当前位置:网站首页>Introduction to redis - Chapter 3 - data structures and objects - Dictionary
Introduction to redis - Chapter 3 - data structures and objects - Dictionary
2022-06-23 11:44:00 【tiger’s bytes】
The dictionary is Redis It is widely used in many fields , such as Redis Our database is implemented using dictionary as the bottom layer , The operation of adding, deleting, modifying and querying databases is also based on the operation of dictionaries .
In addition to representing databases , Dictionaries are also one of the underlying implementations of hash keys , When a hash key contains more key value pairs , Or when the elements in the key value pair are relatively long strings ,Redis Will use the dictionary as the underlying implementation of the hash key .
Dictionary implementation :
Redis The hash table is used as the underlying implementation in the dictionary of , There can be multiple hash table nodes in a hash table , Each hash table node holds a key value pair in the dictionary .
Hashtable
typedef struct dictht {
dictEntry **table; // Hash table array
unsigned long size; // Hash table size , Always equal to 2^n
unsigned long sizemask; // Hash size mask , Used to calculate index values , Always equal to size - 1, You can directly match the hash of the key value to get the corresponding index of the key value
unsigned long used; // The number of existing nodes in the hash table
}table Property is an array , Each element in the array is a pointer to dict.h/dictEntry Pointer to structure , Every dictEntry The structure holds a key value pair .size Property records the size of the hash table , That is to say table Size of array , and used Property records the current number of key value pairs in the hash table .sizemask The value of the property is always equal to size - 1 , This property, together with the hash value, determines that a key should be placed in table Which index of the array is above .
typedef struct dictEntry {
void *key; // key
union{
void *val; // Pointer types
uint64_t u64; // Unsigned 64 An integer
int64_t s64; // A signed 64 An integer
}v; // value
struct dictEntry *next; // Point to the next hash node , Hash conflicts , Form a linked list
}dictEntry;typedef struct dict {
dictType *type; // Type specific function
void *privdata; // Private data
dictht ht[2]; // Hashtable
int rehashidx; // rehash Action marker
}dict;type Properties and privdata Property is for different types of key value pairs , Set to create a polymorphic dictionary :
- type Property is a point dictType Pointer to structure , Every dictType Structure holds a set of functions that operate on a particular type of key value pair ,Redis Different types of specific functions will be set for dictionaries with different purposes .
- privdata Property holds the optional parameters that need to be passed to those type specific functions .
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // Function to calculate hash value
void *(*keyDup)(void *privdata, const void *key); // Copy function of key
void *(*keyDup)(void *privdata, const void *obj); // Function to copy values
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // Functions of comparison keys
void (*keyDestructor)(void *privdata, void *key); // Function to destroy key
void (*valDestructor)(void *privdata, void *obj); // Function to destroy value
}dictType; ht Property is an array of two items , Every item in the array is a dictht Hashtable , In general , The dictionary only uses ht[0] Hashtable ,ht[1] Hash table will only be on ht[0] Hash table rehash I'll use it when I'm sick .
except ht[1] outside , The other and rehash The relevant attribute is rehashidx, It records rehash Current progress , If it hasn't been done yet rehash , So its value is -1 .
As the operation goes on , The key value pairs saved in the hash table will increase or decrease the primary key , In order to keep the load factor of the hash table within a reasonable range , When the hash table holds too many or too few key value pairs , The program needs to expand or shrink the size of the hash table .
Expand or contract by rehash( Re hash ) Operate to complete ,Redis Execute... On the hash table of the dictionary rehash The steps are as follows :
1) For the dictionary ht[1] Hash table allocation space , The size of the hash table depends on the operation to be performed , as well as ht[0] The number of key value pairs currently contained :
- If you are performing an extension operation , that ht[1] The size of the first is greater than or equal to ht[0].used*2 Of 2^n .
- If you are performing a shrink operation , that ht[1] The size of the first is greater than or equal to ht[0].used Of 2^n.
2) Will be saved in ht[0] All key value pairs on rehash To ht[1] above :rehash It refers to recalculating the hash value of the key and the index value in the corresponding hash table , Then place the key value pair in ht[1] The corresponding position of the hash table .
3) When ht[0] All key value pairs contained are migrated to ht[1] after , Release ht[0] , take ht[1] Set to ht[0] , And in ht[1] Create a new blank hash table , For the next time rehash To prepare for .
Expansion and contraction of hash table
When any of the following conditions is satisfied , The program will automatically start extending the hash table :
1) The server is not currently executing BGSAVE or BGREWRITEAOF command , And the load factor of hash table is greater than or equal to 1
2) The server is currently executing BGSAVE or BGREWRITEAOF command , And the load factor of hash table is greater than or equal to 5
among , Load factor = Number of nodes saved in hash table / Hash table size (load_factor = ht[0].used / ht[0].size)
When the load factor of the hash table is less than 0.1 when , The program will automatically start shrinking the hash table .
Progressive type rehash:
rehash The action is not a one-time 、 Centralized completion is divided into several times 、 Gradual completion , The reason for this is that if the amount of data in the hash table is very large , one-time ht[0] Values for all rehash To ht[1] Words , The huge amount of computing may cause the server to stop serving for a period of time . Here is the hash table progressive rehash Step by step :
- by ht[1] Allocate space , Let the dictionary hold ht[0] and ht[1] Two hash tables
- Maintain an index counter in the dictionary rehashidx , And set its value to 0 , Express rehash Work officially begins
- stay rehash During the process , Every time the dictionary is added 、 Delete 、 When searching or updating operations , In addition to performing specified operations , By the way ht[0] The hash table is in rehashidx All key value pairs on the index rehash To ht[1], When rehash When the work is done , Program will rehashidx Property plus 1
- With the continuous execution of dictionary operation , At some point in time ,ht[0] All key value pairs of will be rehash To ht[1] On . At this point the program will rehashidx Property is set to -1 , Express rehash Operation completed
Progressive type rehash The good thing about it is that it takes a divide and rule approach , take rehash The calculation of key value pairs is equally distributed to each addition to the dictionary 、 Delete 、 Search and update operations , Thus avoiding centralized rehash The drawback of the huge amount of computation .

边栏推荐
- 简单易懂的软路由刷机使用教程
- 32路电话+2路千兆以太网32路PCM电话光端机支持FXO口FXS语音电话转光纤
- @黑马粉丝,这份「高温补贴」你还没领?
- 开发增效利器—2022年VsCode插件分享
- 六维图剖析:中国建筑集团有限公司企业成长性分析
- 坚持五件事,带你走出迷茫困境!
- 广播级E1转AES-EBU音频编解码器 E1转立体声音频卡侬头(XLR)编解码器
- The simplest DIY serial port Bluetooth hardware implementation scheme
- Introduction and use of list
- Oversampling Series II: Fourier transform and signal-to-noise ratio
猜你喜欢

【云舟说直播间】-数字安全专场明天下午正式上线

【云原生&微服务八】Ribbon负载均衡策略之WeightedResponseTimeRule源码剖析(响应时间加权)
![Openharmony application development [01]](/img/b1/1e37cecd3d3f9e46444c202cfb1b99.png)
Openharmony application development [01]
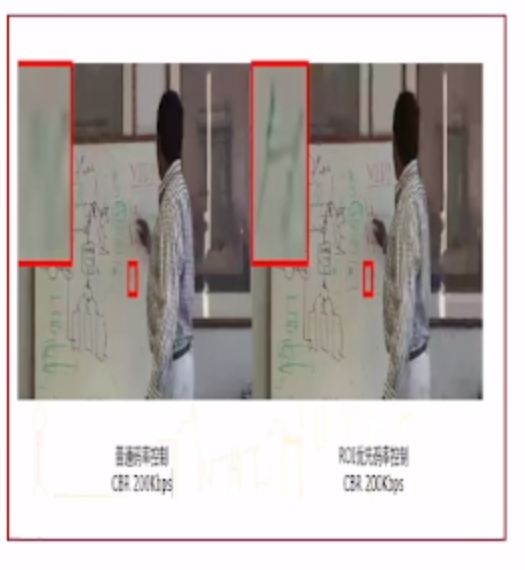
華為雲如何實現實時音視頻全球低時延網絡架構

开发增效利器—2022年VsCode插件分享

16路HD-SDI光端机多路HD-SDI高清视频光端机16路3G-SDI高清音视频光端机

成熟的知识管理,应具备哪些条件?

【零基础微信小程序】基于百度大脑人像分割的证件照换底色小程序实战开发

The simplest DIY pca9685 steering gear control program based on the integration of upper and lower computers of C # and 51 single chip microcomputer
"Core" has spirit "lizard", ten thousand people are online! Dragon Dragon community walks into Intel meetup wonderful review
随机推荐
电感有极性吗?
Analysis of LinkedList source code
Tensorrt notes (4) Modèle de segmentation du raisonnement
How Huawei cloud implements a global low latency network architecture for real-time audio and video
坦然面对未来,努力提升自我
过采样系列三:量化误差与过采样率
简单易懂的软路由刷机使用教程
Tamidog | analysis of investor types and enterprise investment types
今天14:00 | 12位一作华人学者开启 ICLR 2022
One picture decoding opencloudos community open day
OpenHarmony应用开发【01】
Google Earth Engine(GEE)——GEDI L2A Vector Canopy Top Height (Ver
I am in Foshan. Where can I open an account? Is it safe to open a mobile account?
tensorflow2的GradientTape求梯度
4E1 PDH光端机19英寸机架式单纤传输20km E1接口光纤网络光端机
六维图剖析:中国建筑集团有限公司企业成长性分析
如何使用笔记软件 FlowUs、Notion 进行间隔重复?基于公式模版
How to use the interval repetition memory system in flowus, notation and other note taking software?
32路电话+2路千兆以太网32路PCM电话光端机支持FXO口FXS语音电话转光纤
【云原生&微服务八】Ribbon负载均衡策略之WeightedResponseTimeRule源码剖析(响应时间加权)