当前位置:网站首页>Practice brings true knowledge: the strongest seckill system architecture in the whole network is decrypted. Not all seckills are seckills!!
Practice brings true knowledge: the strongest seckill system architecture in the whole network is decrypted. Not all seckills are seckills!!
2022-06-22 22:40:00 【m0_ fifty-four million eight hundred and fifty-three thousand f】
Hello everyone , I'm glacier ~~
A lot of partners said that , I have studied high concurrency for so long , however , In the real project , Still don't know how to deal with high concurrency business scenarios ! Even many of the partners are still simply providing interfaces (CRUD) Stage , I don't know how the learned concurrent knowledge can be applied to the actual project , Not to mention how to build a highly concurrent system !
What kind of system is a high concurrency system ? today , Let's decrypt the architecture of a typical seckill system in high concurrency business scenarios , Combined with other articles under the topic of high concurrency , Put this to use .
E-commerce system architecture
In the field of e-commerce , There are typical seckill business scenarios , What's the second kill scene . Simply put, the number of people who buy a product is far greater than the inventory of the product , And this product will be sold out in a very short time . Like every year 618、 double 11 Great promotion , Xiaomi new product promotion and other business scenarios , It's a typical seckill business scenario .
We can simplify the architecture of the e-commerce system as shown in the figure below .

As shown in the figure , We can simply divide the core layer of e-commerce system into : Load balancing layer 、 Application layer and persistence layer . Next , We estimate the concurrency of each layer .
If the load balancing layer uses high performance Nginx, Then we can estimate Nginx The maximum concurrency is :10W+, Here is the unit of ten thousand .
Suppose the application layer we use is Tomcat, and Tomcat The maximum concurrency can be estimated as 800 about , Here is the unit of 100 .
Suppose the cache of persistence layer uses Redis, The database USES MySQL,MySQL The maximum concurrency can be estimated as 1000 about , In thousands .Redis The maximum concurrency can be estimated as 5W about , In 10000 .
therefore , Load balancing layer 、 The concurrency of application layer and persistence layer is different , that , In order to improve the overall concurrency and cache of the system , What solutions can we usually adopt ?
(1) System expansion
System expansion includes vertical expansion and horizontal expansion , Increase equipment and machine configuration , Most scenarios work .
(2) cache
Local cache or centralized cache , Reduce network IO, Read data based on memory . Most scenarios work .
(3) Read / write separation
Use read-write separation , Divide and rule , Increase the parallel processing capacity of the machine .
Features of seckill system
For the second kill system , We can Business and technology Two angles to elaborate some of its own characteristics .
Business characteristics of seckill system
here , We can use 12306 Website for example , Every year during the Spring Festival ,12306 The number of visits to the website is very large , But the website usually visits is relatively gentle , in other words , Every Spring Festival ,12306 There will be a sudden increase in the number of visits to the website .
Another example , Xiaomi second kill system , In the morning 10 Order for sale ,10 The traffic before the point is relatively flat ,10 At the same time, there will be a sudden increase in concurrent amount .
therefore , Second kill system traffic and concurrency, we can use the following figure to show .

As can be seen from the figure , The concurrency of seckill system has the characteristics of instantaneous bump , It's also called flow spike .
We can summarize the characteristics of the second kill system as follows .

(1) Time limit 、 limited 、 Fixed price
Within a specified time ; The number of goods in the second kill is limited ; The price of goods will be much lower than the original price , in other words , In the second kill , The goods will be sold at a much lower price .
for example , The time of seckill is limited to one morning 10 Point to 10 Half past six , The quantity of goods is only 10 Thousands of pieces of , Until it's sold out , And the price of goods is very low , for example :1 Yuan purchase and other business scenarios .
Time limit 、 Limits and limits can exist alone , It can also be combined .
(2) Warm up the activity
Activities need to be configured in advance ; Before the event started , Users can view information about the event ; Before the second kill , Vigorously promote the event .
(3) Short duration
The number of people buying is huge ; The goods will be sold out quickly .
In terms of system traffic presentation , There will be a spike , At this time, the concurrent access is very high , In most seckill scenarios , The goods will be sold out in a very short time .
Technical characteristics of second kill system
We can summarize the technical characteristics of the second kill system as follows .

(1) The amount of instantaneous concurrency is very high
A large number of users will rush to buy goods at the same time ; The instantaneous concurrency peak is very high .
(2) Read more and write less
The number of visits to the product page in the system is huge ; The quantity of goods available for purchase is very small ; The number of query visits to inventory is far greater than the number of goods purchased .
Some current limiting measures are often added to the product page , For example, the early seckill system product page will add verification code to smooth the front-end access to the system traffic , The product details page of the recent seckill system will be opened when the user opens the page , Prompt the user to log in to the system . These are some measures to restrict the access of the system .
(3) The process is simple
Second kill system business process is generally relatively simple ; In general , The business process of seckill system can be summarized as : Order less stock .
Second kill three stages
Usually , From the beginning to the end of the second kill , There are often three stages :
- Preparation stage : This phase is also called system warm-up phase , At this time, the business data of seckill system will be preheated in advance , Usually at this time , Users will constantly refresh the seckill page , To see if the second kill has started . Up to a point , Through the user constantly refresh the page operation , You can store some data in Redis To preheat .
- Second kill stage : This stage is mainly the process of seckill activities , Will produce instantaneous high concurrent traffic , There will be a huge impact on system resources , therefore , In the second kill stage, we must do a good job in system protection .
- Settlement stage : Finish the data processing after the second kill , For example, data consistency problem processing , Exception handling , Return of goods to warehouse .
For such a system with large traffic in a short period of time , It is not suitable to use the system to expand the capacity , Because even if the system is expanded , That is to say, the expanded system will be used in a very short time , Most of the time , The system can be accessed normally without capacity expansion . that , What solutions can we take to improve the second kill performance of the system ?
Seckill system solution
According to the characteristics of the second kill system , We can take the following measures to improve the performance of the system .

(1) Asynchronous decoupling
Take the whole process apart , The core process is controlled by queue .
(2) Limit current and prevent brush
Control the overall traffic of the website , Raise the threshold of requests , Avoid running out of system resources .
(3) Resource control
Control the resource scheduling in the whole process , Foster strengths and circumvent weaknesses .
Because the amount of concurrency that the application layer can carry is much less than that of the cache . therefore , In high concurrency systems , We can use it directly OpenResty The cache is accessed by the load balancing layer , The performance loss of calling application layer is avoided . You can go to https://openresty.org/cn/ To learn more about OpenResty More knowledge . meanwhile , Because of the second kill system , The quantity of goods is relatively small , We can also use dynamic rendering technology ,CDN Technology to speed up website access performance .
If at the start of the second kill , When the concurrency is too high , We can put the user's request in the queue for processing , And pop up the queuing page for users .

notes : The picture is from Meizu
Second kill system sequence diagram
There are many seckill systems on the Internet and the solutions to them , It's not really a second kill system , They're just using a scheme of synchronous processing of requests , Once concurrency does come up , The performance of their so-called second kill system will drop sharply . Let's take a look at the sequence diagram of the seckill system when placing an order synchronously .
Synchronous order process

1. The user initiates a seckill request
In the synchronous order process , First , The user initiates a seckill request . The mall service needs to execute the following process to process the business of seckill request in turn .
(1) Whether the identification verification code is correct
The mall service judges whether the verification code submitted when the user initiates the seckill request is correct .
(2) Judge whether the activity has ended
Verify that the current seckill activity has ended .
(3) Verify that the access request is on the blacklist
In the field of e-commerce , There is a lot of malicious competition , in other words , Other businesses may maliciously request the second kill system through improper means , It takes up a lot of bandwidth and other system resources . here , We need to use risk control system to achieve blacklist mechanism . For simplicity , You can also use interceptor to count the visit frequency to realize the blacklist mechanism .
(4) Verify that the actual inventory is sufficient
The system needs to verify whether the real inventory of goods is sufficient , Whether it can support the inventory of this seckill activity .
(5) Deduct the inventory in the cache
In the seckill business , Often store information such as inventory in the cache , here , We also need to verify that the inventory of goods used by the seckill campaign is sufficient , And you need to reduce the inventory of seckill activities .
(6) Calculate the price of the second kill
Because in the second kill , There is a difference between the second killing price of commodities and the real prices of commodities , therefore , We need to calculate the second kill price of goods .
Be careful : If in the second kill scene , If the business involved in the system is more complex , More business operations will be involved , here , I'm just listing some common business operations .
2. place order
(1) Order entry
Save the order information submitted by the user to the database .
(2) Deduct the real stock
After the order is put into storage , You need to deduct the quantity of goods placed successfully this time from the real inventory of goods .
If we use the above process to develop a second kill system , When a user initiates a seckill request , Because each business process of the system is executed serially , Overall, the performance of the system will not be too high , When the concurrency is too high , We will pop up the following queuing page for users , To prompt the user to wait .
notes : The picture is from Meizu
The queue time may be 15 second , It could be 30 second , Even longer . There is a problem : During the period between the user initiating the seckill request and the server returning the result , The connection between the client and the server will not be released , This will take up a lot of server resources .
Many articles on the Internet about how to implement the second kill system are adopted in this way , that , Can you do the second kill system in this way ? The answer is that you can do , But the amount of concurrency supported by this method is not too high . here , Some netizens may ask : This is what our company does with the second kill system ! I've been using it since I went online , No problem ! What I want to say is : The use of synchronous order can really do second kill system , But the performance of synchronous order will not be too high . The reason why your company uses synchronous order to do the second kill system does not appear big problem , That's because the concurrency of your seckill system doesn't reach a certain level of magnitude , in other words , The concurrency of your seckill system is not high .
therefore , Many so-called second kill systems , There's a second kill business , But it's not really a second kill system , The reason is that they use a synchronous order process , It limits the concurrent traffic of the system . The reason why there are not too many problems after online , Because the concurrency of the system is not high , Not enough to crush the whole system .
If 12306、 TaoBao 、 Tmall 、 JD.COM 、 Xiaomi and other large shopping mall's second kill system is so play , that , Sooner or later, their systems will die , It's strange that their systems engineers don't get fired ! therefore , In the second kill system , It is not advisable to synchronize the business process of an order .
The above is the whole process operation of synchronous order , If the order process is more complicated , More business operations will be involved .
Asynchronous order process
Since the synchronous single process of the second kill system can not be called a real second kill system , Then we need to adopt asynchronous order process . The asynchronous single process will not limit the high concurrent traffic of the system .

1. The user initiates a seckill request
After the user initiates the seckill request , Mall service will go through the following business process .
(1) Check whether the verification code is correct
When a user initiates a seckill request , The verification code will be sent together , The system will verify that the captcha is valid , And whether it's right .
(2) Whether the current limit
The system will judge whether the user's request is limited or not , here , We can judge by the length of the message queue . Because we put the user's request in the message queue , The message queue is stacked with user requests , According to the number of pending requests in the current message queue, we can judge whether the user's request needs to be limited .
for example , In the second kill , We sell 1000 Commodity , At this point, there is... In the message queue 1000 A request , If there is still a user sending a second kill request , We can stop processing subsequent requests , Return the prompt that the product is sold out directly to the user .

therefore , After using current limiting , We can process user requests more quickly and release connected resources .
(3) send out MQ
After the user's seckill request has passed the previous verification , We can send the user's request parameters and other information to MQ Asynchronous processing in , meanwhile , Respond the result information to the user . In the mall service , There will be a dedicated asynchronous task processing module to consume requests in the message queue , And deal with subsequent asynchronous processes .
When a user initiates a seckill request , An asynchronous order process processes fewer business operations than a synchronous order process , It will follow up the operation through MQ Send to asynchronous processing module for processing , And quickly return the response results to the user , Release request connection .
2. Asynchronous processing
We can asynchronously process the following operations of the order process .
(1) Judge whether the activity has ended
(2) Judge whether the request is in the system blacklist , In order to prevent malicious competition from peers in e-commerce field, blacklist mechanism can be added to the system , Put malicious requests on the system's blacklist . You can use interceptors to count the frequency of visits .
(3) Deduct the inventory quantity of seckill goods in the cache .
(4) Generate second kill Token, This Token It binds the current user to the current seckill activity , Only the second kill is generated Token To be eligible for seckill .
Here we introduce asynchronous processing mechanism , In asynchronous processing , How much resources the system uses , How many threads are allocated to handle the corresponding tasks , It can be controlled .
3. Short polling query seconds kill results
here , Can take the client short polling query whether to obtain the seckill qualification scheme . for example , The client can every 3 Second polling request server , Check whether you are qualified for seckill , here , Our processing in the server is to determine whether the current user has a second kill Token, If the server generates a second kill for the current user Token, Then the current user has the seckill qualification . Otherwise, continue polling , Until the timeout or the server returns the information that the product has been sold out or no seckill qualification .
When short polling is used to query the result of seconds killing , On the page, we can also prompt the user that the queue is being processed , But at this time, the client will poll the server every few seconds to check the status of seckill qualification , Compared to the synchronous order process , No need to take a long time to request connection .
here , Some netizens may ask : Short polling query is adopted , Will it exist until the timeout can not query whether it has the status of seckill qualification ? The answer is : There may be ! Here, let's imagine the real scene of the second kill , Businesses participate in the seckill activity is not essentially to make money , It's about increasing the sales of goods and the popularity of merchants , Attract more users to buy their own products . therefore , We don't have to guarantee that users can 100% Query whether you have the status of seckill qualification .
4. Second kill settlement
(1) Verify order Token
When client submits seckill settlement , Will kill seconds Token Submit to the server together , Mall service will verify the current seckill Token Whether it works .
(2) Join the seckill shopping cart
Mall service is verifying seckill Token After it's legal and valid , Will add user's products to the secar shopping cart .
5. place order
(1) Order warehousing
Save the order information submitted by the user to the database .
(2) Delete Token
After the order is successfully put into storage , Delete seckill Token.
Here you can think about a problem : Why do we only use asynchronous processing in the pink part of the asynchronous order process , And there is no asynchronous peak cutting and valley filling measures in other parts ?
This is because in the design of asynchronous order flow , Whether in product design or interface design , We limit the current of user's request in the stage of user's request , so to speak , The current limiting operation of the system is very advanced . When the user initiates the seckill request, the current is limited , The peak traffic of the system has been smoothed out , Go back , In fact, the system concurrency and system traffic is not very high .
therefore , Many articles and posts on the Internet introduce the second kill system , It is said that asynchronous peak shaving is used to carry out some current limiting operations when placing an order , That's all bullshit ! Because the single operation in the whole process of the second kill system belongs to the later operation , The current limiting operation must be preprocessed , In the process after the second kill business, it is useless to do current limiting operation .
High concurrency “ Black science and technology ” And winning tricks
hypothesis , In the second kill system, we use Redis Implementing caching , hypothesis Redis The concurrency of read and write is in 5 All around . The concurrency that our mall second kill business needs to support is in 100 All around . If this 100 All the concurrency of Wan is entered Redis in ,Redis It's probably going to hang up , that , How can we solve this problem ? Next , Let's discuss this problem together .
In a high concurrency seckill system , If the Redis Cache data , be Redis The concurrent processing ability of cache is the key , Because a lot of prefix operations need to access Redis. Asynchronous peak shaving is only a basic operation , The key is to make sure Redis The concurrent processing power of .
The key idea to solve this problem is : Divide and rule , Open up the inventory of goods .
The sucker
We are Redis When the inventory quantity of seckill goods is stored in , The inventory of seckill goods can be carried out “ Division ” Store to improve Redis Read and write concurrency of .
for example , The original second kill commodity id by 10001, Inventory is 1000 Pieces of , stay Redis The storage in is (10001, 1000), We split the original stock into 5 Share , Then each stock is 200 Pieces of , here , We are Redia The information stored in is (10001_0, 200),(10001_1, 200),(10001_2, 200),(10001_3, 200),(10001_4, 200).
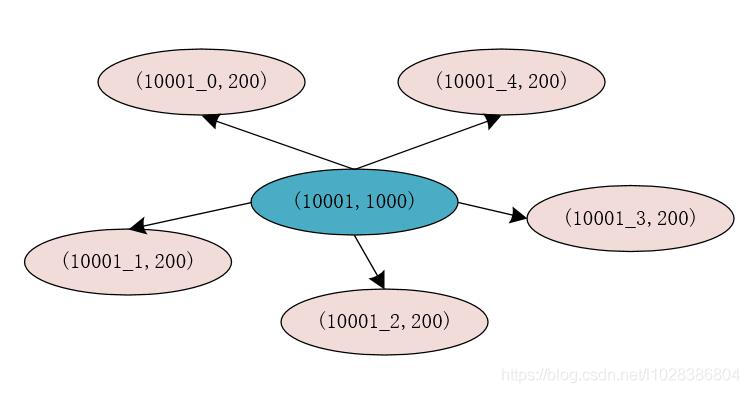
here , After we split the inventory , Each split inventory uses merchandise id Add a digital ID to store , such , In the storage of goods in the inventory of each Key Conduct Hash Operation time , It is concluded that the Hash The result is different , This means that , To store goods in stock Key There is a high probability that it will not be Redis In the same slot of , This can improve Redis The performance and concurrency of processing requests .
After splitting the inventory , We still need to Redis Store a product in id And after the split stock Key The mapping relation of , At this point, the mapping relation of Key For commodities id, That is to say 10001,Value To store inventory information after splitting inventory Key, That is to say 10001_0,10001_1,10001_2,10001_3,10001_4. stay Redis We can use List To store these values .
When dealing with inventory information , We can start from Redis All the split inventory corresponding to the seckill product is found in Key, Use at the same time AtomicLong To record the current number of requests , Use the number of requests for from Redia All of the split inventory corresponding to the seckill products found in Key The length of , The result is 0,1,2,3,4. Then put the goods on the front id You can get the real inventory cache of Key. here , That's what this is Key Direct to Redis Get the corresponding inventory information from the .
Substitute stealthily
In a high concurrency business scenario , We can use it directly Lua Script library (OpenResty) Access the cache directly from the load balancing layer .
here , Let's think about a scene : If in the seckill business scenario , The second kill goods are sold out in an instant . here , When a user initiates a second kill request again , If the system requests services from the application layer by the load balancing layer , The cache and database are accessed by various services in the application layer , Actually , It doesn't make any sense at all , Because the goods are sold out , Then through the application layer of the system for layer by layer verification has not much meaning !! The concurrent access of the application layer is in the unit of 100 , This will reduce the concurrency of the system to a certain extent .
To solve this problem , here , We can take out the users carried by users when sending requests in the load balancing layer of the system id, goods id And the second kill id Etc , Directly through Lua Script and other technologies to access the inventory information in the cache . If the inventory of seckill goods is less than or equal to 0, Then it will directly return the prompt message that the product has been sold out , Instead of going through the layer by layer verification of the application layer . For this architecture , We can refer to the architecture of the e-commerce system in this article ( The first picture at the beginning of the text ).
Redis Help the second kill system
We can do it in Redis Design a Hash data structure , To support the deduction of goods inventory , As shown below .
seckill:goodsStock:${goodsId}{
totalCount:200,
initStatus:0,
seckillCount:0
}
In our design Hash In the data structure , There are three very important attributes .
- totalCount: Represents the total number of products involved in the second kill , Before the second kill , We need to load this value into Redis In cache .
- initStatus: We design this value as a Boolean value . Before the second kill , The value of 0, It means that the second kill has not started . It can be done by scheduled tasks or background operations , Change the value to 1, It means that the second kill begins .
- seckillCount: It means the number of goods killed in seconds , In the process of the second kill , The upper limit of this value is totalCount, When this value reaches totalCount when , It means that the product has been killed in seconds .
We can use the following code snippet in the seckill warm-up phase , The cache that will load the commodity data to participate in the seckill .
/**
* @author binghe
* @description Example of building commodity cache code before seckill
*/
public class SeckillCacheBuilder{
private static final String GOODS_CACHE = "seckill:goodsStock:";
private String getCacheKey(String id) {
return GOODS_CACHE.concat(id);
}
public void prepare(String id, int totalCount) {
String key = getCacheKey(id);
Map<String, Integer> goods = new HashMap<>();
goods.put("totalCount", totalCount);
goods.put("initStatus", 0);
goods.put("seckillCount", 0);
redisTemplate.opsForHash().putAll(key, goods);
}
}
When the second kill begins , We need to judge the cache first in the code seckillCount Is the value less than totalCount value , If seckillCount The value is really less than totalCount value , We can lock in inventory . In our program , These two steps are not atomic . If in a distributed environment , We operate through multiple machines at the same time Redis cache , There will be synchronization problems , And then cause “ Oversold ” The serious consequences of .
In the field of e-commerce , There is a professional term called “ Oversold ”. seeing the name of a thing one thinks of its function :“ Oversold ” That is to say, the quantity of goods sold is more than the quantity of goods in stock , This is a very serious problem in e-commerce . that , How do we solve “ Oversold ” The problem? ?
Lua Scripts perfectly solve the oversold problem
How can we solve the problem of multiple machines operating at the same time Redis What about the synchronization problem ? A better solution is to use Lua Script . We can use Lua The script will Redis The operation of reducing inventory in is encapsulated into an atomic operation , This ensures the atomicity of the operation , So as to solve the synchronization problem in high concurrency environment .
for example , We can write the following Lua Script code , To execute Redis The operation of deducting inventory in .
local resultFlag = "0"
local n = tonumber(ARGV[1])
local key = KEYS[1]
local goodsInfo = redis.call("HMGET",key,"totalCount","seckillCount")
local total = tonumber(goodsInfo[1])
local alloc = tonumber(goodsInfo[2])
if not total then
return resultFlag
end
if total >= alloc + n then
local ret = redis.call("HINCRBY",key,"seckillCount",n)
return tostring(ret)
end
return resultFlag
We can use the following Java Code to call the above Lua Script .
public int secKill(String id, int number) {
String key = getCacheKey(id);
Object seckillCount = redisTemplate.execute(script, Arrays.asList(key), String.valueOf(number));
return Integer.valueOf(seckillCount.toString());
}
such , When we're doing the second kill , To ensure the atomicity of the operation , So as to effectively avoid the problem of data synchronization , And effectively solve the problem “ Oversold ” problem .
In order to deal with the business scenario of high concurrency and large traffic of seckill system , In addition to the business architecture of the second kill system itself , We also need to further optimize the performance of the server hardware , Next , Let's take a look at how to optimize the performance of the server .
Optimize server performance
operating system
here , The operating system I use is CentOS 8, We can enter the following command to see the version of the operating system .
CentOS Linux release 8.0.1905 (Core)
For high concurrency scenarios , We mainly optimize the network performance of the operating system , And in the operating system , There are a lot of parameters about network protocols , Our optimization of server network performance , The main purpose is to tune these system parameters , In order to improve our application access performance .
system parameter
stay CentOS Operating system , We can view all the system parameters through the following command .
/sbin/sysctl -a
Part of the output is as follows .
There are too many parameters here , About a thousand , In high concurrency scenarios , It's impossible to tune all the parameters of the operating system . We pay more attention to network related parameters . If you want to get network related parameters , that , We first need to get the types of operating system parameters , The following command can get the types of operating system parameters .
/sbin/sysctl -a|awk -F "." '{print $1}'|sort -k1|uniq
The result of running the command is as follows .
abi
crypto
debug
dev
fs
kernel
net
sunrpc
user
vm

Among them net Type is the operating system parameter that we should pay attention to . We can get net Subtypes under types , As shown below .
/sbin/sysctl -a|grep "^net."|awk -F "[.| ]" '{print $2}'|sort -k1|uniq
The output result information is as follows .
bridge
core
ipv4
ipv6
netfilter
nf_conntrack_max
unix

stay Linux Operating system , These network related parameters can be found in /etc/sysctl.conf Modification in the document , If /etc/sysctl.conf These parameters do not exist in the file , We can do it on our own /etc/sysctl.conf Add these parameters to the file .
stay net In a subtype of type , The subtypes we need to focus on are :core and ipv4.
Optimize socket buffers
If the server's network socket buffer is too small , It will cause the application to read and write many times to finish the data processing , This will greatly affect the performance of our program . If the network socket buffer is set large enough , It can improve the performance of our program to a certain extent .
We can enter the following command on the server's command line , To get information about the server socket buffer .
/sbin/sysctl -a|grep "^net."|grep "[r|w|_]mem[_| ]"
The output result information is as follows .
net.core.rmem_default = 212992
net.core.rmem_max = 212992
net.core.wmem_default = 212992
net.core.wmem_max = 212992
net.ipv4.tcp_mem = 43545 58062 87090
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_mem = 87093 116125 174186
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096

among , with max、default、min The key words represent respectively : Maximum 、 Default and minimum values ; with mem、rmem、wmem The keywords are : Total memory 、 Receive buffer memory 、 Send buffer memory .
What needs to be noted here is : with rmem and wmem Keyword units are “ byte ”, With mem The unit of the keyword is “ page ”.“ page ” Is the smallest unit of memory managed by the operating system , stay Linux In the system , The default page is 4KB size .
How to optimize sending and receiving large files frequently
If in a high concurrency scenario , Need to send and receive large files frequently , How can we optimize the performance of the server ?
here , The system parameters we can modify are as follows .
net.core.rmem_default
net.core.rmem_max
net.core.wmem_default
net.core.wmem_max
net.ipv4.tcp_mem
net.ipv4.tcp_rmem
net.ipv4.tcp_wmem
here , Let's make an assumption , Let's assume that the system can give TCP Distribute 2GB Memory , The minimum value is 256MB, The pressure value is 1.5GB. Follow one page for 4KB To calculate , tcp_mem The minimum value of 、 Pressure value 、 The maximum values are 65536、393216、524288, The unit is “ page ” .
Suppose the average packet size per file is 512KB, Each socket's read / write buffer can hold at least 2 A packet , By default, it can accommodate 4 A packet , It can accommodate each other at most 10 A packet , Then we can work it out tcp_rmem and tcp_wmem The minimum value of 、 The default value is 、 The maximum values are 1048576、2097152、5242880, The unit is “ byte ”. and rmem_default and wmem_default yes 2097152,rmem_max and wmem_max yes 5242880.
notes : How these values are calculated will be described in detail later ~~
here , The other thing to note is that : The buffer exceeds 65535, Also need to net.ipv4.tcp_window_scaling Parameter set to 1.
After the above analysis , Our final system tuning parameters are as follows .
net.core.rmem_default = 2097152
net.core.rmem_max = 5242880
net.core.wmem_default = 2097152
net.core.wmem_max = 5242880
net.ipv4.tcp_mem = 65536 393216 524288
net.ipv4.tcp_rmem = 1048576 2097152 5242880
net.ipv4.tcp_wmem = 1048576 2097152 5242880
Optimize TCP Connect
If you know something about computer network, you know it ,TCP You need to go through “ Three handshakes ” and “ Four waves ” Of , It's also a slow start 、 The sliding window 、 A series of technical support for reliable transmission, such as packet sticking algorithm . although , These can guarantee TCP The reliability of the protocol , But sometimes it affects the performance of our program .
that , In high concurrency scenarios , How do we optimize TCP How about the connection? ?
(1) Turn off the gluing algorithm
If the user is sensitive to the time taken by the request , We need to be in TCP Add... To the socket tcp_nodelay Parameter to close the gluing algorithm , So that packets can be sent right away . here , We can also set net.ipv4.tcp_syncookies The parameter value of is 1.
(2) Avoid frequent creation and recycling of connection resources
Network connection creation and recycling is very performance intensive , We can close the idle connection 、 Reuse allocated connection resources to optimize server performance . Reusing the allocated connection resources is no stranger to you , image : Thread pool 、 Database connection pool is to reuse thread and database connection .
We can use the following parameters to turn off the idle connection of the server and reuse the allocated connection resources .
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time=1800
(3) Avoid sending packets repeatedly
TCP Support timeout retransmission mechanism . If the sender has sent the packet to the receiver , But the sender didn't get feedback , here , If the set time interval is reached , It will trigger TCP Timeout retransmission mechanism of . In order to avoid sending successful packets again , We need to transfer the server's net.ipv4.tcp_sack Parameter set to 1.
(4) Increase the number of server file descriptors
stay Linux Operating system , A network connection also takes up a file descriptor , More connections , The more file descriptors it takes . If the file descriptor is set smaller , It also affects the performance of our servers . here , We need to increase the number of server file descriptors .
for example :fs.file-max = 10240000, Indicates that the server can be opened at most 10240000 File .
At the end
If you want to enter a large factory , I want a promotion and a raise , Or I'm confused about my current job , You can communicate with me by private letter , I hope some of my experiences can help you ~~
Recommended reading :
- 《 From zero to hundreds of millions of users , How do I optimize step by step MySQL Database ?( Recommended collection )》
- 《 I further optimized the massive data proofreading system under 100 million traffic e-commerce business with multithreading , Performance is up again 200%!!( The whole process is dry , Recommended collection )》
- 《 I optimized the massive data proofreading system under the 100 million traffic e-commerce business with multithreading , The performance is improved directly 200%!!( The whole process is dry , Recommended collection )》
- 《 I use 10 This diagram summarizes the best learning route of concurrent programming !!( Recommended collection )》
- 《 A faster lock than read-write lock in high concurrency scenario , After reading it, I was completely convinced !!( Recommended collection )》
- 《 Summary of the most complete performance optimization of the whole network !!( Glacier spitting blood finishing , Recommended collection )》
- 《 It's over in three days MyBatis, Everybody, feel free to ask !!( Glacier spitting blood finishing , Recommended collection )》
- 《 I would like to advise those younger students who have just joined the work : If you want to enter a large factory , This knowledge of concurrent programming is something you must master ! Complete learning path !!( Recommended collection )》
- 《 I would like to advise those younger students who have just joined the work : If you want to enter a large factory , These are the core skills you have to master ! Complete learning path !!( Recommended collection )》
- 《 I would like to advise those younger students who have just joined the work : The earlier you know the basics of computers and operating systems, the better ! Ten thousand words is too long !!( Recommended collection )》
- 《 I spent three days developing a national game suitable for all ages , Support for playing music , Now open the complete source code and comments ( Recommended collection )!!》
- 《 I am the author of high concurrency programming with the hardest core in the whole network ,CSDN The most noteworthy blogger , Do you agree ?( Recommended collection )》
- 《 Five years after graduation , From the monthly salary 3000 To a million dollars a year , What core skills have I mastered ?( Recommended collection )》
- 《 I invaded the sister next door Wifi, Find out ...( Whole process actual combat dry goods , Recommended collection )》
- 《 Never try to “ Panda burning incense ”, see , I regret it !》
- 《 Tomb Sweeping Day secretly training “ Panda burning incense ”, As a result, my computer is panda “ Dedicated ”!》
- 《7.3 Ten thousand words liver explosion Java8 New characteristics , I don't believe you can finish it !( Recommended collection )》
- 《 What kind of experience is it to unplug the server during peak business hours ?》
- 《 The most complete network Linux Command summary !!( In the history of the most complete , Recommended collection )》
- 《 use Python I wrote a tool , Perfectly cracked MySQL!!( Recommended collection )》
- 《SimpleDateFormat Why classes are not thread safe ?( Six solutions are attached , Recommended collection )》
- 《MySQL 8 The three indexes added in , Directly to MySQL Take off , You don't even know !!( Recommended collection )》
- 《 Finish off Spring Source code , I open source this distributed caching framework !!( Recommended collection )》
- 《 100 million level traffic high concurrent second kill system Commodities “ Oversold ” 了 , Just because of the JDK There are two huge pits in the synchronization container !!( Record of stepping on the pit , Recommended collection )》
- 《 I would like to advise those younger students who have just joined the work : To learn concurrent programming well , You must pay attention to the pit of these concurrent containers !!( Recommended collection )》
Okay , That's all for today , Like it, guys 、 Collection 、 Comment on , Get up with one button three times in a row , I'm glacier , See you next time ~~

边栏推荐
- How to manage tasks in note taking software such as flowus and notation?
- [mavros] mavros startup Guide
- 【李沐】 如何读论文【论文精读】
- Rendu stéréo
- 自助圖書館系統-Tkinter界面和openpyxl錶格綜合設計案例
- 自助图书馆系统-Tkinter界面和openpyxl表格综合设计案例
- Dynamic tree + data table + pagination of spa project development
- 322. change exchange
- 【几何法视觉】4.2 分段线性变换
- Next permutation [give play to subjective initiative to discover laws]
猜你喜欢

5分钟快速上线Web应用和API(Vercel)

自助圖書館系統-Tkinter界面和openpyxl錶格綜合設計案例

In the third week of June, the main growth ranking list (BiliBili platform) of station B single feigua data up was released!

CyCa children's physique etiquette Shenzhen training results assessment successfully concluded

KDD'22 | 阿里: 基于EE探索的精排CTR预估
![[path planning] week 1: hodgepodge](/img/8b/d7c370b0deac33c41a72f8105ea357.png)
[path planning] week 1: hodgepodge

Developing salary management system based on C language course paper + source code and executable EXE file
Summary of just meal with 900W increase in playback and acclaim from station B users

Las point cloud data thinning in ArcGIS

考生必读篇 | PMP6月25日考试临近,需要注意什么?
随机推荐
Core and semiconductor "RF eda/ filter design platform" shines ims2022
考生必读篇 | PMP6月25日考试临近,需要注意什么?
Las point cloud create mesh
Rendu stéréo
Delphi SOAP WebService 服务器端多个 SoapDataModule 要注意的问题
Mysql8 installation and environment configuration
PMP Exam admission ticket problems and precautions in June, which must be read by candidates
How much do you know about the cause of amplifier distortion?
shell(34) : 时间
Query es page subscript exceeds 10000
Half optimized SQL
pycharm 配置远程连接服务器开发环境
SPA项目开发之首页导航+左侧菜单
SQL performance optimization method for interval retrieval
sitl_gazebo/include/gazebo_opticalflow_plugin.h:43:18: error: ‘TRUE’ was not declared in this scope
R language builds a binary classification model based on H2O package: using H2O GLM constructs regularized logistic regression model and uses H2O AUC value of AUC calculation model
[recommended by Zhihu knowledge master] castle in UAV - focusing on the application of UAV in different technical fields
欧洲的龙之城|国家地理全球最浪漫最安全的目的地
Several ways of redis persistence -- deeply parsing RDB
Basic MySQL database operations