当前位置:网站首页>No manual prior is required! HKU & Tongji & lunarai & Kuangshi proposed self supervised visual representation learning based on semantic grouping, which significantly improved the tasks of target dete
No manual prior is required! HKU & Tongji & lunarai & Kuangshi proposed self supervised visual representation learning based on semantic grouping, which significantly improved the tasks of target dete
2022-06-26 16:37:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares papers 『Self-Supervised Visual Representation Learning with Semantic Grouping』, No manual priors are required ! HKU & Tongji &LunarAI& Open vision ( Zhangxiangyu team ) Self supervised visual representation learning based on semantic grouping is proposed , Significantly improve target detection 、 Instance segmentation and semantic segmentation tasks !
The details are as follows :

Thesis link :https://arxiv.org/abs/2205.15288
01
Abstract
In this paper , The author solves the problem of learning visual representation from unlabeled scene centric data . Existing work has demonstrated the potential of utilizing complex underlying structures in scenario centric data ; For all that , They usually rely on hand-made object priors or special excuse tasks to build learning frameworks , This could undermine universality .
contrary , The author proposes to carry out contrastive learning from data-driven semantic slots , namely SlotCon, For joint semantic grouping and representation learning . Semantic grouping is performed by assigning pixels to a set of learnable prototypes , These prototypes can be adapted to each sample by concentrating features , And form new grooves (slot). Slots based on the learned data , Use comparative goals to express learning , Enhanced feature resolution , This in turn facilitates the grouping of semantically related pixels .
Compared with previous work , By optimizing semantic grouping and contrastive learning at the same time , The method in this paper bypasses the shortcoming of manual prior , Be able to learn objects from scene centric images / Group level representation . Experiments show that , This method can effectively decompose complex scenes into semantic groups for feature learning , And for downstream tasks ( Including target detection 、 Instance segmentation and semantic segmentation ) It's obviously helpful .
02
Motivation
The existing self-monitoring methods have proved , It can be predicted by constructing transformation 、 Instance discrimination and mask The excuse of image modeling is to learn visual representation from unmarked data . among , The method of case-based discrimination , Treat each image as a separate class , And use comparative learning objectives for training , A remarkable success , It helps to improve the performance of many downstream tasks .
However , Much of this success is based on a well planned object - centric data set ImageNet Upper ,ImageNet With downstream applications ( Such as city scene or crowd scene ) There is a big gap in the real data . By simply treating the scene as a whole , Directly apply the instance discrimination excuse task to these real-world data , Will ignore its inherent structure ( for example , Multiple objects and complex layouts ), Thus, the possibility of pre training with scene centered data is limited .
This leads to the point of this article : Learning visual representation from unmarked scene centric data . Recent efforts to address this issue can be broadly divided into two types of research : One class extends the instance discrimination task to pixel level , Used to express learning intensively , This shows strong performance in downstream intensive prediction tasks . However , These methods still lack the ability to model the object level relationships presented in scene centric data , This is essential for learning expression . Another class tries to learn representation at the object level , Most of them still rely heavily on domain specific prior knowledge to discover objects , Including significance estimator 、 Unsupervised objects proposal Algorithm 、 Manual segmentation algorithm or unsupervised clustering . However , If it is supervised by the objective prior value made by hand , Will prevent it from learning objectiveness from the data itself , And it is easy to make mistakes from the prior value . therefore , The ability and versatility of representation will be limited .
In this work , The goal is to propose a fully learnable and data-driven approach , In order to be able to learn representation from scene centric data , To improve efficiency 、 Portability and generalization . say concretely , The author proposes a data-driven semantic slot based contrastive learning , namely SlotCon, For joint semantic grouping and representation learning . Semantic grouping is described as a pixel level deep clustering problem in feature space , The cluster center is initialized as a set of learnable semantic prototypes shared by data sets , Grouping is achieved by assigning pixels to clusters . then , By gently assigning pixels to cluster centers , And gather its features in a weighted way , Forming new features , Also known as slots , The cluster center can be updated for each sample .
Besides , Slots based on data learned from two random views of an image , Use comparative goals for representational learning , The target tries to put the positive slot ( I.e. slots from the same prototype and sample ) Pull together , And push open the negative groove . An optimized representation will enhance the features 、 Distinguishability of prototype and groove , This in turn helps to group semantically consistent pixels together . Compared with previous work , By optimizing semantic grouping and contrastive representation learning at the same time , The method in this paper bypasses the shortcoming of manual prior , Be able to learn objects from scene centric images / Group level representation .
Through the target detection 、 Instance segmentation 、 Semantic segmentation for transfer learning evaluation , The representational learning ability of this model is widely evaluated . The method of this paper is in COCO Pre training and ImageNet-1K The pre training shows good results , It makes up the gap between scene centered and object centered pre training . Besides , The proposed method also achieves remarkable performance in unsupervised segmentation , It shows strong semantic concept discovery ability .
in summary , The author's main contribution in this paper is :1) The author shows , Decomposition of natural scenes ( Semantic grouping ) It can be done in a learnable way , And you can use representations for joint optimization from scratch .2) The authors demonstrate that semantic grouping is essential for learning good representation from scene centric data .3) Combine semantic grouping and representation learning , The author unleashed the potential of scene centered pre training , To a large extent, it makes up for the gap between it and object-oriented pre training , And achieved the most advanced results in various downstream tasks .
03
Method
3.1 Semantic grouping with pixel-level deep clustering
Given a dataset of unlabeled images D, The goal of this article is to learn a set of prototypes , Classify each pixel into a meaningful Group , So that the pixels in the same group have semantic consistency ( Having similar characteristics indicates ), The pixels in different groups are semantically inconsistent . The author finds that this problem can be regarded as unsupervised semantic segmentation , And through pixel level depth clustering to solve .
Intuitively speaking , Semantically meaningful groupings should remain unchanged for data enhancement . therefore , Different enhancements to the same image , The author forces the pixels in the same location to the same cluster center set ( Prototype ) Should have similar distribution scores . In addition to consistent grouping , These groups should also be different from each other , To ensure that the learned representation is differentiated , And avoid trivial solutions . Plus common techniques used in self supervised learning ( Such as nonlinear projection and momentum teacher ), This forms the framework of this paper .

say concretely , As shown in the figure above , The method in this paper consists of two neural networks : The student network is parameterized , Including the encoder 、 Projection and a set of K Learnable prototypes
402 Payment Required
; The teacher network has the same structure as the students , But use different weight sets , The weight is updated to θ The exponential moving average of .Given an input image x, Apply two random enhancements to generate two enhanced views and . Each enhanced view then uses an encoder f Encoded into hidden feature mapping , Then use a multi-layer perceptron (MLP)g To transform , obtain . then , The author uses the corresponding prototype to calculate the distribution of projection (assignment), And force it to be assigned to another view generated by the teacher network t Match :



Among them are the temperature parameters that control the output distribution of the two networks . Due to geometric image enhancement , For example, random cropping 、 Zoom or flip , The scale or layout of the two feature maps and may be inconsistent , So the author performs the inverse enhancement process , Align the spatial position of the prediction on the specified :. Be careful , It's about distribution Q Instead of projection z Perform inverse enhancement , To keep the context information out of the overlapping area , To generate slots .
Alignment based allocation , The author applies the cross entropy loss
402 Payment Required
, To enhance the consistency of distribution scores between spatially aligned pixels from different views . The cross entropy loss of all spatial positions is averaged , To generate packet loss :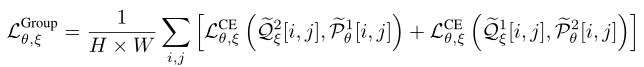
Direct optimization of the above objectives is similar to the unsupervised variant of ordinary teachers . To avoid collapse , Keep average logit, And reduce it when generating teacher assignments . Average logit It stores all the generated by the teacher network logit Exponential moving average of :

among B representative Batch size . Intuitively speaking , Reduce the average logit It will magnify the distribution difference between different pixels , This avoids assigning all pixels to the same prototype . Besides , Set the teacher temperature to be less than the student temperature , To produce clearer goals and avoid uniform distribution . Both of these actions help avoid crashes , And force the web to learn meaningful semantic grouping .
3.2 Group-level representation learning by contrasting slots
When you receive it Slot Attention Inspired by the , The author reuses the allocation of semantic grouping module , In dense projection z Execute note pooling on , To generate group level eigenvectors , As shown in the figure above . therefore , Dense projection z For the corresponding prototype S Of soft assignments A It can also be regarded as the attention coefficient , Describes how the prototype decomposes dense projections into non overlapping groups . This inspired the author to decompose the dense projection . To be specific , about view The resulting dense projection , The author extracts K Slot :

It means Hadamard The product of , A similar operation applies to the teacher network to generate . Be careful , Since the initial slot is shared by the entire dataset , Therefore, the corresponding semantics may be missing in a particular view , Thus, redundant slots are generated . therefore , The author calculates the following binary Indicator , With mask Cannot occupy the slot of the dominant pixel :

The calculation method of is similar to . Then apply the comparative learning objectives , Distinguish between slots with the same semantics in the view and distracted slots :

This goal helps maximize the similarity between different views of the same slot , At the same time, the similarity between slots in another view with different semantics and all slots in other images is minimized . Here, an additional predictor with the same architecture as the projection is applied to the slot , Because according to experience , It can produce more performance . The resulting slot level contrast loss also follows the symmetrical design :

3.3 The overall optimization objective
The author jointly optimizes the semantic grouping goal and the group level comparative learning goal , And use the balance factor to control :

In each training step , Using the gradient of the total loss function to optimize the student network , among η It means the learning rate ; The teacher network is updated to the exponential moving average of the student network , Represents the momentum value . After training , Only the teacher encoder is reserved for downstream tasks .
04
experiment

The above table shows the details of the data set used for pre training .

The table above shows COCO The main results of pre training .COCO There has been a steady improvement in object level pre training , The best performance method is DetCon and ORL, They still rely on an object prior , But it can't beat the most advanced pixel level PixPro Method .
The method in this paper alleviates these limitations , And greatly improved the current object level method in all tasks , Compared with the previous method, it has achieved a consistent improvement . It is worth noting that , The method in this paper can segment the largest and most challenging dataset ADE20K Achieve better performance on , This increases the importance of this work .

The table above shows ImageNet1K The main results of pre training . The method in this article has no effect on the target proposal Carry out selective search , It's not true FPN head Pre training and migration , Still better than most current jobs , And to a large extent, it narrows the relationship with SoCo The gap between .

In the above table , The author reports COCO+ Results of pre training .COCO+ yes COCO train2017 +unlabeled2017 aggregate , This is about twice the number of training images , And greatly increase the diversity of data . The method in this article uses extensions in all COCO+ There are significant improvements in the task of data , It even shows a connection with ImageNet-1K(COCO+ Of 5 Times as big as ) The performance of the best model on pre training is comparable to the results , It shows the great potential of scene centered pre training .

The above table shows the results of unsupervised semantic segmentation , As shown in the table above , The method in this article can surpass the previous PiCIE and SegDiscover,mIoU Improve 4 percentage . meanwhile , Because of the low resolution (7×7 v.s.80×80 Characteristics of figure ) Training models ,pAcc The lower . The author also describes the visualization results , The method in this paper distinguishes the confused objects ( The first 4 Column ), And successfully locate the small object ( The first 5 Column ). Because this method only needs to separate pixels with different semantics in the same image , Therefore, errors in category prediction can be ignored .

The table above lists the number of prototypes , The author observed that the best fit COCO Tested K by 256, This is close to its actual semantic class number 172(thing+stuff). Besides ,Cityscapes and PASCAL VOC The performance of has a continuous downward trend , And when K When large enough ,ADE20K The performance of is always good .

The above table shows the balance between semantic grouping loss and group level comparison loss , Where the two losses are treated equally , The best balance is achieved . It is worth noting that , When λg=1.0 when , Only apply semantic grouping loss , Significant performance degradation , It shows the importance of group level contrast loss in learning good representation .
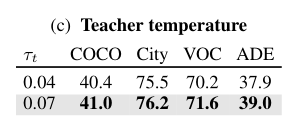
The above table lists the temperature parameters of the teacher model , Indicated soft Teacher distribution helps achieve better performance .

Last , The author analyzed in COCO val2017 split in , Whether the prototype learns semantics by visualizing its nearest neighbors . First, each image is semantically grouped , Divide them into non overlapping groups , Then merge each group into an eigenvector , And according to the cosine similarity index, the front 5 Nearest neighbor segments . As shown in the figure above , Prototypes are well bound to semantics , These semantics cover everything from animals 、 Food and sports to furniture 、 Architecture and other scenarios and semantic granularity , Regardless of object size and occlusion , Can locate them well ; It is worth noting that , No human comments .
05
summary
This work proposes a unified framework , It is used for joint semantic grouping and representation learning in unlabeled scene centric images . Semantic grouping is performed by assigning pixels to a set of learnable prototypes , These prototypes can be adapted to each sample by pooling attention on the feature map , And form new grooves . Slots based on the learned data , Use comparative goals to express learning , Enhance the distinguishability of features , And facilitate the grouping of semantically related pixels . By optimizing semantic grouping and contrastive learning at the same time , This method bypasses the disadvantage of manual prior , You can learn objects from scene centric images / Group level representation . Experiments show that , This method can effectively decompose complex scenes into semantic groups for feature learning , And significantly simplifies the follow-up tasks , Including target detection 、 Instance segmentation and semantic segmentation .
Reference material
[1]https://arxiv.org/abs/2205.15288

END
Welcome to join 「 Self supervision 」 Exchange group notes :SSL

边栏推荐
- Several forms of buffer in circuit
- 若依如何实现接口限流?
- Which position does Anxin securities rank? Is it safe to open an account?
- 108. 简易聊天室11:实现客户端群聊
- Learn about common functional interfaces
- 长安链交易防重之布谷鸟过滤器
- Net based on girdview control to delete and edit row data
- 【力扣刷题】二分查找:4. 寻找两个正序数组的中位数
- stm32h7b0替代h750程序导致单片机挂掉无法烧录程序问题
- day10每日3题(1):逐步求和得到正数的最小值
猜你喜欢

Supplement the short board - Open Source im project openim about initialization / login / friend interface document introduction

国内首款开源 MySQL HTAP 数据库即将发布,三大看点提前告知

TCP congestion control details | 1 summary

Make up the weakness - Open Source im project openim about initialization / login / friend interface document introduction
Scala Foundation (2): variables et types de données
![[Li Kou brush question] monotone stack: 84 The largest rectangle in the histogram](/img/75/440e515c82b5613b117728ba760786.png)
[Li Kou brush question] monotone stack: 84 The largest rectangle in the histogram

Learn about common functional interfaces

Qt 5.9.8 安装教程
Scala Basics (II): variables and data types

MS | Xie Liwei group found that mixed probiotics and their metabolites could alleviate colitis

随机推荐
Kept to implement redis autofailover (redisha)
Pybullet robot simulation environment construction 5 Robot pose visualization
板卡的分级调试经验
Exquisite makeup has become the "soft power" of camping, and the sales of vipshop outdoor beauty and skin care products have surged
电路中缓存的几种形式
牛客小白月赛50
基于Kubebuilder开发Operator(入门使用)
# 补齐短板-开源IM项目OpenIM关于初始化/登录/好友接口文档介绍
知道这几个命令让你掌握Shell自带工具
Solution for filtering by special string of microservice
1-12Vmware新增SSH功能
R language plot visualization: plot visualizes the normalized histogram, adds the density curve KDE to the histogram, and uses geom at the bottom edge of the histogram_ Adding edge whisker graph with
牛客编程题--必刷101之动态规划(一文彻底了解动态规划)
Redis Guide (8): principle and implementation of Qianfan Jingfa distributed lock
Ideal path problem
[force deduction question] two point search: 4 Find the median of two positive arrays
How can I get the stock account opening discount link? Is online account opening safe?
Supplement the short board - Open Source im project openim about initialization / login / friend interface document introduction
R language plotly visualization: Violin graph, multi category variable violin graph, grouped violin graph, split grouped violin graph, two groups of data in each violin graph, each group accounts for
Greenplum database fault analysis - semop (id=2000421076, num=11) failed: invalid argument