当前位置:网站首页>X-VLM多模态模型解读
X-VLM多模态模型解读
2022-06-26 08:13:00 【just do it now】
论文:https://arxiv.org/abs/2111.08276
代码:https://github.com/zengyan-97/X-VLM
研究背景

现有的多模态预训练模型大致分为两类:
1)依赖目标检测器提取基于物体(例如:车、人、树、背包)的特征来表示图片,这种方法可以学习到物体级别的视觉和语言对齐,如图1中(a)所示。这些方法要么直接利用预先训练的目标检测器,要么将目标检测过程合并到多模态预训练中;
2)用 ResNet 或者 Vision Transformer 编码整张图片,只学习图片和文本之间的对齐,如图1(b)所示。
这两种方法都存在一定的问题。首先,基于目标检测的方法会识别图片中所有可能的物体,其中不乏一些与配对文本无关的。此外,这种方法所提取的基于物体的视觉特征可能会丢失物体之间的信息(可以认为是一种上下文信息)。而且,这种方法只能识别有限种类的物体,我们很难预先定义合适的物体类别。而第二种方法则比较简单直接,但是较难学习到细粒度的视觉和语言对齐,例如:物体级别的对齐。这种细粒度的对齐关系被之前的工作证实对于视觉推理 (visual reasoning) 和视觉定位 (visual grounding) 任务很有帮助。
实际上,对于多模态预训练,有以下公开数据以供模型使用:1)图片和图片标题;2)区域标注,例如:图1中的文本 “man crossing the street” 关联到了图片中的某个具体区域。然而,之前的工作却粗略地将区域标注与整张图片对齐;3)物体标签,例如 “backpack”,这些标注被之前的工作用来训练目标检测器。
与之前的做法不同,本文中作者提出X-VLM,以统一的方式利用上述数据高效地学习多粒度的视觉和语言对齐,能够避免高开销的目标检测过程,也不局限于学习图像级别或物体级别的对齐。具体来说,作者提出可以使用基于 Vision Transformer 的 patch embeddings 来灵活表示各种粒度大小的视觉概念,如图1(c)所示:例如,视觉概念 “backpack” 由2个patch组成,而视觉概念 “man crossing the street” 由更多的patch组成。
因此,X-VLM学习多粒度视觉和语言对齐的秘诀在于:
1)使用 patch embeddings 来灵活表示各种粒度的视觉概念,然后直接拉齐不同粒度的视觉概念和对应文本,这一过程使用常用的对比学习损失、匹配损失、和MLM损失优化;
2)更进一步,在同一张图片中,给出不同的文本,要求模型能预测出对应粒度的视觉概念的坐标,以边界框坐标的回归损失和交并比损失优化。实验证明,这种预训练方法十分高效,模型规模无需很大,预训练数据无需很多,X-VLM 就能在下游多种多模态理解/生成任务上获得非常优秀的表现。
方法

X-VLM 由一个图像编码器,一个文本编码器,一个跨模态编码器组成。
图2左侧给出了视觉概念 (可以是物体/区域/图片)的编码过程:该图像编码器基于Vision Transformer,将输入图片分成patch编码。然后,给出任意一个边界框,灵活地通过取框中所有patch表示的平均值获得区域的全局表示。再将该全局表示和原本框中所有的patch表示按照原本顺序整理成序列,作为该边界框所对应的视觉概念的表示。通过这样的方式获得图片本身(I)和图片中视觉概念(V1,V2,V3)的编码。与视觉概念对应的文本,则通过文本编码器一一编码获得,例如图片标题、区域描述、或物体标签。
X-VLM采用常见的模型结构,其不同之处在于预训练的方法。作者通过以下两类损失进行优化:
第一,在同一张图片中,给出不同的文本,例如:T(text)、T1(text1)、T2(text2)、T3(text3),要求模型预测图片中对应视觉概念的边界框:

![]()
![]() 是跨模态编码器在 [CLS] 位置的输出向量。Sigmoid 函数是为了标准化预测的边界框。Ground-truth bj对应了 ,依次是标准化后的的中心横坐标、中心纵坐标、宽、高。最后,该损失是边界框坐标的回归损失(L1)和交并比损失(GIoU)之和。作者认为在同一张图片中,给不同文字,要求模型预测出对应的视觉概念,能使模型更有效地学习到多粒度的视觉语言对齐。该损失也是首次被使用在多模态预训练中。
是跨模态编码器在 [CLS] 位置的输出向量。Sigmoid 函数是为了标准化预测的边界框。Ground-truth bj对应了 ,依次是标准化后的的中心横坐标、中心纵坐标、宽、高。最后,该损失是边界框坐标的回归损失(L1)和交并比损失(GIoU)之和。作者认为在同一张图片中,给不同文字,要求模型预测出对应的视觉概念,能使模型更有效地学习到多粒度的视觉语言对齐。该损失也是首次被使用在多模态预训练中。
第二,使用patch embeddings来灵活表示各种粒度的视觉概念,然后直接优化模型去拉齐不同粒度的文本和视觉概念,包括了物体/区域/图片与文本的对齐。作者使用多模态预训练中常见的三个损失优化,依次是:
1)对比学习损失:



![]() ,
,![]() 是ground-truth相似度, 对角线为1,其余为0。
是ground-truth相似度, 对角线为1,其余为0。
![]() ,
, ![]() 是模型基于文字编码器输出和图像编码器输出所计算的相似度。
是模型基于文字编码器输出和图像编码器输出所计算的相似度。
2)匹配损失:

pmatch是基于跨模态编码器计算,预测所给 对是否匹配(换句话说,0/1分类)。对于每对正例,作者采样一对负例。
3)Masked Language Modeling损失:

T(估计值)中的一些词已经被随机替换成了 [MASK],pj(V, T(估计值))是跨模态编码器在词tj位置的输出向量所计算的词表概率分布。
最终优化loss即上述几个loss相加:

实验
作者使用多模态预训练中常见的中等规模的4M和16M图片数据集进行实验,如下表所示:

其中,标注(# Ann)是区域标注和物体标签的总和。可以看出,有些数据集没有图片标题,例如Visual Genome(VG),有些数据集没有图片标注,例如CC-3M/12M。

表2展示了在图像文本检索任务 (MSCOCO和Flickr30K) 上的表现。即使,之前的方法在更大量的内部数据上预训练或者模型规模更大,在4M图片数据集下训练的X-VLM就已经可以超过之前的方法。
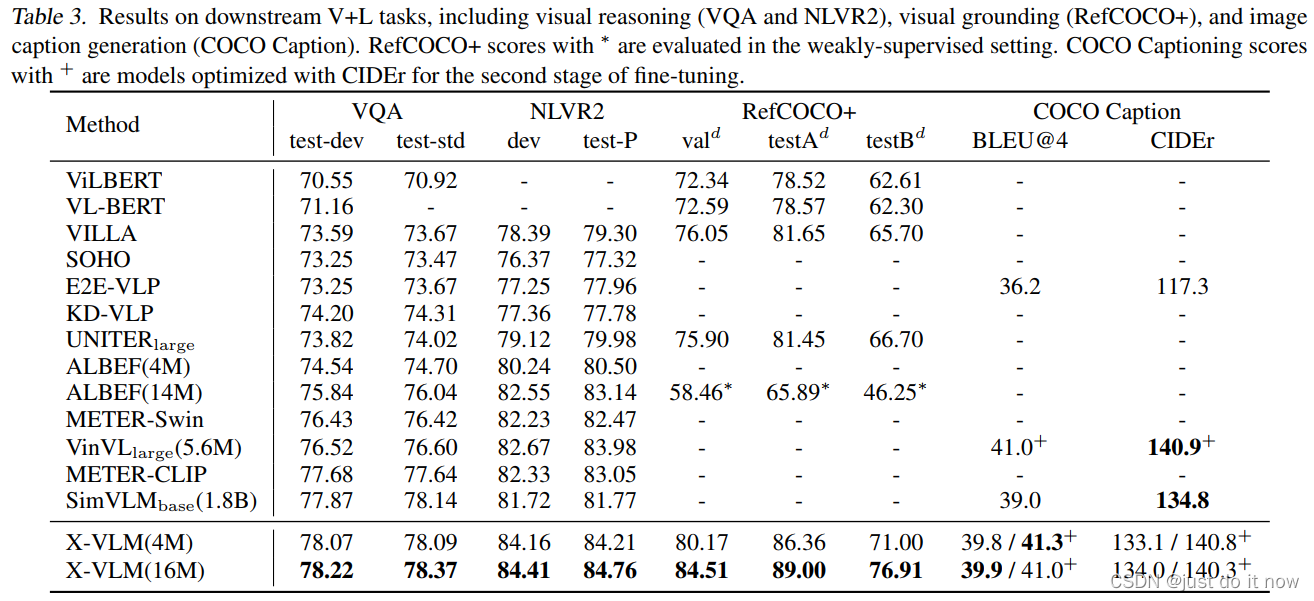
表3展示了在视觉推理 (VQA2.0和NLVR2)、视觉定位 (RefCOCO+) 、图片描述生成 (COCO Caption) 上的模型表现。为了公平的对比,X-VLM 沿用了之前工作的 fine-tune 方法,没有进行额外的调整。结合表2和表3,可以看出,相比之前的方法,X-VLM支持更多种类的下游任务,并且在这些常见的视觉语言任务上都取得了十分优秀的表现。
总结和讨论
在本文中,作者提出了X-VLM以学习多粒度的视觉和语言对齐,能够避免高开销的目标检测过程,也不局限于学习图像级别或物体级别的对齐。X-VLM 的秘诀在于:
1)基于 patch embeddings 灵活表示各种粒度的视觉概念,然后直接拉齐不同粒度的视觉概念和对应文本;
2)更进一步,在同一张图片中,给出不同的文本,要求模型能预测出对应视觉概念的坐标。实验证实这种预训练方法十分高效。
在实验部分,作者使用常用的4M和16M数据,训练总参数量216M的 X-VLM ,就能超过更大规模的模型或使用大量预训练数据的模型,在下游多种多模态理解/生成任务上取得非常优秀的表现。
边栏推荐
- Use intent to shuttle between activities -- use explicit intent
- h5 localStorage
- QT之一个UI里边多界面切换
- (vs2019 MFC connects to MySQL) make a simple login interface (detailed)
- Solve the problem that pychar's terminal cannot enter the venv environment
- swift 代码实现方法调用
- Google Earth engine (GEE) 01- the prompt shortcut ctrl+space cannot be used
- Uploading pictures with FileReader object
- buuresevewp
- Opencv鼠标事件+界面交互之绘制矩形多边形选取感兴趣区域ROI
猜你喜欢

Idea uses regular expressions for global substitution

JS Date object

Google Earth engine (GEE) 02 basic knowledge and learning resources

Quickly upload data sets and other files to Google colab ------ solve the problem of slow uploading colab files

The difference between setstoragesync and setstorage

Chapter VII (structure)

MySQL query time period

MySQL insert Chinese error
![[industry cloud talk live room] tomorrow afternoon! Focus on digital intelligence transformation of the park](/img/20/05f0a2dfb179a89188fbb12605370c.jpg)
[industry cloud talk live room] tomorrow afternoon! Focus on digital intelligence transformation of the park
![[postgraduate entrance examination] group planning exercises: memory](/img/ac/5c63568399f68910a888ac91e0400c.png)
[postgraduate entrance examination] group planning exercises: memory
随机推荐
PyTorch-12 GAN、WGAN
MySQL practice: 1 Common database commands
Google Earth engine (GEE) 02 basic knowledge and learning resources
Project management learning
Leetcode topic [array] -11- containers with the most rainwater
MFC writes a suggested text editor
buuresevewp
Chapter II (summary)
Ora-12514: tns: the listener currently does not recognize the service requested in the connection descriptor
Detailed explanation and code implementation of soft voting and hard voting mechanism in integrated learning
ECE 9203/9023 analysis
What if the service in Nacos cannot be deleted?
Software engineering - high cohesion and low coupling
Record the dependent installation problems encountered in building the web assets when developing pgadmin
2022 ranking of bank financial products
Bluebridge cup 1 introduction training Fibonacci series
Uniapp uses uviewui
PCB miscellaneous mail
Blue Bridge Cup 3 sequence summation
Understanding of closures