当前位置:网站首页>"Statistical learning methods (2nd Edition)" Li Hang Chapter 17 latent semantic analysis LSA LSI mind mapping notes and after-school exercise answers (detailed steps) Chapter 17
"Statistical learning methods (2nd Edition)" Li Hang Chapter 17 latent semantic analysis LSA LSI mind mapping notes and after-school exercise answers (detailed steps) Chapter 17
2022-07-24 05:50:00 【Ml -- xiaoxiaobai】
Mind mapping :
17.1
Trial plot 17.1 For latent semantic analysis , And observe the results .
import numpy as np
X = np.array([[2, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 1, 0],
[0, 0, 2, 3],
[0, 0, 0, 1],
[1, 2, 2, 1]])
U, Sigma, VT = np.linalg.svd(X)
print(f' word - The topic matrix is :\n{
U[:, :4]}')
print(f' topic of conversation - The text matrix is :\n{
Sigma * VT}')
word - The topic matrix is :
[[-7.84368672e-02 -2.84423033e-01 8.94427191e-01 -2.15138396e-01]
[-1.56873734e-01 -5.68846066e-01 -4.47213595e-01 -4.30276793e-01]
[-1.42622354e-01 1.37930417e-02 -1.25029761e-16 6.53519444e-01]
[-7.28804669e-01 5.53499910e-01 -2.24565656e-16 -1.56161345e-01]
[-1.47853320e-01 1.75304609e-01 8.49795536e-18 -4.87733411e-01]
[-6.29190197e-01 -5.08166890e-01 -1.60733896e-16 2.81459486e-01]]
topic of conversation - The text matrix is :
[[-7.86063931e-01 -9.66378217e-01 -1.27703091e+00 -7.78569971e-01]
[-1.75211118e+00 -2.15402591e+00 7.59159661e-02 5.67438984e-01]
[ 4.00432027e+00 -1.23071666e+00 -4.47996189e-16 6.41436023e-17]
[-5.66440763e-01 -6.96375947e-01 1.53734473e+00 -6.74757960e-01]]
about U matrix , Only the former 4 Column , Because in the end, only 4 Singular values ( topic of conversation ). in addition , Scientific counting is somewhat difficult to observe , We reserve the 2 Take a look at the decimal places U matrix :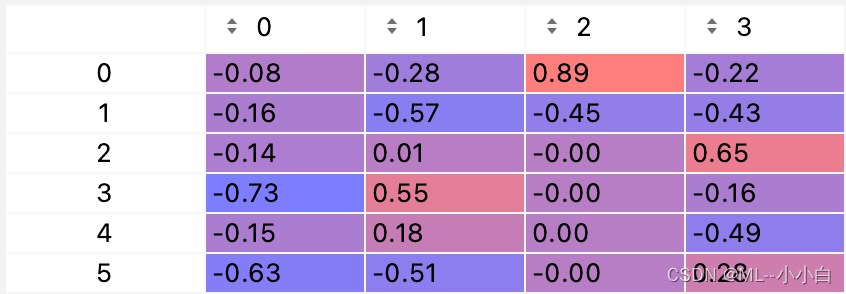
You can see , First column , The more important thing is 4 And the 6 Word , namely apple and produce, Guess this is about Apple or apple agricultural products ;
Second column , The more important thing is 2,4,6 Word , namely aircraft,apple,produce, This topic may have a certain probability problem , Whereas aircraft, It may be the topic of Apple product air transportation ;
The third column , The most important thing is the first word , The second is relatively important , namely airplane,airplane, Guess the topic is aviation related ;
The fourth column , Here's the important thing computer,fruit,aircraft, This is confusing , It may indicate that there is not enough data , The classification is still biased , Maybe this singular value or principal component is no longer important .
Then take a look at Sigma matrix :
You can find 4 There is no magnitude difference between the two topics , Then it may indeed be divided into these four topics rather than less .
Finally, take a look at VT matrix :
Analysis of each column shows , The probability of the first sample is 3 Topics , Corresponding to the aviation topic in the third column ;
The second sample probability is the second topic , It may involve the transportation of Apple products , But the actual situation may not be so ;
The third sample probability is the fourth topic , Combined with its large projection component in the first topic , Guess it's related to Apple products ;
The fourth sample probability is the first and fourth topic .
In short, it can be found that the analysis is not so accurate .
17.2
The nonnegative matrix decomposition is given when the loss function is divergence loss ( Latent semantic analysis ) The algorithm of .
Imitation of this topic book 335 page , Algorithm 17.1 It's a good way to do it , Just change the update rule from square loss to divergence loss .
Input : word - Text matrix X ≥ 0 X \ge 0 X≥0, Number of topics in the text set k k k, Maximum number of iterations t t t;
Output : word - Topic matrix W W W, topic of conversation - Text matrix H H H.
(1) initialization :
W ≥ 0 W \ge 0 W≥0, Also on W W W Each column of is normalized ;
H ≥ 0 H \ge 0 H≥0
(2) iteration :
The number of iterations is determined by 1 To t t t Follow these steps :
i. to update W W W The elements of ,
W i l * W i l ∑ j H l j X i j / ( W H ) i j ∑ j W l j W_{i l} \longleftarrow W_{i l} \frac{\sum_{j} H_{l j} X_{i j} /(W H)_{i j}}{\sum_{j} W_{l j}} Wil*Wil∑jWlj∑jHljXij/(WH)ij
among , i i i from 1 To m m m( Number of words ), l l l from 1 To k k k.
ii. to update H H H The elements of ,
H l j * H l j ∑ i W i l X i j / ( W H ) i j ∑ i W i l H_{l j} \longleftarrow H_{l j} \frac{\sum_{i} W_{i l} X_{i j} /(W H)_{i j}}{\sum_{i} W_{i l}} Hlj*Hlj∑iWil∑iWilXij/(WH)ij
among , j j j from 1 To n n n( Number of texts ), l l l from 1 To k k k.
17.3
The computational complexity of two algorithms for latent semantic analysis is given , Including singular value decomposition method and non negative matrix decomposition method .
First , General number of words m m m Greater than the number of texts n n n, For singular value decomposition algorithm , Its complexity is O ( m 3 ) O(m^{3}) O(m3), For nonnegative matrix, its complexity is O ( t m 2 ) O(tm^{2}) O(tm2)
17.4
List the similarities and differences between latent semantic analysis and principal component analysis .
identical :
For latent semantic analysis using singular value decomposition LSA, Its essence is exactly the same as principal component analysis ;
For using nonnegative matrix decomposition LSA, Its idea is the same as that of truncated singular value decomposition .
Different :
For using singular value decomposition LSA, The sample in this book is listed , features / Words are lines , And PCA The process of one is different PCA To normalize the data ( Put the origin at the position of data mean , Variance can be normalized, but not normalized ), in addition ,PCA Of SVD We should transpose the original matrix in this book , therefore PCA Of SVD The right singular matrix in the algorithm corresponds to LSA Left singular matrix of , Another less important point is PCA Of SVD Is the sample PCA For the whole PCA Estimation , It uses the unbiased estimation that the sample covariance is the total covariance , The sample covariance is different from that just mentioned LSA It's one transpose away , There will be more 1 n − 1 \frac{1}{n-1} n−11 The coefficient of ;
PCA The original matrix of is generally not a sparse matrix ,LSA The matrix of is generally sparse ;
Personally feel ,LSA Try something like PCA Do that to normalize the data , Because different words may be chosen to be the same scaling There will be different results , Maybe it will be closer to the real situation , But I haven't practiced , Please leave a message and let me know if someone has tested it , I'm curious ;
LSA Nonnegative matrix decomposition of NMF Obviously and SVD There are differences in Algorithm , The advantage of being positive is that it looks better to explain .
边栏推荐
- Points for attention in adding spp module to the network
- [vSphere high availability] virtual machine reset and restart
- Authorized access to MySQL database
- Logical structure of Oracle Database
- 第五章神经网络
- 国内外知名源码商城系统盘点
- The method of using bat command to quickly create system restore point
- 电商系统PC商城模块介绍
- 对ArrayList<ArrayList<Double>>排序
- ThreadLocal stores the current login user information
猜你喜欢

Zotero快速上手指南

《机器学习》(周志华)第2章 模型选择与评估 笔记 学习心得
Multi merchant mall system function disassembly lecture 09 - platform end commodity brands

Likeshop100%开源无加密-B2B2C多商户商城系统
多商户商城系统功能拆解13讲-平台端会员管理

plsql查询数据乱码
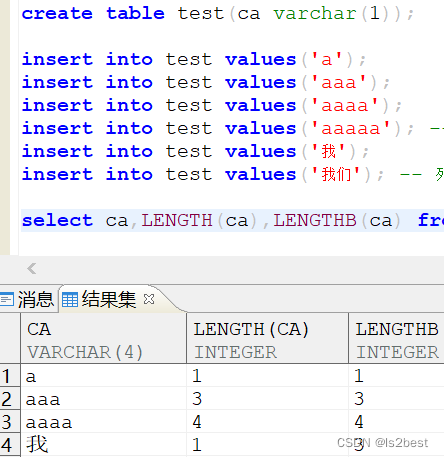
达梦数据库_LENGTH_IN_CHAR和CHARSET的影响情况
多商户商城系统功能拆解09讲-平台端商品品牌

Multi merchant mall system function disassembly lecture 07 - platform side commodity management

Delete the weight of the head part of the classification network pre training weight and modify the weight name
随机推荐
ERP+RPA 打通企业信息孤岛,企业效益加倍提升
Brief introduction of [data mining] cluster analysis
《机器学习》(周志华)第2章 模型选择与评估 笔记 学习心得
ThreadLocal stores the current login user information
OpenWRT快速配置Samba
删除分类网络预训练权重的的head部分的权重以及修改权重名称
Unknown collation: ‘utf8mb4_ 0900_ ai_ Solution of CI '
主成分分析计算步骤
jestson安装ibus输入法
‘Results do not correspond to current coco set‘
Target detection tagged data enhancement code
How to quickly connect CRM system and ERP system to realize the automatic flow of business processes
jupyter notebook一直自动重启(The kernel appears to have died. It will restart automatically.)
opencv读取avi视频报错:number < max_number in function ‘icvExtractPattern
Multi merchant mall system function disassembly Lecture 11 - platform side commodity column
Erp+rpa opens up the enterprise information island, and the enterprise benefits are doubled
Test whether the label and data set correspond after data enhancement
【mycat】mycat分库分表
第五章神经网络
多商户商城系统功能拆解13讲-平台端会员管理