当前位置:网站首页>分布式系统解决之道:目录、消息队列、事务系统及其他
分布式系统解决之道:目录、消息队列、事务系统及其他
2022-06-24 10:04:00 【华为云】
一、目录服务(ZooKeeper)
分布式系统是一个由很多进程组成的整体,这个整体中每个成员部分,都会具备一些状态,比如负载情况,对某些数据的掌握等等。而这些和其他进程相关的数据,在故障恢复、扩容缩容的时候变得非常重要。
简单的分布式系统,可以通过静态的配置文件来记录这些数据:进程之间的连接对应关系,它们的IP地址和端口等等。然而,一个自动化程度高的分布式系统,必然要求这些状态数据都是动态保存的。这样才能让程序自己去做容灾和负载均衡的工作。
一些程序员会专门自己编写一个DIR服务(目录服务),来记录集群中进程的运行状态。集群中进程会和这个DIR服务产生自动关联,这样在容灾、扩容、负载均衡的时候,就可以自动根据这些DIR服务里的数据,来调整请求的发送目地,从而达到绕开故障机器、或连接到新的服务器的操作。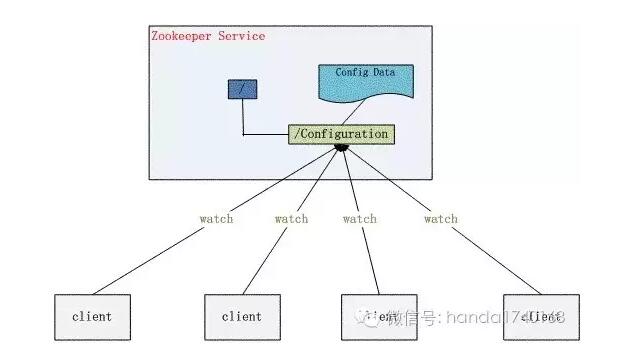
然而,如果只是用一个进程来充当这个工作,那么这个进程就成为了这个集群的“单点”——意思就是,如果这个进程故障了,那么整个集群可能都无法运行的(单点故障)。所以存放集群状态的目录服务也需要是分布式的。幸好有ZooKeeper这个优秀的开源软件,它正是一个分布式的目录服务器。
ZooKeeper可以简单启动奇数个进程,来形成一个小的目录服务集群。这个集群会提供给所有其他进程,进行读写其巨大的“配置树”的能力。这些数据不仅仅会存放在一个Zookeeper进程中,而是会根据一套非常安全的算法,让多个进程来承载。这让Zookeeper成为一个优秀的分布式数据保存系统。
由于Zookeeper的数据存储结构,是一个类似文件目录的树状系统,所以我们常常会利用它的功能,把每个进程都绑定到其中一个“分枝”上,然后通过检查这些“分支”,来进行服务器请求的转发,就能简单的解决请求路由(由谁去做)的问题。另外还可以在这些“分支”上标记进程的负载的状态,这样负载均衡也很容易做了。
目录服务是分布式系统中最关键的组件之一。而ZooKeeper是一个很好的开源软件,正好是用来完成这个任务。
二、消息队列服务(ActiveMQ、ZeroMQ、Jgroups)
两个进程间如果要跨机器通讯,我们几乎都会用TCP/UDP这些协议。但是直接使用网络API去编写跨进程通讯,是一件非常麻烦的事情。除了要编写大量的底层socket代码外,还要处理诸如:如何找到要交互数据的进程,如何保障数据包的完整性不至于丢失,如果通讯的对方进程挂掉了,或者进程需要重启应该怎样等等这一系列问题。这些问题包含了容灾扩容、负载均衡等一系列的需求。
为了解决分布式系统进程间通讯的问题,人们总结出一个有效的模型,就是“消息队列”模型。消息队列模型,就是把进程间的交互,抽象成对一个个消息的处理,而对于这些消息,都有一些“队列”,也就是管道,来对消息进行暂存。每个进程都可以访问一个或者多个队列,从里面读取消息(消费)或写入消息(生产)。由于有一个缓存的管道,可以放心地对进程状态进行变化。当进程起来的时候,它会自动去消费消息就可以了。而消息本身的路由,也是由存放的队列决定的,这样就把复杂的路由问题,变成了如何管理静态的队列的问题。
一般的消息队列服务,都是提供简单的“投递”和“收取”两个接口,但是消息队列本身的管理方式却比较复杂,一般来说有两种。一部分的消息队列服务,提倡点对点的队列管理方式:每对通信节点之间,都有一个单独的消息队列。这种做法的好处是不同来源的消息,可以互不影响,不会因为某个队列的消息过多,挤占了其他队列的消息缓存空间。而且处理消息的程序也可以自己来定义处理的优先级——先收取、多处理某个队列,而少处理另外一些队列。
但是这种点对点的消息队列,会随着集群的增长而增加大量的队列,这对于内存占用和运维管理都是一个复杂的事情。因此更高级的消息队列服务,开始可以让不同的队列共享内存空间,而消息队列的地址信息、建立和删除,都采用自动化的手段。——这些自动化往往需要依赖上文所述的“目录服务”,来登记队列的ID对应的物理IP和端口等信息。比如很多开发者使用ZooKeeper来充当消息队列服务的中央节点;而类似Jgropus这类软件,则自己维护一个集群状态来存放各节点信息。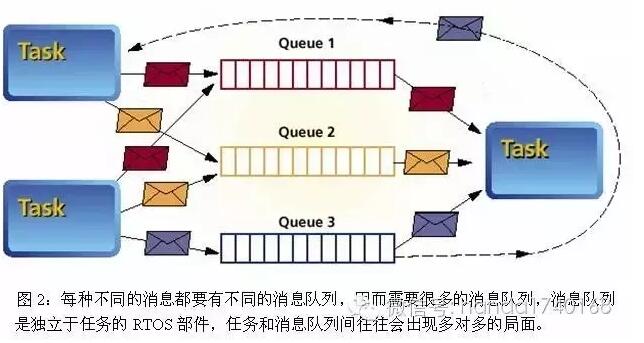
另外一种消息队列,则类似一个公共的邮箱。一个消息队列服务就是一个进程,任何使用者都可以投递或收取这个进程中的消息。这样对于消息队列的使用更简便,运维管理也比较方便。不**过这种用法下,任何一个消息从发出到处理,最少经过两次进程间通信,其延迟是相对比较高的。**并且由于没有预定的投递、收取约束,所以也比较容易出BUG。
不管使用哪种消息队列服务,在一个分布式服务器端系统中,进程间通讯都是必须要解决的问题,所以作为服务器端程序员,在编写分布式系统代码的时候,使用的最多的就是基于消息队列驱动的代码,这也直接导致了EJB3.0把“消息驱动的Bean”加入到规范之中。
三、事务系统
在分布式的系统中,事务是最难解决的技术问题之一。由于一个处理可能分布在不同的处理进程上,任何一个进程都可能出现故障,而这个故障问题则需要导致一次回滚。这种回滚大部分又涉及多个其他的进程。这是一个扩散性的多进程通讯问题。要在分布式系统上解决事务问题,必须具备两个核心工具:一个是稳定的状态存储系统;另外一个是方便可靠的广播系统。
事务中任何一步的状态,都必须在整个集群中可见,并且还要有容灾的能力。这个需求,一般还是由集群的“目录服务”来承担。如果我们的目录服务足够健壮,那么我们可以把每步事务的处理状态,都同步写到目录服务上去。Zookeeper再次在这个地方能发挥重要的作用。
如果事务发生了中断,需要回滚,那么这个过程会涉及到多个已经执行过的步骤。也许这个回滚只需要在入口处回滚即可(加入那里有保存回滚所需的数据),也可能需要在各个处理节点上回滚。如果是后者,那么就需要集群中出现异常的节点,向其他所有相关的节点广播一个“回滚!事务ID是XXXX”这样的消息。这个广播的底层一般会由消息队列服务来承载,而类似Jgroups这样的软件,直接提供了广播服务。
虽然现在我们在讨论事务系统,但实际上分布式系统经常所需的“分布式锁”功能,也是这个系统可以同时完成的。所谓的“分布式锁”,也就是一种能让各个节点先检查后执行的限制条件。如果我们有高效而原子操作的目录服务,那么这个锁状态实际上就是一种“单步事务”的状态记录,而回滚操作则默认是“暂停操作,稍后再试”。这种“锁”的方式,比事务的处理更简单,因此可靠性更高,所以现在越来越多的开发人员,愿意使用这种“锁”服务,而不是去实现一个“事务系统”。
四、自动部署工具(Docker)
**由于分布式系统最大的需求,是在运行时(有可能需要中断服务)来进行服务容量的变更:扩容或者缩容。**而在分布式系统中某些节点故障的时候,也需要新的节点来恢复工作。这些如果还是像老式的服务器管理方式,通过填表、申报、进机房、装服务器、部署软件……这一套做法,那效率肯定是不行。
**在分布式系统的环境下,我们一般都是采用“池”的方式来管理服务。**我们预先会申请一批机器,然后在某些机器上运行服务软件,另外一些则作为备份。显然我们这一批服务器不可能只为某一个业务服务,而是会提供多个不同的业务承载。那些备份的服务器,则会成为多个业务的通用备份“池”。随着业务需求的变化,一些服务器可能“退出”A服务而“加入”B服务。
这种频繁的服务变化,依赖高度自动的软件部署工具。我们的运维人员,应该掌握开发人员提供的部署工具,而不是厚厚的手册,来进行这类运维操作。**一些比较有经验的开发团队,会统一所有的业务底层框架,以期大部分的部署、配置工具都能用一套通用的系统来进行管理。**而开源界,也有类似的尝试,最广为人知的莫过于RPM安装包格式,然而RPM的打包方式还是太复杂,不太符合服务器端程序的部署需求。所以后来又出现了Chef为代表的可编程的通用部署系统。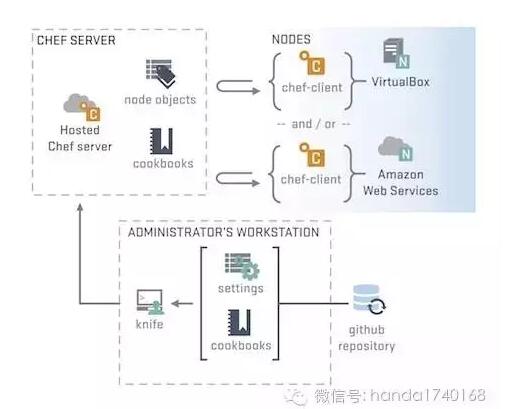
在虚拟机技术出现之后,PaaS平台为自动部署提供了强大的支持:如果我们是按某个PaaS平台的规范来编写的应用,可以完全把程序丢给平台去部署,其承载量计算、部署规划都自动完成了。这方面的佼佼者是Google的AppEngine:我们可以直接用Eclipse开发一个本地的Web应用,然后上传到AppEngine里面,所有的部署就完成了。AppEngine会自动的根据对这个Web应用的访问量,来进行扩容、缩容、故障恢复。
然而,真正有革命性的工具,是Docker的出现。虽然虚拟机、沙箱技术早就不是什么新技术,但是真正使用这些技术来作为***部署工具***的时间却不长。Linux高效的轻量级容器技术,提供了部署方面的便利性——可以在各种库、协作软件的环境下打包应用程序,然后随意的部署在任何一个Linux系统上。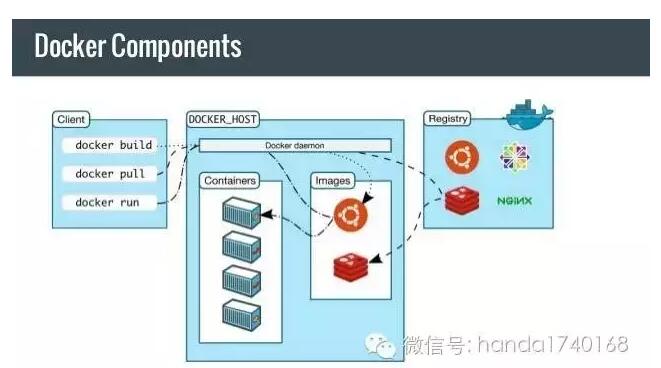
为了管理大量的分布式服务器端进程,我们确实需要花很多功夫,优化其部署管理的工作。统一服务器端进程的运行规范,是实现自动化部署管理的基本条件。我们可以根据“操作系统”作为规范,采用Docker技术;也可以根据“Web应用”作为规范,采用某些PaaS平台技术;或者自己定义一些更具体的规范,自己开发完整的分布式计算平台。
五、日志服务(log4j)
服务器端的日志,一直是一个既重要又容易被忽视的问题。很多团队在刚开始的时候,仅仅把日志视为开发调试、排除BUG的辅助工具。但是很快会发现,在服务运营起来之后,日志几乎是服务器端系统在运行时可以用来了解程序情况的唯一有效手段。
尽管我们有各种profile工具,但是这些工具大部分都不适合在正式运营的服务上开启,因为会严重降低其运行性能。所以我们更多的时候需要根据日志来分析。尽管日志从本质上就是一行行的文本信息,但是由于其具有很大的灵活性,所以会很受开发和运维人员的重视。
日志本身从概念上是一个很模糊的东西。你可以随便打开一个文件,然后写入一些信息。但是现代的服务器系统,一般都会对日志做一些标准化的需求规范:日志必须是一行一行的,这样比较方便日后的统计分析;每行日志文本,都应该有一些统一的头部,比如日期时间就是基本的需求;日志的输出应该是分等级的,比如fatal/error/warning/info/debug/trace等等,程序可以在运行时调整输出的等级,以便节省日志打印的消耗;日志的头部一般还需要一些类似用户ID或者IP地址之类的头信息,用于快速查找定位过滤某一批日志记录,或者有一些其他的用于过滤缩小日志查看范围的字段,这叫做染色功能;日志文件还需要有“回滚”功能,也就是保持固定大小的多个文件,避免长期运行后,把硬盘写满。
由于有上述的各种需求,所以开源界提供了很多游戏的日志组件库,比如大名鼎鼎的log4j,以及成员众多的log4X家族库,这些都是应用广泛而饱受好评的工具。
不过对比日志的打印功能,日志的搜集和统计功能却往往比较容易被忽视。作为分布式系统的程序员,肯定是希望能从一个集中节点,能搜集统计到整个集群日志情况。而有一些日志的统计结果,甚至希望能在很短时间内反复获取,用来监控整个集群的健康情况。要做到这一点,就必须有一个分布式的文件系统,用来存放源源不断到达的日志(这些日志往往通过UDP协议发送过来)。而在这个文件系统上,则需要有一个类似Map Reduce架构的统计系统,这样才能对海量的日志信息,进行快速的统计以及报警。有一些开发者会直接使用Hadoop系统,有一些则用Kafka来作为日志存储系统,上面再搭建自己的统计程序。
日志服务是分布式运维的仪表盘、潜望镜。如果没有一个可靠的日志服务,整个系统的运行状况可能会失控。所以无论你的分布式系统节点是多少,必须花费重要的精力和专门的开发时间,去建立一个对日志进行自动化统计分析的系统。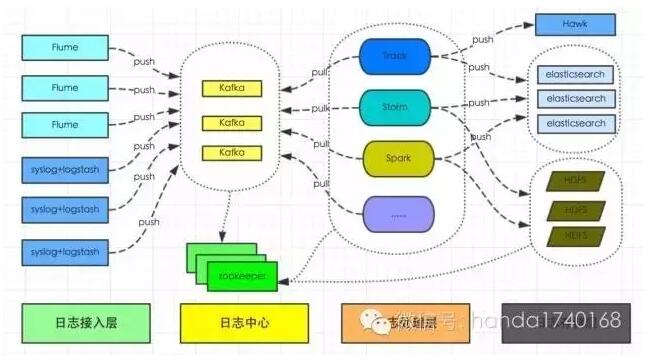
六、拓展阅读
边栏推荐
- Self cleaning Manual of mining Trojan horse
- Opencv optical flow prediction and remap remapping function usage
- Libuv的安装及运行使用
- Qt: 判断字符串是否为数字格式
- How to use data analysis tools to deal with emergencies in retail industry
- How to make a good video? What are the operation methods?
- Example of PHP observer mode [useful in the laravel framework]
- math_ Summation and derivation of proportional series & derivation of sum and difference of equal powers / difference between two nth power numbers/
- What is the function of the graphics card driver? Do you want to update the graphics card driver
- What code did the full stack programmer write this month?
猜你喜欢









随机推荐
Adobe Photoshop using the box selection tool for selection tutorial
How to use arbitrarygen code generator what are the characteristics of this generator
Beauty of script │ VBS introduction interactive practice
math_ Summation and derivation of proportional series & derivation of sum and difference of equal powers / difference between two nth power numbers/
What does ERP system mean
腾讯开源项目「应龙」成Apache顶级项目:前身长期服务微信支付,能hold住百万亿级数据流处理...
Does the depth system work?
[latest in the whole network] how to start the opentsdb source code in the local ide run
When the data security law comes, how can enterprises prepare for a rainy day? Tencent security has something to say
Smart energy: scenario application of intelligent security monitoring technology easycvr in the petroleum energy industry
What is the function of the graphics card driver? Do you want to update the graphics card driver
喜歡就去行動
What characteristics should a good design website have?
[深度学习][pytorch][原创]crnn在高版本pytorch上训练loss为nan解决办法
Why use a firewall? What is the function of firewall?
@RequestBody注解
Turn 2D photos into 3D models to see NVIDIA's new AI "magic"!
使用Process Monitor工具监测进程对注册表和文件的操作
Redis
Step 3: access the API interface for inquiry of SF express doc No. [express 100api interface]