当前位置:网站首页>Break the memory wall with CPU scheme? Learn from PayPal stack to expand capacity, and the volume of missed fraud transactions can be reduced to 1/30
Break the memory wall with CPU scheme? Learn from PayPal stack to expand capacity, and the volume of missed fraud transactions can be reduced to 1/30
2022-06-25 03:45:00 【QbitAl】
Dream morning Xiao Xiao From the Aofei temple
qubits | official account QbitAI
Have to say ,Colossal-AI The training system, an open-source project, is rising fast .
stay “ You can't afford a big model without a dozen graphics cards ” The present , It simply uses only one consumer graphics card , It's a success 180 A big model with 100 million parameters .
No wonder every time a new version is released , Will dominate the list for several days in a row GitHub Popular first .

△ Use github-star-history drawing
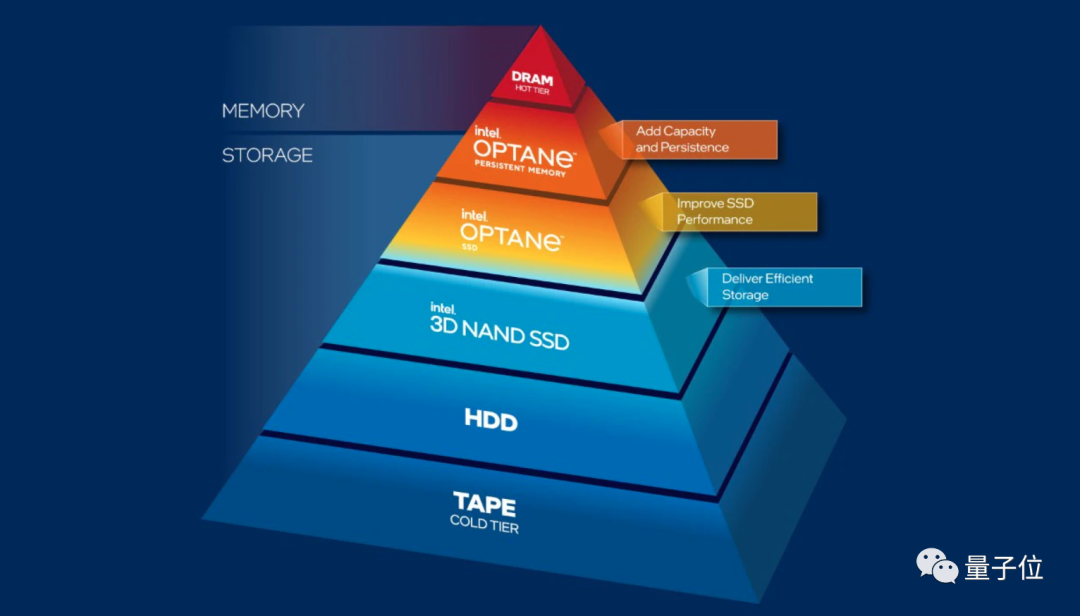
We also introduced ,Colossal-AI One of the key points is Breaking the memory wall limit , Such as training GPT-2 With NVIDIA's own Megatron-LM, comparison GPU Video memory can save up to 91.2%.
With AI The continuous growth of model parameters , The problem of insufficient memory is becoming more and more obvious , A word of CUDA out of memory It gives many practitioners a headache .
even to the extent that Berkeley AI Laboratory scholars Amir Gholami It was predicted a year ago , In the future, the memory wall will be a bigger bottleneck than computing power :
Memory capacity On ,GPU The capacity of single card video memory only doubles every two years , The model parameters that need support are close to exponential growth .
Transmission bandwidth On , In the past 20 Annual growth 30 times , It is far less than calculating power 20 Annual growth 9 Ten thousand times faster .
therefore , From inside the chip to between the chips , Even AI Data communication between accelerators , All hinder AI Further development and implementation .
To solve this problem , The whole industry is trying to find ways from different angles .
To break the memory wall , What efforts have the industry made ?
First , Start with the model algorithm itself to reduce the memory consumption .
Like Stanford & Proposed by the State University of New York at Buffalo FlashAttention, Add... To the attention algorithm IO Perceptual ability , Velocity ratio PyTorch standard Attention fast 2-4 times , The memory required is only its 5%-20%.

△arxiv.org/abs/2205.14135
And such as , The University of Tokyo & Shang Tang & The University of Sydney team proposed to layer ViT A new method integrated with mask image modeling . Memory usage is reduced compared with the previous method 70%.

△arxiv.org/abs/2205.13515
Similar studies are actually emerging in endlessly , Let's start with these two results published recently .
Although these individual methods are effective, their application is narrow , It is necessary to make targeted design according to different algorithms and tasks , Not very generalizable .
Next , There are also memory computing integrated chips that are highly expected to solve the memory wall problem .
This new chip architecture embeds computing power in memory cells , This eliminates the delay and power consumption of data handling , To break through the bottleneck of von Neumann .
Memory computing integrated chip is represented by memristor technology , The resistance of this circuit element will change with the passing current , If the current stops , The resistance will stay at the current value , amount to “ remember ” The amount of current .
If the high resistance value is defined as 1, Low resistance is defined as 0, Memristor can realize binary calculation and storage at the same time .

△ come from doi:10.1038/s41586-021-03748-0
However, the memory computing integrated chip industry is still in its infancy , Progress in materials science is needed to promote . One side , Not many can achieve mass production , On the other hand, there is also a lack of corresponding compiler and other software infrastructure support , Therefore, there is still a long way to go before the real large-scale application .
The present , Optimization based on the existing software and hardware framework has become a more pragmatic option .
As mentioned earlier Colossal-AI, Use multidimensional parallelism to reduce the number of GPU Number of communication between each other in parallel , And then through CPU“ Borrow memory ” The way to make GPU A single card can also train a large model .
say concretely , It is based on the memory usage dynamically queried , Continuously and dynamically transform the tensor state 、 Adjust the tensor position , Efficient use of GPU+CPU Heterogeneous memory .
thus , When AI When there is enough computing power but not enough memory in training , Just add money to buy DRAM Just memory , It sounds like buying GPU Much more cost-effective .
However , Here is another new problem .
GPU The platform is direct “ Borrow memory ”, Not a very efficient choice ( Otherwise, everyone will pile up memory modules )——
And CPU comparison ,GPU The memory scalability of the platform is actually not that high 、 I don't have L1-L3 Cache . The data is in CPU And GPU Exchange between them PCIe The interface efficiency should also be lower .
For those more sensitive to delay AI For application scenarios , Is there a more appropriate solution ?
use CPU The scheme breaks the memory wall , Is it feasible? ?
Ask if you can , We have to see if there is .
From an industry perspective , Indeed, many companies have started to build on CPU Build some platforms AI project , Some of them are personalized recommendations 、 be based on AI Real-time decision-making system, etc , All belong to “ Very sensitive to delay ” Decision making AI.
And decision-making AI, It is the memory wall that is deeply troubled “ The victim ” One of ——
It is not because of the large number of model parameters , But because the model has high requirements for the database .
It is directly put into use after other training AI Different , Decision making AI Fresh data must be obtained from the real environment every day , Make decisions more “ accurate ”, This requires a lot of low latency data interaction .
therefore , The database behind it also needs large-scale concurrent read and write 、 Strong real time 、 Features such as extensibility .
under these circumstances , How to make full use of memory to speed up data reading and writing , On the contrary, it has become more difficult than improving computing power AI The problem of .

that , How on earth are these enterprises CPU On the platform To solve the memory wall problem ?
It has led the trend of online payment services in the world , It is still in this field C Bit PayPal For example .
PayPal Our business now covers online transfer 、 Billing and payment , And the customer scale has reached 200 Super in multiple markets 3.25 Billion consumers and businesses , So it is also like traditional banking services , Faced with a serious challenge of fraud .
PayPal How to deal with it , It is to build a real-time decision-making system with the ability to identify new fraud patterns in real time .
But fraudsters are also changing their fraud patterns , Or find new ways to counter the system , therefore ,PayPal The accuracy of new fraud detection needs to be continuously improved , And it is necessary to shorten the fraud detection time as much as possible .
In this cat and mouse game , Who reacts faster 、 Who can be more flexible in the confrontation , What plays a key role is the rapid processing, reading and writing of data .
To identify emerging fraud patterns in real time ,PayPal Need to process and analyze more data faster , It is necessary to better connect as large a volume of data as possible with real-time processing .
However , Memory wall problem , At this time, it also quietly appeared .
PayPal Find out , I have to deal with hundreds of data collected by the platform over the years PB data , With the data volume of its anti fraud decision-making platform increasing year by year , The size of the primary index is also expanding , To the point that it almost brought down its database , In particular, once the memory capacity of each node carrying these data is exhausted , The efficiency of anti fraud will be greatly reduced , Real time is also out of the question .
therefore ,PayPal Start considering new memory and storage technologies , To break through the memory wall , In other words , Improve the overall storage density of its database scheme .
Just in time ,PayPal On 2015 Since, it is mainly from Aerospike Database technology , The latter was the first to support Intel Haughty One of the database vendors of persistent memory . Its innovative hybrid memory architecture (Hybrid Memory Architecture,HMA) optimized , Can help PayPal Store the larger and larger primary index into aoten persistent memory instead of DRAM in , The memory wall problem is over .
Final test results , It also verifies that aoteng persistence breaks the memory wall 、 Increase the value of overall database capacity and performance :
stay PayPal Total current 2,000 platform Aerospike Server , Yes 200 The console has imported this persistent memory , As a result, the storage space of each node is increased to about 4 times , It also maintains the extremely fast response and low time delay of the application .
With the increase of memory and storage capacity , There are also substantial cost savings , According to the PayPal and Aerospike Benchmarking conducted :
Because the ability of a single node in data storage and read-write has been strengthened , The number of servers required can thus be reduced 50%, The cost per cluster can thus be reduced by about 30%[1].
and , Aoteng persistent memory has another BUFF, Also in the PayPal This anti fraud application scenario has played an unexpected role , This is data persistence , It can bring super fast data and application recovery speed .
Compared with storing the primary index in DRAM, It is also necessary to scan data from storage devices and rebuild indexes after planned or unplanned downtime , Store the primary index in aoteng persistent memory and persist it , Whether it's accidental downtime , Or planned downtime , The data will not disappear due to power failure , The entire system can be restored and brought back online faster .
How fast is this ?PayPal The answer given is the original need 59 Minutes to rebuild the index , Now just 4 minute .
PayPal It also gives some more holistic perspectives , And explain its benefits from the data of business and final application efficacy :
It uses 2015 Preliminary estimate in 50TB Fraud data volume and past memory systems as benchmarks , Discover a new solution based on aoteng persistent memory , Can help it align service level agreements (SLA) Compliance rates range from 98.5% Upgrade to 99.95%.
Missed fraudulent transactions , Then it will be reduced to the original one 1/30, The occupied space of the overall server can be reduced to about 1/8( from 1024 Reduced to 120 Servers ), The overall hardware cost can be reduced to about 1/3.
Considering that the predicted annual data growth rate is about 32%,PayPal The new anti fraud system can achieve cost-effective expansion on the new scheme , And let it continue 99.95% Calculation of fraud SLA Compliance rate 、 Shorter data recovery time 、 Stronger data processing 、 Query performance and data consistency as well as up to 99.99% The usability of .
therefore , Recommendations like this that require higher database performance 、 Online evaluation AI application , utilize CPU platform , In particular, the use of AI Acceleration ability CPU+ Aoteng persistent memory to break the memory wall , It is possible to accelerate overall performance and reduce costs , And it's affordable .
As mentioned earlier , except PayPal Such a global guest outdoor , There are also many Internet enterprises eager to break the memory wall in China 、AI Startups have tried aoteng persistent memory in their similar application scenarios , As a result, the memory subsystem capacity has been greatly expanded + Data and application recovery time is significantly reduced + Hardware cost or TCO Multiple effects of great depression .
and , These scenarios are not the only ones that can use this scheme .
Even in AI for Science On , At present, some scientific research projects are trying to make full use of this scheme , To solve the memory wall problem .
from DeepMind stay 2021 Published in AlphaFold2 Even if it is an example .
Thanks to the accelerated localization of protein three-dimensional structure exploration , And high reliability of prediction ,AlphaFold2 It is bringing about a subversive change in the field of life science , And the secret of its success , It is to use the deep learning method to predict the protein structure , This makes it efficient 、 Cost and other aspects are far better than traditional experimental methods ( Include X-ray Diffraction 、 Cryoelectron microscope 、NMR etc. ).
therefore , Almost all the practitioners in biology are working on the implementation of this technology 、 Pipeline construction and performance tuning . Intel is one of them . It combines the software and hardware advantages of its own architecture , Yes AlphaFold2 The algorithm is carried out in CPU End to end high throughput optimization on the platform , And it has realized the comparison with the special AI Acceleration chips also have excellent performance .
To achieve this result , Thanks to the third generation Intel To the strong The built-in high bit width advantage of scalable processors (AVX-512 etc. ), Also cannot leave Ao Teng persistent memory pair “ Memory wall ” Breakthrough .
One side , In the model reasoning stage , Intel experts through the attention module (attention unit) Perform large tensor segmentation (tensor slicing), And using Intel oneAPI Operator fusion and other optimization methods improve the computational efficiency and CPU Processor utilization , Speed up parallel reasoning , It also alleviates the memory bottleneck and other problems faced by each link in the implementation of the algorithm .
On the other hand , Deployment of aoteng persistent memory , Also provided TB Level memory capacity “ Strategic level ” Support , It can more easily solve the memory bottleneck of memory peak superposition during multi instance parallel execution .
How big is the bottleneck ? According to Intel technology experts : Enter a length of 765aa Under the condition of ,64 When instances are executed in parallel , The demand for memory capacity will break through 2TB. In this case , For users , Using aoteng persistent memory is also their real feasible solution at present .
next step : Heterogeneous chips , Unified memory
Of course , From the development trend of the whole industry ,CPU With a large amount of persistent memory , Nor can it be solved once and for all “ Memory wall ” The problem of .
It is also just one of many solutions .
that , Is there any other solution for memory wall , It is not as far away as the memory computing integrated chip , But more than CPU+ The use of persistent memory is more comprehensive 、 More ?
The answer may be heterogeneous chips + Unified memory .

The heterogeneous chips here , It doesn't just mean CPU and GPU, It also includes FPGA and ASIC And so on AI Computing chip types that provide acceleration . With the core (Chiplet) Technological development , Heterogeneous computing may offer new possibilities for breaking the memory wall .
at present , Open standards for core particle interconnection UCIe(Universal Chiplet Interconnect Express) It has been recognized by a large number of players in the chip industry , It is expected to become the mainstream standard .
Intel, the leader of this standard, is actively laying out itself XPU strategic , Put scalar (CPU)、 vector (GPU)、 matrix (ASIC) And space (FPGA) And the diverse computing power of chips of different types and architectures .
A recent achievement is the next generation supercomputing system of Argonne National Laboratory —— Aurora (Aurora).
Aurora supercomputing CPU The code named will be used Sapphire Rapids Fourth generation Intel To the strong Scalable processor , And the matching code is Ponte Vecchio Intel Data Center GPU, Double precision peak computing performance exceeds 20 billion times per second , It can support R & D and innovation activities such as more accurate climate prediction and the discovery of new treatments for cancer .
This is still a visible development . stay UCIe With the support of , There may be different architectures in the future 、 Even different processes IP Package into one piece SoC A new species of chip .

With the cooperation of heterogeneous chips and even the integration of heterogeneous cores , The memory matched by different chips and cores is likely to be unified or pooled .
One possible way to do this , Through optics I/O To connect different chips 、 Cored grain 、 Memory and other components , That is to say, the optical signal is used to replace the electrical signal for the communication between chips , Higher bandwidth can be achieved 、 Lower delay and lower power .
for example , optics I/O Innovative enterprises in Ayar Labs, At present, it has been favored by major chip giants and high-performance computing suppliers .
In the latest round 1.3 Billion dollars in financing , Its investors include Intel 、 Ying Wei Da 、 Lattice core and HPE.
Maybe , Distance memory “ unified ” The era of is really not far away .
under these circumstances , Persistent memory itself is also seeing more opportunities .
for example , At present, aoteng persistent memory has realized a single memory 512GB The capacity of , Single 1TB Capacity models are also being prepared .
If you want to really efficiently expand the unified memory pool of heterogeneous systems , Its multiple advantages can not be ignored .
Reference link :
[1]https://www.intel.com/content/www/us/en/customer-spotlight/stories/paypal-customer-story.html
边栏推荐
- Randla net: efficient semantic segmentation of large scale point clouds
- 马斯克:推特要学习微信,让10亿人「活在上面」成为超级APP
- TensorFlow,危!抛弃者正是谷歌自己
- Cloud native database vs traditional database
- Tai Chi graphics 60 lines of code to achieve classic papers, 0.7 seconds to get Poisson disk sampling, 100 times faster than numpy
- Administrator如何禁止另一个人踢掉自己?
- MySQL根据表前缀批量修改、删除表
- Amazon's other side in China
- MCN institutions are blooming everywhere: bloggers and authors should sign contracts carefully, and the industry is very deep
- Sleep more, you can lose weight. According to the latest research from the University of Chicago, sleeping more than 1 hour a day is equivalent to eating less than one fried chicken leg
猜你喜欢

MySQL根据表前缀批量修改、删除表

Wuenda, the new course of machine learning is coming again! Free auditing, Xiaobai friendly

Background page production 01 production of IVX low code sign in system

Musk was sued for $258billion in MLM claims. TSMC announced the 2nm process. The Chinese Academy of Sciences found that the lunar soil contained water in the form of hydroxyl. Today, more big news is

Now, the ear is going into the metauniverse

你真的需要自动化测试吗?
MySQL modifies and deletes tables in batches according to the table prefix

Sleep more, you can lose weight. According to the latest research from the University of Chicago, sleeping more than 1 hour a day is equivalent to eating less than one fried chicken leg

北大换新校长!中国科学院院士龚旗煌接任,15岁考上北大物理系

Please check the list of commonly used software testing tools.
随机推荐
Redis related-02
Randla net: efficient semantic segmentation of large scale point clouds
发布功能完成02《ivx低代码签到系统制作》
股票开户用客户经理发的开户链接安全吗?知道的给说一下吧
Tencent's open source project "Yinglong" has become a top-level project of Apache: the former long-term service wechat payment can hold a million billion level of data stream processing
MySql安裝教程
华为上诉失败,被禁止在瑞典销售 5G 设备;苹果公司市值重获全球第一;Deno 完成 2100 万美元 A 轮融资|极客头条
About sizeof() and strlen in array
Svn deployment
俄罗斯AIRI研究院等 | SEMA:利用深度迁移学习进行抗原B细胞构象表征预测
扎克伯格最新VR原型机来了,要让人混淆虚拟与现实的那种
Collaboration + Security + storage, cloud box helps Shenzhen edetai restructure its data center
服乔布斯不服库克,苹果传奇设计团队解散内幕曝光
The release function completed 02 "IVX low code sign in system production"
Amazon's other side in China
Tutorial on installing SSL certificates in Microsoft Exchange Server 2007
The file attributes downloaded by the browser are protected. How to remove them
用CPU方案打破内存墙?学PayPal堆傲腾扩容量,漏查欺诈交易量可降至1/30
Maintenant, les oreilles vont entrer dans le métacosme.
How to raise key issues in the big talk club?