当前位置:网站首页>AI系统前沿动态第38期:谷歌已放弃TensorFlow?;训练大模型的四种GPU并行策略;LLVM之父:模块化设计决定AI前途
AI系统前沿动态第38期:谷歌已放弃TensorFlow?;训练大模型的四种GPU并行策略;LLVM之父:模块化设计决定AI前途
2022-06-23 09:33:00 【智源社区】
1、放弃TensorFlow,谷歌全面转向JAX?
https://mp.weixin.qq.com/s/UMIJltvUWfvf8USub5WetQ
2、一个算子在深度学习框架中的旅程
https://mp.weixin.qq.com/s/l5JB449YTNmzFRJPfw_hKw
3、训练千亿参数大模型,离不开四种GPU并行策略
https://mp.weixin.qq.com/s/DsbFkiCpmI_D9jsWBwBrhQ
4、embedx分布式训练和推理框架
https://mp.weixin.qq.com/s/1ulsDVcqcEaoN-p_dYGj5g
5、BytePS中对rdma的优化
https://zhuanlan.zhihu.com/p/525076335
6、数据并行Deep-dive: 从DP 到 Fully Sharded Data Parallel (FSDP)完全分片数据并行
https://zhuanlan.zhihu.com/p/485208899
7、自动微分的正反模式
https://mp.weixin.qq.com/s/u-UEpfZwvvE3IpPRowIQQA
8、ARM 算子性能优化上手指南
https://zhuanlan.zhihu.com/p/517371998
9、关于并发和并行,Go和Erlang之父都弄错了?
https://mp.weixin.qq.com/s/hE3UapcUp7apThmsSBsNRw
10、LLVM之父Chris Lattner:模块化设计决定AI前途,不服来辩
https://mp.weixin.qq.com/s/GOyR0cMMwUTLHdGaH0UqIg
11、深度学习概述:从基础概念、计算步骤到调优方法
https://mp.weixin.qq.com/s/1ARk-7kFC3U1GgJoiLkFUA

边栏推荐
- Redis learning notes pipeline
- Best time to buy and sell stock
- Redis learning notes - data type: ordered set (Zset)
- Common English explanations in arm
- Redis学习笔记—客户端通讯协议RESP
- Redis学习笔记—数据库管理
- Redis learning notes - data type: hash
- ionic5錶單輸入框和單選按鈕
- Web -- Information Disclosure
- Thin film interference data processing
猜你喜欢

Basic process of code scanning login

What is BFC? What problems can BFC solve
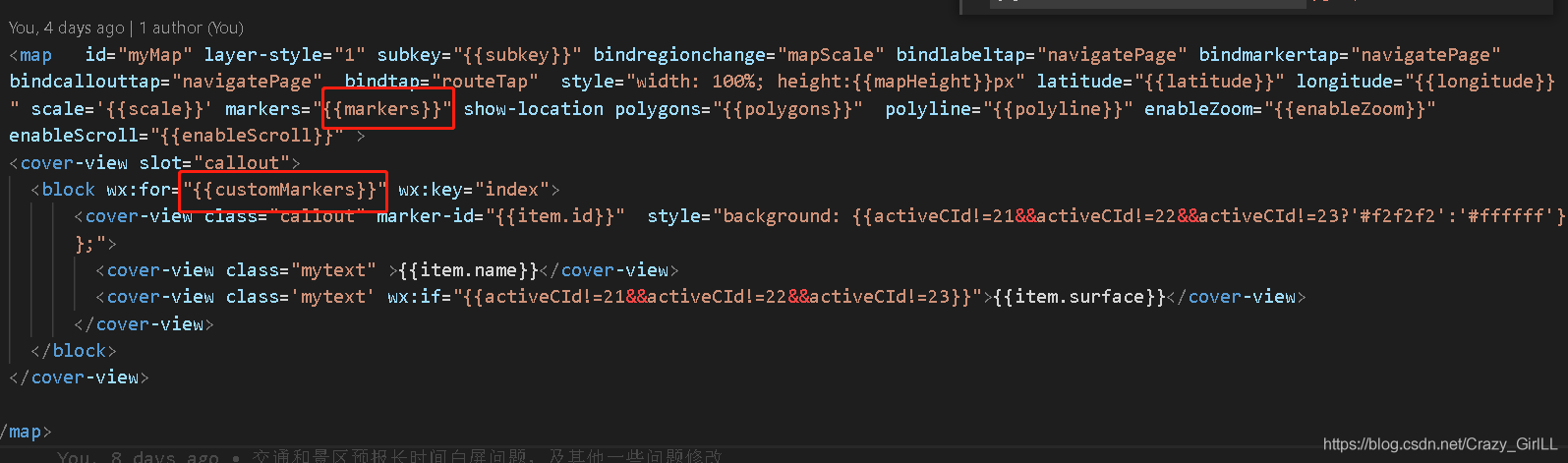
Wechat applet: click the button to switch frequently, overlap the custom markers, but the value does not change
Redis学习笔记—慢查询分析
![[极客大挑战 2019]HardSQL](/img/73/ebfb410296b8e950c9ac0cf00adc17.png)
[极客大挑战 2019]HardSQL

UEFI 源码学习4.1 - PciHostBridgeDxe

Learn SCI thesis drawing skills (E)

Mysql database introduction summary

#gStore-weekly | gStore源码解析(四):安全机制之黑白名单配置解析
Redis learning notes - data type: string (string)

随机推荐
Pizza ordering design - simple factory model
[GXYCTF2019]BabySQli
Redis learning notes - AOF of persistence mechanism
UEFI learning 3.6 - ACPI table on ARM QEMU
Redis learning notes - detailed explanation of redis benchmark
Redis learning notes - redis and Lua
RBtree
Leetcode topic analysis contains duplicate II
Redis learning notes - slow query analysis
Gesture recognition based on mediapipe
Redis learning notes - Database Management
Lua的基本使用
cooding代码库的使用笔记
位绑定
【CTF】bjdctf_2020_babyrop
UEFI源码学习3.7 - NorFlashDxe
Combination sum of leetcode topic analysis
线性表(SequenceList)的顺序表示与实现----线性结构
Redis学习笔记—持久化机制之RDB
Redis学习笔记—数据类型:字符串(string)