当前位置:网站首页>The Google File System (GFS) learning notes
The Google File System (GFS) learning notes
2022-06-24 20:35:00 【zhanyd】
List of articles
Introduction
This article was written by xuwenhao, a teacher of geek time 《 Interpretation of classic big data papers 》 Course notes , A lot of text and pictures come from the column , Delete if there is infringement .
This article 2003 A paper published in 1987 , Although it's been a long time , But it is still a classic paper in the field of big data . Address of thesis :The Google File System
The core of this paper is to solve the problem of how to efficiently store massive data in a distributed environment .
GFS The architecture of
GFS It's single Master framework , single Master Give Way GFS The architecture of has become very simple , Avoids the need to manage complex consistency issues . But it also brings many limitations , For example, once Master Something goes wrong , The entire cluster cannot write data .
Throughout GFS in , There are two types of servers , One is Master, That is the whole GFS There is only one master node in ; The second is chunkserver, That is, the node that actually stores data .
since GFS It's called a distributed file system , So this file , In fact, you can not store on the same server .
therefore , stay GFS Inside , Will put each file according to 64MB The size of a piece , Cut into pieces chunk. Every chunk There will be one in GFS The only one on the handle, This handle It's actually a number , Be able to uniquely identify specific chunk. And then every one chunk, In the form of a file , Put it in chunkserver On .
and chunkserver, In fact, it is an ordinary Linux The server , There is a user mode GFS Of chunkserver Program . This program will be responsible for Master as well as GFS The client of RPC signal communication , Complete the actual data reading and writing operation . Of course , In order to ensure that the data does not chunkserver If it is broken, it will be lost , Every chunk All three copies will be saved (replica).
One of them is the master data (primary), Two copies are secondary data (secondary), When the three data are inconsistent , The master data shall prevail . There are three copies , It can not only prevent data loss for various reasons , It can also be used when there are many concurrent reads , The pressure read by the sharing system .
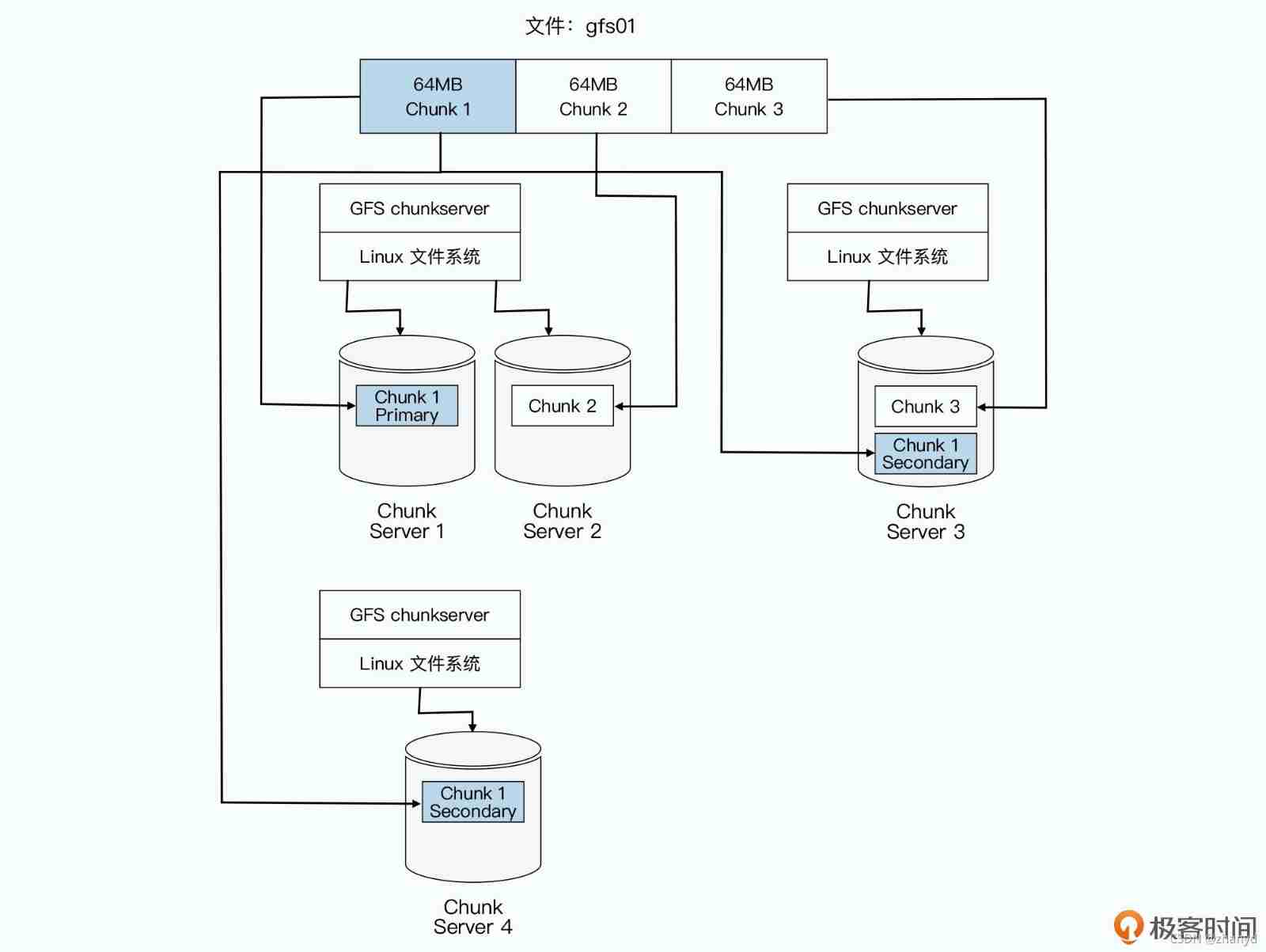
First ,master It will store three main metadata (metadata):
1. Document and chunk Namespace information for , That is, similar to the previous /data/geektime/bigdata/gfs01 Such path and file name ;
2. How many of these files are split into chunk, That is, the full path file name to multiple chunk handle The mapping relation of ;
3. these chunk What is actually stored chunkserver On , That is to say chunk handle To chunkserver The mapping relation of .
About Metadata, The original text of the thesis is as follows :
The master stores three major types of metadata: the file and chunknamespaces, the mapping from files to chunks, and the locations of each chunk’s replicas. All metadata is kept in the master’s memory. The first two types (namespaces and file-to-chunkmapping) are also kept persistent by logging mutations to an operation log stored on the master’s local diskand replicated on remote machines. Using a log allows us to update the master state simply, reliably, and without risking inconsistencies in the event of a master crash. The master does not store chunklocation information persistently. Instead, it asks each chunkserver about its chunks at master startup and whenever a chunkserver joins the cluster.

Reading data
The steps for the client to read data are as follows :
1. The client first finds the data to be read in the first few chunk in , Because of every chunk The length is fixed 64M, The client will read the file according to the offset and length You can calculate the number of data you need chunk On . The client compares the file name with chunk Send your message to Master.
2.Master When you get the information , Will be able to chunk Where all the corresponding copies are located chunkserver Tell the client .
3. The client gets chunk Where chunkserver After the message , The client can go to any one chunkserver Read the data you need in .
The original picture of the paper is as follows :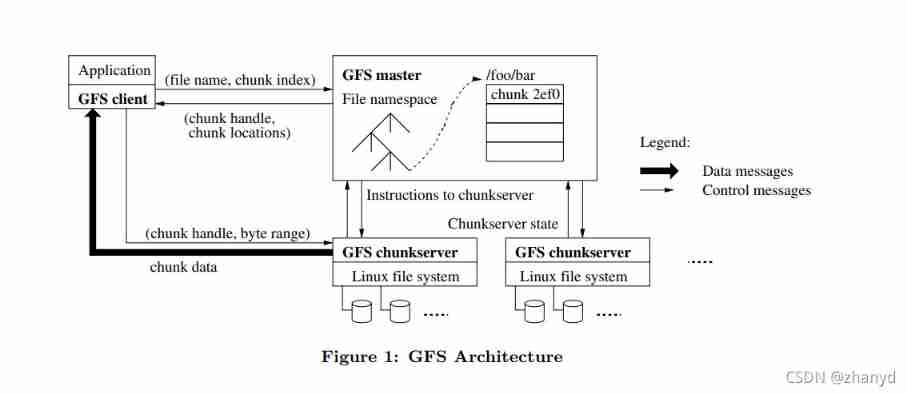
single Master Nodes can easily become performance bottlenecks , once Master Hang up , The service will stop . To improve performance ,Master All data of the node , Are stored in memory , This can also cause problems , Once Master Hang up , The data will be lost . therefore ,Master It will record the operation log and generate the corresponding data on a regular basis Checkpoints persist , That is to write to the hard disk .
This is to ensure that in Master The data in , It will not be lost because of a machine failure . When Master When the node restarts , Will first read the latest Checkpoints, Then replay (replay)Checkpoints Subsequent operation logs , hold Master The state of the node is restored to the latest state . This is the most common recoverable mechanism used by storage systems .
But here comes the problem , If Master The nodes are completely obsolete ? Hardware failure , What should I do if I can't even turn it on ?
Don't be afraid of , We still have a spare tire , They are called Backup Master, We are Master Write up operation , The corresponding operation records will be saved to the disk , also Back Master After the data on is saved successfully , The whole operation is successful . The whole process is synchronous , be called “ Synchronous replication ”. When Master After hanging up , Will choose one Backup Master The spare tire is in full swing , Become new Master.
But switch to new Master The process may also be relatively long , Read required Checkpoints And operation log , This may affect the use of the client , In order to prevent this short period of service suspension , The designer added another name “ shadow Master” Things that are , shadow Master Will keep syncing Master The data in , However, when Master When something goes wrong , Clients can learn from these shadows Master Find the information you want . shadow Master Is read-only , And it is asynchronous replication , So there won't be much performance impact .
Writing data
The main steps for the client to write data are as follows :
First step , The client will ask master The data to be written , Where should I chunkserver On .
The second step , Just like reading data ,master Will tell the client all the secondary copies (secondary replica) Where chunkserver. It is not enough ,master It also tells the client which replica yes “ The eldest brother ”, That is, the master copy (primary replica), The data shall be subject to it at this time .
The third step , Get what data should be written to chunkserver After , The client will send the data to be written to all replica. But this time ,chunkserver After getting the data sent, it won't really be written down , Only put the data in one LRU In the buffer of .
Step four , Wait until all copies have received data , The client will send a write request to the primary replica .GFS Facing hundreds of concurrent clients , Therefore, the primary replica may receive write requests from many clients . The master copy itself will arrange these requests in a certain order , Ensure that all data writes are in a fixed order . Next , The primary replica starts in this order , The just now LRU The data in the buffer of is written to the actual chunk In go to .
Step five , The primary replica will forward the corresponding write request to all secondary replicas , All secondary replicas are written in the same order as the primary replica , Write data to the hard disk .
Step six , After the data of the secondary replica is written , Will reply to the master copy , I have finished writing the data just like you .
Step seven , The primary replica then tells the client , The data is written successfully . If an error occurs in the process of writing data to any replica , This error will be told to the client , This means that the write failed .

And previously from GFS It is the same as reading data ,GFS The client is only from master Got it chunk data In which chunkserver Metadata , The actual data reading and writing do not need to pass master. in addition , Not only the specific data transmission does not go through master, The subsequent data is in multiple chunkserver Coordination work written simultaneously on , There is no need to go through master.
Pipelined network data transmission
The client does not send data to multiple servers in turn chunkserver, Instead, first send all the data to the nearest one chunkserver, And then let chunkserver Then synchronize the data to other copies .

The advantage of this is , It bypasses the network bottleneck of the client , The data transmission efficiency between servers is much faster than that of clients .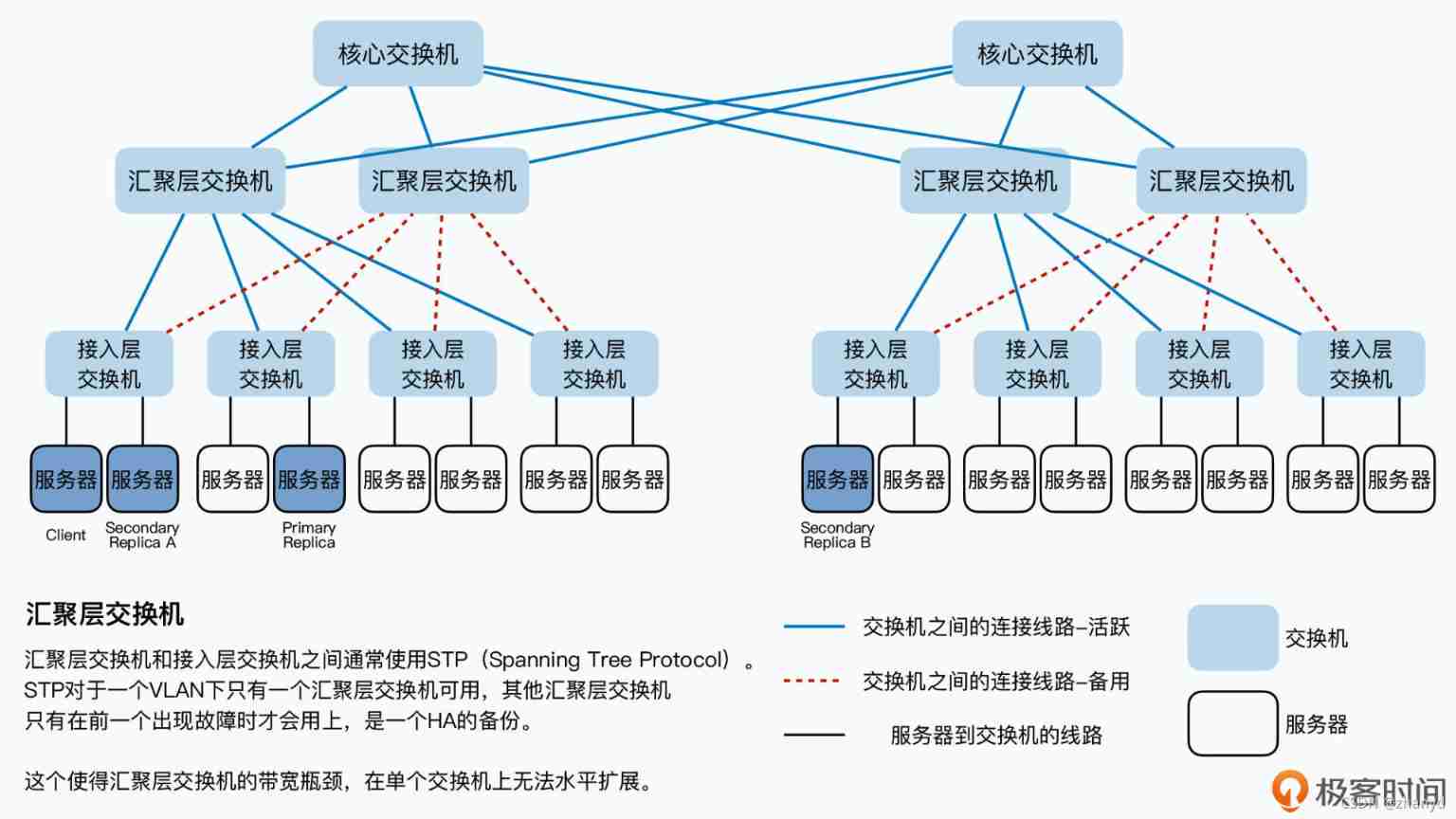
First , The client transmits the data to itself “ lately ” Of , That is, the secondary replica on the same rack A The server ;
then , Secondary copy A The server then transmits the data to itself “ lately ” Of , In different racks , But it is on the primary replica server under the same aggregation layer switch ;
Last , Primary replica server , And then transfer the data to the secondary replica under another convergence layer switch B The server .
When writing data , The client is just from master Get chunk Metadata of the location , In the actual data transmission process , It doesn't need to master Participate in , So as to avoid master Become a bottleneck .
On the client side to multiple chunkserver When writing data , Adopted “ Nearby ” Pipeline transmission scheme of , Avoid the client network becoming a bottleneck .
Record addition
The above writing method is prone to problems , That is, multiple clients write one at the same time chunk When , Will overwrite each other's data . To solve this problem ,GFS A main data writing method is recommended , be called “ Record addition ”, It guarantees atomicity (Atomic), And it can be basically determined during concurrent writing .
The specific operation process is as follows :
1. Check the current chunk Is it possible to write down the records to be added now . If you can write down , Then write in the current additional record , meanwhile , This data write will also be sent to other secondary copies , Write it again on the second copy .
2. If at present chunk I can't put it anymore , Then it will first put the current chunk Fill in empty data , And let the secondary copy be filled with empty data . then , The primary replica will tell the client , Let it be on the next chunk Retest on . Now , The client will go to a new chunk Where chunkserver Add records .
3. Because the primary replica is located in chunkserver It controls the operation sequence of data writing , And the data will only be appended later , So even if there are concurrent writes , All requests will go to the same location of the primary replica chunkserver Get in line , No data will be written to the same area , Overwriting the data that has been appended to write .
4. And to protect chunk The data to be added can be stored in the ,GFS Limiting the amount of data added to a record is 16MB, and chunkserver One of them chunk Its size is 64MB. therefore , Adding to the record needs to be in chunk When filling in the blank data , At most, that is to fill in 16MB, That is to say chunkserver The maximum amount of storage is wasted 1/4.
Each client is assigned to a chunk Independent space on , And then write concurrently , Because each client writes its own independent space , There will be no conflict . If the write fails, find a new space to write again , Most of all, the order is different , To ensure that the data is complete .
For example, client x The data to be written A stay chunkserver R I failed on , It will be appended to C Back , Although there are some duplicate data , But it can ensure that the data is complete in the end .

summary
Last , Let's see GFS The overall design drawing of is as follows :
To sum up ,GFS The design principle of is simple 、 Design around hardware performance , And the loose requirements for consistency under these two premises .
GFS There is no theoretical innovation in the design of , But according to the hardware constraints in the design innovation . What suits oneself is the best , We don't have to pursue any high technology , What can meet the demand at low cost is a good solution . Innovation is not necessarily about creating something new , Putting things together in a proper way is also innovation .
边栏推荐
- Image panr
- 【CANN文档速递05期】一文让您了解什么是算子
- [performance tuning basics] performance tuning standards
- RF_DC系统时钟设置GEN1/GEN2
- 主数据建设的背景
- Hosting service and SASE, enjoy the integration of network and security | phase I review
- [cloud resident co creation] ModelBox draws your own painting across the air
- "Ningwang" was sold and bought at the same time, and Hillhouse capital has cashed in billions by "selling high and absorbing low"
- 视频平台如何将旧数据库导入到新数据库?
- Coinbase将推出首个针对个人投资者的加密衍生产品
猜你喜欢

二叉树的基本性质与遍历

顺序栈1.0版本

Set up your own website (14)

Cooking business experience of young people: bloggers are busy selling classes and bringing goods, and the organization earns millions a month

物联网?快来看 Arduino 上云啦

16 excellent business process management tools

2022年最新四川建筑八大员(电气施工员)模拟题库及答案

对“宁王”边卖边买,高瓴资本“高抛低吸”已套现数十亿
"Ningwang" was sold and bought at the same time, and Hillhouse capital has cashed in billions by "selling high and absorbing low"

伯克利、MIT、剑桥、DeepMind等业内大佬线上讲座:迈向安全可靠可控的AI
随机推荐
得物多活架构设计之路由服务设计
Leetcode (455) - distribute cookies
The first public available pytorch version alphafold2 is reproduced, and Columbia University is open source openfold, with more than 1000 stars
Behind Tiantian Jianbao storm: tens of millions in arrears, APP shutdown, and the founder's premeditated plan to run away?
Otaku can't save yuan universe
RF_ DC system clock setting gen1/gen2
Huawei cloud modelarts has ranked first in China's machine learning public cloud service market for the fourth time!
Ribbon源码分析之@LoadBalanced与LoadBalancerClient
等等党们的胜利!挖矿退潮后,显卡价格全面暴跌
苹果不差钱,但做内容“没底气”
[cann document express issue 04] unveiling the development of shengteng cann operator
How does the video platform import the old database into the new database?
C語言實現掃雷(簡易版)
Vant component used in wechat applet
Get to know the data structure of redis - hash
Berkeley, MIT, Cambridge, deepmind and other industry leaders' online lectures: towards safe, reliable and controllable AI
红象云腾完成与龙蜥操作系统兼容适配,产品运行稳定
Bytebase加入阿里云PolarDB开源数据库社区
16 excellent business process management tools
Ribbon source code analysis @loadbalanced and loadbalancerclient