当前位置:网站首页>Meta&伯克利基于池化自注意力机制提出通用多尺度视觉Transformer,在ImageNet分类准确率达88.8%!开源...
Meta&伯克利基于池化自注意力机制提出通用多尺度视觉Transformer,在ImageNet分类准确率达88.8%!开源...
2022-06-24 19:50:00 【我爱计算机视觉】
关注公众号,发现CV技术之美
本文分享 CVPR 2022 论文『MViTv2: Improved Multiscale Vision Transformers for Classification and Detection』,Meta&UC Berkeley基于池化自注意力机制提出通用多尺度视觉Transformer,在ImageNet分类准确率达88.8%!代码已开源!
详细信息如下:

论文链接:https://arxiv.org/abs/2112.01526
项目链接:https://github.com/facebookresearch/mvit
01
摘要
在本文中,作者研究了多尺度视觉Transformer(MViTv2)作为图像和视频分类以及目标检测的统一架构 ,提出了一个改进的MViT版本,它包含了分解的相对位置嵌入和残差池化连接。
作者以五种尺寸实例化了该结构,并对其在ImageNet分类、COCO检测和Kinetics-400视频识别方面进行了评估,其性能优于以前的工作。作者进一步将MVITv2的池化注意力(pooling attention)机制与窗口注意机制进行了比较,发现池化注意力机制在精确度/计算方面优于窗口注意机制。
MViTv2在三个领域都具有一流的性能:ImageNet分类准确率为88.8%,COCO目标检测准确率为58.7,Kinetics-400视频分类准确率为86.1%。
02
Motivation
为不同的视觉识别任务设计结构历来都很困难,最广泛采用的结构是将简单性和有效性结合在一起的架构,例如VGGNet和ResNet。最近,视觉Transformer(ViT)表现出了良好的性能,可与卷积神经网络(CNN)相媲美,并且最近提出了一系列修改,以将其应用于不同的视觉任务。
虽然ViT在图像分类中很受欢迎,但它在高分辨率目标检测和时空视频理解任务中的应用仍然具有挑战性。视觉信号的密度对计算和记忆需求提出了严峻的挑战,因为这些信号在基于Transformer的模型的自注意块中以二次复杂度进行缩放。目前采用了不同的策略来处理这一负担:两种流行的策略是:(1)在窗口内计算局部注意力,用于目标检测;(2)池化注意力,在计算视频任务中的自注意之前,局部聚集特征。
后者推动了多尺度视觉Transformer(MViT),这种架构以一种简单的方式扩展了ViT:它没有在整个网络中拥有固定的分辨率,而是具有从高分辨率到低分辨率的多个阶段的特征层次。MViT是为视频任务而设计的,它具有最先进的性能。
在本文中,作者开发了两个简单的技术改进,以进一步提高其性能,并研究MViT作为一个单一模型家族的视觉识别横跨3个任务:图像分类、目标检测和视频分类,以了解它是否可以作为空间和时空识别任务的一般视觉主干。本文的实验研究产生了一个改进的架构(MViTv2),包括以下内容:
作者创建了强baseline,以改善沿两个轴的注意力:(a)使用分解的位置距离进行平移不变的位置嵌入,以在Transformer块中注入位置信息;(b) 一种残差池化连接,用于补偿在注意力计算中池化的影响。本文简单而有效的升级带来了显著更好的结果。
利用改进的MViT结构,作者采用了一个标准的密集预测框架:带特征金字塔网络(FPN)的Mask R-CNN,并将其应用于目标检测和实例分割。作者研究了MViT是否可以通过池化注意力来处理高分辨率的视觉输入,以克服所涉及的计算和内存开销。实验表明,池化注意力比局部窗口注意机制(如Swin)更有效。作者进一步开发了一种简单而有效的混合窗口注意方案,该方案可以补充池化注意,以实现更好的准确性/计算权衡。
作者以五种复杂的尺寸(宽度、深度、分辨率)实例化了本文的结构,并报告了大型多尺度Transformer的实用训练方法。MViT变体应用于图像分类、目标检测和视频分类,只需稍加修改,即可研究其作为通用视觉结构的目的。
03
方法
3.1 Revisiting Multiscale Vision Transformers
MViTv1的关键思想是为低级和高级视觉建模构建不同的阶段,而不是ViT中的单比例尺块。从网络的输入阶段到输出阶段,MViT缓慢扩展通道宽度D,同时降低分辨率L(即,序列长度)。
为了在Transformer块内执行下采样,MViT引入了池化注意力(Pooling Attention)。具体来说,对于输入序列,,它应用线性投影,然后是池化运算符(P),分别用于查询、键和值张量:

其中Q的长度可通过减少,K和V长度可通过和减少。
随后,采用池化自注意力:

输出序列为。其中,键和值张量的下采样因子和可能不同于应用于查询序列的下采样因子。
池化注意力可以通过池化查询张量Q在MViT的不同阶段之间降低分辨率,并通过池化键K和值V张量显著降低计算和内存复杂性。
3.2 Improved Pooling Attention
Decomposed relative position embedding
尽管MViT在建模token间的交互方面表现出了巨大的潜力,但它们关注的是内容,而不是结构。时空结构建模完全依赖于“绝对”位置嵌入来提供位置信息。这忽略了视觉中平移不变性的基本原理。也就是说,MViT建模两个patch之间交互的方式将根据它们在图像中的绝对位置而改变。为了解决这个问题,作者将相对位置嵌入纳入池化自注意计算中,它只取决于token之间的相对位置距离。
作者将两个输入元素i和j之间的相对位置编码为位置嵌入,其中和表示元素i和j的空间(或时空)位置。然后将成对编码表示嵌入到自注意模块中:

然而,可能嵌入的数量以为单位,计算起来可能很昂贵。为了降低复杂性,作者沿时空轴分解元素i和j之间的距离计算:

其中,是沿高度、宽度和时间轴的位置嵌入;分别表示token i的垂直、水平和时间位置。是可选的,仅在视频样本中需要支持时间维度。相比之下,这样的分解嵌入将学习嵌入的数量减少到,这对早期的高分辨率特征映射有很大影响。
Residual pooling connection
池化注意力对于降低注意力块的计算复杂度和内存需求非常有效。MViTv1在K和V张量上的步长比Q张量的步长大,Q张量的步长只有在输出序列的分辨率在不同阶段发生变化时才进行下采样。这促使将残差池化连接添加到池化的Q张量中,以增加信息流并促进MViT中池化注意力块的训练。

如上图所示,作者在注意力块内部引入了一个新的残差池化连接,即将池化查询张量添加到输出序列Z中。因此,池化注意力表示为:

其中,输出序列Z的长度与池化查询张量Q的长度相同。
3.3 MViT for Object Detection
FPN integration

MViT的层次结构分四个阶段生成多尺度特征图,因此自然地集成到目标检测任务的特征金字塔网络(FPN),如上图所示。FPN中具有横向连接的自上而下金字塔为MViT在所有尺度上构建语义强大的特征映射。通过使用带有MViT主干的FPN,作者将其应用于不同的检测结构(例如Mask R-CNN)。
Hybrid window attention
Transformer中的自注意相对于token的数量具有二次复杂性。对于目标检测来说,这个问题更加严重,因为它通常需要高分辨率的输入和特征图。在本文中,作者研究了两种显著降低这种计算和内存复杂性的方法:第一,在MViT的注意块中设计的池化注意力。其次,将窗口注意作为一种减少目标检测计算量的技术。
池化注意力和窗口注意力都通过减少查询、键和值的大小来控制自注意力的复杂性。然而,它们的本质是不同的:池化注意力的特点是通过局部聚合对注意力进行降采样,但保持全局的自注意力计算;窗口注意保持张量的分辨率,但通过将输入划分为非重叠窗口,然后仅计算每个窗口内的局部自注意。
这两种方法的内在差异促使作者研究它们是否可以在目标检测任务中发挥互补作用。默认窗口注意力仅在窗口内执行局部自注意力,因此缺少跨窗口的连接。与用移动窗口来缓解此问题的Swin不同,作者提出了一种简单的混合窗口注意(Hwin)设计来添加跨窗口连接。Hwin在最后三个阶段的所有窗口中计算局部注意力,但最后三个阶段的最后一个块除外,这些阶段都会输入给FPN。这样,到FPN的输入特征映射会包含全局信息。
本文的消融表明,这种简单的Hwin在图像分类和目标检测任务上始终优于Swin。此外,作者证明了,将池化注意力与Hwin相结合可以获得最佳的目标检测性能。
Positional embeddings in detection
与ImageNet分类不同,在ImageNet分类中,输入是固定分辨率的crop(例如224×224),目标检测通常包括训练中大小不同的输入。对于MViT中的位置嵌入(无论是绝对的还是相对的),首先初始化来自ImageNet预训练权重的参数,该权重对应于输入大小为224×224的位置嵌入,然后将其插值到相应的大小,以进行目标检测训练。
3.4. MViT for Video Recognition
Initialization from pre-trained MViT
相比于基于图像的MViT,基于视频的MViT只有三个区别:1)patchification stem中的投影层需要将输入投影到时空立方体中,而不是2D patch;2) 现在,池化操作符将时空特征图池化在一起;3) 相对位置嵌入参照时空位置。
投影层和池化操作符在默认情况下由卷积层实例化,具体而言,作者使用预训练模型中2D conv层的权重初始化中心帧的conv滤波器,并将其他权重初始化为零。然后,作者采用上面分解的相对位置嵌入,从预训练的权重初始化空间嵌入,将时间嵌入初始化为零。
3.5. MViT Architecture Variants

如上表所示,作者构建了几个具有不同参数和FLOPs数量的MViT变体,以便与其他vision transformer作品进行公平比较。具体来说,作者通过改变基本通道尺寸、每个阶段的块数和块中的头数,为MViT设计了五种变体。
04
实验

上表展示了本文的MViTv2和最先进的CNN和Transformer的对比结果。可以看出,相比于这些CNN和Transformer模型,MViTv2的模型效率和准确率大大提升。

上表显示了使用大规模IN-21K预训练的结果。IN-21K数据为MViTv2-L增加了2.2%的精确度。

上表a显示了使用Mask R-CNN和Cascade Mask R-CNN对COCO的结果。

在上表a中,作者比较了IN1K上的不同注意力模式。具体来说,作者比较了5种注意力机制:全局、窗口、移位窗口(Swin)、混合窗口(Hwin)和池化注意力。上表b显示了COCO数据集上各种注意力机制的比较。

上表展示了ImageNet和COCO数据集上不同位置编码的实验结果。

上表研究了残差池化连接的重要性。

上表中展示了MViTv2和Swin的运行时间的对比。

上表比较了ViT-B和MViTv2-S的默认多尺度(FPN)检测器与单尺度检测器的实验结果。

上表比较了在Kinetics-400数据集上,MViTv2与之前的工作的对比,包括最先进的CNN和VIT。
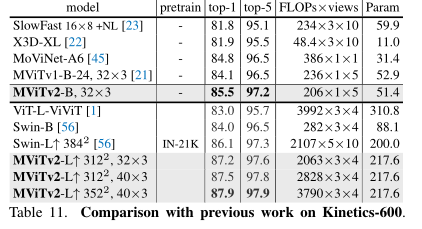
上表比较了在Kinetics-600数据集上,MViTv2与之前的工作的对比。

上表比较了在Kinetics-700数据集上,MViTv2与之前的工作的对比。

上表比较了在SSv2数据集上,MViTv2与之前的工作的对比。

上表比较了不同预训练方案对K400的影响。
05
总结
在本文中,作者提出了一种改进的多尺度视觉Transformer作为视觉识别的通用层次结构。在实验评估中,与其他视觉Transformer相比,MViT表现出了强大的性能,并在图像分类、目标检测、实例分割和视频识别等广泛使用的基准上达到了SOTA的精度。
参考资料
[1]https://arxiv.org/abs/2112.01526
[2]https://github.com/facebookresearch/mvit

END
欢迎加入「Transformer」交流群备注:TFM

边栏推荐
- Scala IO serialization and deserialization
- JPA学习2 - 核心注解、注解进行增删改查、List查询结果返回类型、一对多、多对一、多对多
- Hibernate learning 3 - custom SQL
- The third generation of power electronics semiconductors: SiC MOSFET learning notes (V) research on driving power supply
- Scala IO writes data to a text file
- Eye gaze estimation using webcam
- Unmanned driving: Some Thoughts on multi-sensor fusion
- DO280OpenShift访问控制--加密和ConfigMap
- 干接点和湿接点
- Difficult and miscellaneous problems: A Study on the phenomenon of text fuzziness caused by transform
猜你喜欢

Creative SVG ring clock JS effect

U.S. House of Representatives: digital dollar will support the U.S. dollar as the global reserve currency

Tongji and Ali won the CVPR best student thesis, lifeifei won the Huang xutao award, and nearly 6000 people attended the offline conference

How to delete the entire row with duplicate items in a column of WPS table

Opengauss kernel: simple query execution
![[interview question] what is a transaction? What are dirty reads, unrepeatable reads, phantom reads, and how to deal with several transaction isolation levels of MySQL](/img/95/02a58c9dc97bd8347b43247e38357d.png)
[interview question] what is a transaction? What are dirty reads, unrepeatable reads, phantom reads, and how to deal with several transaction isolation levels of MySQL

Is there really something wrong with my behavior?

在滴滴和字节跳动干了 5年软件测试,太真实…

有趣的checkbox计数器

Svg line animation background JS effect
随机推荐
美国众议院议员:数字美元将支持美元作为全球储备货币
C program design topic 18-19 final exam exercise solutions (Part 2)
What is the difference between one way and two way ANOVA analysis, and how to use SPSS or prism for statistical analysis
How to delete the entire row with duplicate items in a column of WPS table
教程详解|在酷雷曼系统中如何编辑设置导览功能?
Analysis report on development mode and investment direction of sodium lauriminodipropionate in the world and China 2022 ~ 2028
Dry and wet contacts
Analysis report on development trend and investment forecast of global and Chinese D-leucine industry from 2022 to 2028
【Proteus仿真】定时器0作为16位计数器使用示例
Current situation analysis and development trend forecast report of global and Chinese acrylonitrile butadiene styrene industry from 2022 to 2028
Hibernate learning 3 - custom SQL
C程序设计专题 15-16年期末考试习题解答(上)
VIM use command
C WinForm maximizes occlusion of the taskbar and full screen display
Microsoft won the title of "leader" in the magic quadrant of Gartner industrial Internet of things platform again!
走近Harvest Moon:Moonbeam DeFi狂欢会
融合模型权限管理设计方案
Fast pace? high pressure? VR panoramic Inn brings you a comfortable life
水库大坝安全监测
MySQL日志管理