当前位置:网站首页>Interpretation of x-vlm multimodal model
Interpretation of x-vlm multimodal model
2022-06-26 08:17:00 【just do it now】
The paper :https://arxiv.org/abs/2111.08276
Code :https://github.com/zengyan-97/X-VLM
Research background

The existing multimodal pre training models can be roughly divided into two categories :
1) Depending on the target detector extraction based on the object ( for example : vehicle 、 people 、 Trees 、 knapsack ) To represent a picture , This method can learn object level visual and language alignment , Pictured 1 in (a) Shown . These methods either directly use the pre trained target detector , Or combine the target detection process into multimodal pre training ;
2) use ResNet perhaps Vision Transformer Encode the whole picture , Just learn the alignment between the picture and the text , Pictured 1(b) Shown .
There are some problems in both methods . First , The method based on object detection can recognize all possible objects in the picture , Some of them have nothing to do with paired text . Besides , The object-based visual features extracted by this method may lose the information between objects ( It can be considered as a kind of contextual information ). and , This method can only identify a limited number of objects , It is difficult to predefine the appropriate object categories . The second method is simple and direct , But it is difficult to learn fine-grained visual and language alignment , for example : Object level alignment . This fine-grained alignment relationship has been confirmed by previous work for visual reasoning (visual reasoning) And visual positioning (visual grounding) The task is very helpful .
actually , For multimodal pre training , The following public data is available for use by the model :1) Picture and picture title ;2) Area labeling , for example : chart 1 The text in the “man crossing the street” Associated with a specific area in the picture . However , Previous work has roughly aligned the area labels with the whole picture ;3) Object label , for example “backpack”, These annotations are used to train the target detector in the previous work .
Different from the previous practice , In this paper, the author proposes X-VLM, Use the above data in a unified way to efficiently learn multi granularity visual and language alignment , It can avoid high overhead target detection process , Nor is it limited to learning image level or object level alignment . say concretely , The author suggests that the Vision Transformer Of patch embeddings To flexibly represent the visual concepts of various particle sizes , Pictured 1(c) Shown : for example , Visual concepts “backpack” from 2 individual patch form , And the visual concept “man crossing the street” By more patch form .
therefore ,X-VLM The secret to learning multi granularity visual and language alignment is :
1) Use patch embeddings To flexibly represent visual concepts of various granularity , Then directly pull together the visual concepts and corresponding texts of different granularity , This process uses the commonly used comparative learning loss 、 Match loss 、 and MLM Loss optimization ;
2) Further more , In the same picture , Give different texts , The model is required to predict the coordinates of the visual concept corresponding to the granularity , Optimization with regression loss and intersection union ratio loss of boundary box coordinates . Experimental proof , This pre training method Very efficient , The scale of the model does not need to be very large , Pre training data does not need a lot ,X-VLM It can be understood in multiple modes downstream / Excellent performance on generation tasks .
Method

X-VLM By an image encoder , A text encoder , A cross modal encoder consists of .
chart 2 The visual concept is given on the left ( It can be an object / Area / picture ) The coding process : The image encoder is based on Vision Transformer, Divide the input picture into patch code . then , Give any bounding box , Flexible access to all... In the box patch The average value of the representation obtains the global representation of the region . Then compare the global representation with all in the original box patch Means to arrange into a sequence according to the original order , As the representation of the visual concept corresponding to the bounding box . Get the picture itself in this way (I) And visual concepts in pictures (V1,V2,V3) The coding . Text corresponding to visual concepts , One by one by text encoder , For example, picture title 、 Area description 、 Or object labels .
X-VLM Adopt the common model structure , The difference lies in the method of pre training . The author optimizes through the following two types of losses :
First of all , In the same picture , Give different texts , for example :T(text)、T1(text1)、T2(text2)、T3(text3), The model is required to predict the bounding box of the corresponding visual concept in the picture :

![]()
![]() Is the cross modal encoder in [CLS] The output vector of the position .Sigmoid The function is to standardize the bounding box of prediction .Ground-truth bj Corresponding , In turn are the standardized abscissa of the center 、 Center ordinate 、 wide 、 high . Last , This loss is the regression loss of the bounding box coordinates (L1) Compare losses with each other (GIoU) The sum of the . The author thinks that in the same picture , Give different words , The model is required to predict the corresponding visual concept , It can make the model learn multi granularity visual language alignment more effectively . This loss is also the first time it has been used in multimodal pre training .
Is the cross modal encoder in [CLS] The output vector of the position .Sigmoid The function is to standardize the bounding box of prediction .Ground-truth bj Corresponding , In turn are the standardized abscissa of the center 、 Center ordinate 、 wide 、 high . Last , This loss is the regression loss of the bounding box coordinates (L1) Compare losses with each other (GIoU) The sum of the . The author thinks that in the same picture , Give different words , The model is required to predict the corresponding visual concept , It can make the model learn multi granularity visual language alignment more effectively . This loss is also the first time it has been used in multimodal pre training .
second , Use patch embeddings To flexibly represent visual concepts of various granularity , Then directly optimize the model to pull together different granularity text and visual concepts , Including objects / Area / Alignment of picture and text . The author uses three common loss optimization methods in multimodal pre training , In turn, is :
1) Compare learning loss :



![]() ,
,![]() yes ground-truth Similarity degree , The diagonal to 1, Others are 0.
yes ground-truth Similarity degree , The diagonal to 1, Others are 0.
![]() ,
, ![]() It is the similarity calculated by the model based on the output of text encoder and image encoder .
It is the similarity calculated by the model based on the output of text encoder and image encoder .
2) Match loss :

pmatch It is based on the calculation of cross modal encoder , Forecast given Whether it matches ( let me put it another way ,0/1 classification ). For each positive example , The author sampled a pair of negative cases .
3)Masked Language Modeling Loss :

T( Estimated value ) Some words in have been randomly replaced with [MASK],pj(V, T( Estimated value )) It's a cross modal encoder in the word tj The probability distribution of thesaurus calculated by the output vector of position .
The final optimization loss Namely, the above several loss Add up :

experiment
The author uses the medium-sized model commonly used in multimodal pre training 4M and 16M Experiment with image data set , As shown in the following table :

among , mark (# Ann) Is the sum of area labels and object labels . It can be seen that , Some datasets don't have picture titles , for example Visual Genome(VG), Some datasets have no picture labels , for example CC-3M/12M.

surface 2 It shows the task of image text retrieval (MSCOCO and Flickr30K) Performance on . Even if , The previous methods are pre trained on a larger amount of internal data or have a larger model scale , stay 4M Training under picture data set X-VLM You can go beyond the previous methods .
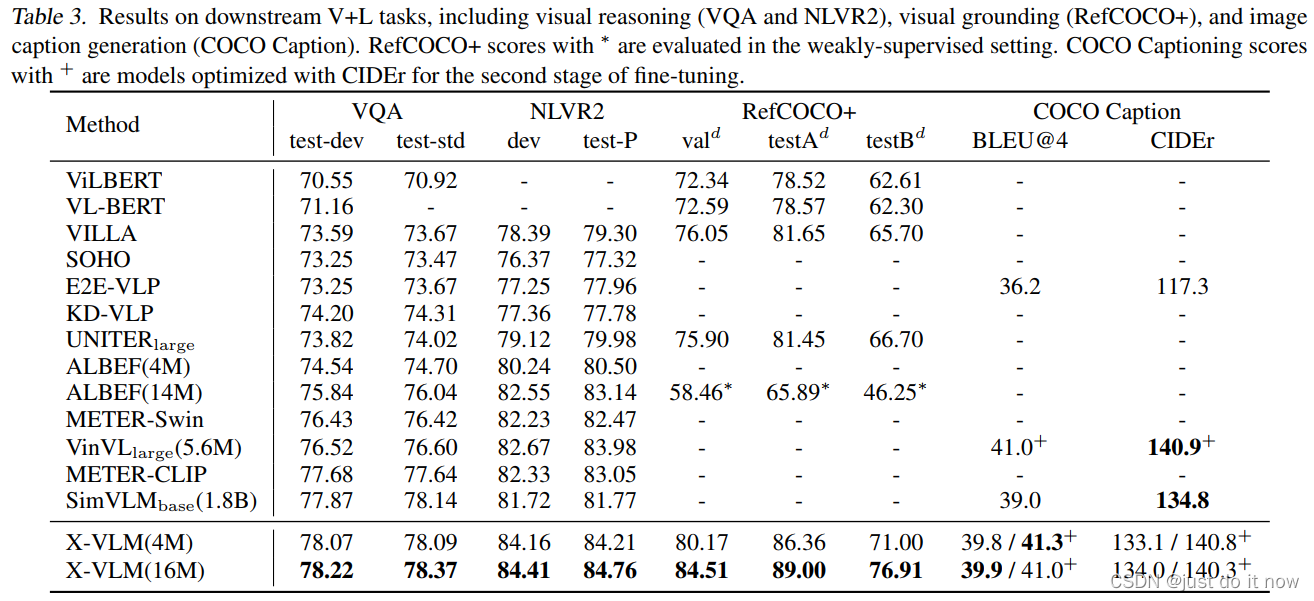
surface 3 Demonstrated in visual reasoning (VQA2.0 and NLVR2)、 Visual positioning (RefCOCO+) 、 Picture description generation (COCO Caption) Model performance on . For a fair comparison ,X-VLM It follows the previous work fine-tune Method , No additional adjustments have been made . Combine tables 2 And table 3, It can be seen that , Compared with the previous method ,X-VLM Support more kinds of downstream tasks , And in these common visual language tasks have achieved very good performance .
Summarize and discuss
In this paper , The author puts forward X-VLM To learn multi granular visual and language alignment , It can avoid high overhead target detection process , Nor is it limited to learning image level or object level alignment .X-VLM The secret to success is :
1) be based on patch embeddings Flexible presentation of visual concepts of various granularity , Then directly pull together the visual concepts and corresponding texts of different granularity ;
2) Further more , In the same picture , Give different texts , The model is required to predict the coordinates corresponding to the visual concept . Experiments show that this pre training method is very efficient .
In the experimental part , The author uses the commonly used 4M and 16M data , Total training parameters 216M Of X-VLM , It can surpass a larger scale model or a model using a large amount of pre training data , In the downstream multi-modal understanding / Excellent performance on generation tasks .
边栏推荐
- [untitled]
- Delete dictionary from list
- What if the service in Nacos cannot be deleted?
- Method of measuring ripple of switching power supply
- Calculation of decoupling capacitance
- buuresevewp
- What is the five levels of cultivation of MES management system
- Idea auto Guide
- X-VLM多模态模型解读
- Mapping '/var/mobile/Library/Caches/com.apple.keyboards/images/tmp.gcyBAl37' failed: 'Invalid argume
猜你喜欢
![[postgraduate entrance examination] group planning: interrupted](/img/ec/1f3dc0ac22e3a80d721303864d2337.jpg)
[postgraduate entrance examination] group planning: interrupted

Reflection example of ads2020 simulation signal

Discrete device ~ resistance capacitance

Chapter VI (pointer)

RF filter

Database learning notes I

Fabrication of modulation and demodulation circuit

The difference between push-pull circuit drive and totem pole drive

. eslintrc. JS configuration

buuresevewp
随机推荐
Database learning notes II
Pic 10B parsing
JMeter performance testing - Basic Concepts
GHUnit: Unit Testing Objective-C for the iPhone
Interview JS and browser
Monitor iPad Keyboard Display and hide events
Fabrication of modulation and demodulation circuit
Baoyan postgraduate entrance examination interview - operating system
Golang collaboration and channel usage
optee中的timer代码导读
I want to open a stock account at a discount. How do I do it? Is it safe to open a mobile account?
Example of offset voltage of operational amplifier
Uniapp uses uviewui
Interview for postgraduate entrance examination of Baoyan University - machine learning
How to Use Instruments in Xcode
HEVC学习之码流分析
Use middleware to record slow laravel requests
Getting started with idea
[postgraduate entrance examination] group planning exercises: memory
ASP. Net and Net framework and C #