当前位置:网站首页>Stochastic Adaptive Dynamics of a Simple Market as a Non-Stationary Multi-Armed Bandit Problem
Stochastic Adaptive Dynamics of a Simple Market as a Non-Stationary Multi-Armed Bandit Problem
2022-06-22 20:36:00 【ZZZZZ Zhongjie】
Yann BRAOUEZEC
Abstract
We develop a dynamic monopoly pricing model as a nonstationary multi arm slot machine problem . Every time , A monopolist chooses a price in a finite set , Each customer randomly but independently decides whether to visit his store . Each customer has two parameters , Affordability and access probability . Our problem is nonstationary for monopolists , Because every customer will modify his probability according to experience . We define a prior optimal price for our problem , Then look at two different ways to learn the optimal price . In the first part , Suppose the monopolist knows everything except his ability to pay , We propose a simple counting rule based on buying behavior , It allows him to get enough information to calculate the optimal price . In the second part , Assume no specific knowledge , We consider the case where a monopolist uses an adaptive random algorithm .
When learning is easy ( difficult ) when , Our simulation shows that monopolists ( No ) Select the optimal price on each sample path .
The dobby problem , Adaptive learning , Random market dynamics , Explore - Use trade-offs , Nonstationarity
1 introduction
Economic theorists study market equilibrium as a mathematical problem : The existence of solutions 、 Uniqueness and stability . Stability produces what is called tatonnement Model , The adaptive dynamics of prices should reflect walrasian The learning process of auctioneers . just as Kirman And so on .
(2001), This learning process ( Unfortunately ) Does not always lead to equilibrium prices , But the main problem is that this auctioneer does not exist in most markets ! actually , Companies adjust their prices based on their knowledge and experience ( for example ,Lesourne,1992): therefore , The market should be modeled as a self-organizing process .
In recent years , Self organizing ( Learning and evolution ) Process has been widely studied in economic theory , But mainly in the framework of game theory ( for example ,Fudenberg-Levine,1998,Weibull,1996). contrary , In this paper , We regard the market model as a non strategic dynamic decision model embedded in the multi arm slot machine problem .
In the incomplete information economy model related to robber problem ( for example Aghion wait forsomeone . 1991, Arthur, 1993, Easley and Kieffer, 1988, McLennan, 1979, Rothschild, 1974, Schmalensee, 1975), Every decision ( Robbers ) It is related to the stationary probability distribution of income , But the parameters of this distribution are unknown Decision makers , For example, mean value and / Or variance . There have been two “ solve ” The main method of this multi decision problem .
1)“ Bayes optimal ” Learning methods .
2)“ The adaptive ” Learning methods .
In the first way , The decision maker forms a priori probability distribution on the unknown parameters , Use Bayesian rules to correct it , His goal is to maximize a given standard , It is usually the sum of the expected discounted profits . Because learning itself is not the goal of decision makers , Therefore, it may not be optimal for her to perfectly identify the true value of the unknown parameter . therefore , In the long run , She may choose a suboptimal decision , just as Rothschild (1974) As it turns out . From a behavioral point of view , This Bayesian optimal learning method requires decision makers to be highly rational , Because she not only has to use Bayesian rules to modify their beliefs , We also need to solve a very complex dynamic optimization problem ( See for example , EASTLEY and Kiefer ,1988).
In the second way , The rational requirements for decision makers are much lower , Because she just follows a simple “ Rule of thumb ”, That is, she applies an adaptive algorithm ( Random or non random ) To choose her decision . Interestingly , This kind of self-adaptive is in the fifties and sixties , Mathematician 、 Psychologists and economists have studied learning methods .
– from ( application ) Mathematician , As “ solve ” both arms ( Fix ) One way to solve the slot machine problem . The aim is to design an adaptive algorithm ( Have limited memory ), It may be deterministic , Such as Robbins (1952) and Robbins (1956), Or random , Such as Samuels (1968), It maximizes the probability of choice ( In the long run run ) The best robber ( See Cover and Hellman,1970 as well as Narendra and Thathachar,1989 The first 3 Chapter Overview ).
– By psychologists , As a way to model observed human behavior , for example “ Probability matching phenomenon ”. The experimental scheme is usually a simple two arm slot machine problem ( Even one armed slot machines ), The subjects were repeatedly placed in a position where one of the two possible responses must be given , And there are two results , for example ,“ success ” and “ Failure ”. Probability matching phenomenon is the fact that subjects match the potential probability , That is, if p It's a slot machine 1 Reward probability in , So after a while , The subjects chose the slot machine 1 The frequency of is close to the probability 2 p.
– Economists think , As simulation ( So-called ) A form of bounded rationality , That is, when the agent does not act in the way predicted by the utility theory ( see Simon, 1959, p. 260261).
These are about learning ( Optimal Bayes or adaptive ) The common ground of the various literatures is that decision makers have no impact on their environment , Because it is static . stay Rothshlid (1974) or Schmalensee (1975) In the market pricing theory considered , Monopolists learn over time , And suppose the customer's behavior is static . For all that , Suppose in a typical ( retail ) In the market , The seller ( Try ) Learn their demand function to maximize their profits , And the customer ( Try ) Learn from the cheapest sellers to minimize their expenses , It seems quite safe . result , The market develops in a non-stationary way . In this paper , We provide a non-stationary dobby slot machine theory with monopoly pricing , Both sides of the market ( Monopolists and customers ) As time goes on, I am learning , Therefore, the evolution of the market is a self-organizing process .
In our model , Every time a monopolist chooses a price from a finite set , Each customer randomly but independently decides whether to visit the monopolist's store . When a given customer visits the store at a certain time and the price is acceptable to her , She will buy a unit of goods . under these circumstances , We said she got “ Reward ”. When she goes to the store but the price is too high for her , She doesn't buy , So she “ No reward ”. Suppose it is well known ( psychology ) Law of effect , It asserts events “ Reward ” Increases the probability of recurrence of protected responses ( See, for example ,Staddon and Horner 1989), This means that when customers visit and buy , She will increase the possibility of visiting . contrary , When she visits but doesn't buy , She will reduce the possibility of visiting . Use the terms used in behavioral psychology ,“ Access and do not buy ” Events are negatively reinforced , and “ Access and purchase ” The event is being reinforced . Because the probability of each customer visiting the store is time-varying , The expected profits of monopolists are also time-varying ; therefore , He is faced with a nonstationary dobby slot machine problem .
There are important differences between static and non static environments . In a static environment , Decision makers can always separate the exploration phase from the development phase . result , Use simple stop rules ( Optimal or non optimal ), He can choose the best slot machine in the long run , The probability is arbitrarily close to 1. Unfortunately , As we will see , In a nonstationary environment , Not only is this separation impossible , And the concept of the best slot machine is not defined .
In the first part of this paper , We define a prior optimal decision for our nonstationary dobby slot machine problem , Learning in static and non-stationary environments is also discussed . In the second part , Suppose the monopolist knows everything except the ability to pay , We show a model based on buying behavior “ Counting learning rules ”, It allows him to get enough information to calculate the optimal price . In the third part , We relaxed the assumption that monopolists know everything except their ability to pay . therefore , We allocated to the monopolist Arthur (1993) On the dobby ( Fix ) Slot machine problem (Posch (1997) Also used ) Random reinforcement learning rules proposed in ,Hopkins and Posch (2005), Beggs (2005)) In the framework of game theory ), No specific knowledge other than environmental feedback is required . under these circumstances , Such as Kirman wait forsomeone . (2001) Among other things , The randomness of the market reflects the learning process of various agents . In limine , Decisions are made at random , But over time , Agents tend to choose a probability of 1 The decision . Our numerical simulation shows that , In the long run : – The probability of each customer visiting the store is zero or one .
– Monopolists may choose long-term suboptimal prices .
The market can indeed lock in the absorption state , This state is not only suboptimal from the perspective of the monopolist , The same is true from the customer's point of view . Last , Based on the numerical simulation results , We showed a “ Easy to learn ” Environment , In this environment , Monopolists always choose long-term monopoly prices .
2 Model
We model ( discrete time ) The dynamics are as follows . At every time t, The monopolist chooses the price in the following finite set P j > 0, Deduct production costs :
(1)
(2)
Every buyer i ∈ I ≡ {1, 2…N } Decide whether to come to the store independently . If time t The price of is lower than ( Or equal to ) Her willingness to pay , Then the buyer who decides to come will now buy a unit of goods , And in the opposite case will not buy . Make n t ≤ N For in time t The number of customers who buy a unit of goods . So the monopolist's profit is equal to :
(3)
Please note that , Since each price P j > 0 All are deducted from the production cost , So the profit is nonnegative .
In time t At the end , Each buyer adjusts her visit probability , To see if she bought the product .
2.1 Seller's decision rules
Every buyer i ∈ I Is characterized by the following two parameters : 1) Ability to pay v i ∈ R + .
2) Adaptive probability of access monopolist θ i,t ∈ [0, 1].
We assume that each buyer's willingness to pay is constant , This is equivalent to saying that buyers' preferences are stable over time . However , The probability of visiting a monopolist's store will change over time . In their early book on stochastic models of buying behavior ,Massy wait forsomeone . (1970) It is suggested that the factors affecting the purchase probability are : - Experience , Feedback from past purchases .
– The impact of exogenous market forces .
– Population heterogeneity .
In the following content , We assume that a given customer tends to visit the store more frequently when purchasing an item , And even less when she doesn't buy . The purchase probability is only modified based on personal experience , And there is no interactive effect ( There is no strategic behavior , No imitation ) and / Or there is no possibility of collective learning 3 .
Make P t ∈ P It is the monopolist in time t Selected price , And let z i,t = 1 (z i,t = 0) customer i In time t visit ( Do not visit ) The situation of the store .
Formally , We assume that every customer i Use the following random reinforcement algorithm to modify her access θ i,t Probability :
(4)
among β i ∈]0, 1] It's a parameter . This reinforcement algorithm is called linear reward penalty in the literature of learning automata ( See, for example Narendra and Thathachar,1989 year ) And very natural : When the customer is in time t When buying a unit of goods , She will increase the probability of access and reduce the probability of access When she doesn't buy . Given learning rules [4], In the long run , There may be such a situation , A customer may go to a store , And the other person will eventually stop to visit him , Because he has experienced too many high prices . It is important to : - {0} Is the absorption state of a random process , But it's not {1}.
– The size of the increment is β i The decreasing function of . Given the relationship [4], Increment of random process {θ i,t } by :
(5)
therefore , We can β i Interpreted as “ Reactivity parameters ”. β i The higher the , The greater the customer's response , Because the magnitude of the increment is β i Incremental function of .
2.2 Monopoly price in pure strategy : Complete information case
Like most of the literature on adaptive learning , We will assume in this article that monopolists will not underestimate the future . As we'll see later , It means “ Exploration costs ” zero . In order to get the optimal price in our dynamic market model ( Monopoly price ), We assume that the information is complete ; The monopolist knows the customer set 、 Ability to pay v i 、 Reinforcement learning rules [4]、 Learning parameters β i and ( If necessary, ) Every i The initial conditions of the system θ i,0. Since, as we have already said , Every customer i The probability of visiting the store is not constant , Monopolists face a nonstationary multi arm slot machine problem , This complicates the specification analysis , Because there is no transcendental natural way to define The best price . Here we will focus on the optimal price in pure strategy . In game theory , We call pure strategy the monopolist in every t ∈ N Time based probability 1 The decision of choice ( That's the price P j ∈ P). Give Way
(6)
It is a group of customers who make their ability to pay above this price P j And let
(7)
Be its complement . Last , Give Way Card I j Become I j Base number of . No loss of generality , Let's assume that the card I j 6 = ∅ For all j = 1, 2…J.
proposition 1 Assume all i Of θ i,0 > 0. If P j CardI j 6 = P k CardI k for j 6 = k, Then there is a unique ( In advance ) The best price .
prove : Consider the monopolist's choice of price in pure strategy P j The situation of . Given reinforcement learning rules [4] And assume that all i ∈ I θ i,0 > 0, Belong to I j Of customers will be in probability 1 Long term visit to the store , It doesn't belong to I Customers In the long run ,j Not with probability 1 Visit him . It means :
(8)
therefore , The long-term expected profit is :
(9)
(10)
If all Π ∞ (P j ) Different , There is a price P m ∈ P, Monopoly price , bring Π ∞ (P m ) > Π ∞ (P j ) For all j 6 = m In In the case of complete information , The monopolist can calculate with each price P j Associated long-term ( deterministic ) profits Π ∞ (P j ) = P j Card I j , Because he knows Card I j . therefore , He will at every time t ∈ N Charge this price P m. It is important to , find ( Unified ) What monopoly prices really need is not v i Knowledge , But only all j Of Card I j Knowledge , in other words , If they are all visiting the store , How many customers at the price P j Buy . Of course , If monopolists are allowed to discriminate on price , That is to charge different prices to different customers , that , Perfect discrimination will require discrimination against vi A complete understanding of .
We can now calculate the long-term ( Usual ) Marshall total surplus W ∞ (p m ), The definition is as follows :
(11)
Definition W ∞ (P m ) Very important , Because it defines the normative benchmark of market welfare .
2.3 Learning in fixed and non fixed environments : Explore - Use trade-offs
We now assume that the monopolist does not have complete information about his environment , especially vi It is unknown. , But the number of customers and their reinforcement learning rules [4] It could also be unknown . When θ i,t For each i Constant over time , The monopolist's environment is stable , And when θ i,t Over time , The environment is non-stationary .
2.3.1 Study in a fixed environment
Consider a smooth situation , For example, in Schmalensee (1975) or Arthur (1993) in . If the monopolist knows that for every i θ i It is constant in time , Because there is no discount in the future , His problem is not difficult , Because he can use the following stop rules to separate the exploration phase from the development phase .
1) Explore . choice ( continuity )n ∈ N Time (n Co., LTD. ) Price P j, And then through its empirical average Π j,n It is estimated that ( Unknown ) Expected profit . repeat j = 1, 2…J.
2) Development . about t ≥ nJ, With probability 1 Select the price related to the highest empirical mean .
According to the law of large numbers , He knows if n High enough , He will approach at will 1 The probability of finding a monopoly price . therefore , In a static environment , Monopolists can behave like classical ( Even Bayes ) Statistician .
especially , There is no need to use some random adaptive algorithm . It's important to realize that n It can be any size , Because the exploration cost is zero , Because the future will not be discounted by assumptions . When the future is discounted , Given an optimization criterion , choice n“ high ” It may not be optimal . Rothschild (1974) The discount in the fixed two arm slot machine problem is explicitly considered from the perspective of Bayesian learning , The goal of the decision-maker is to maximize the sum of the expected discounted profits . He showed that , There is an optimal stopping rule , Can best solve the problem of exploration - Development conflicts , And this optimal stop rule may cause decision makers to choose suboptimal prices indefinitely . In the long run , This result 4 It is called incomplete learning in the economic literature .
In a stable environment , When there is no discount in the future , Just try all the prices , The decision maker is based on price P 1 still P J It doesn't matter at the beginning of exploration . When this is done , At any close 1 Under the probability of , The monopolist will be after the exploration phase ( forever ) Choose a monopoly price .
Schmalensee (1975) And recent Arthur (1993) A fixed dobby slot machine problem is considered , The monopolist uses some random reinforcement algorithms . They show that , Generally speaking , Monopolists will not find long-term monopoly prices : Under positive probability , He will end up choosing suboptimal prices indefinitely 5 . In a smooth frame , This random reinforcement algorithm is not very convincing , Because we can easily find the optimal price by using the above simple statistical decision rules . As we will see now , When the environment is non-stationary , Such a stop rule cannot be implemented , This means that stochastic reinforcement learning may find its roots in non-stationary environments .
2.3.2 Nonstationarity :“ Exogenous ” And “ Endogenetic ”
If the stable environment is clear , Nonstationary environment is not . As we will see , A non - stationary environment may indeed be stationary at times ! In the multi arm slot machine problem , If the probability distribution of a given slot machine is time independent , Then the environment is static for the decision-maker . In a simple two arm slot machine problem , Every slot machine i Is the parameter θi Bernoulli distribution of ,i = 1, 2( namely “ success ” Probability ), Smoothness means θi It has nothing to do with time . contrary , If θ i It's time related , That is, if θ i May change over time , Then the environment is non-stationary . however θ i May change over time in many different ways .
Nonstationary “ Exogenous ” The form is the parameter according to “ Exogenous specific rules ” From time t Evolution to time t + 1 The situation of .
In their talk about “ Learning automata ” In the book ,Narendra and Thathachar 6 (1989) Distinguish between two forms of ( Exogenous ) Nonstationary environment :
1) Markov switching environment .
2) State dependent nonstationary environment .
Markov switching environment may be θ i,t Environments that follow simple Markov chains , for example ,θ i,t ∈ {0.2, 0.6} and P(θ i,t+1 = 0.2|θ i,t = 0.2 ) = p i and P(θ i,t+1 = 0.6|θ i,t = 0.6) = q i . A state dependent nonstationary environment may be θ i,t An evolving environment , It can be said to be a deterministic function of time . for example , For a ( Fix ) function f,θ i,t+1 = f (θ i,t ) bring f (θ i,t ) ∈]0, 1[ For all t.
In these two forms of environment , Nonstationarity is exogenous , Because decision makers have no impact on their environment . actually , The environment is marked as non-stationary because of the parameter θ i,t Over time , But the evolution law of parameters is stable , That is, the transfer matrix and function of Markov chain f It has nothing to do with time , also It's really exogenous . One can even think of transfer matrices and functions f It's time related , As long as their laws of evolution are stable .
Nonstationary “ Endogenetic ” Form is much more difficult , It involves “ System ”( That's the game 、 market 、 Social networks ……) The evolution of , This is the result of many interdependent decision-making processes . Let's take two well-known examples .
– El-Farol Bar problems 7, Suppose there are... Every Sunday N( for example ,N = 100) People go to bars (El-Farol). Everyone independently decides whether to visit the bar . The problem is that the bar is very small , Everyone doesn't like to stay there when it's crowded . If more than 70% People go to bars , It's very crowded , Everyone is worse than staying at home . contrary , If less than 70% People go to bars , Everyone likes to be there , in other words , Come without regret . Given a learning rule , Let everyone according to n The weekly number of people who go to bars is known 8 Frequency to determine whether it is in the n + 1 Zhou Lai , The evolution of this system is ( Endogenous ) Nonstationary , because Everyone's decision-making process depends on the percentage of people in the bar , This in itself depends on everyone's decision-making process .
– Repetitive “ Average game 9”, among N One must choose every time 0 To 100 A number between , The winner is to choose the nearest average of all the selected numbers multiplied by the parameter p People with lower numbers ( Or equal to ) To a 10 . At the end of each game , The winner's number will be announced . Given a learning rule, let each player according to the game n The result is the game n + 1 Select some numbers , The evolution of this system is ( Endogenous ) Nonstationary , Because everyone's decision-making process depends on the number of winners , The number of winners itself Depends on everyone's decision-making process .
Suppose each agent has a fixed ( The adaptive ) The learning process , Modeler ( May know various learning processes ) We still don't know the laws governing the evolution of the system . This is why we talk about endogenous nonstationarity .
Generally speaking , For such a system , Evolution ( strong ) Path dependent , And there are many ( Acceptable )“ Stationary state ”. Such systems are often referred to as self-organizing processes .
2.3.3 Study in a non fixed environment
Now consider {θ i,t } Over time , Like the equation (4) Described , And assume that the monopolist passes ( continuity ) collect n Second highest price P J To begin the exploration phase . If n High enough , Before the end of the exploration phase , Do not belong to I J 's customers will no longer visit the store . because {0} It's a random process {θ i,t } Absorption state of , Therefore, it belongs to I J Our customers will be the only remaining customers after the exploration phase . under these circumstances ,P J Become “ After the event ” The best price , But usually it is not equal to the best price in advance . A better idea might be to offer the lowest price P 1 Start the exploration phase , And then there was P 2 wait , But if you try all the prices , This will obviously lead him to the same problem .
therefore , There is a fundamental difference between static and non static environments , That is, there is an irreversible effect in the non static environment 11 ( Or locking effect ). This irreversible effect means that it is impossible to separate the exploration phase from the utilization phase , Because the process of collecting information will affect the learning objects , Or to put it another way , Learning will affect what you want to learn . This problem is well known in game theory ( See, for example Fudenberg-Levine (1998)), But as far as we know , In the case of multi arm slot machines, it is not ( See Banks wait forsomeone ,1997). Interestingly , We found out recently , Many psychologists 、 Neuroscientists and biologists are studying exploration in static and non - static environments - Explore trade-offs .
stay Daw wait forsomeone . (2006 year )( See also Cohen wait forsomeone ,2007 or Groß wait forsomeone ,2008), They consider a nonstationary dobby slot machine problem , The average return changes randomly and independently in each trial . They consider the following three learning processes .
– - The rules of greed , Among them, the decision-maker takes the probability (1− ) Choose robbers ( It is believed that ) It's the best , And with probability Choose another robber .
– soft-max The rules , Randomly select a slot machine according to its relative performance or estimated expected value .
– One “ Revised ”soft-max The rules , Slot machines that are not selected will get “ Bonus ”, So as to increase the probability of being selected .
Daw et al., (2006) Found experience ( strong ) The evidence shows that the subjects ( In their experiment ) Used soft-max The rules .
3 Learn by counting : Only the customer's ability to pay is unknown
We will assume in this section that only payment vi The ability of is unknown . especially , equation [4] The reinforcement algorithm is given together with the parameters β i 、 all i The initial conditions of the system θ i,0 And the number of customers are assumed to be known to the monopolist . Under this incomplete information setting , Given a set of prices P, If only vi Unknown , How decision makers find monopoly prices P m?
A natural way to find monopoly prices is to infer from customers' buying behavior ( Learning ) card I j. Please note that , This is in a sense equivalent to ( old ) Show preference questions , Among them, people try to infer from purchasing behavior ( Unobservable ) Preference . for example , If a given customer i At a given price P j c Buy , But not with P j+1 For the price of , The monopolist can infer i ∈ I j ∩ I j+1 . Given price set P, know i ∈ I j ∩ I j+1 Equivalent to knowing v i . As we said before , What is really needed here is not right vi Perfect knowledge of , But only Card I j .
Suppose the monopolist charges a given price P j . If all the customers come to the store , He only needs to count the number of customers who buy at this price to get Card I j . If he could be all j = 1, 2…J Do this , He will be able to calculate each j Relevant profits P j Card I j. However, the problem is not so simple , Because monopolists face a non-stationary problem : If he charges a given price several times in a row P j , Belong to I j c Our customers may be 1 The probability of vanishing . We will now propose a “ Counting rules ”, When learning parameters β i For all i Enough hours , It allows the monopolist for all j infer Card I j.
I .
Counting rules
**1) Loyalty promotion process :** continuity n Time (n Co., LTD. ) Charge the lowest price P 1 .
**2) Statistical process :** In time n+j,j=1,2…J-1, Charge a price Pj+1, Count the number of customers who buy at this price .
When n When high enough , At the end of the process of increasing loyalty , Belong to I 1 The probability of all customers visiting the store is arbitrarily close 1. Now? , During the inventory process ,( At least )I 1 ∩ I 2 c All of our customers didn't buy the product when they came to the store . therefore , From time t = n + 1 To time T = n + J - 1, For all i ∈ I 1 ∩ I 2 c ,θ i,t yes t The minus function of . However , stay β i Small enough for a particular case , Belong to I 1 ∩ I 2 c Our customers are in time T = n + J - 1 Will still approach at will 1 The probability of visiting the store . This is a proposition 2 The basic idea of .
proposition 2 Suppose the monopolist uses the above counting rule . For the sake of simplicity , We assume that θ i,0 = θ 0 and β i = β For all i ∈ I. Given a set of prices P, 1 i J−1 h ) ln( 2(1−θ 0 ) 1− and n ≥ , In time ∀ > 0 (with < 2(1 − θ 0 )), If β ≤ 1 − 2 2− ln(1 − β) T = n + J − 1, that θ i,t ≥ 1 − , ∀i ∈ I 1 , ∀t ∈ {n + 1, …n + J − 1}; The counting process can be approached in any way 1 The probability of accurate completion .
prove See appendix .
Another way to get the same result is to consider the parameters β i,t It's all i Time for t The case of the decreasing function of . If we look like LambertonPagès-Tarrès (2004) Assume that :
()
We can also prove the existence of a finite n, So that the counting process can be arbitrarily close to 1 The probability of accurate completion .
We have seen before , The increment of random process (θ i,t ) t∈N( See equation [5]) yes β i The increasing function of . hypothesis β i A very small , It is equivalent to saying that the learning process is very slow . When the process of increasing loyalty is completed , The probability of all visits to the store is arbitrarily close to one . Because of all β i They are very small , The monopolist can try all the prices , It's like the probability of access is constant , This is what a monopolist can infer from buying behavior Card I j Why .
When all kinds of β i ∈]0, 1[, That is not necessarily very small , Assume all i Of θ i,0 > 0, He can still use the following counting rules . Let any small > 0.
- Continuously charge the lowest price P 1 Of n times , bring θ i,n > 1 - For all i ( Please note that , For all i and ,n yes θ i,0 and β i Function of )
- In time n + 1, Charge a price P J And count the number of customers who buy at this price , That is, get the card I J
- Now continuous collection n J ≥ 1 Times the lowest price P 1 Make probability θ i,n+n J +1 > 1 - For all i
- In time n + n J + 2, Charge a price P J-1 And calculate the number of customers who buy at this price , That is, get the card I J-1
- Now charge n J−1 ≥ 1 Times the lowest price P 1 Make probability θ i,n+n J +2+n J−1 > 1 − For all i
- Repeat until the card I j For all j.
Of course , Learn from buying behavior Card I j The possibility depends critically on the ability to pay vi Perfect knowledge and customer learning rules . In practice , It is not clear why we should know the ability to pay . When the monopolist knows nothing about the characteristics of the customer , Because he observed a profit related to the price he charged , He can still use a version of the soft Max rule to ( Try ) Learn to monopolize prices . This is what we are going to study now .
4 Reinforcement learning : A monopolist may “ Complete ignorance ”
4.1 Reinforcement learning rules
In a static dobby slot machine problem , We see that the decision-maker can first estimate the unknown parameters ( It's usually the mean ), Then select the price with the highest estimated mean . Using this stop rule will allow him to approach at will 1 The probability of finding the optimal price . However , In the case of nonstationary , As we've seen before , Such a stop rule does not work , Because decision makers cannot separate the exploration phase from the development phase . In such an environment ,“ solve ” One way to solve the problem is to use soft-max Rules to achieve , Random decision rules . Although there are many candidates , We still chose Arthur (1993) The proposed random adaptive algorithm .
Make S j,t-1 It's in time t-1 Assigned to price P j The intensity of , And suppose P j Is time t The choice price , also n t Customers in time t Bought a unit of goods .
Make Π j,t = P j .n t For monopolists in time t The profits of the . ( Simple ) The adaptive rules are as follows :
(12)
(13)
The strength of each price reflects its past performance , That is, its accumulated profits .
Because our monopolists cannot separate the exploration phase from the development phase , So it's natural to assume that he uses an adaptive random rule , The rule allows him to “ Exploration and utilization ”. Make η j,t For every time t Normalized intensity of :
(14)
because η j,t Is the standardized weight , Let us now assume that the monopolist is in time t Equal to η j,t The probability of random selection of a given price P j. because η j,t According to the price P j Performance over time , This random reinforcement algorithm may be a kind of “ solve ” Development - Explore trade-offs .
In our model ,Π j,t ≥ 0 signify η j,t ≥ 0. If Π j,t May be a negative ,η j,t It can also be negative , Our reinforcement algorithm will not work . However , When Π j,t Can be negative , We can still use the following of our random reinforcement rules “logit” edition , Such as Kirman wait forsomeone (2001) etc. :
(15)
among λ It's a parameter . Of course , This enhancement algorithm depends on the parameters λ, The algorithm we use is parameterless .
remarks 12. Customer reinforcement learning rules ( By the equation [4] give ) And the reinforcement learning rules of monopolists ( By the equation [12] To [14] give ) Is different . Monopolist's learning rules and decision-making performance ( That is, profit ) In direct proportion to , The customer's learning rules and the performance of access decision ( Surplus ) Not in direct proportion . Make S i,1,t For customers i Of “ visit ” The strength of the decision (
(16)
(17)
among P t ∈ P And let
(18)
It's the customer i In time t Probability of visiting the store , among β i It's a parameter .
When (v i - P t ) > 0 when , That is, when the customer i When visiting and buying , Her probability of visiting increases , And when (v i -P t ) < 0 when , The probability of visiting is reduced . In such a model , The decision-making rules of both customers and monopolists are related to “ The performance of ” In direct proportion to .
4.2 Related literature
I . They use the mean field approximation to study the asymptotic behavior of stochastic processes . Although this is not strictly a proof of probability , But this provides an interesting and simple computational method to study the long-term behavior of stochastic processes . Related to slot machine problems ,Lamberton wait forsomeone (2004) When the decision-maker uses linear reward, not as a random algorithm, but in a static environment 2 A strict probability proof of the asymptotic behavior of the arm slot machine problem . Arthur (1993) Use linear rewards not as an algorithm (14) The problem of a static dobby slot machine is studied , Where a renormalization sequence is used C t = C t v The strength is renormalized ( See also Laslier-Topol-Walliser 2001). Arthur (1993) indicate , When 0 < v < 1 when , The stochastic process converges to the non optimal vertex of the simplex with positive probability , And when v = 1 when , It's based on probability 1 Converge to the optimal vertex . In proof ,Arthur (1993) Depend on Pemantle (1990) A very general theorem of . Hopkins and Posch (2005) In the framework of game theory Arthur (1993) The algorithm used , And discussed Pemantle (1990) Applicability of theorem ( See also Beggs (2005) and Pementle (2007)). They think that Arthur (1993) The theorem may be correct , Although it proved incorrect , Because he depends on Pemantle (1990) Theorem but the condition is not satisfied . We will not discuss these technical details further , Because we only provide numerical results in this section .
4.3 Numerical results
4.3.1 summary
We will study market behavior from the perspective of numerical simulation .
Make η t = (η 1,t , …η J,t ) ∈ Δ(R J ), among Δ(R J ) yes R J Unit simplex of , θ t = (θ 1,t , …θ N,t ) ∈ [0, 1] N . Give Way
(19)
among (η t , θ t ) Is the state vector of our random process ,Δ(R J ) × [0, 1] N It's state space . On each sample path , Our numerical simulation shows that the long-term behavior of stochastic processes has the following two properties : – The probability of all customers is zero or one ; – The probability of monopolist selection is 1 The price of .
This means that in the long run , The evolution of the market is deterministic : The probability of monopolist selection is 1 The price of , The probability of all customers is 1 or 0. To understand the intuition behind this numerical observation , Note the size of the increment .
– Δθ i,t It's static .
Adaptive rules (12), because X – Δη t Not static . The reason is simple : hypothesis X S j,t Is time t The increasing function of , For a given profit Π j ,S j,t The higher the ,j j The incremental Δη t The lower the . therefore , The process η t The increment of is time t The decreasing function of .
From a behavioral point of view , This means that the customer's “ Reactivity ” It is constant over time , And the monopolist's “ Reactivity ” Is time t The minus function of . Although the monopolist still chooses each price with a positive probability in the intermediate operation , But customers tend to be divided into two groups : – With probability 1 People who visit stores and buy goods 13; —— Disappeared person .
To recall {0} It's a random process (θ i,t ) t∈N instead of {1} Absorption state of , As we said , This may be the case , That is, the customer comes with equal probability ( And buy ) In the middle run time, it becomes a , But it will eventually disappear in the long run . This feature comes from the path dependence of the market .
We have carried out numerical simulation considering the following ideas . When the profit related to monopoly price is not enough to be higher than all other prices , It may be difficult for decision makers to find long-term prices on each sample path P m. therefore , We studied two cases , One is learning “ difficult ”, One is learning “ Easy to ”. We have selected the following parameters in both cases :
– J = N =5
– P i = v i , among v i ∈ R + But for all i It's all limited
– β i = 0.2
– θ i,0 = 0.5 For all i
– S j,0 = 1 ⇐⇒ η j, For all j,0 = 0.2.
4.3.2 Study “ difficult ” The case of
As we said before , When the profits associated with each price are very close to each other , Learning is “ difficult ”. The natural candidates for difficult learning are the various prices at 0 and 1 The situation between , namely :
(20)
Consider the following set of prices .
(21)
Therefore, it is easy to test whether the monopoly price is
(22)
According to history , We observe that monopolists choose... In the long run P The price of , except P 1 = 0.12. For the non negligible sample path part , The monopolist chooses the price in the long run P 5, therefore , Customer 5 Is the only remaining customer . The reason lies in the self reinforcing nature of market dynamics : Price P 5 The higher the probability of choice , Under other conditions , Customer 1 To 4 The lower the probability of access . But the lower the probability of access . Customer 1 To 4 The interview of , Price P 5 The higher the probability of choice , because P 5 Become the best price . Please note that , When the monopolist chooses this price for a long time P 5 when , From the customer's point of view , This static state is highly suboptimal , The same is true from the monopolist's point of view . The total Marshall surplus related to monopoly price is W (P m ) = 0.75 + 1.4 = 2.15, In the static state, it is W (P 5 ) = 0.85. The welfare loss is so great !
The negative result is that learning is “ difficult ”, Because the profits associated with each price are very close to each other . therefore , The adaptive algorithm used by monopolists cannot distinguish the optimal price from other 14. If the profit related to monopoly price is much higher than other prices , Then the adaptive algorithm ( Maybe ) It will be found in the long run . Now let's consider this situation .
4.3.3 Study “ Easy to ” The case of
Consider the following set of prices .
(23)
It's easy to check P 5 It is a monopoly price . under these circumstances , Once you choose P 5, Dynamics will strengthen itself , The monopolist will soon approach 1 The probability of choice P 5. To see this more clearly , Suppose on the date t = 0 I chose P 5 And customers 5 At this time 15 To visit the store .
Because only customers 5 Purchase goods , The monopolist's profit is equal to P 5 = 10. Use adaptive rules (12) And give the initial conditions S j,0 = 1 For all j, The monopolist will choose the price P 5 In time t = 1 when , The probability is equal to (11/15) ≈ 0.73: Then dynamically become self reinforcing . therefore , On each sample path , We observe that monopolists choose... In the long run ( The optimal ) Price P 5 = 10. Of course , This is a simple case , Because the profit realized at this price is much higher than all other prices .
Now consider a set of prices P’, But the P 5 ∈]0.53; 10[. obviously , When P 5 from 10 Down to 0.53 when , Learning becomes more and more difficult , Because when other conditions remain the same , With the highest price P 5 The associated profits have become lower . As we've seen before , When P 5 = 0.75 when , A monopolist is not always able to P 5 = 0.75 The optimal price of the is distinguished from other prices . contrary , When P 5 = 10 when , Monopolists are always able to distinguish between the best prices . So it's natural to ask whether there is “ critical ” Price P * bring : – If P 5 ≥ P * , Always choose the long-term monopoly price .
– If P 5 < P ∗ , Monopoly prices are not always chosen in the long run .
We have conducted numerical tests on many prices , We find that the critical price is ( about )P * = 1.9, This means that when we consider price sets P 0 = {P 1 = 0.12; P 2 = 0.35; P 3 = 0.42; P 4 = 0.53; P 5 }, as long as P 5 > 1.9, Monopolists always find long-term monopoly prices .
Now it is natural to ask this critical price P * = 1.9 Whether it is robust to environmental disturbance . So , Many disturbances can be made . for example ,on You can change the price P 4 Or customer quantity or price quantity , For example, by adding another price P 0 . As we will see , This critical price is usually not robust to such disturbances . Please note that , In all of the following cases ,P 5 Are the best prices .
- Now consider a set of prices
(24)
among , except P 4 Outside , Only one customer is satisfied v i = P i . For the price P 4 , Now there is 3 A customer , Their ability to pay is 0.53. Numerical simulation shows that , Monopolists cannot find long-term monopoly prices : Long term possible choice P 4 or P 5. therefore ,1.9 No longer a key price . - Make P i = v i for i = 1…5 As in the previous case . however , We now have the following set of prices
.(25)
In this example , When the customer 5 When visiting the store , Price P 0 and P 5 Offer... Compared to other prices ( high ) profits . Numerical simulation shows that , In the long run , The monopolist may choose P 0 = 1.8 and P 5 = 2. therefore ,1.9 No longer a key price . - Consider the following set of prices , All that is i Of P i = v i.
(26)
When P 4 = 0.53 when , Let's go back to our previous environment , We know that the monopolist will find the best price . However , When P 4 = 0.9 when , Numerical simulation shows that , Monopolists may eventually choose long-term prices P 4 = 0.9. therefore ,1.9 No longer a key price .
Basically , This exercise of robustness shows that , The stochastic algorithm used by monopolists is only relevant to the optimal price “ performance ” Much higher than all other algorithms . If this is not the case , In the long run , May choose a sub optimal price . In fixed settings , A method to obtain optimal price convergence , Such as Arthur (1993) Described , It is possible to reduce the speed of the learning process through the renormalization sequence . Unfortunately , In a non fixed environment , It doesn't work , Because the learning process affects the content to be learned in a path dependent way . just as Cohen wait forsomeone (2007) In their paper :“ so far , It has not been described how to make a trade-off between exploration and utilization in a non-stationary environment , And it is not clear whether this is feasible .” Cohen wait forsomeone ,(2007) The first 935 page .
We have simulated this market model many times with different prices , In our market “ qualitative ” Behavior remains the same : In the long run , The probability per customer is 0 or 1, The price chosen by the monopolist is Probability one .
5 Conclusion
We believe in our “ Simple ” The framework is interesting , Because it emphasizes the use of adaptive random algorithm in non-stationary environment , It is impossible to separate the development phase from the exploration phase . When the monopolist knows everything except the ability to pay , We have proved that the monopolist can infer all the information necessary to infer the optimal price from the purchase behavior by using the counting rule . When he is on the customer's characteristics “ Complete ignorance ” when , A natural way to learn the optimal price can be obtained by using an adaptive stochastic algorithm , The probability of choosing a given price is related to ( In the past ) In direct proportion to performance . When the performance of different prices is enough “ near ” when , Monopolists may eventually choose suboptimal prices in the long run , Because the algorithm cannot distinguish the optimal price from other prices . The performance of the optimal price is much higher than that of all other specific cases , The monopolist will choose this price in the long run .
Our results are indeed numerical , Not analytical . therefore , We still need to prove that our market stochastic process “ The convergence ”, We also need to design an adaptive random algorithm , So that the monopolist can choose the long-term optimal price with probability . As far as we know , We don't know of any market model that can be used to prove us “ convergence ” General theorem of , Because models involving adaptive stochastic algorithms are mathematically difficult ( for example , See Pemantle,2007) And heavily dependent on Consider the random algorithm ( See, for example ,Lamberton et al., 2004).
边栏推荐
- Ribbon负载均衡
- Implementation of UART with analog serial port
- Simple integration of client go gin 11 delete
- Using qtest for data set test performance test GUI test
- Pit of undefined reference
- [deeply understand tcapulusdb technology] realize tcapulusdb transaction management in the operation and maintenance platform
- 【深入理解TcaplusDB技术】创建游戏区
- I wrote a telnet command myself
- [in depth understanding of tcapulusdb technology] tcapulusdb adds a new business cluster cluster
- Can financial products be redeemed on weekends?
猜你喜欢

Simple integration of client go gin 11 delete
Gradle Build Cache引发的Task缓存编译问题
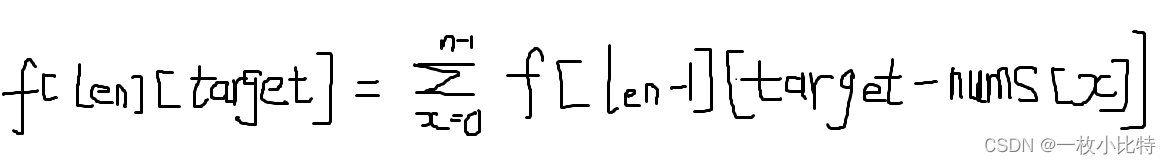
Comment le sac à dos complet considère - t - il la disposition?
Oracle system/用户被锁定的解决方法

科技云报道:东数西算不止于“算”,更需“新存储”

EasyDSS问题及解决方案汇总

他98年的,我玩不过他...

【Proteus仿真】74LS138译码器流水灯
client-go gin的简单整合十一-Delete
what? You can't be separated by wechat


随机推荐
Which securities firm is better to choose for opening an account in flush? Is it safe to open a mobile account?
[deeply understand tcapulusdb technology] realize tcapulusdb transaction management in the operation and maintenance platform
Scheduling with Testing
软件压力测试有哪些方法,如何选择软件压力测试机构?
理财产品在双休日可以赎回吗?
client-go gin的简单整合十一-Delete
Ribbon负载均衡
【Proteus仿真】NE555延时电路
Redis持久化的几种方式——深入解析RDB
MySQL Basics - functions
【深入理解TcaplusDB知識庫】部署TcaplusDB Local版常見問題
ROS从入门到精通(八) 常用传感器与消息数据
[deeply understand tcapulusdb technology] tcapulusdb table management - modify table
DynamicDatabaseSource,在应用端支持数据库的主从
UnityEditor 编辑器脚本执行菜单
Raspberry pie environment settings
智能計算之神經網絡(BP)介紹
【深入理解TcaplusDB技术】单据受理之建表审批
完全背包如何考慮排列問題
[deeply understand tcapulusdb technology] view the online operation of tcapulusdb