当前位置:网站首页>Application practice | massive data, second level analysis! Flink+doris build a real-time data warehouse scheme
Application practice | massive data, second level analysis! Flink+doris build a real-time data warehouse scheme
2022-06-24 21:52:00 【InfoQ】
Business background
Doris The basic principle

- Receive user connection request (MySQL Protocol layer )
- Metadata storage and management
- Query statement parsing and execution plan distribution
- Cluster management and control
- Data storage and management
- Query plan execution
Technology Architecture

- adopt FlinkCDC collection MySQL Binlog To Kafka Medium Topic1
- Development Flink Tasks consume the above Binlog Generate a wide table of related topics , write in Topic2
- To configure Doris Routine Load Mission , take Topic2 Data import Doris
Application practice
Build table
CREATE TABLE IF NOT EXISTS table_1
(
key1 varchar(32),
key2 varchar(32),
key3 varchar(32),
value1 int,
value2 varchar(128),
value3 Decimal(20, 6),
data_deal_datetime DateTime COMMENT ' Data processing time ',
data_status INT COMMENT ' Whether the data is deleted ,1 Is normal ,-1 Indicates that the data has been deleted '
)
ENGINE=OLAP
UNIQUE KEY(`key1`,`key2`,`key3`)
COMMENT "xxx"
DISTRIBUTED BY HASH(`key2`) BUCKETS 32
PROPERTIES (
"storage_type"="column",
"replication_num" = "3",
"function_column.sequence_type" = 'DateTime'
);
- data_deal_datetime Mainly the same key The judgment basis of data coverage in case of
- data_status It is compatible with the deletion of data by the business library
Data import task
CREATE ROUTINE LOAD database.table1 ON table1
COLUMNS(key1,key2,key3,value1,value2,value3,data_deal_datetime,data_status),
ORDER BY data_deal_datetime
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "10",
"max_batch_rows" = "500000",
"max_batch_size" = "209715200",
"format" = "json",
"json_root" = "$.data",
"jsonpaths"="[\"$.key1\",\"$.key2\",\"$.key3\",\"$.value1\",\"$.value2\",
\"$.value3\",\"$.data_deal_datetime\",\"$.data_status\"]"
)FROM KAFKA
(
"kafka_broker_list"="broker1_ip:port1,broker2_ip:port2,broker3_ip:port3",
"kafka_topic"="topic_name",
"property.group.id"="group_id",
"property.kafka_default_offsets"="OFFSET_BEGINNING"
);
- ORDER BY data_deal_datetime Express basis data_deal_datetime Field to overwrite key Same data
- desired_concurrent_number Indicates the desired concurrency .
- Maximum execution time of each subtask .
- Maximum number of rows read per subtask .
- Maximum number of bytes read per subtask .
Task monitoring and alarm
import pymysql # Import pymysql
import requests,json
# Open database connection
db= pymysql.connect(host="host",user="user",
password="passwd",db="database",port=port)
# Use cursor() Method get operation cursor
cur = db.cursor()
#1. Query operation
# To write sql Query statement
sql = "show routine load"
cur.execute(sql) # perform sql sentence
results = cur.fetchall() # Get all the records of the query
for row in results :
name = row[1]
state = row[7]
if state != 'RUNNING':
err_log_urls = row[16]
reason_state_changed = row[15]
msg = "doris The data import task is abnormal :\n name=%s \n state=%s \n reason_state_changed=%s \n err_log_urls=%s \n About to automatically resume , Please check the error message " % (name, state,
reason_state_changed, err_log_urls)
payload_message = {
"msg_type": "text",
"content": {
"text": msg
}
}
url = 'lark Call the police url'
s = json.dumps(payload_message)
r = requests.post(url, data=s)
cur.execute("resume routine load for " + name)
cur.close()
db.close()
Data model
Aggregate
CREATE TABLE tmp_table_1
(
user_id varchar(64) COMMENT " user id",
channel varchar(64) COMMENT " User source channel ",
city_code varchar(64) COMMENT " User's city code ",
last_visit_date DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT " Last time the user visited ",
total_cost BIGINT SUM DEFAULT "0" COMMENT " Total user consumption "
)
ENGINE=OLAP
AGGREGATE KEY(user_id, channel, city_code)
DISTRIBUTED BY HASH(user_id) BUCKETS 6
PROPERTIES("storage_type"="column","replication_num" = "1"):
insert into tmp_table_1 values('suh_001','JD','001','2022-01-01 00:00:01','57');
insert into tmp_table_1 values('suh_001','JD','001','2022-02-01 00:00:01','76');
insert into tmp_table_1 values('suh_001','JD','001','2022-03-01 00:00:01','107');
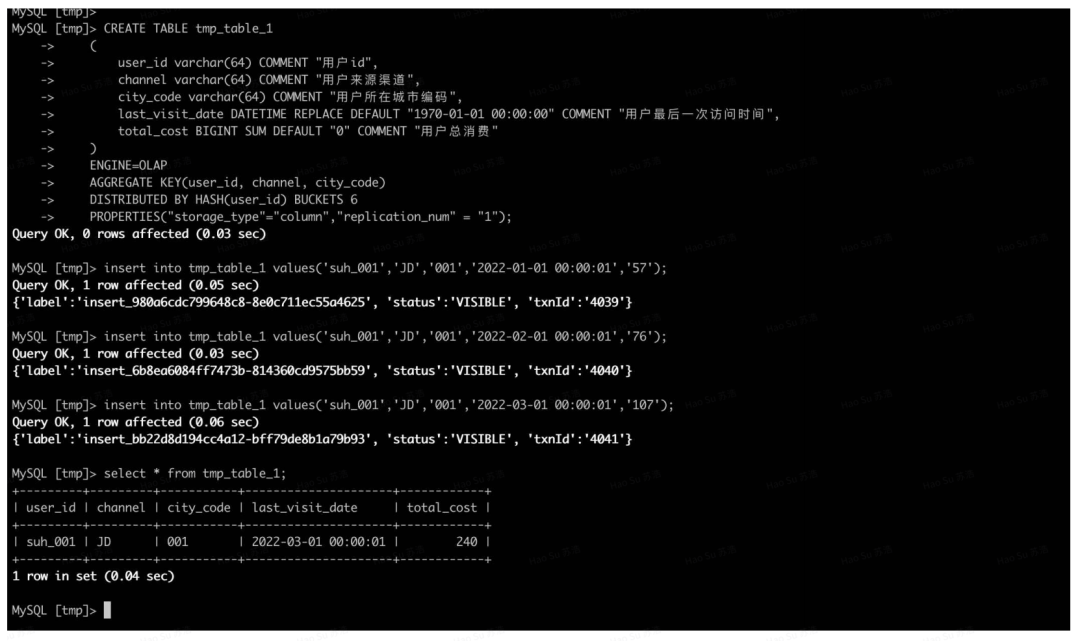
Unique Model
Duplicate Model
CREATE TABLE tmp_table_2
(
user_id varchar(64) COMMENT " user id",
channel varchar(64) COMMENT " User source channel ",
city_code varchar(64) COMMENT " User's city code ",
visit_date DATETIME COMMENT " User login time ",
cost BIGINT COMMENT " User consumption amount "
)
ENGINE=OLAP
DUPLICATE KEY(user_id, channel, city_code)
DISTRIBUTED BY HASH(user_id) BUCKETS 6
PROPERTIES("storage_type"="column","replication_num" = "1");
insert into tmp_table_2 values('suh_001','JD','001','2022-01-01 00:00:01','57');
insert into tmp_table_2 values('suh_001','JD','001','2022-02-01 00:00:01','76');
insert into tmp_table_2 values('suh_001','JD','001','2022-03-01 00:00:01','107');

Suggestions on the selection of data model
summary


边栏推荐
猜你喜欢
AntDB数据库在线培训开课啦!更灵活、更专业、更丰富
ping: www.baidu. Com: unknown name or service

TDengine可通过数据同步工具 DataX读写

关于Unity中的transform.InverseTransformPoint, transform.InverseTransofrmDirection

Memcached comprehensive analysis – 2 Understand memcached memory storage

Shengzhe technology AI intelligent drowning prevention service launched

2022国际女性工程师日:戴森设计大奖彰显女性设计实力
自己总结的wireshark抓包技巧

memcached完全剖析–1. memcached的基础

二叉搜索树模板
随机推荐
dp问题集
一文理解OpenStack网络
【吴恩达笔记】多变量线性回归
在每个树行中找最大值[分层遍历之一的扩展]
MySQL optimizes query speed
Make tea and talk about heroes! Leaders of Fujian Provincial Development and Reform Commission and Fujian municipal business office visited Yurun Health Division for exchange and guidance
Bld3 getting started UI
使用Adb连接设备时提示设备无权限
如何做到全彩户外LED显示屏节能环保
字节的软件测试盆友们你们可以跳槽了,这还是你们心心念念的字节吗?
Byte software testing basin friends, you can change jobs. Is this still the byte you are thinking about?
socket(1)
leetcode-201_2021_10_17
队列实现原理和应用
双链表实现
socket(2)
Web project deployment
SYSCALL_ Define5 setsockopt code flow
基于kruskal的最小生成树
Memcached full profiling – 1 Fundamentals of memcached