当前位置:网站首页>Can the characteristics of different network structures be compared? Ant & meituan & NTU & Ali proposed a cross architecture self supervised video representation learning method CaCl, performance SOTA
Can the characteristics of different network structures be compared? Ant & meituan & NTU & Ali proposed a cross architecture self supervised video representation learning method CaCl, performance SOTA
2022-06-23 23:29:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares CVPR 2022 The paper 『Cross-Architecture Self-supervised Video Representation Learning』, Raise questions : The characteristics of different network structures can also be compared ? And by ants & Meituan & Nanjing University & Ali proposes a cross architecture self supervised video representation learning method CACL, In the task of video retrieval and motion recognition SOTA!
The details are as follows :

Thesis link :https://arxiv.org/abs/2205.13313
Project links :https://github.com/guoshengcv/CACL
01
Abstract
In this paper , The author proposes a new cross architecture contrastive learning for self supervised video representation learning (cross-architecture contrastive learning,CACL) frame .CACL By a 3D CNN And a video Transformer form , They are used in parallel to generate various alignments for comparative learning . This enables the model to represent Xi Qiang from these different but meaningful aspects .
Besides , The author introduces a time self - supervised learning module , The module can explicitly predict the editing distance between two video sequences in time order , This enables the model to learn rich temporal representations . The author's comments on the method in this paper UCF101 and HMDB51 The video retrieval and motion recognition tasks on the dataset are evaluated , The results show that this method has achieved excellent performance , Much more than Video MoCo and MoCo+BE And other state-of-the-art methods .
02
Motivation
Video representation learning is a basic task of video understanding , Because it plays an important role in various tasks , For example, action recognition 、 Video Retrieval . Recent work has focused on improving the performance of deep neural networks by using supervised learning , This usually requires a large-scale video dataset with very expensive human annotations , Such as Sports1M、Dynamics、HACS and MultiSports. The huge annotation cost inevitably limits the potential of deep network in learning video representation . therefore , It is important to improve this task with unlabeled video that is easy to access on a large scale .
In recent years , Self supervised learning has made great progress in learning strong image representation . It has also been extended to the field of video , Contrastive learning has been widely used in the field of video . for example , In recent work , Introducing contrast learning to capture the differences between two video instances , This enables contrastive learning to learn the representation in each video instance . However , In these methods , Contrastive learning mainly focuses on learning the global space-time representation of video , It is difficult to capture meaningful time details , These details usually provide important clues for distinguishing different video instances . therefore , Different from learning image representation , Modeling time information is very important for video representation . In this work , A new self supervised video representation method is proposed , This method can simultaneously perform video level contrast learning and time modeling in a unique framework .
By exploring the sequence nature of video , You can create a monitoring signal for learning time information , So as to realize self supervised learning . Some recent methods follow this research route , An excuse task for self-monitoring time prediction is created ( pretext task). In this work ,shuffle. This enables the model to clearly quantify the degree of time difference in editing distance , However, the existing self-monitoring methods are usually limited to estimating the approximate difference between two videos in the time domain . for example , Previous methods often created an excuse task to predict whether the speed or playback speed of two video sequences were the same , But it ignores the details of this time difference .
Although most self supervised contrastive learning methods use a variety of data enhancements to generate positive alignments , These data enhancements provide different views of the instance , But the author developed a new method , Be able to get stronger representation from different structures through comparative learning .3D CNN The series has achieved remarkable performance in various video tasks , Include C3D、R3D、R(2+1)D etc. . because CNN Inherent characteristics of , They can capture local correlations in the time domain . however CNN The effective receptive field may limit its ability to model long-term dependence .
On the other hand ,transformer The architecture can naturally capture such long-distance dependencies using a self - attention mechanism , Each of them token Can learn to pay attention to the whole sequence , Thus meaningful context information is encoded into the video representation . Besides , When training on large enough data ,CNN The inductive bias of may limit its performance , Due to the dynamic weighting of self attention , This restriction may not apply to Transformer Occur in the .
The author thinks that , Modeling local and global dependencies is crucial for video understanding ;CNN Inductive bias and Transformer The capacity of can compensate each other . In this work , The author proposes a new cross architecture contrastive learning for self supervised video representation learning (CACL) frame .CACL Can from 3D CNN And video Transformer Generate a variety of more meaningful comparisons to learn from . The author proved that the video Transformer Can be greatly enhanced by 3D CNN Generated video representation . It produces rich high-level contextual features , And encourage 3D CNN Capture more details . This allows the two structures to work together , This is the key to improving performance .
The main contributions of this paper are summarized as follows :
The author designed a new cross architecture comparative learning (CACL) frame , For self supervised video representation learning .CACL Use 3DCNN and Transformer Collaborative generation of diverse but meaningful alignments , So as to achieve more effective comparative representation learning .
By explicitly measuring video and its time self-shuffle Edit distance between , A new self supervised time learning method is introduced . This helps to learn a wealth of time information , To supplement from CACL The learned expression .
The author verifies the method in this paper on two downstream video tasks : Video recognition and Motion Retrieval . stay UCF101 and HMDB51 The result of the experiment shows that , The proposed CACL Can be significantly better than existing methods , Such as VideoMoCo and MoCo+BE.
03
Method
The author deals with video representation learning in a self supervised way . In this section , Firstly, the general framework of the proposed method is introduced . Then the proposed contrastive learning method is described in detail , And self supervised time learning based on frame level disorder prediction .
3.1. Overall Framework

The above table shows the overall framework of this approach , The framework of this paper consists of two paths , Including a transformer Video encoder and a 3D CNN Video encoder . The self supervised learning signal is calculated by two tasks : Segment level contrast learning and frame level time prediction .
3D CNN video encoder
In this work , use 3D CNN As the main video encoder , It's also used for reasoning . whatever 3D CNN Architecture can be applied to the framework of this article . Combine the original clip with shuffle The output characteristics of the fragment concat get up , Then enter the comparison header and classification header . Both heads are fully connected feedforward networks .
Transformer video encoder

transformer Encoder by 2D CNN and transformer Architecture Composition , As shown in the figure above . First , adopt 2D CNN Calculate each image frame of the video clip , The CNN Perform feature extraction to obtain frame level token Sequence . then , Output CNN The feature is projected to through the full connection layer 768-D Frame of token. Then the frames are sorted in chronological order token concat get up , And at frame token Add learnable embeddedness to the sequence .
Last , One 6 layer 6 head Transformer The model takes segment level feature sequence as input , The embedded output can be learned as a video representation . It is worth noting that , The feature extraction network is achieved by using a self supervised method MoCo, Use UCF101 Training set of video frames for pre training ResNet50, Its weight is frozen during the self supervised video presentation learning .
3.2. Cross-Architecture Contrastive learning
The goal of self supervised contrastive learning in this paper is to maximize the similarity between video clips with the same context , At the same time, minimize the similarity between clips from different videos . It is different from the previous contrastive learning methods , In this paper, the CACL Better joint capture of local and remote dependencies using cross architecture contrast learning signals .
Construction of positive pairs
The fundamental problem of contrastive learning lies in the design of positive and negative samples . Previous work on self supervised contrastive learning usually used various data enhancements to generate different versions of specific instances , So as to form a positive . In this work , The author enriches the antithesis from two perspectives : Embedded layer ( Use different network structures ) And the data layer .
From the perspective of the Internet ,CACL Take advantage of 3D CNN and Transformer The advantages of . Given an input video clip , Each video segment generates a video representation , Compared with the previous method , This will double the number of positive samples . In the data layer , The author of the original fragment x Random in time dimension shuffle, And get a shuffle Video clip . These two examples then cancat together .
Pictured 1 Shown , By using different data enhancement and encoder , Maximizes the similarity of the four positive pairs generated from each video clip . Express different data enhancements as ,Transformer The encoder is represented as , The three dimensional CNN The encoder is represented as , Four feature representations can then be generated for the video clip .
Negative pairs
Clips from different videos are considered negative samples . Author use MoCo The proposed momentum encoder and memory dictionary queue It further enhances comparative learning , It provides more meaningful negative samples to improve the performance of contrastive learning .
Data augmentations
The author performs data enhancement in the spatial and temporal domains of the input video clip . Be careful , Spatial enhancement is performed consistently on all frames within the clip . therefore , The author maximizes three kinds of similarity :(1) The similarity between segments calculated by the same network but performing different data extensions ;(2) The similarity between fragments with the same data expansion but calculated by different networks ;(3) Using different networks and different data to enhance the similarity between fragments .
Loss function
Formally , The author considers a case by N Random sampling of different video instances batch, Then extract a segment from each video . This will result in a batch In all N A fragment (C). The author randomly shuffle The order of each segment , Create a new set of N A fragment (). Then put each fragment and its shuffle edition concat get up , And use data enhancement for further processing .
This will generate two with different data enhancements concat Video clip . The generated clips are processed by different video coders : be based on 3D-CNN Video encoder based on Transformer The encoder . therefore , The author generates four segment level video representations for each video instance :, It is used to construct a positive alignment during comparative learning . The author makes use of InfoNCE The case discrimination idea of contrast loss :

Where is the similarity measure between two vectors . And are two kinds of characteristics .τ It's an adjustable parameter . In this work , The author extends the contrastive learning of video representation learning to :

among , Is from a queue of size m Of memory dictionary queue The negative sample of . As shown in the above formula , In this paper, the CACL Be able to generate more alignments than standard contrastive learning .
3.3. Temporal Prediction with Edit Distance
The goal of this article is to learn time - sensitive video representation . So , The author tries to predict video clips and their shuffle Time differences between versions to train the network . The authors believe that this time prediction task requires motion and appearance cues . This enables the model to learn meaningful time details , Thus, it is beneficial to downstream tasks . In this work , The author proposes to use the minimum editing distance (MED) To measure video clips versus shuffle The degree of time difference between versions .
MED Provides a way to measure two strings by calculating the minimum operand required to convert one string to another ( For example, words ) The difference between the methods . Mathematically speaking , Two strings a,b Between Levenshtein Distance is represented by , among :

among , It's an indicator function , Then equal to 0, Otherwise 1. In this work , take shuffle The prediction task is described as a classification problem , The cross entropy loss is used to calculate the three-dimensional CNN Model training . Given a video clip and its shuffle edition , You can calculate :

among m It's all shuffle Number of videos .
Uniform shuffle-degree sampling
Given a 16 Video clips of frames , The author carried out a random shuffle, And calculate the original clip and shuffle Between fragments MED. The author finds that in this example ,MED It is a slave. 0 To 16 Of discrete integers (1 With the exception of ), This allows the author to put MED The regression problem of prediction is reformulated as a classification task . However , The distribution of these discrete integers is not uniform , This may lead to classification imbalance , Make the training process unstable . Technically speaking , The author first sampled a random sample from the uniform distribution MED Count , Then a random shuffle Video clip , Until it meets the requirements of sampling MED Count . This operation makes the model well balance the label distribution in classification , This is very important for time modeling and joint learning .
Compared with other shuffle&learn method
Compared with earlier methods , Such as Shuffle&Learn、OPN and VCOP. The method in this paper focuses on degree perception , Not sequential prediction / verification , This naturally leads to the following characteristics . It can learn more meaningful time information by increasing the number of frames , The previous method is usually limited to a very small number of frames . Because with the frame / An increase in the number of fragments , The number of sequences will increase rapidly . This method can capture more detailed and meaningful differences between video clips , This enables the model to learn more abundant temporal characteristics .
04
experiment
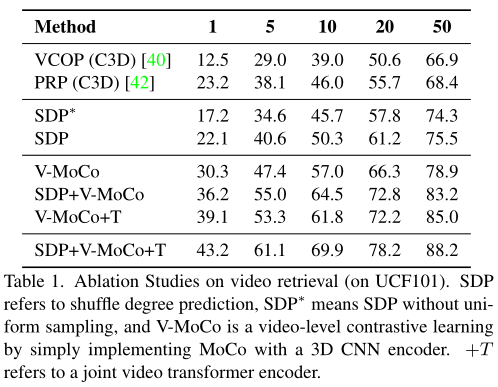
The author has studied shuffle degree prediction(SDP) The ability to learn time information from video , And compare it with the recently developed VCOP and PRP Made a comparison . The above table compares the results , Among them, the SDP Significantly better than VCOP, And achieved with PRP Quite a result .

As shown in the table above , Express 3D CNN Right opposite of , With different data enhancements , This is equivalent to using SDP Execute the original... On the video MoCo. Use all possible alignments
402 Payment Required
It's in this article CACL Full implementation . By adding more facing groups , Can gradually improve performance . This shows that the video of this article Transformer The encoder can provide more meaningful contrast information .
In order to further study the influence of different positive samples on self supervised contrastive learning , The author calculated UCF101 test split 1 Average similarity of positive sample pairs in score , As shown in the table above .

In the above table , The author shows the comparison of retrieval results between this method and different self supervised learning methods in video retrieval task , It can be seen that this method has obvious advantages .

In the above table , The author shows the comparison of the retrieval results of this method and different self supervised learning methods in action recognition task .
05
summary
In this paper , A new self supervised video representation learning framework is proposed CACL. By introducing Transformer Video encoder , Designed a framework of comparative learning , It's three-dimensional CNN The comparative learning of provides a wealth of comparative samples . The author also introduces a new pretext Task to train a predictive video shuffle A model of degree . In order to verify the effectiveness of this method , The author has conducted extensive experiments on two different downstream tasks across three network architectures . Experimental results show that , In this paper, the shuffle degree prediction and transformer Video coders can encourage models to learn portable video representations , Compared with the method based on comparative learning , The features learned are heterogeneous .
Reference material
[1]https://arxiv.org/abs/2205.13313
[2]https://github.com/guoshengcv/CACL

END
Welcome to join 「 Self supervision 」 Exchange group notes :SSL

边栏推荐
- The sandbox and bayz have reached cooperation to jointly drive the development of metauniverse in Brazil
- Detailed process of deploying redis cluster and micro service project in docker
- What is the development prospect of face recognition technology?
- Bilibili×蓝桥云课|线上编程实战赛全新上新!
- 项目中常用到的 19 条 MySQL 优化
- C# 读取内存条占用大小,硬盘占用大小
- FANUC机器人SRVO-050碰撞检测报警原因分析及处理对策(亲测可用)
- Short video enters the hinterland of online music
- Summary of some indicators for evaluating and selecting the best learning model
- Detailed quaternion
猜你喜欢

开发协同,高效管理 | 社区征文

百万消息量IM系统技术要点分享

Ambire 指南:Arbitrum 奥德赛活动开始!第一周——跨链桥

Common core resource objects of kubernetes
迪赛智慧数——柱状图(基本柱状图):2022年父亲节过节的方式

【观察】戴尔科技+英特尔傲腾技术:以“纳秒之速”领跑存储创新
Phpmailer sends mail PHP

The 12 SQL optimization schemes summarized by professional "brick moving" old drivers are very practical!

Giants end up "setting up stalls" and big stalls fall into "bitter battle"

Flutter中的GetX状态管理用起来真的那么香吗?
随机推荐
Go deep: the evolution of garbage collection
Docker中部署Redis集群与部署微服务项目的详细过程
Detailed process of deploying redis cluster and micro service project in docker
Summary of some indicators for evaluating and selecting the best learning model
堡垒机安装pytorch,mmcv,mmclassification,并训练自己的数据集
不同网络结构的特征也能进行对比学习?蚂蚁&美团&南大&阿里提出跨架构自监督视频表示学习方法CACL,性能SOTA!...
Micro build low code tutorial - Application creation
《阿里云天池大赛赛题解析》——O2O优惠卷预测
How to batch generate flattermark barcode
Application of clock synchronization system in banking system
Payment industry tuyere project: smart digital operation 3.0
kubernetes之常用核心资源对象
MySQL索引底层为什么用B+树?看完这篇文章,轻松应对面试。
Build the first security defense line for enterprises to go to the cloud Tencent's new generation cloud firewall product launch is about to open
Go language core 36 lectures (go language practice and application 23) -- learning notes
Giants end up "setting up stalls" and big stalls fall into "bitter battle"
AIX系统月维护查什么(一)
Pressure measuring tool platform problem case base
Summary of cloud native pipeline tools
Debian change source and uninstall useless services