当前位置:网站首页>Take you through the normalization flow of GaN
Take you through the normalization flow of GaN
2022-06-25 07:48:00 【Lattice titanium Engineer】
Hand in hand to get you started GAN Of Normalizing Flow
author :Aryansh Omray, Microsoft Data Science Engineer ,Medium Technology Blogger
A basic problem in the field of machine learning is how to learn the representation of complex data .
The importance of this task lies in , There are a lot of unstructured and unlabeled data , Only through unsupervised learning can we understand . Density estimation 、 Anomaly detection 、 Text summary 、 Data clustering 、 Bioinformatics 、DNA Modeling and other applications need to complete this task .
these years , Researchers have invented many methods to learn the probability distribution of large data sets , Including generating countermeasure networks (GAN)、 Variational self encoder (VAE) and Normalizing Flow etc. .
This article will introduce Normalizing Flow This is to overcome GAN and VAE The proposed method .

Glow Sample output of the model (Source)
GAN and VAE Your ability is already amazing , They can learn very complex data distribution through simple reasoning methods .
However ,GAN and VAE Lack of accurate evaluation and reasoning of probability distribution , This often leads to VAE The quality of fuzzy results in is not high ,GAN Training also faces challenges such as pattern collapse and post collapse .
therefore ,Normalizing Flow emerge as the times require , This paper attempts to solve the current problem by using reversible functions GAN and VAE There are many problems .
Normalizing Flow
In short ,Normalizing Flow Is a series of invertible functions , In other words, the analytical inverses of these functions can be calculated . for example ,f(x)=x+2 Is a reversible function , Because each input has and only one unique output , And vice versa , and f(x)=x² Is not a reversible function . Such functions are also called bijective functions .

Source Author
As can be seen from the above figure ,Normalizing Flow Complex data points can be ( Such as MNIST Image in ) Into a simple Gaussian distribution , vice versa . and GAN What's very different is ,GAN The input is a random vector , And the output is an image , Based on flow (Flow) The model is to convert data points into simple distribution . In the picture above MNIST In one case , We take random samples from Gaussian distribution , Can regain its corresponding MNIST Images .
The flow based model is trained using a negative logarithmic likelihood loss function , among p(z) It's a probability function . The following loss function is obtained by using the variable change formula in Statistics .

(Source)
Normalizing Flow The advantages of
And GAN and VAE comparison ,Normalizing Flow It has various advantages , Include :
- Normalizing Flow The model does not need to put noise in the output , Therefore, there can be a more powerful local variance model (local variance model);
- And GAN comparison , The training process of flow based model is very stable ,GAN You need to carefully adjust the super parameters of the generator and discriminator ;
- And GAN and VAE comparison ,Normalizing Flow It's easier to converge .
Normalizing Flow Deficiency
Although the flow based model has its advantages , But they also have some disadvantages :
- The performance of flow based model in tasks such as density estimation is not satisfactory ;
- The flow based model requires that the transformed volume be preserved (volume preservation over transformations), This often leads to very high-dimensional potential space , It usually leads to poor interpretation ;
- The samples generated by flow based models usually do not GAN and VAE Good. .
Just to understand Normalizing Flow, We use Glow Take architecture as an example to explain .Glow yes OpenAI stay 2018 A flow based model proposed in . The following figure shows Glow The architecture of .
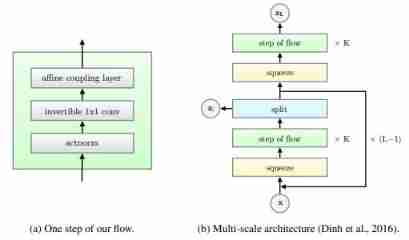
Glow The architecture of (Source)
Glow The architecture consists of multiple layers (superficial layers) It's a combination of . First let's take a look Glow Multiscale framework of the model .Glow The model consists of a series of repeating layers ( Named scale ) form . Each scale includes an extrusion function and a flow step , Each flow step contains ActNorm、1x1 Convolution and Coupling Layer, After the flow step is the partition function . The split function divides the input into two equal parts in the channel dimension . Half of them go into the next layer , The other half goes into the loss function . Segmentation is to reduce the effect of gradient disappearance , The gradient disappears in the model in an end-to-end manner (end-to-end) During training .
As shown in the figure below , Squeeze function (squeeze function) By transversely reshaping the tensor , Will be the size of [c, h, w] The input tensor of is converted to a size of [4c, h/2, w/2] Tensor . Besides , Reshaping functions can be used in the testing phase , Will input [4c, h/2, w/2] Reshape to size [c, h, w] Tensor .

(Source)
Other layers , Such as ActNorm、1x1 Convolution and Affine Coupling layer , It can be understood from the following table . This table shows the functions of each layer ( Including forward and reverse ).
(Source)
Realization
In understanding Normalizing Flow and Glow After the basic knowledge of the model , We will show you how to use PyTorch Implement the model , And in MNIST Training on datasets .
Glow Model
First , We will use PyTorch and nflows Realization Glow framework . To save time , We use nflows Including the implementation of all layers .
import torch
import torch.nn as nn
import torch.nn.functional as F
from nflows import transforms
import numpy as np
from torchvision.transforms.functional import resize
from nflows.transforms.base import Transform
class Net(nn.Module):
def __init__(self, in_channel, out_channels):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channel, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 1),
nn.ReLU(inplace=True),
ZeroConv2d(64, out_channels),
)
def forward(self, inp, context=None):
return self.net(inp)
def getGlowStep(num_channels, crop_size, i):
mask = [1] * num_channels
if i % 2 == 0:
mask[::2] = [-1] * (len(mask[::2]))
else:
mask[1::2] = [-1] * (len(mask[1::2]))
def getNet(in_channel, out_channels):
return Net(in_channel, out_channels)
return transforms.CompositeTransform([
transforms.ActNorm(num_channels),
transforms.OneByOneConvolution(num_channels),
transforms.coupling.AffineCouplingTransform(mask, getNet)
])
def getGlowScale(num_channels, num_flow, crop_size):
z = [getGlowStep(num_channels, crop_size, i) for i in range(num_flow)]
return transforms.CompositeTransform([
transforms.SqueezeTransform(),
*z
])
def getGLOW():
num_channels = 1 * 4
num_flow = 32
num_scale = 3
crop_size = 28 // 2
transform = transforms.MultiscaleCompositeTransform(num_scale)
for i in range(num_scale):
next_input = transform.add_transform(getGlowScale(num_channels, num_flow, crop_size),
[num_channels, crop_size, crop_size])
num_channels *= 2
crop_size //= 2
return transform
Glow_model = getGLOW()
We can use various data sets to train Glow Model , Such as MNIST、CIFAR-10、ImageNet etc. . This article is for the convenience of demonstration , It uses MNIST Data sets .
image MNIST Such data sets can be easily extracted from ** Grid titanium open dataset platform obtain , The platform contains all the commonly used open data sets in machine learning , Such as classification 、 Density estimation 、 Object detection and text-based classification data set .
To access the dataset , We just need to create an account on the platform of Gewu titanium , You can do it directly fork The data set you want , You can directly download or use the... Provided by grid titanium pipeline Import dataset . The basic code and related documents can be found in TensorBay** On the support page of .

Combined lattice titanium TensorBay Of Python SDK, We can easily import MNIST Data set to PyTorch in :
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from tensorbay import GAS
from tensorbay.dataset import Dataset as TensorBayDataset
class MNISTSegment(Dataset):
def __init__(self, gas, segment_name, transform):
super().__init__()
self.dataset = TensorBayDataset("MNIST", gas)
self.segment = self.dataset[segment_name]
self.category_to_index = self.dataset.catalog.classification.get_category_to_index()
self.transform = transform
def __len__(self):
return len(self.segment)
def __getitem__(self, idx):
data = self.segment[idx]
with data.open() as fp:
image_tensor = self.transform(Image.open(fp))
return image_tensor, self.category_to_index[data.label.classification.category]
model training
Model training can simply start with the following code . The code uses grid titanium TensorBay Provided Pipeline Create data loader , Among them ACCESS_KEY Can be in TensorBay Get... From your account settings .
from nflows.distributions import normal
ACCESS_KEY = "Accesskey-*****"
EPOCH = 100
to_tensor = transforms.ToTensor()
normalization = transforms.Normalize(mean=[0.485], std=[0.229])
my_transforms = transforms.Compose([to_tensor, normalization])
train_segment = MNISTSegment(GAS(ACCESS_KEY), segment_name="train", transform=my_transforms)
train_dataloader = DataLoader(train_segment, batch_size=4, shuffle=True, num_workers=4)
optimizer = torch.optim.Adam(Glow_model.parameters(), 1e-3)
for epoch in range(EPOCH):
for index, (image, label) in enumerate(train_dataloader):
if index == 0:
image_size = image.shaape[2]
channels = image.shape[1]
image = image.cuda()
output, logabsdet = Glow_model._transform(image)
shape = output.shape[1:]
log_z = normal.StandardNormal(shape=shape).log_prob(output)
loss = log_z + logabsdet
loss = -loss.mean()/(image_size * image_size * channels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch:{
epoch+1}/{
EPOCH} Loss:{
loss}")
The code above uses MNIST Data sets , To use other data sets, we can directly replace the data loader of the data set .
Sample generation
After the model training , We can generate the sample through the following code :
samples = Glow_model.sample(25)
display(samples)
Use nflows After the library , We only need one line of code to generate the sample , and display Function can display the generated sample in a grid .

use MNIST Examples generated after training the model
Conclusion
This article introduces Normalizing Flow Basic knowledge of , And with GAN and VAE Made a comparison , At the same time, it shows you Glow The basic working mode of the model . We also explained how to simply implement Glow Model , And use MNIST Data sets are trained . With the help of grid titanium open dataset platform , Data set access becomes very convenient .
【 About lattice titanium 】
Gewu titanium Intelligent Technology Focus on building new infrastructure of artificial intelligence , Through unstructured data platforms and open dataset communities , Help machine learning teams and individuals better unlock the potential of unstructured data , Give Way AI Faster application development 、 Better performance , Continue to empower artificial intelligence with thousands of lines and industries 、 Driving industrial upgrading 、 Promote the popularization of science and technology and build a solid foundation . At present, Sequoia has been obtained 、 Yunqi 、 True 、 Wind and 、 Yaotu capital and Qiji Chuangtan's ten million dollar investment .
边栏推荐
- How to select lead-free and lead-free tin spraying for PCB? 2021-11-16
- C#控件刷新
- Accès à la boîte aux lettres du nom de domaine Lead à l'étranger
- 【视频】ffplay 使用mjpeg格式播放usb摄像头
- Ca-is1200u current detection isolation amplifier has been delivered in batch
- Modular programming of digital light intensity sensor module gy-30 (main chip bh1750fvi) controlled by single chip microcomputer (under continuous updating)
- Tips on how to design soft and hard composite boards ~ 22021/11/22
- 单位转换-毫米转像素-像素转毫米
- 权限、认证系统相关名词概念
- Find out what informatization is, and let enterprises embark on the right path of transformation and upgrading
猜你喜欢

海思3559 sample解析:vio

权限、认证系统相关名词概念

Chuantu microelectronics ca-if1051 can-fd transceiver
Terms and concepts related to authority and authentication system

Chuantu microelectronics breaks through the high-end isolator analog chip market with ca-is3062w

Three years of continuous decline in revenue, Tiandi No. 1 is trapped in vinegar drinks

神经网络与深度学习-3- 机器学习简单示例-PyTorch

SCM Project Training

Elk + filebeat log parsing, log warehousing optimization, logstash filter configuration attribute

Summary of small problems in smartbugs installation
随机推荐
Cglib dynamic proxy
2160. 拆分数位后四位数字的最小和
个人域名和企业域名的区别
57. 插入区间
One "stone" and two "birds", PCA can effectively improve the dilemma of missing some ground points under the airborne lidar forest
权限、认证系统相关名词概念
微信小程序入门记录
C#入门教程
Mysql面试-执行sql响应比较慢,排查思路。
WinForm实现窗口始终在顶层
C#中如何调整图像大小
How to select lead-free and lead-free tin spraying for PCB? 2021-11-16
Static bit rate (CBR) and dynamic bit rate (VBR)
Hisilicon 3559 sample parsing: Vio
realsense d455 semantic_slam实现语义八叉树建图
China Mobile MCU product information
NPM install reports an error: gyp err! configure error
Lebel only wants an asterisk in front of it, but doesn't want to verify it
AttributeError: ‘Upsample‘ object has no attribute ‘recompute_ scale_ factor‘
Audio (V) audio feature extraction