Preface In this paper , The author introduces a simple framework , namely Slimmable Domain Adaptation, To improve cross domain generalization through weight sharing model base , From it, models with different capacities can be sampled , To accommodate different accuracy and efficiency tradeoffs . Besides , The author also developed a random integrated distillation method , In order to make full use of the complementary knowledge in the model base for the interaction between models .
Under various resource constraints , The author's framework greatly outperforms other competitive approaches on multiple benchmarks , And can maintain the performance improvement of the source only model , Even if the computational complexity is reduced to 1/64.
Welcome to the official account CV Technical guide , Focus on computer vision technology summary 、 The latest technology tracking 、 Interpretation of classic papers 、CV Recruitment information .

The paper :Slimmable Domain Adaptation
The paper :http://arxiv.org/pdf/2206.06620
Code :https://github.com/hikvision-research/SlimDA
background
Deep neural network is usually used for offline image acquisition ( Marked source data ) Training , And then embedded into the edge device , To test the images taken from the new scene ( Unlabeled target data ). In practice , This mode reduces network performance due to domain transfer . In recent years , More and more researchers are adapting to unsupervised fields (UDA) In depth research , To solve this problem .
Vanilla UDA It aims to align source data and target data into a joint representation space , So that the model trained according to the source data can be well extended to the target data . however , There is still a gap between academic research and industrial demand : Most of the existing UDA Methods only the fixed neural structure was used for weight adaptation , But it can not effectively meet the requirements of various devices in real world applications .
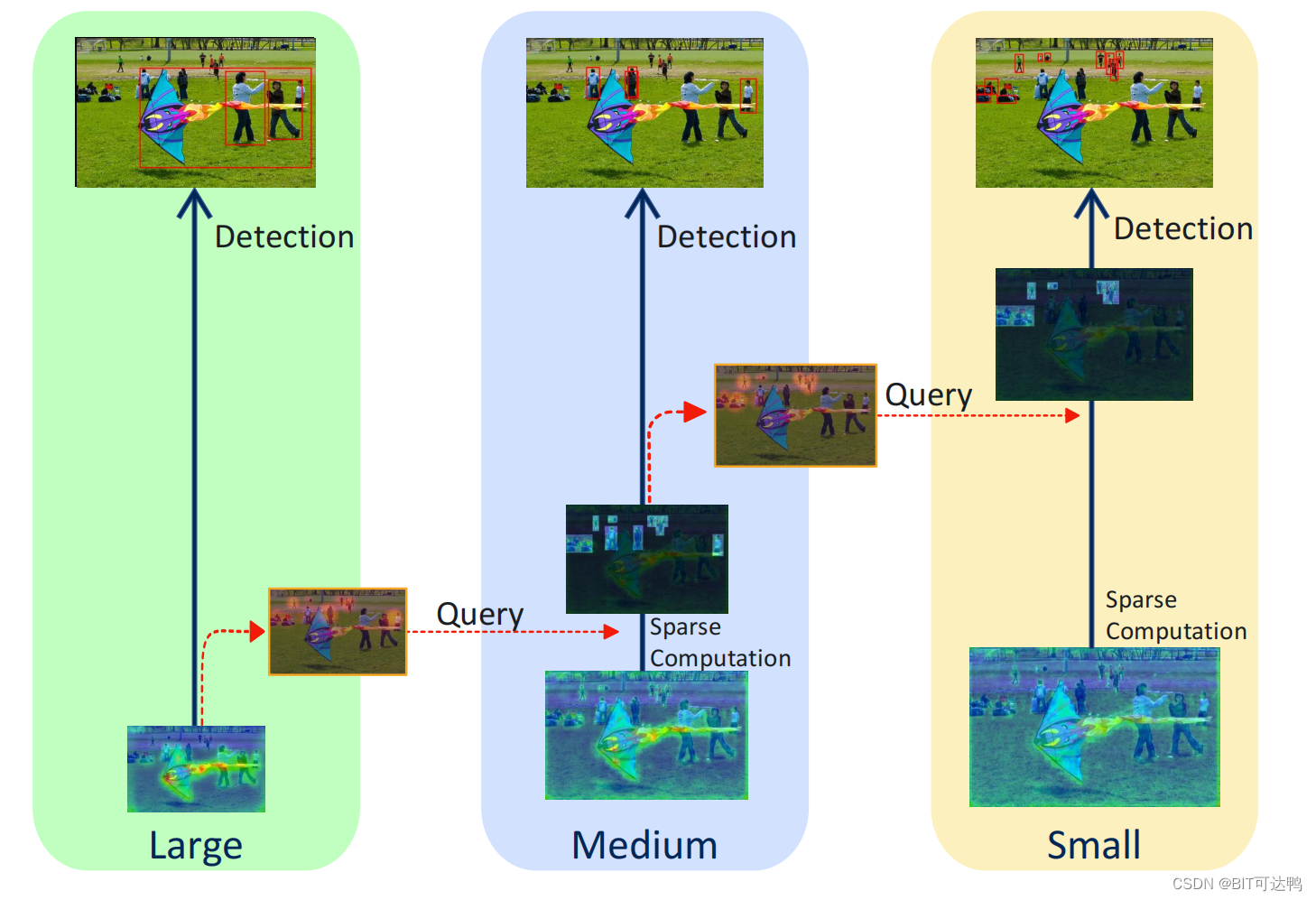
In an effort to 1 The widely used application scenario shown in , under these circumstances , Ordinary UDA The method must repeatedly train a series of models with different capacities and architectures , To meet the needs of equipment with different calculation budgets , It's expensive and time consuming .
In order to solve the above problems , The author puts forward Slimmable Domain Adaption(SlimDA), That is, the model is trained only once , In this way, you can flexibly extract customized models with different capacities and architectures from them , To meet the needs of equipment with different calculation budgets .

chart 1 SlimDA
When the thin neural network satisfies the unsupervised domain adaptation , Two challenges remain :
1) Weight adaptation : How to improve the adaptive performance of all models in the model base at the same time .
2) Architecture adaptation : Given a specific calculation budget , How to search for an appropriate model on unlabeled target data .
For the first challenge , Random integrated distillation is proposed (SEED) To interact with models in the model library , In order to suppress the uncertainty of unlabeled target data adaptively in the model . surface 1 Shows SEED And traditional knowledge distillation .

surface 1 Distillation of traditional knowledge (CKD) With random integrated distillation (SEED)
For the second challenge , The author puts forward an unsupervised performance evaluation index , It can alleviate the output difference between the candidate model and the anchor model . The smaller the measure , Assume better performance .
contribution
1. Put forward SlimDA, One “ Once and for all ” Framework , To jointly adapt to the adaptive performance and calculation budget of equipment with limited resources .
2. Put forward SEED, It can improve the adaptability of all models in the model base at the same time .
3. An optimal separation of three classifiers is designed to adjust the optimization between intra model adaptation and inter model interaction .
4. An unsupervised performance evaluation index is proposed , To facilitate architectural adaptation .
Related methods
1. Unsupervised domain adaptation (UDA)
The existing UDA The method aims to improve the performance of the model on the unlabeled target domain . In the last few years , The difference based method and antagonism optimization method are proposed , This problem is solved by field alignment .SymNet A dual classifier architecture is developed , To promote category level domain confusion . lately ,Li Others are trying to learn the best architecture , To further improve the performance of the target domain , This proves that the network architecture is right UDA Importance . these UDA The approach focuses on implementing specific models with better performance on the target domain .
2. Neural architecture search (NAS)
NAS The method aims at reinforcement learning 、 Evolutionary methods 、 Gradient based methods, etc. automatically search for the optimal architecture . lately , The one-time method is very popular , Because you only need to train a super network , At the same time, multiple weight sharing subnetworks of various architectures are optimized . such , You can search for the optimal network structure from the model base . In this paper , The author emphasizes UDA about NAS It is an unnoticed but significant scene , Because they can work together unsupervised to optimize lightweight, scenario specific architectures .
3. Cross domain network compression
Chen Et al. Proposed a cross domain unstructured pruning method .Y u And so on MMD To minimize domain differences , And prune the filter in the Taylor based strategy ,Yang Et al. Focused on compressed graph neural networks .Feng Et al. Conducted antagonistic training between the channel pruning network and the full-size network . However , There is still much room for improvement in the performance of the existing methods . Besides , Their methods are not flexible enough , Many optimal models cannot be obtained under different resource constraints .
Method
1. SlimDA frame
It has been proved in the reducible neural network , With different widths ( That is, the layer channel ) Many networks can be coupled to the weight sharing model base , And optimize at the same time . Start with a baseline , In this baseline ,SymNet Directly merge with the slender neural network .
For the sake of simplicity ,SymNet The overall goal of the project is Ldc. In each training iteration , From the model library {(Fj,Csj,Ctj)}mj=1 Several models of random sampling in ∈(F,Cs,Ct), Named model batch , among m Represents the model batch size . here (F、Cs、Ct) Can be regarded as the largest model , Other models can be sampled through weight sharing .
To ensure that the model base is adequately trained , The largest and smallest models shall be sampled in each training iteration , And make it part of the model batch .

This baseline can be regarded as Eqn The two alternate processes of . To encourage interaction between models in the above baseline , The author puts forward SlimDA frame , Pictured 2 Shown . The framework consists of randomly integrated distillation (SEED) And optimize the separation of three classifiers (OSTC) Design composition .
SEED The aim is to use the complementary knowledge in the model base for multi model interaction .Cs and Ct The red arrow on the classifier indicates domain confusion training Ldc And knowledge aggregation in the model base .Ca The purple arrow on the classifier indicates seed optimization Lseed.

chart 2 SlimDA frame
2. Random integrated distillation (SEED)
SEED The aim is to use the complementary knowledge in the model base for multi model interaction . Different models in the model base can intuitively learn supplementary knowledge about unlabeled target data . Inspired by Bayesian learning with model perturbations , The author uses the models in the model base to suppress the uncertainty of unlabeled target data through Monte Carlo sampling .
Model confidence definition :

Sharpen the function to induce implicit entropy minimization during seed training :

3. Optimize the separation of three classifiers (OSTC)
The first two are used for domain obfuscation training , The last one is used to receive the knowledge of random polymerization for distillation . The distillation loss formula is as follows :

4. Unsupervised performance evaluation indicators
Unsupervised performance measures (UPEM):

experiment
surface 2 ImageCLEF-DA Two ablation experiments on the dataset

surface 3 stay ImageCLEF-DA The data set is right SlimDA To conduct ablation experiments

surface 4 ImageCLEF-DA Yes I→P Two ablation experiments for adaptation tasks

surface 5 stay ImageCLEF-DA Performance comparison with different most advanced lightweight networks on data sets

surface 7 Office-31 Performance on data sets

chart 3 With the random search model in ImageCLEF-DA Compare the six adaptation tasks on the

chart 4 Unsupervised performance measures (UPEM) And use ground-truth Between the accuracy of labels Pearson The correlation coefficient
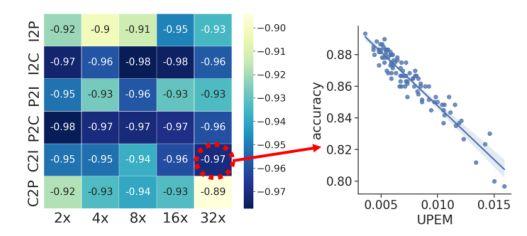
chart 5 Convergence performance of model base

Conclusion
In this paper , The author puts forward a simple and effective SlimDA frame , To facilitate the joint adaptation of weights and architectures . stay SlimDA in , Proposed SEED Using the architecture diversity in the weight sharing model base to suppress the prediction uncertainty of unlabeled target data , And OSTC Adjust the optimization conflict between the adaptation within the model and the interaction between the models .
In this way , The resource satisfaction model can be flexibly distributed to various devices in the target domain by sampling without retraining . In order to verify SlimDA The effectiveness of the , Extensive ablation experiments were carried out .
CV The technical guide creates a computer vision technology exchange group and a free version of the knowledge planet , At present, the number of people on the planet has 700+, The number of topics reached 200+.
The knowledge planet will release some homework every day , It is used to guide people to learn something , You can continue to punch in and learn according to your homework .
CV Every day in the technology group, the top conference papers published in recent days will be sent , You can choose the papers you are interested in to read , continued follow Latest technology , If you write an interpretation after reading it and submit it to us , You can also receive royalties . in addition , The technical group and my circle of friends will also publish various periodicals 、 Notice of solicitation of contributions for the meeting , If you need it, please scan your friends , And pay attention to .
Add groups and planets : Official account CV Technical guide , Get and edit wechat , Invite to join .
Welcome to the official account CV Technical guide , Focus on computer vision technology summary 、 The latest technology tracking 、 Interpretation of classic papers 、CV Recruitment information .

Other articles of official account
Introduction to computer vision
Summary of common words in computer vision papers
YOLO Series carding ( Four ) About YOLO Deployment of
YOLO Series carding ( 3、 ... and )YOLOv5
YOLO Series carding ( Two )YOLOv4
YOLO Series carding ( One )YOLOv1-YOLOv3
CVPR2022 | Thin domain adaptation
CVPR2022 | Based on egocentric data OCR assessment
CVPR 2022 | Using contrast regularization method to deal with noise labels
CVPR2022 | Loss problem in weakly supervised multi label classification
CVPR2022 | iFS-RCNN: An incremental small sample instance divider
CVPR2022 | A ConvNet for the 2020s & How to design neural network Summary
CVPR2022 | PanopticDepth: A unified framework for depth aware panoramic segmentation
CVPR2022 | Reexamine pooling : Your feeling field is not ideal
CVPR2022 | Unknown target detection module STUD: Learn about unknown targets in the video
CVPR2022 | Ranking based siamese Visual tracking
Build from scratch Pytorch Model tutorial ( Four ) Write the training process -- Argument parsing
Build from scratch Pytorch Model tutorial ( 3、 ... and ) build Transformer The Internet
Build from scratch Pytorch Model tutorial ( Two ) Build network
Build from scratch Pytorch Model tutorial ( One ) data fetch
Some personal thinking habits and thought summary about learning a new technology or field quickly
CVPR2022 | More relevant articles on thin domain adaptation
- ASP.Net Development WebAPI Cross domain access (CORS) Streamlining the process
1: Web.config There's a line in it : <remove name="OPTIONSVerbHandler" /> This one needs to be deleted . 2: nuget install Microsoft.A ...
- Windows 2003】 Utilization domain && Group policy automatically deploys Software
Windows 2003] Utilization domain && Group policy automatically deploys Software from http://hi.baidu.com/qu6zhi/item/4c0fa100dc768613cc34ead0 ==== ...
- Web The front-end knowledge system is simplified
Web The front end technology consists of html.css and javascript Three parts make up , It's a huge and complex technology system , Its complexity is no less than that of any back-end language . And when we learn it, we often start from a certain point , And then constantly contact and learn new knowledge ...
- spring mvc:ueditor Cross domain multi image upload failure solution
The company needs to use Baidu's when developing a background system UEditor Rich text editor , The application scenarios are as follows : UEditor All the pictures of .js And other static resources on a proprietary static server : The picture is uploaded to another server : Because the company will use ...
- SXWIN7X64EN_20181104_NET_msu_LITE English simplified version
SXWIN7X64EN_20181104_NET_msu_LITE English simplified version this version is English simplified version ! The English version is simplified ! The English version is simplified ! One . Preface : Notes on the minimalist version This system is a limited version , Extreme lite ...
- SX_WIN10X64LTSB2016_EN_LITE English simplified version
SX_WIN10X64LTSB2016_EN_LITE English simplified version this version is in English ! This version is in English ! This version is in English ! Because the forum Pakistan maanu brother PM I , So I took the time to do one . The introduction follows the original , Google translate Chinese ...
- WIN10X64_LTSB2016 Extreme compact by Bicentric
WIN10X64LTSB2016 Extreme compact by Bicentric http://www.cnblogs.com/liuzhaoyzz/p/9162113.html One . Preface : Notes on the minimalist version This system is a limited version , ...
- WIN7X64SP1 Extreme compact by Bicentric
WIN7X64SP1 Extreme compact by Bicentric http://bbs.wuyou.net/forum.php?mod=viewthread&tid=405044&page=1&ext ...
- jQuery Of ajax Cross domain Jsonp principle
1.Jsonp Jsonp(json with padding) yes JSON A kind of “ Usage mode ”, It can be used to solve the problem of cross-domain data access in major browsers . Jsonp To solve the problem ajax Send across domains http The request appears , utilize S ...
- The essence of front end Engineering ( One ): Static resource version update and cache ( With concise js Tools for )
from :http://www.infoq.com/cn/articles/front-end-engineering-and-performance-optimization-part1/ Everyone has participated in ...
Random recommendation
- Check the Internet exit IP && Traceroute
One .CentOS Check the Internet exit IP 1---------------- # curl ifconfig.me 2----------------# curl icanhazip.com Two .Trace ...
- In depth source code analysis String,StringBuilder,StringBuffer
[String,StringBuffer,StringBulider] In depth source code analysis String,StringBuilder,StringBuffer [ author : Gao Ruilin ] [ Blog address ]http://ww ...
- TCP Flow control and congestion handling
1. Use sliding window to realize flow control If the sender sends the data too fast , The receiver may not have time to receive , This will result in the loss of data . The so-called flow control is to make the sending rate of the sender not too fast , To give the receiver time to receive . Using the sliding window mechanism, you can ...
- JavaScript Regular also has a single line pattern
Regular expressions were first created by Ken Thompson On 1970 In the year he improved QED In the editor , The simplest metacharacter in regularization “.” At that time, what was matched was any character except the newline character : "." ...
- Generative model VS Discriminant model
1 Definition 1.1 Generative model Generative model (Generative Model) Would be right x and y The joint distribution of p(x,y) modeling , And then we use Bayes formula to get p(yi|x), Then select make p(yi|x) maximal yi, namely ...
- mybatis Some summary of my study
I used to use it all the time spring Of JDBCTEMPLATE and hibernate Do the project . Both are pretty good ,spring Of jdbctemplate It's troublesome to use , Although very easy. and hibernate Well , It's very useful ...
- java Send mail function [ turn ]
Link to the original text :https://blog.csdn.net/jjkang_/article/details/56521959 Javamail Follow two agreements , One is smtp agreement , The other is pop3 agreement . General situation ...
- 11.UiAutomator relevant JAVA knowledge
One . Encapsulation methods and modular use cases 1. Method : stay JAVA in , Method is like an action in daily life , A series of complete operations composed of actions . Method structure : Method modifier Method return value type Method name { Method body } such as : public ...
- caffe Python API And SoftmaxWithLoss
net.loss = caffe.layers.SoftmaxWithLoss(net.fc3, net.label) Output : layer { name: "loss" type: ...
- mysql Modify the default value of a field in the table
Mysql of use SQL increase . Delete field , Modify field name . Field type . notes , Adjust the field order summary In website reconstruction , The data structure is usually modified , So add the , Delete , increase mysql Table fields are unavoidable , Sometimes for convenience , Changes will also be added ...