当前位置:网站首页>In depth analysis of yolov7 network architecture
In depth analysis of yolov7 network architecture
2022-07-25 07:44:00 【Invincible Zhang Dadao】
In the US regiment yolov6 Just came out less than a month ,yolov4 Official troops of yolov7 Show up high-profile with papers and code , Quickly dominate the screen , Worship speed and accuracy :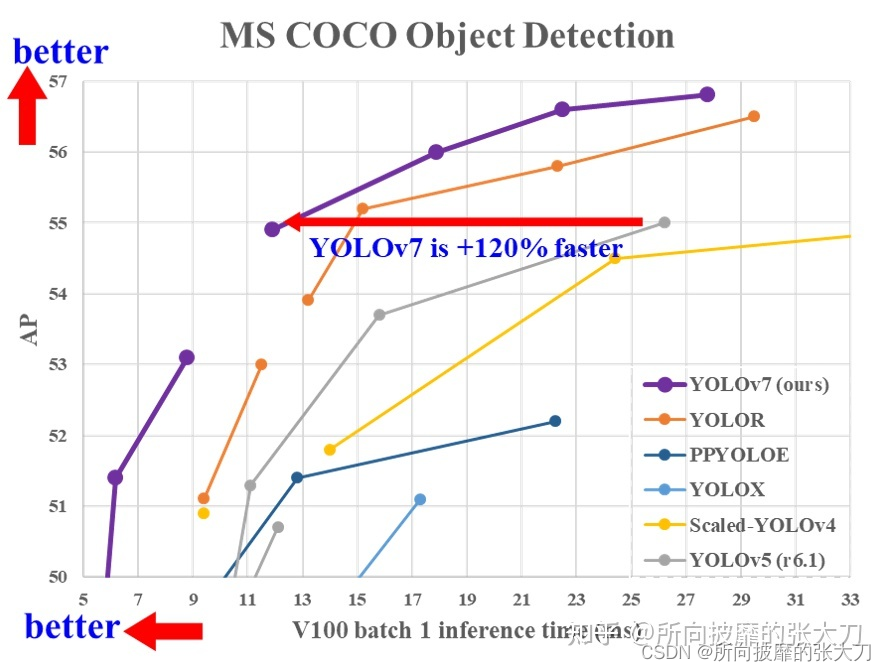
Four words “ Achieve greater, faster, better and more economical results ”,yolov7 Still based on anchor based Methods , At the same time, add E-ELAN layer , And will REP Layers are also added , Convenient for subsequent deployment , While training , stay head when , newly added Aux_detect Used for auxiliary detection , Personal understanding is a preliminary screening of the prediction results , Species two-stage The feeling of ( Welcome to face ).
Online based on yolov7 There are many interpretations of , At the end of the article will be attached yolov7 Of ariv Thesis connection and open source code github link . This article first shares with you the whole yolov7 The network architecture of ( be based on tag0.1 Version of yolov7L), Later, based on each module, I will share it with you according to my own understanding .
The overall framework
If you need something in the text ppt Use , Please click the link below , Official account , Add wechat in the background , receive , remarks “ppt”.
yolov7 In depth analysis of network architecture
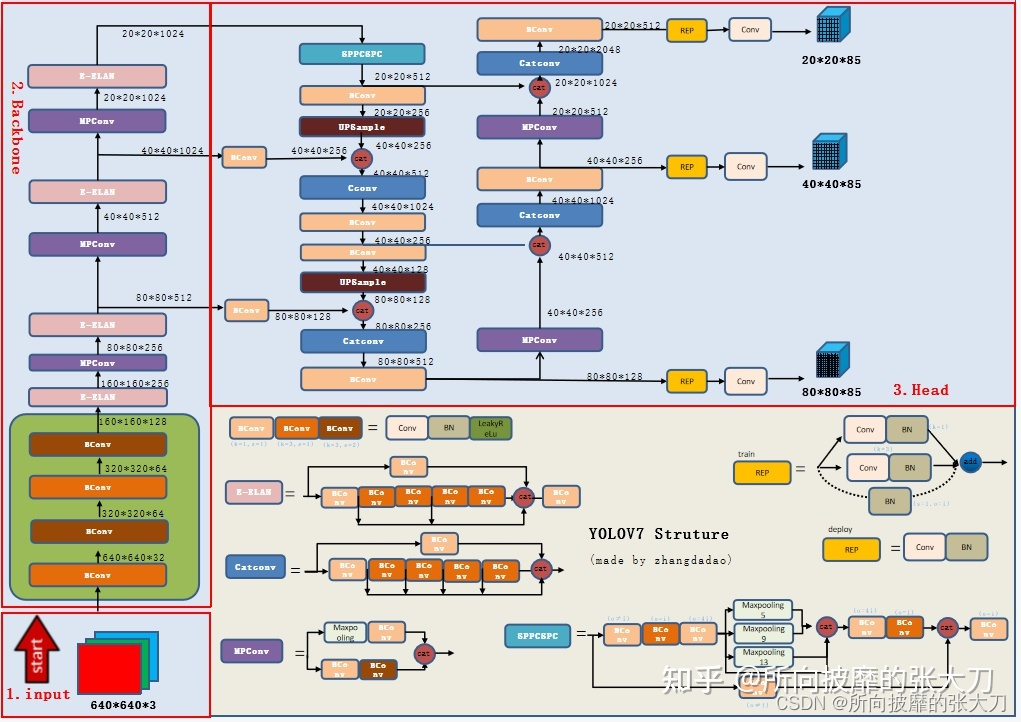
The above is yolov7 Overall network architecture , As you can see from the diagram yolov7 The network consists of three parts :input,backbone and head, And yolov5 The difference is , take neck Layer and head The lamination is called head layer , In fact, the functions are the same . For the functions of each part and yolov5 identical , Such as backbone For feature extraction ,head Used to predict .
Go through the network process according to the architecture diagram above : First preprocess the input picture , Alignment 640*640 The size of RGB picture , Input to backbone In the network , according to backbone Three layer output in the network , stay head Layers pass through backbone The network continues to output three different layers size The size of feature map( hereinafter referred to as fm), after RepVGG block and conv, Three kinds of tasks for image detection ( classification 、 Background classification before and after 、 Frame ) forecast , Output the final result .
backbone

yolov7 Of backbone The layer is shown in the figure above , By a number of BConv layer 、E-ELAN Layers and MPConv layers , among BConv Layers consist of convoluted layers +BN layer + The activation function consists of , stay tag0.1 The activation function in version is ReakyReLu.
Different colors of Bconv Representing convolution kernel Different ( following k Express kernel Length, width, size ,s Express stride, o by outchannel, i by inchannel, among o=i Express outchannel=inchannel, o≠i Express outchannel And inchannel No correlation , Its value is not necessarily equal ), The first is (k=1,s=1) Convolution of dot convolution kernel , The length and width of input and output remain unchanged , The second is (k=3,s=1) Convolution of convolution kernel , The length and width of the output remain the same , The third is s=2, The length and width of the output is half of the input . The above different colors Bconv Mainly for the purpose of distinguishing k and s, Do not distinguish between input and output channels .
E-ELAN Layers are also composed of different convolutions , As shown in the figure below :
Whole E-ELAN layer The length and width of input and output remain unchanged ,channel On o=2i, among 2i By 4 individual conv Layer output channel by i/2 Output concate Splicing into .
MPConv layer ( The name comes from itself , If there is actually a definite name , Welcome to chat privately and I will correct ) The process is as shown in the figure above , The input and output channels are the same , The output length and width is half of the input length and width , The upper branch passes maxpooling Halve the length and width , adopt BConv Halve the channel , The lower branch passes through the first BConv Halve the channel , Second k=3,s=2 Of Bconv Halve the length and width , Then branch up and down cat Merge , Get the length and width halved ,o=i Output .
Overview of the whole backbone The layer consists of several BConv layer 、E-ELAN Layers and MPConv The length and width of layers are halved alternately , Multiplier channel , The extracted features .
head

As shown in the figure above , Whole head Layers pass through SPPCPC layer 、 A number of BConv layer 、 A number of MPConv layer 、 A number of Catconv Layer and subsequent output head Of RepVGG block layers .
among SPPCPC layer Here's the picture : Whole SPPCSPC The output layer of layer channel by out_channel, In the calculation, the accountant calculates a hidden_channel = int(2eout_channel), Used to deal with hidden_channel( The following a general designation hc) expand , Usually take e=0.5, be hc=out_channel . The specific flow chart is as follows :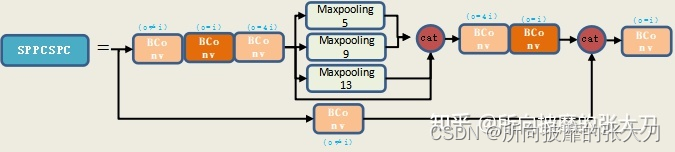
Catconv layer ( The name comes from itself , If there is actually a definite name , Welcome to chat privately and I will correct ) And E-ELAN The operation of layer is basically the same :
Whole Catconv The length and width of layer input and output remain unchanged ,channel On o=2i, among 2i By 6 individual conv Layer output channel by i/2 Output concate Splicing into .
REP layer namely repvgg_block layer , Deploy a friendly network layer for this year's super fire ,yolov6 It's also useful for :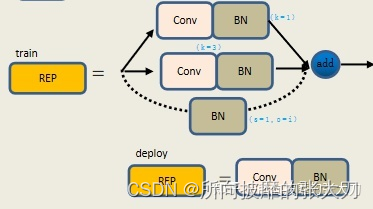
REP The structure is different during training and deployment , During the training, you should 33 Convolution addition of 11 Convolution branch of , At the same time, if the input and output channel as well as h,w Of size Consistent time , Add another BN The branch of , Add the three branches and output , At deployment time , For the convenience of deployment , It will reparameterize the parameters of the branch to the main branch , take 3*3 Main branch convolution output of .
Whole head The process of layer is , As shown in the above figure, output three feature map after , Through three separate REP and conv The layer outputs three different size Unprocessed prediction results of size .
The above is personal understanding , Look at the others yolov7 Network architecture , There will be DownC and ReOrg Two yolov7L Layers that do not appear in , among DownC Layer and MPConv Layers are similar :
ReOrg Layer and yolov5 The early focus The slicing principle of layers is the same . If there is any understanding deviation , Welcome to exchange , Follow up on yolov7 The detailed principles and codes in each module in continue to be updated , Hopefully that helped .
【yolov7 series 】 Disassemble the details of the network framework
Reference resources :
[1] https://github.com/WongKinYiu/yolov7( official github Code )
[2] https://arxiv.org/pdf/2207.02696.pdf(yolov7 The paper )
[3]https://www.zhihu.com/question/541985721
[4]YOLOv7 Official open source | Alexey Bochkovskiy Platform , Accuracy and speed exceed all YOLO, It has to be AB (qq.com)
[5] YOLOv7 coming : Detailed reading and analysis of the thesis (qq.com)
[6]【yolov6 series 】 Details disassemble the network framework (qq.com)
边栏推荐
- P1047 [noip2005 popularization group t2] tree outside the school gate
- [paper notes] progressive layered extraction (PLE): a novel multi task learning (MTL) model for personalized
- Introduction to cesium
- Competition path design of beacon group
- Huawei wireless device configuration wpa2-802.1x-aes security policy
- P1049 [noip2001 popularization group t4] packing problem
- 转行学什么成为了一大部分人的难题,那么为什么很多人学习软件测试呢?
- Leetcode (Sword finger offer) - 04. search in two-dimensional array
- [paper notes] next vit: next generation vision transformer for efficient deployment in real industry
- Network file storage system (II) practical operation of Minio distributed file system
猜你喜欢
![[dynamic programming] - Knapsack model](/img/0d/c467e70457495f130ec217660cbea7.png)
[dynamic programming] - Knapsack model

nanodet训练时出现问题:ModuleNotFoundError: No module named ‘nanodet‘的解决方法

Network file storage system (II) practical operation of Minio distributed file system

【Unity入门计划】基本概念-GameObject&Components

Teach you to use cann to convert photos into cartoon style

oracle 触发器创建
Matlab self programming series (1) -- angular distribution function

【软件测试】包装简历从这几点出发、提升通过率

A domestic open source redis visualization tool that is super easy to use, with a high-value UI, which is really fragrant!!
Teach you to use cann to convert photos into cartoon style
随机推荐
[unity introduction program] basic concepts GameObject & components
Load capacity - sorting out the mind map that affects load capacity
QT learning diary 20 - aircraft war project
Robot framework mobile terminal Automation Test ----- 01 environment installation
交叉熵计算公式
uiautomator2 常用命令
toolbar的使用
Kubernetes monitoring component metrics server deployment
diagramscene工程难点分析
People who lose weight should cry: it's no good not eating food, because your brain will be inflamed
12 combination methods and risk interpretation of database architecture optimization (books available)
【Unity入门计划】基本概念-预制件 Prefab
How to do a good job in safety development?
A review of nature: gender differences in anxiety and depression - circuits and mechanisms
QT学习日记20——飞机大战项目
Have you got the advanced usage of pytest?
Tips - prevent system problems and file loss
文件详细操作
[unity entry program] make my first little game
Summer Challenge harmonyos - slider slider for custom components