当前位置:网站首页>Memory barrier store buffer, invalid queue
Memory barrier store buffer, invalid queue
2022-06-27 06:49:00 【Pangolin without armor】
stay 「 Front content 」 in , We learned that 「 The most primitive 」 Of cpu How is the Cache consistency agreement MESI Working under the guidance of , At the same time, we also find that at this time cpu Performance due to synchronous request remote ( other cpu) Data at a discount . This article will introduce cpu Optimization process of , You will learn about hardware level optimization ——Store Buffer, Invalid Queue, And software level optimization ——cpu Memory barrier instructions .

Original architecture
Performance optimization journey ——Store Buffer
When cpu The required data is in other cpu Of cache Internal time , Need to request , And wait for a response , This is obviously a synchronous behavior , The optimized scheme is also obvious , Asynchronous . The idea is probably in cpu and cache Add one between store buffer,cpu You can write the data to store buffer, At the same time to other cpu Send a message , And then go on with other things , Wait until you get another cpu A response message from , And then the data is transferred from store buffer Move to cache line.

increase store buffer
The plan sounds good ! But there are loopholes in logic , Need to be refined , Let's look at a few vulnerabilities . For example, there is the following code :
a = 1;
b = a + 1;
assert(b == 2);- 1
- 2
In the initial state , hypothesis a,b Values are 0, also a There is cpu1 Of cache line in (Shared state ), The following sequence of operations may occur :

Code execution sequence diagram , indicate cache line The change of
- cpu0 To write a, take a=1 write in store buffer, And issue Read Invalidate news , Continue with other instructions .
- cpu1 received Read Invalidate, return Read Response( contain a=0 Of cache line) and Invalidate ACK,cpu0 received Read Response, to update cache line(a=0).
- cpu0 Start execution b=a+1, here cache line Is not loaded yet b, So he sent out Read Invalidate news , Load from memory b=0, meanwhile cache line There is already a=0, So I got b=1, Status as Modified state .
- cpu0 obtain b=1, Assertion failed .
- cpu0 take store buffer Medium a=1 Pushed to the cache line, But it's too late .
The root cause of this problem lies in the same cpu Existence is right a Two copies of , One in cache, One in store buffer, and cpu Calculation b=a+1 when ,a and b The values of all come from cache. It seems that the execution order of the code is like this :
b = a + 1;
a = 1;
assert(b == 2);- 1
- 2
This problem needs to be optimized .
Thinking questions : The above sequence of operations is only one possibility , Specific response ( Operation 2) When it will come is uncertain , Then suppose the response is in cpu0 Calculation “b=a+1” What will happen next ?
Performance optimization journey ——Store Forwarding
store buffer Problems that may lead to breaking the program sequence , The hardware engineer is in store buffer On the basis of , It's realized again ”store forwarding” technology : cpu Can be directly from store buffer Load data in , That is, support will cpu Deposit in store buffer Data transfer (forwarding) For subsequent loading operations , Without going through cache.

Although the same problem has been solved now cpu The problem of reading and writing data , But there are still loopholes , Let's look at concurrent programs :
void foo() {
a = 1;
b = 1;
}
void bar() {
while (b == 0) continue;
assert(a == 1)
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
In the initial state , hypothesis a,b Values are 0,a Exist in cpu1 Of cache in ,b Exist in cpu0 Of cache in , Are all Exclusive state ,cpu0 perform foo function ,cpu1 perform bar function , The expected assertion of the above code is true . So let's look at the execution sequence :

Code execution sequence diagram
- cpu1 perform while(b == 0), because cpu1 Of Cache There is no b, issue Read b news
- cpu0 perform a=1, because cpu0 Of cache There is no a, So it will a( Current value 1) Write to store buffer And issue Read Invalidate a news
- cpu0 perform b=1, because b It already exists in cache in , And for Exclusive state , Therefore, writing can be performed directly
- cpu0 received Read b news , take cache Medium b( Current value 1) Return to cpu1, take b Write back to memory , And will cache Line Status changed to Shared
- cpu1 Received contains b Of cache line, end while (b == 0) loop
- cpu1 perform assert(a == 1), Because of this time cpu1 cache line Medium a Still for 0 And it works (Exclusive), Assertion failed
- cpu1 received Read Invalidate a news , Return contains a Of cache line, And include the local a Of cache line Set as Invalid, However, it is too late .
- cpu0 received cpu1 From here cache line, And then store buffer Medium a( Current value 1) Refresh to cache line
The reason for this problem is cpu I do not know! a, b Data dependency between ,cpu0 Yes a And others cpu signal communication , So there is a delay , And yes b Write directly to modify local cache Just go , therefore b Than a First in cache Enter into force , Lead to cpu1 Read b=1 when ,a It still exists in store buffer in . From a code point of view ,foo The function seems to look like this :
void foo() {
b = 1;
a = 1;
}- 1
- 2
- 3
foo Function code , Even if it's store forwarding Nor can it be prevented from being cpu“ rearrangement ”, Although this does not affect foo The correctness of the function , But it will affect all dependencies foo Function assignment order thread . It seems that we need to continue to optimize !
Performance optimization journey —— Write barrier instructions
up to now , We found out ” Command rearrangement “ One of the essence of [1],cpu In order to optimize the execution efficiency of instructions , Introduced store buffer(forwarding), This leads to a change in the order in which instructions are executed . To ensure this order consistency , Hardware cannot be used for optimization , It needs to be supported at the software level , you 're right ,cpu Provides a write barrier (write memory barrier) Instructions ,Linux The operating system encapsulates the write barrier instruction into smp_wmb() function ,cpu perform smp_mb() The idea is , Will first put the current store buffer Swipe the data in to cache after , Then execute the... After the barrier “ Write operation ”, There are two ways to realize this idea : One is to simply brush store buffer, But if it's remote cache line No return , You need to wait , Second, the current store buffer Marking entries in , Then put the... Behind the barrier “ Write operation ” Also wrote store buffer in ,cpu Keep doing other things , When all the marked items are brushed to cache line, Then brush the following items ( The concrete realization is not the goal of this article ), Take the second implementation logic as an example , Let's look at the following code execution process :
void foo() {
a = 1;
smp_wmb()
b = 1;
}
void bar() {
while (b == 0) continue;
assert(a == 1)
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

- cpu1 perform while(b == 0), because cpu1 Of cache There is no b, issue Read b news .
- cpu0 perform a=1, because cpu0 Of cache There is no a, So it will a( Current value 1) Write to store buffer And issue Read Invalidate a news .
- cpu0 notice smp_wmb() Memory barrier , It marks the current store buffer All entries in ( namely a=1 Marked ).
- cpu0 perform b=1, Even though b It already exists in cache in (Exclusive), But because of store buffer There are also marked entries in , therefore b Can't write directly , Only... Can be written first store buffer in .
- cpu0 received Read b news , take cache Medium b( Current value 0) Return to cpu1, take b Write back to memory , And will cache line Status changed to Shared.
- cpu1 Received contains b Of cache line, continue while (b == 0) loop .
- cpu1 received Read Invalidate a news , Return contains a Of cache line, And local cache line Set as Invalid.
- cpu0 received cpu1 The transmission contains a Of cache line, And then store buffer Medium a( Current value 1) Refresh to cache line, And will cache line The state is set to Modified.
- because cpu0 Of store buffer All marked items in have been refreshed to cache, here cpu0 You can try to store buffer Medium b=1 Refresh to cache, But because it contains B Of cache line It's not Exclusive It is Shared, So we need to start first Invalidate b news .
- cpu1 received Invalidate b news , Will include b Of cache line Set as Invalid, return Invalidate ACK.
- cpu1 Carry on while(b == 0), here b No longer cache in , So send out Read news .
- cpu0 received Invalidate ACK, take store buffer Medium b=1 write in Cache.
- cpu0 received Read news , Return contains b New value cache line.
- cpu1 Received contains b Of cache line, Can continue to execute while(b == 0), End cycle , And then execute assert(a == 1), here a Not in its cache in , So send out Read news .
- cpu0 received Read news , Return contains a New value cache line.
- cpu1 Received contains a Of cache line, The assertion is true .
Performance optimization journey ——Invalid Queue
Introduced store buffer, Supplemented by store forwarding, Write barriers , It seems that we can negotiate with each other , However, there is another problem that has not been considered : store buffer The size of is limited , All write operations occur cache missing( The data is no longer local ) Will use store buffer, Especially when there is a memory barrier , All subsequent write operations ( Whether or not cache missing) Will squeeze in store buffer in ( until store buffer The items before the middle barrier are processed ), therefore store buffer It's easy to fill , When store buffer After full ,cpu It will still be stuck waiting for the corresponding Invalidate ACK To deal with store buffer Items in . So we still have to go back to Invalidate ACK In the to ,Invalidate ACK The main reason for the time-consuming is cpu First put the corresponding cache line Set as Invalid And then back Invalidate ACK, A very busy cpu May cause other cpu Waiting for it to come back Invalidate ACK. The solution is to change synchronization into asynchrony : cpu There's no need to deal with cache line Then go back to Invalidate ACK, Instead, you can put Invalid Put the message on a request queue Invalid Queue, And then back to Invalidate ACK.CPU It can be processed later Invalid Queue The messages in the , Greatly reduce Invalidate ACK response time . At this time CPU Cache Structure diagram is as follows :

Joined the invalid queue after ,cpu Dealing with anything cache line Of MSEI Before the State , Must first see invalid queue Is there any such thing as cache line Of Invalid The message was not processed . in addition , It also destroys memory consistency again . Please look at the code. :
void foo() {
a = 1;
smp_wmb()
b = 1;
}
void bar() {
while (b == 0) continue;
assert(a == 1)
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Still assuming a, b The initial value of 0,a stay cpu0,cpu1 In both Shared state ,b stay cpu0 Monopoly (Exclusive state ),cpu0 perform foo,cpu1 perform bar:
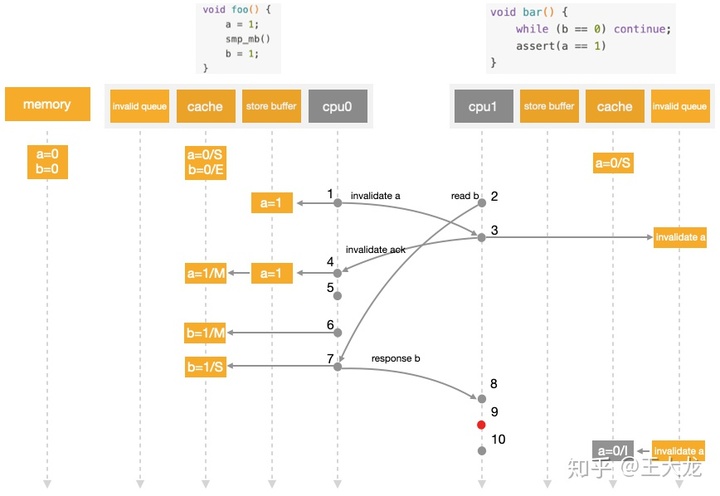
- cpu0 perform a=1, Because it contains a Of cache line, take a write in store buffer, And issue Invalidate a news .
- cpu1 perform while(b == 0), It has no b Of cache, issue Read b news .
- cpu1 received cpu0 Of Invalidate a news , Put it in the Invalidate Queue, return Invalidate ACK.
- cpu0 received Invalidate ACK, take store buffer Medium a=1 Refresh to cache line, Marked as Modified.
- cpu0 notice smp_wmb() Memory barrier , But because of it store buffer It's empty , So it can skip the statement directly .
- cpu0 perform b=1, Because of its cache Monopoly b, So write directly ,cache line Marked as Modified.
- cpu0 received cpu1 The hair Read b news , Will include b Of cache line Write back to memory and return the cache line, The local cache line Marked as Shared.
- cpu1 Received contains b( Current value 1) Of cache line, end while loop .
- cpu1 perform assert(a == 1), Because its local contains a Old value cache line, Read a Initial value 0, Assertion failed .
- cpu1 Only then can we deal with Invalid Queue The messages in the , Will include a Old value cache line Set as Invalid.
The problem is that 9 In step cpu1 In the reading a Of cache line when , No prior treatment Invalid Queue Should be cache line Of Invalid operation , What do I do ? Actually cpu It also provides Read barrier instructions ,Linux Encapsulate it as smp_rmb() function , Insert this function into bar Function , Just like this. :
void foo() {
a = 1;
smp_wmb()
b = 1;
}
void bar() {
while (b == 0) continue;
smp_rmb()
assert(a == 1)
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
and smp_wmb() similar ,cpu perform smp_rmb() When the , Will first put the current invalidate queue After the data in , Then execute the... After the barrier “ Read operation ”, The specific operation sequence will not be repeated .
Memory barrier
up to now , We have come into contact with 「 Reading barrier 」 and 「 Write barriers 」, In this section, we will talk about memory barriers . First, there are several different types of memory barriers , such as 「 Reading barrier 」、「 Write barriers 」、「 Full screen barrier 」 wait , each cpu Vendors can choose which semantics to support and how to support , So different cpu The semantics supported are different , The corresponding instructions are also different , Let's take a look at the figure below :

The horizontal axis indicates 8 Memory barrier semantics , The vertical axis represents different cpu, This figure shows the difference cpu Support for memory barrier semantics . In fact, as a programmer of application development, there is no need to go further ,Linux The operating system is oriented to cpu Abstract out a set of memory barrier functions , They are :
- smp_rmb(): stay invalid queue After the data has been brushed, the read operation behind the barrier is performed .
- smp_wmb(): stay store buffer After the data is brushed, the write operation behind the barrier is performed .
- smp_mb(): It has both read barrier and write barrier functions .
- smp_read_barrier_depends() that forces subsequent operations that depend on prior operations to be ordered. This primitive is a no-op on all platforms except Alpha.
- mmiowb() that forces ordering on MMIO writes that are guarded by global spinlocks. This primitive is a no-op on all platforms on which the memory barriers in spinlocks already enforce MMIO ordering. The platforms with a nonno-op mmiowb() definition include some (but not all) IA64, FRV, MIPS, and SH systems. This primitive is relatively new, so relatively few drivers take advantage of it.
The last two don't want to translate , We'll learn more about it when we use it .
summary
This passage cpu Optimization process of , Finally, the concept of memory barrier is introduced , It can be seen that , The memory barrier is above the hardware , The last level of consistency under the operating system . in addition , When I read the description of the execution sequence in the original paper, I felt very confused , So I came up with a sequence diagram to represent the code execution process cache line The state of change , I hope it will be helpful to your understanding .
Memory Barriers: a Hardware View for Software Hackerswww.puppetmastertrading.comCache Consistency and memory model wudaijun.com Uploading … Re upload cancel
Reference resources
- ^「 Command rearrangement 」 There are two types , One is 「 active 」, The compiler will actively rearrange the code so that a specific cpu Faster execution . Another type is 「 Passive 」, To asynchronize the execution of instructions , introduce Store Buffer and Invalidate Queue, But it led to 「 The order of instructions changes 」 Side effects .
边栏推荐
- EasyExcel:读取Excel数据到List集合中
- 记一次Spark报错:Failed to allocate a page (67108864 bytes), try again.
- Optimistic and pessimistic affairs
- 【LeetCode】Day90-二叉搜索树中第K小的元素
- tar: /usr/local:归档中找不到tar: 由于前次错误,将以上次的错误状态退出
- Modeling competition - optical transport network modeling and value evaluation
- JVM class loading mechanism
- When there are multiple El select, the selected value is filtered by El select, and the last selected value is filtered by the second El select
- Information System Project Manager - Chapter VII project cost management
- vs怎么配置OpenCV?2022vs配置OpenCV详解(多图)
猜你喜欢

vs怎么配置OpenCV?2022vs配置OpenCV详解(多图)

Mathematical modeling contest for graduate students - optimal application of UAV in rescue and disaster relief
解决 Win10 Wsl2 IP 变化问题

Unsafe中的park和unpark
分数阶PID控制

Redis 缓存穿透、缓存击穿、缓存雪崩
Redis cache penetration, cache breakdown, cache avalanche

Assembly language - Wang Shuang Chapter 11 flag register - Notes

AHB2APB桥接器设计(2)——同步桥设计的介绍

2018年数学建模竞赛-高温作业专用服装设计
随机推荐
An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
Block level elements & inline elements
LeetCode 0086. Separate linked list
G1 and ZGC garbage collector
高斯分布Gaussian distribution、線性回歸、邏輯回歸logistics regression
SQL 注入绕过(一)
tracepoint
Ora-00909: invalid number of parameters, caused by concat
Mathematical modeling contest for graduate students - optimal application of UAV in rescue and disaster relief
Redis 缓存穿透、缓存击穿、缓存雪崩
JVM garbage collection mechanism
Crawler learning 5--- anti crawling identification picture verification code (ddddocr and pyteseract measured effect)
winow10安装Nexus nexus-3.20.1-01
Classical cryptosystem -- substitution and replacement
Partial function of Scala
机 器 学 习
Force buckle 179, max
高斯分布Gaussian distribution、线性回归、逻辑回归logistics regression
pytorch Default process group is not initialized
Transaction overview of tidb