当前位置:网站首页>Machine Learning - Ensemble Learning
Machine Learning - Ensemble Learning
2022-08-05 10:57:00 【Ding Jiaxiong】
10. 集成学习
文章目录
通过建立几个模型来解决单一预测问题
10.1 工作原理
生成多个分类器/模型,各自独立地学习和作出预测
- 这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测
10.2 Two core tasks in machine learning
如何优化训练数据 解决 欠拟合问题
如何提升泛化性能 解决 过拟合问题
10.3 boosting和Bagging

10.4 Bagging
主要实现过程
- 采样
- 学习
- 集成
10.5 随机森林构造过程
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定
随机森林 = Bagging + 决策树

10.5.1 关键步骤
- 1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
- 2) 随机去选出m个特征, m <<M,建立决策树
10.6 随机森林API
10.6.1 sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
n_estimators:integer,optional(default = 10)森林里的树木数量
Criterion:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
max_features="auto”,每个决策树的最大特征数量
- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features)(same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
10.6.2 超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
10.7 bagging集成优点
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
10.7.1 优点
- 均可在原有算法上提高约2%左右的泛化正确率
- 简单, 方便, 通用
10.8 Boosting集成
每新加入一个弱学习器,整体能力就会得到提升
10.8.1 代表算法
- Adaboost
- GBDT
- XGBoost
10.8.2 AdaBoost的构造过程小结

10.8.3 API
- from sklearn.ensemble import AdaBoostClassifier
10.9 bagging集成与boosting集成的区别
10.9.1 数据方面
- Bagging:对数据进行采样训练;
Boosting:根据前一轮学习结果调整数据的重要性.
10.9.2 投票方面
- Bagging:所有学习器平权投票;
Boosting:对学习器进行加权投票.
10.9.3 学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
Boosting学习是串行,学习有先后顺序.
10.9.4 主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
10.10 GBDT
梯度提升决策树(GBDT Gradient Boosting Decision Tree)
一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案
GBDT = 梯度下降 + Boosting + 决策树
10.10.1 主要执行思想
- 1.使用梯度下降法优化代价函数;
- 2.使用一层决策树作为弱学习器,负梯度作为目标值;
- 3.利用boosting思想进行集成
10.11 XGBoost
XGBoost= 二阶泰勒展开+boosting+决策树+正则化
- 二阶泰勒展开:每一轮学习中,XGBoost对损失函数进行二阶泰勒展开,使用一阶和二阶梯度进行优化.
- Boosting:XGBoost使用Boosting提升思想对多个弱学习器进行迭代式学习
- 决策树:在每一轮学习中,XGBoost使用决策树算法作为弱学习进行优化.
- 正则化:在优化过程中XGBoost为防止过拟合,在损失函数中加入惩罚项,限制决策树的叶子节点个数以及决策树叶子节点的值.
10.12 泰勒展开式
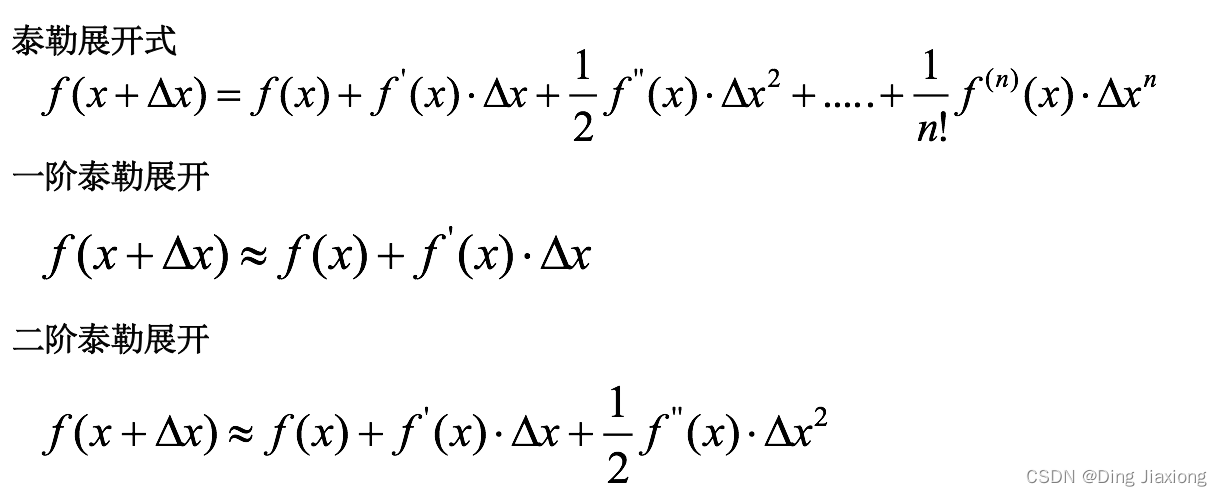
泰勒展开越多,计算结果越精确
边栏推荐
- MMDetection实战:MMDetection训练与测试
- 负载均衡应用场景
- 上位机开发C#语言:模拟STC串口助手接收单片机发送数据
- FPGA:基础入门LED灯闪烁
- Image segmentation model - a combination of segmentation_models_pytorch and albumations to achieve multi-category segmentation
- 七夕来袭!还要做CDH数据迁移怎么办?来看看DistCp
- Score interview (1)----related to business
- Android 开发用 Kotlin 编程语言三 循环控制
- Data Middle Office Construction (10): Data Security Management
- TiDB 6.0 Placement Rules In SQL 使用实践
猜你喜欢

PCB布局必知必会:教你正确地布设运算放大器的电路板

How to choose coins and determine the corresponding strategy research

什么是 DevOps?看这一篇就够了!

Use KUSTO query statement (KQL) to query LOG on Azure Data Explorer Database

反射修改jsessionid实现Session共享

【深度学习】mmclassification mmcls 实战多标签分类任务教程,分类任务

Create a Dapp, why choose Polkadot?
![智源社区AI周刊No.92:“计算复杂度”理论奠基人Juris Hartmanis逝世;美国AI学生九年涨2倍,大学教师短缺;2022智源大会观点报告发布[附下载]](/img/e7/df5a17d372a4324d1a2120829d03e9.png)
智源社区AI周刊No.92:“计算复杂度”理论奠基人Juris Hartmanis逝世;美国AI学生九年涨2倍,大学教师短缺;2022智源大会观点报告发布[附下载]
PCB layout must know: teach you to correctly lay out the circuit board of the op amp

登录功能和退出功能(瑞吉外卖)
随机推荐
Oracle 19.3 restart 环境
MySQL 中 auto_increment 自动插入主键值
拓朴排序例题
#yyds干货盘点#【愚公系列】2022年08月 Go教学课程 001-Go语言前提简介
Data Middle Office Construction (10): Data Security Management
数据可视化(一)
R语言使用yardstick包的pr_curve函数评估多分类(Multiclass)模型的性能、查看模型在多分类每个分类上的ROC曲线(precision(精准率),R代表的是recall(召回率)
智能算力的枢纽如何构建?中国云都的淮海智算中心打了个样
How to choose coins and determine the corresponding strategy research
【OpenCV】-仿射变换
OpenHarmony如何查询设备类型
Login function and logout function (St. Regis Takeaway)
Android 开发用 Kotlin 编程语言三 循环控制
【加密解密】明文加密解密-已实现【已应用】
TiDB 6.0 Placement Rules In SQL 使用实践
负载均衡应用场景
L2-042 老板的作息表
微信小程序标题栏封装
微服务结合领域驱动设计落地
【名词】什么是PV和UV?