当前位置:网站首页>11.1.1 overview of Flink_ Flink overview
11.1.1 overview of Flink_ Flink overview
2022-06-26 00:26:00 【Loves_ dccBigData】
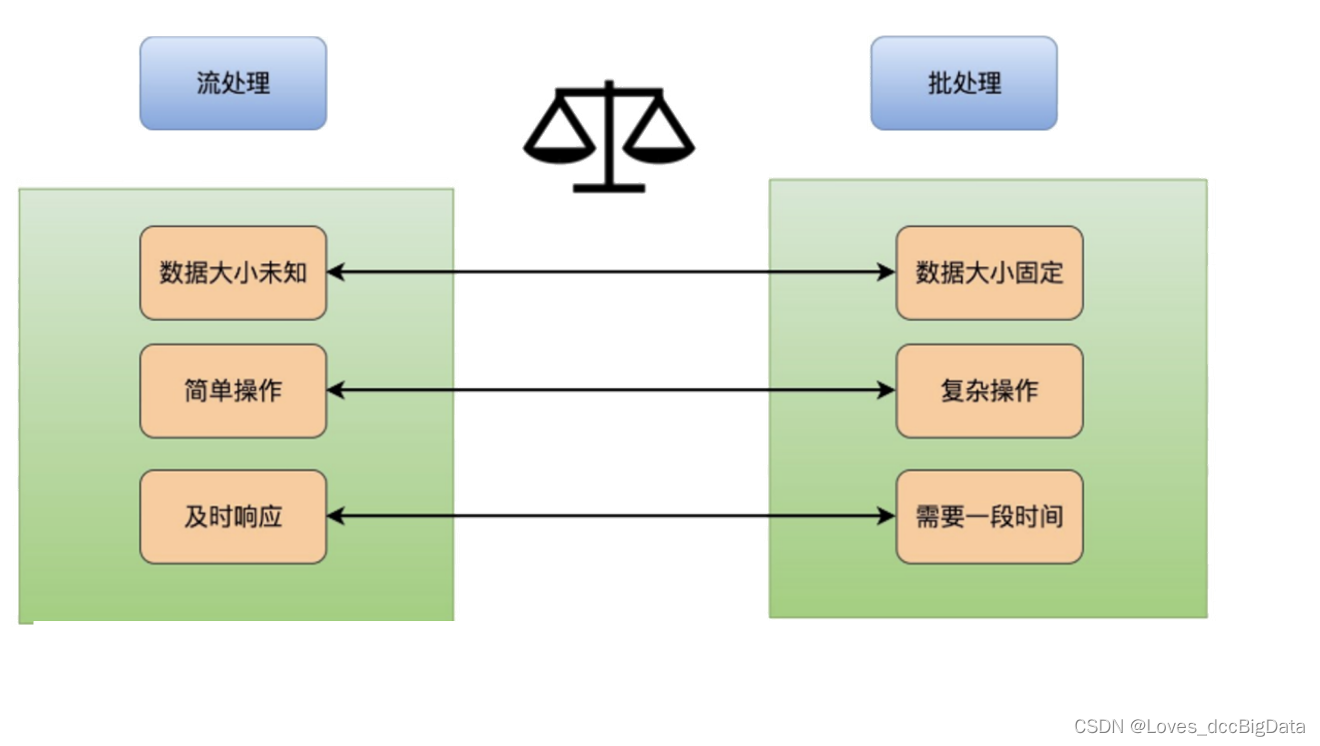
1、 Stream processing and batch processing
2、 Bounded flow and unbounded flow
Bounded flow : The amount of data is limited ,eg:mysql etc.
By incident : Data has no boundaries , commonly kafka Li data
3、flink summary , characteristic
(1)flink Is a distributed data processing engine
(2) Support high throughput 、 Low latency 、 High performance streaming
(3) Support windows with event time (Window)
(4) operation
Supports stateful computing Exactly-once semantics
(5) Support highly flexible windows (Window) operation , Support based on time、count、session, as well as data-driven Window operation
(6) Support continuous flow model with back pressure function
(7) Support based on lightweight distributed snapshot (Snapshot) Implemented fault tolerance
(8) A runtime supports Batch on Streaming Deal with and Streaming Handle
(9)Flink stay JVM Internal implementation of their own memory management , Avoid the appearance of oom
(10) Support iterative calculation
(11) Support automatic program optimization : Avoid specific situations Shuffle、 Expensive operations like sorting , Intermediate results need to be cached
4、 Deployment environment
(1) Local mode local
(2)cluster Cluster pattern (standalone,yarn)
(3) Cloud model cloud
5、flink Continuous flow execution process ( important )
KeyBy: Will be the same key To the same Task in
— The default is hash Partition
—flink and spark Both are coarse-grained resource scheduling
— Called upstream and downstream , Don't cry map,reduce
—flink It is a scheduling
— It is generally a stateful operator

spark Of shuffle The process :
wait for map Execute after the end reduce End
flink Of shuffle The process :
flink All in task Start together , Wait for the data to come
The upstream task Downstream task Conditions for sending data :
(1) The data reaches 32k(buffle Cache size , Prevent frequent data sending IO Consume )
(2) Time to achieve 200 millisecond
6、 Dispatch
spark Task scheduling :
(1) structure DAG Directed acyclic graph
(2) segmentation stage
(3) Put in order stage Send to taskschedule
(4)taskschedule take task Send to executor In the implementation of
fink Task scheduling
(1) structure DataFlow
(2) Split into multiple task
(3) Will all task Deployment launch
(4) Wait for the data to come , Processing data
7、 Run Guide Package
logger For printing logs , You also need to put the log file in resources Only in the middle can
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
</dependencies>
边栏推荐
- Smt贴片机工作流程
- Drag the mouse to rotate the display around an object
- farsync 简易测试
- Rocket message storage
- EBS r12.2.0 to r12.2.6
- Use Coe_ load_ sql_ profile. SQL fixed execution plan
- smt贴片加工行业常见术语及知识汇总
- Mysql5.7 is in the configuration file my Ini[mysqld] cannot be started after adding skip grant tables
- Multi-Instance Redo Apply
- 1-9Vmware中网络配置
猜你喜欢










随机推荐
如何绕过SSL验证
farsync 简易测试
毕业季 | 在不断探索中拟合最好的自己
dbca静默安装及建库
SQL中只要用到聚合函数就一定要用到group by 吗?
Use Coe_ load_ sql_ profile. SQL fixed execution plan
19c安装psu 19.12
Why do we need to make panels and edges in PCB production
在同一台机器上部署OGG并测试
SMT贴片加工PCBA板清洗注意事项
实现异步的方法
Logstash discards log data that does not match the file name exactly
【图像检测】基于高斯过程和Radon变换实现血管跟踪和直径估计附matlab代码
mtb13_Perform extract_blend_Super{Candidate(PrimaryAlternate)_Unique(可NULL过滤_Foreign_index_granulari
leetcode. 14 --- longest public prefix
【TSP问题】基于Hopfield神经网络求解旅行商问题附Matlab代码
深圳台电:联合国的“沟通”之道
86. (cesium chapter) cesium overlay surface receiving shadow effect (gltf model)
每日刷题记录 (四)
Introduction to anchor free decision