当前位置:网站首页>[feature transformation] feature transformation is to ensure small information loss but high-quality prediction results.
[feature transformation] feature transformation is to ensure small information loss but high-quality prediction results.
2022-07-24 20:29:00 【Sunny qt01】
- Feature transformation *
We may have thousands of characteristics , If it's graphics 256*256 The graphic , There will be 196608 Features , If there is 256 Just a photo 256196608, There are so many different types of graphics
Can we collect enough features , Come on
We must reduce the number of features , Goal is to Poriginal Make a new conversion Pnew, Keep a characteristic number .Pnew Far less than Poriginal.
After feature transformation, there is only a small loss of information , But there are high-quality predictions .
shortcoming : The result of conversion may not be interpreted by us . It's hard to understand its meaning ( The mathematical formula )
If you need to understand the meaning of features , Then we need to select its features ( Statistical choice )
- Linear feature transformation
Transformation independent of the target field
PCA,SVD,TSVD, Matrix decomposition NMF
Transformations related to the target field
LDA
PCA: Use a linear relationship , Do the method of dimension elimination . Project the original observations into less principal component space , It can also retain a lot of differences ,(retain the most variance). Replace variables with fewer principal components
PCA It is an unsupervised calculation , Therefore, less variables are generally used for feature transformation .

You can find directions ,first Principal component The biggest variation is ( Most information ) The variable of ,second Principal component Is the second largest principal component of variation
There is no correlation between the principal components

PCA step :
Covariance matrix
Find the eigenvalues of the covariance matrix , Eigenvector
The first principal component is determined by ranking from large to small 、 Second principal component .( Eigenvalue is variance )

Solution eigenvalue a The problem is in the covariance matrix A Find satisfaction Ax=ax Of a as well as x,a It's characteristic value ,x It's the eigenvector ( The essence is to find the coordinates of each point in the coordinate main component )
Case study :

The above is a hypothesis , That is to use covariance to calculate the first principal component and the second principal component , Find the point value under the coordinate system of the first principal component and the second principal component .
Solve the eigenvalue problem of covariance matrix , And the problem of finding the principal component with the maximum variation , It is equivalent in Mathematics .
PCA How to find numbers , We need to see how much percentage of the original variable value we need . Per cent 80, Per cent 90 Fine

If the result is a blue line , Then it is not recommended to use PCA.
LSA: Latent semantic analysis (Latent Semantic Analysis,LSA) Application SVD(Singular Value Decomposition) Find out the potential semantic relevance of vocabulary from text data , Dimension reduction methods widely used in natural language data search .
The search method of traditional natural language search engine will require users to query the keywords , How to query the articles with keywords in the articles according to these keywords .
But if the meaning of the word is the same as that of the word , But the words are different , You can't successfully search these articles
A simple example : There is the word "car" in the article , The key word of query is car , So although the two are synonyms , Can't successfully search out .
LSA It's used to solve the problem , It can calculate the similarity between words , The similarity between words and articles has been , To solve this problem
LSA, It's using SVD Matrix decomposition technology of , Put the words - Matrix dimensionality reduction of documents , Transform into potential semantic space

Case study :
file 1: Drive a car to the company
file 2: Drive over
file 3: Eat hamburger steak in the restaurant
file 4: Eat spaghetti in the restaurant

SVD Matrix decomposition technique

Among them n It's the number of lines ,d It's the number of columns ,r Is the number of features you selected .
We take two characteristics

After feature transformation, our semantic space

The latter is our semantic space , We compare the values , Close , That means its semantics are similar .

If the words used before and after are similar ,SVD You will think the two are similar .
This is it. LSA How to do it .

The latter is the relevance between articles and words .
Comparing with the above figure, we can find the article 1, With cars , The company is highly connected .
Compare keywords to search , This method uses words around words to define words , Then his flexibility is higher .
shortcoming :
1.LSA It's using SVD After dimension reduction , The semantic dimension is orthogonal , The elements in the matrix may be negative , It may be difficult to interpret ,NMF perhaps LDA Can solve .
2.SVD It's very time consuming , Especially when the number of keywords is very large .
3. When new words are added , Matrix decomposition needs to be carried out again
4. Conduct SVD When , Truncation can be used SVD(Truncated SVD,TSVD)
The difference between them is TSVD It can generate a decomposition matrix with a specified dimension , Fast operation . amount to SVD Will be extracted after all calculations r results ,TSVD Just take it directly r Calculate the results . In fact, it's the same in essence .
Matrix decomposition NMF( Unsupervised calculation unsupervised technique)
The original space corresponds to the new space . and SVD equally , To be sure r value V~WH,V Namely d*n
W It was before d*r,H It was before r*n
characteristic :
1. It won't have a negative value , All elements in the original matrix are also non negative
2. After decomposition, they are all non negative numbers
3. But the potential semantic space dimension is not necessarily orthogonal

step :
take W,H initialization , Comes at a time
H As a constant , to update W
hold W As a constant , to update H
until W,H convergence , Stop calculating .


The white dot is the original coordinate , The green dot is NWH Result
LDA(linear Discriminant Analysis)
It is a kind of classification analysis classification algorithm
Variable reduction
PCA The pursuit is to maximize variance ( Unsupervised ),LDA I hope to divide the distance of multiple classes as far as possible ( Supervised )
LDA Steps for :
Calculate the average vector of each category
Within the calculation category Sw And categories Sb Scatter matrix of (Scatter Matrix)
Find out Sw-1Sb Eigenvalues and eigenvectors of
The eigenvalues are sorted from large to small , Leave the K eigenvectors
Used K Feature vectors project data into a new space



LDA The prediction result of is better , You can cut directly with horizontal lines , Suitable for algorithms such as decision trees ,PCA There is a slash , It's not reasonable to ,
This is because LDA There are reference target fields for coordinate construction .
- Nonlinear feature transformation
Transformation independent of the target field
Kernel PCA,t-SNE
Transformations related to the target field
neural network
Kernel PCA : utilize kernels Nonlinear transformation of coordinate space corresponds to coordinate space , It's going on PCA. If it is raw data, it is linear ,PCA Transformation is very practical , But if the native data is not linear ,PCA Not so usable
This is a Kernel PCA It's very important. ,rbf,poly( polynomial ),sigmoid()linear( standard pca)

Ordinary PCA Treating nonlinearity will make the two overlap , Two Kernal PCA You can distinguish .
Case study :

Dealing with nonlinear problems .
-t-SNE
The complex , High latitude data is reduced to two-dimensional or three-dimensional . For low dimensional space visualization .
step :
First, Gaussian distribution is used to calculate any two points in high latitude data XiXj The similarity H
In the low latitude space, the same number of data points are randomly generated in the high latitude space , utilize t Any two points in the low latitude data of distribution calculation yiyj The similarity L
T Distribution can make the results close to each other in high-dimensional space , Get closer in low dimensional space , Originally, the farther away in Gaowei , At low latitudes, it becomes farther . Expand differences
Update data point yi, To draw closer H And L Similarity distribution
Repeat the last step , until H And L The similarity distribution of tends to be the same .
That is to find the corresponding value in the low dimensional space . Projection of high latitude space .

Keep the similarity , stay
neural network :( Will refer to the target field )
Case study ,

On the left is the output field , In the middle is the hidden layer , The output field on the right . After training , Will get DrugY The value of is high .

We will find that Y~0.07*Na-1.02494*K Greater than 0 when ,drugY The probability of .
That is to say NA/K>14.642 when , use DRUGY The probability is high
Then we will specify the characteristic parameters
summary :

The value in the middle represents whether there is supervision , The value on the right represents whether it is linear .
AutoEncoder, Neural network will be more specific next time , How to generate new features , It's the point . Others have specific goals ( Suppose the variance is the largest and so on ) No assumptions , So it's more like feature learning .
The fifth part has practical operation , Specify , Can understand more specifically .
边栏推荐
- How to apply Po mode in selenium automated testing
- 1. Mx6u-alpha development board (buzzer experiment)
- YouTube "label products" pilot project launched
- Transport layer protocol parsing -- UDP and TCP
- Two methods of how to export asynchronous data
- Connect the smart WiFi remote control in the home assistant
- [training Day6] triangle [mathematics] [violence]
- C# 窗体应用TreeView控件使用
- Modulenotfounderror: no module named 'pysat.solvers' (resolved)
- Oracle creates table spaces and views table spaces and usage
猜你喜欢

Richview table table alignment

VLAN Technology
![[msp430g2553] graphical development notes (2) system clock and low power consumption mode](/img/4e/c08288c3804d3f1bcd5ff2826f7546.png)
[msp430g2553] graphical development notes (2) system clock and low power consumption mode

Substr and substring function usage in SQL
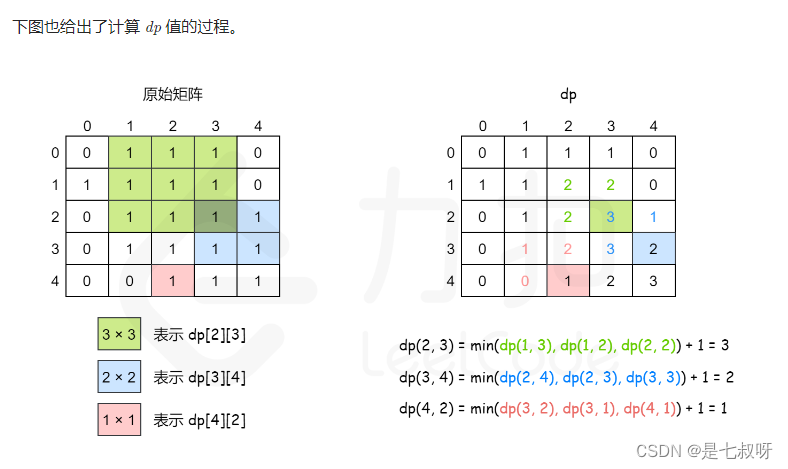
Leetcode 48 rotating image (horizontal + main diagonal), leetcode 221 maximum square (dynamic programming DP indicates the answer value with ij as the lower right corner), leetcode 240 searching two-d

Implementation of OA office system based on JSP
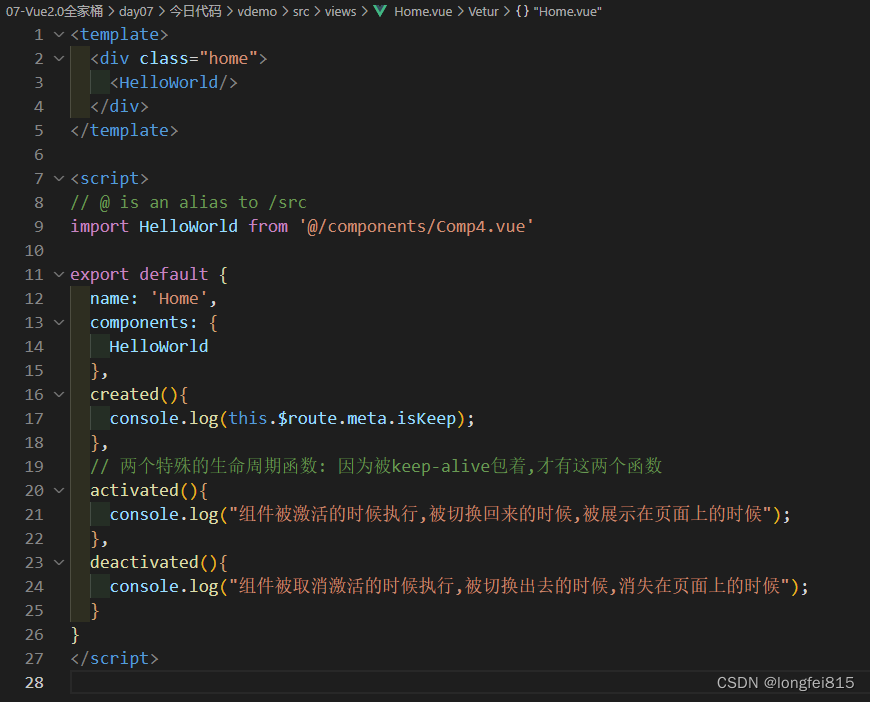
147-利用路由元信息设置是否缓存——include和exclude使用——activated和deactivated的使用

Native applets are introduced using vant webapp

Leetcode 206 reverse linked list, 3 longest substring without repeated characters, 912 sorted array (fast row), the kth largest element in 215 array, 53 largest subarray and 152 product largest subarr

How to test WebService interface
随机推荐
vlan技术
Write a batch and start redis
[training Day10] silly [simulation] [greed]
Leetcode 48 rotating image (horizontal + main diagonal), leetcode 221 maximum square (dynamic programming DP indicates the answer value with ij as the lower right corner), leetcode 240 searching two-d
What should Ali pay attention to during the interview? Personal account of Alibaba interns who passed five rounds of interviews
Functional test of redisgraph multi active design scheme
[training Day9] maze [line segment tree]
147 set whether to cache by using the routing meta information - use of include and exclude - use of activated and deactivated
The U.S. economy continues to be weak, and Microsoft has frozen recruitment: the cloud business and security software departments have become the hardest hit
Delete remote and local branches
[training Day8] tent [mathematics] [DP]
Install MySQL 5.7.37 on windows10
Connect the smart WiFi remote control in the home assistant
Leetcode 1911. maximum subsequence alternating sum
What does software testing need to learn?
Cloud native observability tracking technology in the eyes of Baidu engineers
Redisgraph graphic database multi activity design scheme
Unity's ugui text component hard row display (improved)
Unitywebgl project summary (unfinished)
"Hualiu is the top stream"? Share your idea of yyds