /etc/ld.so.conf.d/sqlite3.conf
ldconfig
vim ~/.bashrc add to export LD_LIBRARY_PATH=“/usr/local/lib”
source ~/.bashrc
View the current sqlite3 Version of
sqlite3 --version

Reinitialize gerapy database

Configure account secret
gerapy createsuperuser
start-up gerapy
gerapy runserver
gerapy runserver 0.0.0.0:9000 # External access 9000 Port boot

Because it is not started scrapy The host here is not 0

start-up scrapyd after , To configure scrapyd The host information 
After the configuration is successful, it will be added to the host list 
Four 、scrapy+scrapyd+gerapy Combined use of
4.1 establish scrapy project
Enter gerapy Project directory
cd ~/gerapy/projects/
And then create a new one scrapy project
scrapy startproject gerapy_test
scrapy genspider baidu_test www.baidu.com
modify scrapy.cfg as follows

In the use of scrapyd-deploy Upload to scrapyd, First establish a soft connection and then upload
ln -s /usr/local/python3/bin/scrapyd-deploy /usr/bin/scrapyd-deploy
scrapyd-deploy app -p gerapy_test

4.2 Deployment packaging scrapy project
And then again gerapy You can see our new project on the page , Pack it again




It needs to be modified before operation scrapy Code 

Run the code after modification 
4.3 function
The successful running , This deployment is ok 了 !

5、 ... and 、 Filling pit
5.1 function scrapy Reptile error

terms of settlement : modify lzma The source code is as follows
try:
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
except ImportError:
from backports.lzma import *
from backports.lzma import _encode_filter_properties, _decode_filter_properties

5.2 scrapyd function scrapy Report errors
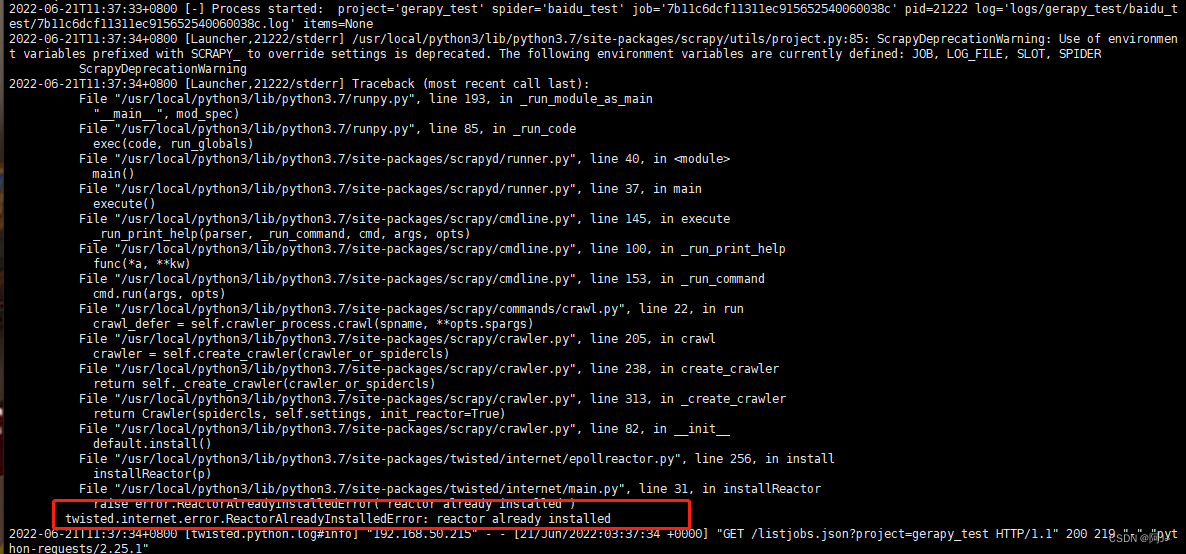
terms of settlement : Reduce scrapy edition pip3 install scrapy==2.5.1
边栏推荐
- 今天16:00 | 中科院计算所研究员孙晓明老师带大家走进量子的世界
- Detailed explanation of Android interview notes handler
- 撸一个随机数生成器
- Application of global route guard
- 手机炒股安全吗?
- A random number generator
- [the path of system analyst] Chapter 6: Double inventory demand engineering (comprehensive knowledge concept)
- 性能之文件系统篇
- SystemVerilog(十三)-枚举数据类型
- Server rendering
猜你喜欢

Es learning

XSS攻击

c盘使用100%清理方法
![[image fusion] image fusion based on morphological analysis and sparse representation with matlab code](/img/ae/027fc1a3ce40b35090531370022c92.png)
[image fusion] image fusion based on morphological analysis and sparse representation with matlab code

How to start the phpstudy server

Shen Ying, China Academy of communications and communications: font open source protocol -- Introduction to ofl v1.1 and analysis of key points of compliance

开源社邀请您参加OpenSSF开源安全线上研讨会
Open source invites you to participate in the openssf Open Source Security Online Seminar

今天16:00 | 中科院计算所研究员孙晓明老师带大家走进量子的世界

【观察】ObjectScale:重新定义下一代对象存储,戴尔科技的重构与创新
随机推荐
金仓数据库 KingbaseES 插件identity_pwdexp
Detection and analysis of simulator in an app
MySQL and Oracle processing CLOB and blob fields
中国信通院沈滢:字体开源协议——OFL V1.1介绍及合规要点分析
仿真与烧录程序有哪几种方式?(包含常用工具与使用方式)
Multiple environment variables
金仓数据库 KingbaseES 插件force_view
网络远程访问的方式使用树莓派
ARM64汇编的函数有那些需要注意?
Dragon Book tiger Book whale Book gnawing? Try the monkey book with Douban score of 9.5
Task03 probability theory
Network remote access using raspberry pie
看完这篇 教你玩转渗透测试靶机Vulnhub——DriftingBlues-7
Dell technology performs the "fast" formula and plays ci/cd
炒股票开户的话,手机开户安全吗?有谁知道啊?
Apache ShenYu 入門
垃圾回收机制
TASK03|概率论
[shangyun boutique] energy saving and efficiency improvement! Accelerating the transformation of "intelligent manufacturing" in the textile industry
Writing wechat applet with uni app