当前位置:网站首页>The more AI evolves, the more it resembles the human brain! Meta found the "prefrontal cortex" of the machine. AI scholars and neuroscientists were surprised
The more AI evolves, the more it resembles the human brain! Meta found the "prefrontal cortex" of the machine. AI scholars and neuroscientists were surprised
2022-06-25 03:42:00 【QbitAl】
Fish and sheep Xiao Xiao From the Aofei temple
qubits | official account QbitAI
You may not believe it , There is one. AI Just proven , The way we deal with voice is the same as The brain The mystery is similar .
Even in structure Can correspond to each other ——
Scientists in AI Directly located on the body “ Visual cortex ”.
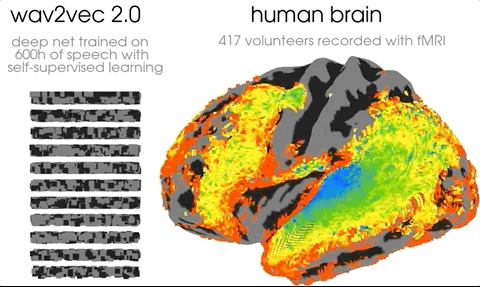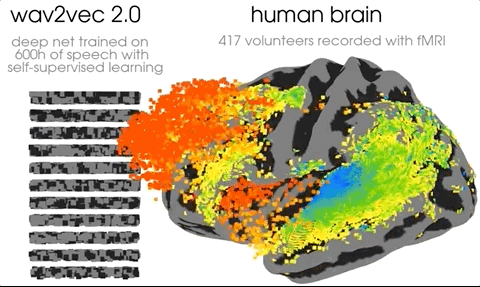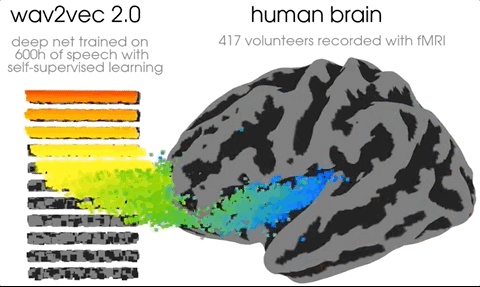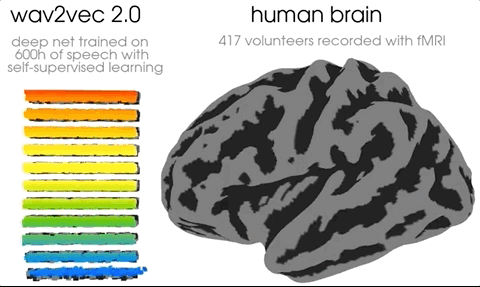
This one comes from Meta AI And so on po Out , It immediately exploded on social media . A wave of neuroscientists and AI The researchers went to the onlookers .

LeCun Praise this is “ Excellent work ”: Self supervision Transformer Between stratification and human auditory cortex , It is indeed closely related .

Some netizens took the opportunity to make fun of :Sorry Marcus , but AGI It's really coming .

however , The research has also aroused the curiosity of some scholars .
For example, Dr. of neuroscience, McGill University Patrick Mineault Ask questions :
We published in NeurIPS In a paper of , Also tried to fMRI Data and models are linked , But I didn't think there was any relationship between the two .

therefore , What kind of research is this , How does it come to “ This one AI Work like a brain ” The conclusion is ?
AI Learn to work like a human brain
Simply speaking , In this study , Researchers focus on speech processing problems , The self-monitoring model Wav2Vec 2.0 Same as 412 name The brain activity of the volunteers was compared .
this 412 Of the volunteers , Yes 351 People speak English ,28 People speak French ,33 People speak Chinese . The researchers listened to them for about 1 Hours of audio books , And in this process fMRI Their brain activity was recorded .

Model side , Researchers used more than 600 Hours of unlabeled voice training Wav2Vec 2.0.
Corresponding to the volunteer's mother tongue , The model is also divided into English 、 French 、 Three in Chinese , Another one is trained with non speech acoustic scene data set .
Then the models listened to the same audio book of volunteers . The researchers extracted the activation of the model .
Evaluation criteria of relevance , Follow this formula :

among ,X Activate... For the model ,Y For human brain activity ,W For the standard coding model .

From the results , Self supervised learning does make Wav2Vec 2.0 It produces speech representations similar to those of the brain .
As you can see from the above figure , In the primary and secondary auditory cortex ,AI It clearly predicts brain activity in almost all cortical areas .
The researchers also found that AI Of “ Auditory cortex ”、“ Prefrontal cortex ” Which floor is it on .

The picture shows , Auditory cortex and Transformer The first floor of ( Blue ) Best match , The prefrontal cortex is associated with Transformer The deepest layer of ( Red ) Best match .
Besides , The researchers quantitatively analyzed the differences in human ability to perceive native and non-native phonemes , And with Wav2Vec 2.0 Compare the models .
They found that ,AI Just like human beings , Yes “ mother tongue ” Have a stronger ability to distinguish , such as , The French model is easier to perceive the stimulation from French than the English model .
The above results prove ,600 Hours Self supervised learning , Enough to make Wav2Vec 2.0 Learning specific representations of language —— This is similar to what babies come into contact with in the process of learning to speak “ Data volume ” Quite a .

Need to know , Before DeepSpeech2 The paper holds that , Need at least 10000 Hours Voice data ( It has to be the marked one ), To build a good set of voice to text (STT) System .

Once again, neuroscience and AI Boundary discussion
For this study , Some scholars think , It did make some new breakthroughs .
for example , From Google brain Jesse Engel call , This research takes the visualization filter to a new level .
Now? , Not only can you see them in “ Pixel space ” What does it look like , Connect them to “ Brain like space ” You can also simulate the shape in :

For example , front MILA And Google researchers Joseph Viviano Think , This study also proves that fMRI The resting state in (resting-state) Imaging data is meaningful .

But in a discussion , There were also some voices of doubt .
for example , Doctor of neuroscience Patrick Mineault In addition to pointing out that they have done similar research but have not reached a conclusion , Also gave some of their own doubts .

He thinks that , This study does not really prove that it measures “ Voice Processing ” The process of .
Compared to the speed at which people talk ,fMRI The speed of measuring the signal is actually very slow , Therefore, we hastily come to the conclusion that “Wav2vec 2.0 Learning the behavior of the brain ” The conclusion is unscientific .
Of course ,Patrick Mineault He said that he did not deny the view of the study , He himself is “ One of the author's fans ”, But this study should give some more convincing data .
In addition, some netizens think ,Wav2vec And the input of human brain is not the same , One is the processed waveform , But the other is the original waveform .

Regarding this , One of the authors 、Meta AI researcher Jean-Rémi King summary :
Simulate human level intelligence , There is really a long way to go . But at least for now , We may be on the right path .

Do you think? ?
Address of thesis :
https://arxiv.org/abs/2206.01685
Reference link :
[1]https://twitter.com/patrickmineault/status/1533888345683767297
[2]https://twitter.com/JeanRemiKing/status/1533720262344073218
[3]https://www.reddit.com/r/singularity/comments/v6bqx8/toward_a_realistic_model_of_speech_processing_in/
[4]https://twitter.com/ylecun/status/1533792866232934400
边栏推荐
- 服乔布斯不服库克,苹果传奇设计团队解散内幕曝光
- AI writes its own code to let agents evolve! The big model of openai has the flavor of "human thought"
- The file attributes downloaded by the browser are protected. How to remove them
- CVPR大会现场纪念孙剑博士,最佳学生论文授予同济阿里,李飞飞获黄煦涛纪念奖...
- Is it safe to open an account on your mobile phone?
- 20年ICPC澳门站L - Random Permutation
- 陆奇首次出手投资量子计算
- 老叶的祝福
- Administrator如何禁止另一个人踢掉自己?
- X86 CPU, critical! The latest vulnerability has caused heated discussion. Hackers can remotely steal keys. Intel "all processors" are affected
猜你喜欢

Performance rendering of dSPACE

Getting started with unityshader Essentials - PBS physics based rendering

中国天眼发现地外文明可疑信号,马斯克称星舰7月开始轨道试飞,网信办:APP不得强制要求用户同意处理个人信息,今日更多大新闻在此...

用CPU方案打破内存墙?学PayPal堆傲腾扩容量,漏查欺诈交易量可降至1/30

Before the age of 36, Amazon transgender hackers were sentenced to 20 years' imprisonment for stealing data from more than 100million people!

Tencent Open Source Project "Yinglong" est devenu un projet Apache de haut niveau: l'ancien Service à long terme Wechat payment, peut maintenir un million de milliards de niveaux de traitement de flux

What is an SSL certificate and what are the benefits of having an SSL certificate?

About sizeof() and strlen in array

Copilot免费时代结束!正式版67元/月,学生党和热门开源项目维护者可白嫖
什么是SSL证书,拥有一个SSL证书有什么好处?
随机推荐
陆奇首次出手投资量子计算
What is an SSL certificate and what are the benefits of having an SSL certificate?
发布功能完成02《ivx低代码签到系统制作》
好用的字典-defaultdict
New solution of 202112-2 sequence query
Getting started with unityshader Essentials - PBS physics based rendering
Is flush a regular platform? Is it safe for flush to open an account
X86 CPU, critical! The latest vulnerability has caused heated discussion. Hackers can remotely steal keys. Intel "all processors" are affected
Is it safe for tonghuashun securities to open an account
吴恩达机器学习新课程又来了!旁听免费,小白友好
Two way combination of business and technology to build a bank data security management system
Skywalking implements cross thread trace delivery
Is it safe to open an online stock account?
China's SkyEye found suspicious signals of extraterrestrial civilization. Musk said that the Starship began its orbital test flight in July. Netinfo office: app should not force users to agree to proc
Is it safe to open an account in the way of winning 100% of the new bonds
When people look at the industrial Internet from the Internet like thinking and perspective, they have actually fallen into a dead end
Array - fast and slow pointer in one breath
Easy to use dictionary -defaultdict
DSPACE set zebra crossings and road arrows
Rebeco:使用机器学习预测股票崩盘风险