当前位置:网站首页>Semantic segmentation cvpr2019-advance: advantageous enterprise minimization for domain adaptation in semantic segmentation
Semantic segmentation cvpr2019-advance: advantageous enterprise minimization for domain adaptation in semantic segmentation
2022-06-25 05:27:00 【HheeFish】
ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation A domain adaptation method for semantic segmentation based on anti entropy minimization
Address of thesis
The code download
0. Abstract
Semantic segmentation is a key problem in many computer vision tasks . Although the method based on convolutional neural network is constantly breaking new records on different benchmarks , But extending it to different test environments is still a major challenge . In many practical applications , There is really a big gap between the data distribution in the training domain and the test domain , This can result in severe performance loss at runtime . In this work , We solve the unsupervised domain adaptive task in lossy semantic segmentation based on pixel prediction entropy . So , We propose two new complementary methods , Separate use (i) Entropy loss and (ii) Confrontational loss . We are in two challenging “ synthesis –> real ” It shows the latest performance of semantic segmentation , It is shown that this method can also be used to detect .
1. summary
Semantic segmentation is the task of assigning class labels to all pixels in an image . In practice , Segmentation models are usually complex computer vision systems ( For example, automatic driving vehicle. ) The pillar of , These systems require high accuracy in a variety of urban environments . for example , In bad weather , The system must be able to identify the road 、 Vehicle Lane 、 Side or pedestrian , Although their appearance is different from that of the people in the Training Center . A more extreme and important example is the so-called “ synthesis –> real ” Set up [31,30]—— Training samples are synthesized by the game engine , The test sample is a real scene . The current method of full supervision [23,47,2] There is no guarantee that any test case will be well generalized . therefore , A model trained on a domain called a source , When applied to another domain called the target , Usually experience a sharp drop in performance .
Unsupervised domain adaptation (Unsupervised domain adaptive, UDA) It is a research field , Its purpose is to learn the model with good performance on the target sample only from the source supervision . Recent UDA In the method , Many methods solve this problem by reducing cross domain differences , And conduct supervised training on the source domain . They approach by minimizing the difference between the intermediate feature distribution or the final output of the source data and the target data, respectively UDA. Use the maximum average difference (MMD) Or confrontation training (10,42) Can be in a single [15,32,44] Or multiple levels [24,25] Conduct . Other methods include self training [51] Providing pseudo tags or generating networks to generate target data [14,34,43].
Semi supervised learning solves a closely related problem , That is, learning from a subset of data . therefore , It inspired UDA Several ways to , for example , Self training , Generate model or career balance [49]. Entropy minimization is also semi supervised learning [38] One of the ways to succeed .
In this work , We apply the entropy minimization principle to UDA Semantic segmentation of tasks . Let's start with a simple observation : Models trained only on the source domain tend to produce overconfidence , Low entropy , However, the prediction of data similar to the source image is not confident , High entropy , Prediction of class target image . This phenomenon is shown in the figure 1 Shown . The scene prediction entropy map obtained from the source domain looks like the edge detection result along the target boundary with high entropy activation . On the other hand , The prediction of the target image is uncertain , Results in very noisy high entropy output . We think , One possible way is through Strengthen the high prediction certainty of target prediction ( Low entropy ) To bridge the gap between the source and the target . So , We propose two methods : Direct entropy minimization using entropy loss and indirect entropy minimization using anti entropy loss . The first method imposes a low entropy constraint on independent pixel prediction , The goal of the latter is to match the source and target distributions globally according to the weighted self information. Our contributions are summarized as follows :
- For semantic segmentation UDA, We propose to use entropy loss to directly punish the low confidence prediction in the target domain . The use of this entropy loss will not add significant overhead to the existing semantic segmentation framework .
- A new training method based on entropy is proposed , This method not only aims at minimizing entropy , And it aims at structural adaptation from source domain to target domain .
- In order to further improve the performance under specific settings , We propose two additional experiments :(i) Train specific entropy ranges and (ii) Incorporate analogical priors . We discussed practical insights in experimental and ablation studies .
The entropy minimization objective pushes the decision boundary of the model to the low-density region of the target domain in the prediction space . In this way, we can get “ Cleaner ” Semantic segmentation output , Finer object edges and larger blurred image areas are correctly restored , Pictured 1 Shown . The model proposed in this paper is applied in several UDA The effect of semantic segmentation on the benchmark is better than the most advanced method at present , In particular, the two main syntheses –> True datum ,GTA5→Cityscapes and SYNTHIA→Cityscapes.
2. Related work
Unsupervised domain adaptation is a hot topic in the field of classification and detection , In recent years, semantic segmentation technology has also made some progress . A very attractive application of domain adaptability is the use of synthetic data in real-world tasks . This has encouraged the development of several synthetic scenario projects with relevant data sets , Such as Carla [8], SYNTHIA[31] etc. [35,30].
UDA The main methods include Minimize the difference between source and target feature distribution [10,24,15,25,42]、 Pseudo label [51] Self training and generation methods [14,34,43]. In this work , What we are particularly interested in is for semantic segmentation UDA. therefore , We only review here the UDA Method ( For a more general literature review, see [7]).
in the light of UDA The confrontation training of is the most studied semantic segmentation method at present . It involves two networks . A network prediction input image segmentation mapping , It can come from either the source domain or the target domain , The other network acts as a discriminator , it Extracting feature maps from segmented networks , And try to predict the input domain . The segmented network tries to trick the discriminator , Thus, the features from the two domains have similar distribution .Hoffman wait forsomeone [15] Is the first to apply the countermeasure method to UDA People with semantic segmentation . By transferring tag statistics from the source domain , They also have category specific adaptability .[5] A similar global and class alignment method is used in , Class alignment is accomplished by antagonizing the soft pseudo labels of the grid . stay [4] in , Antagonism training is used for spatial perception adaptation and distillation loss , To solve the problem of synthesis –> Real field migration .[16] The residual net is used to make the source feature mapping similar to the target feature mapping , Then the feature mapping is used to segment tasks . stay [41] in , Use countermeasures in the output space , To benefit from cross domain structural consistency .[32,33] Another interesting way to use confrontation training : They make two predictions on the target domain image , It is composed of two classifiers [33] Accomplished , Or in the classifier [32] Use in dropout. Considering these two predictions , Train the classifier to maximize the difference between distributions , The feature extractor part of the training network minimizes the difference between distributions .
Some methods are based on Generation network On the basis of , Generate the target image based on the source .Hoffman Et al. Proposed cyclic uniform antagonism domain adaptation (CyCADA), Among them, they are adapted in the representation of pixel level and feature level . For pixel level adaptation , They use Cycle-GAN[48] Generate a target image from the source image . stay [34] in , Learning to generate models , Image reconstruction from feature space . then , For domain adaptation , The training feature module generates the target image according to the source feature , vice versa . stay DCAN[43] in , The feature alignment of channel is used in generator and partition network . Segmentation network is learned from the generated images with source content and target style , Source partition graph as target groundtruth.[50] The authors use generative countermeasure networks (GAN)[11] To align the source and target embedding . Besides , They also use a conservative loss (CL) Instead of cross entropy loss , This loss penalizes the easy and difficult cases in the source example .CL The method is orthogonal to most UDA Method , Including our : It can benefit any method that uses cross entropy as a source .
UDA Another way to do this is to train yourself . The idea is to use the prediction of the integrated model or the previous state of the model as the pseudo label data , To train the current model . Many semi supervised methods [20,39] Use self training . stay [51] in ,UDA Self training method is used for semantic segmentation , It is further extended on the basis of class balance and space priority . Self training is with us 3.1 There is an interesting connection between the entropy minimization methods discussed in section .
In other ways ,[26] Use a combination of countermeasures and generation techniques through multiple losses ,[46] Combined with the generation method for appearance adaptation and confrontation training for representation adaptation ,[45] By strengthening the local ( Super pixel level ) Consistency with global label distribution , by UDA Put forward a course based learning .
Entropy minimization has been proven for semi supervised learning [12,38] And clustering [17,18] It is useful to . This method has also recently been used to classify tasks [25] Domain adaptation . As far as we know , We are the first to successfully integrate entropy - based UDA Training the competitive performance of semantic segmentation tasks .
3. Method
In this section , We introduce two entropy minimization methods we have proposed , Use (i) Unsupervised entropy loss and (ii) Confrontation training . To build our model , We start with the existing semantic segmentation framework , And add an additional network branch for domain adaptation . chart 2 Illustrates our architecture .
chart 2: Methods an overview . The picture shows our understanding of UDA Two methods of . First , Direct entropy minimization makes the target Pxt The entropy of is the smallest , Equivalent to minimizing the sum of weighted self information mapping . In the second complementary approach , We use confrontational training to strengthen Ix Cross domain consistency . The red arrow is used for the target domain , The blue arrow is used for the source . An example of entropy mapping is given .
Our model is trained on the source domain using supervised loss . Formally , Let's consider a group Xs⊂RH×W×3 Source example of , And related ground-truth C Class partition graph ,Ys⊂(1,C)H×W. sample xs It's a picture H × W Color image of , Input ys(H,W)=[ys(H,W,c)] Associated map ys Provide pixels (h, w) The label of is a unique hot code vector . set up F Segment the web for semantics , Take an image x, forecast c dimension “ Soft segmentation graph ”F (x) = Px =[Px(w,h,c)]h,w,c. Through the final softmax layer , Every c Vector in the direction of the dimension pixel [Px(w,h,c)]c It is shown as discrete distribution on classes . If a class protrudes , The distribution is low entropy , If the scores are uniformly distributed , From the perspective of the Internet , This is a sign of uncertainty , Entropy is very large . Study F Parameters of θF To minimize segmentation losses Lseg(xs, ys) =−∑Hh=1∑Ww=1∑Cc=1y(h,w,c)s(logP(h,w,c)xs). When only the source domain is trained without domain adaptation , The optimization problem is :
3.1. Direct entropy minimization
For the target domain , Because we don't have an image sample xt∈Xt Notes yt, So we can't use (1) To learn F. Some methods use model predictions y∧t As yt An alternative . Besides , This substitution is only used to predict pixels with sufficient confidence . We Do not use highly confident agents , Instead, it proposes a constraint model , Make it produce highly confident predictions . We do this by minimizing the entropy of the prediction .
We introduce entropy loss Lent Directly maximize the prediction certainty of the target domain . In this work , We use Shannon entropy [36]. Given the target input image xt, Entropy mapping Ext∈[0,1]H×W From normalization to [0,1] Within the scope of Independent pixel entropy form ,(h,w) The entropy of the pixel at is :
An example of entropy mapping is 2 Shown . Entropy loss Lent Defined as the sum of normalized entropy at all pixel levels :
In the process of training , We Jointly optimize the supervised segmentation loss of source samples Lseg And the unsupervised entropy loss of the target sample Lent. The final optimization problem is expressed as :
λent As entropy Lent The weight factor of
The connection with self training : Pseudo mark It is a simple and effective semi supervised learning method . In recent years , This method has been applied to iterative self training (ST) Program [51] In the semantic segmentation task of .ST The method assumes that the target sample is High score pixels The set of predictions K⊂(1,H) × (1, W) That's right. , And the probability is high . This assumption allows the use of cross entropy loss and false label target prediction . In practice ,K It is constructed by selecting high resolution pixels with a fixed threshold or a predetermined threshold . To be associated with entropy minimization , We will ST The training problem of the method is written as :
among y∧t yes xt Single hot code category prediction , And there are :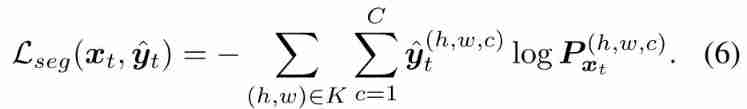
Comparison (2-3) and (6), We notice our entropy loss Lent(xt) It can be regarded as false label cross entropy loss Lseg(xt,y∧t) Soft distribution version of . And ST[51] Different , Our entropy based approach No complex scheduling process is required to select the threshold . even to the extent that , And ST Suppose the opposite , We are 4.3 It is shown in section , In some cases , Training “ difficult ” or “ The most confused ” Pixels produce better performance .
3.2. Minimizing entropy by adversarial learning
chart 2: Methods an overview . The picture shows our understanding of UDA Two methods of . First , Direct entropy minimization makes the target Pxt The entropy of is the smallest , Equivalent to minimizing the sum of weighted self information mapping . In the second complementary approach , We use confrontational training to strengthen Ix Cross domain consistency . The red arrow is used for the target domain , The blue arrow is used for the source . An example of entropy mapping is given .
In the type (3) in , The entropy loss of the input image is defined as the sum of the predicted entropy of the independent pixels . therefore , The minimization of this loss Ignoring the structural dependencies between local semantics . Such as [41] Shown , about UDA When semantic segmentation , Yes Structured output space for adaptation It's good . Based on the source domain and the target domain Semantic layout Have a strong similarity in .
In this part , We introduced a unified confrontation training framework , adopt The entropy distribution of the target is similar to that of the source to minimize the entropy indirectly . This allows for leveraging structural consistency between domains . So , We will UDA The task is defined as in the weighted self information space Minimize the distribution distance between source and target . chart 2 It explains our confrontation learning process . The motivation for our method of confrontation is , Trained model Naturally generate low entropy predicted source images . adopt Align the weighted self information distribution of the target domain and the source domain , Indirectly minimize the target prediction entropy . Besides , Because the adaptation is carried out in the weighted self information space , Our model takes advantage of structural information from source to target .
say concretely , Given the pixel level class prediction score Px(h,w,c), Self information or “surprisal”[40] Defined as −log Px(h,w,c). actually ,(2) The entropy in the equation Ex(h,w) Is self information Ec[−log Px(h,w,c)] The expectation of . We are using pixel level vectors Ix(h,w) = -Px(h,w,c)logPx(h,w,c) The weighted self information mapping Ix On the . These vectors can be thought of as Shannon De entanglement of entropy . then , We construct a Full convolution discriminator network D, Parameters θD With Ix For input , Generate domain classification output , That is, the category is marked as 1(0) As source ( The goal is ) Domain . And [11] similar , We train The recognizer distinguishes the output from the source image and the target image , Training at the same time Split the network to cheat the recognizer . among , Give Way LD Represents the classification loss in the cross entropy domain . The training objective of the discriminator is :
The countervailing goal of training partition network is :
combination (1) and (8), Get the optimization problem :
Use counter items LD Weighting factor of λadv. During training , We use (7) and (9) The objective function in alternates to optimize the network D and F.
3.3. A priori knowledge of the proportion of categories used jointly
Entropy minimization may favor some simple classes . therefore , Sometimes it is useful to use some prior knowledge to guide learning . So , We are based on the distribution of classes on the source tag , Use a simple class a priori . We put the number of pixels of each class on the source tag ℓ1- The normalized histogram is calculated as a class of prior vectors ps. Now? , According to the forecast Pxt, The expected probability of any category is the same as that of the previous category ps Too big a difference between them will be punished , Use 
among ,µ∈[0,1] Used to relax class a priori constraints . This solves the problem that the class distribution on a single target image is not necessarily close ps Fact .
4. experiment
In this section , We will present our experimental results . The first 4.1 Section describes the data sets used and our training parameters . stay 4.2 Festival sum 4.3 In the festival , We report and discuss our main results . stay 4.3 In the festival , We discuss the entropy based UDA Preliminary results of the test .
4.1. Details of the experiment
Data sets
To evaluate our approach , We use challenging synthesis –> Real unsupervised domain adaptation settings . The model is trained on fully annotated synthetic data , And verified on real-world data . In this setup , The model can obtain some unlabeled real images in training . To train our model , We use GTA5[30] or SYNTHIA[31] Compose data as a source domain , And will Cityscapes Data sets [6] Training segmentation as target domain data . Similar settings have been used in other works before [15,14,41,51].
- GTA5→Cityscapes:GTA5 Data set from 24,966 Frame composition of the video game screen . The image provides 33 Pixel level semantic annotation of classes . And [15] similar , We used and cityscape Data sets are the same 19 Classes .
- SYNTHIA→Cityscapes: We use SYNTHIARAND-CITYSCAPES aggregate 4 and 9400 Zhang synthetic images for training . We use it SYNTHIA and cityscape Medium 16 A public class to train our model . In the evaluation , We compared [51] The protocols used in 16 Classes and 13 Performance on a subset of classes .
In both settings ,2975 Unlabeled urban landscape images were used for training . We use the standard average - The intersection - Merge (mIoU) Measure [9] To measure segmentation performance . Yes 500 A validation image was used for evaluation .
Network architecture
We use Deeplab-V2[2] As the basic semantic segmentation Architecture F. To better capture the scene context , The feature output of the last layer adopts Atrous Space pyramid pool (Atrous Spatial Pyramid Pooling, ASPP). The sampling rate is fixed to {6,12,18,24}, Be similar to [2] Medium ASPP-L Model . We are in two different base deep CNN Experiments on the architecture :VGG-16[37] and ResNet101[13]. stay [2] after , We modified the last layer stride and expand rate, To produce more dense 、 With a wider view feature map. In order to further improve ResNet-101 Performance of , We are from conv4 and conv5[41] The multi-level output characteristics of the .
chapter 3.2 The countermeasure network introduced in D Have and DCGAN[28] The same architecture used in . Weighted self information mapping Ix adopt 4 Volume layer forwarding , Each convolution has a fixed negative slope of 0.2 Of leaky-ReLU Layer coupling . Last , The classifier layer generates classification output , Indicates whether the input corresponds to the source domain or the target domain
Implementation details
We used in our implementation PyTorch Deep learning framework [27]. All the experiments were carried out in a single NVIDIA 1080TI Completed on the graphics card , Memory is 11 GB. except 3.2 In addition to the confrontation discriminator mentioned in section , Our model uses a random gradient descent optimizer [1] Trained , The learning rate is 2.5 × 10−4, Momentum is 0.9, The attenuation of the weight is 10−4. We use a learning rate of 10−4 Of Adam Optimizer [19] To train the discriminator . In order to arrange the learning rate , We followed [2] Polynomial annealing program mentioned in .
Entropy and the weight factor of antagonism loss : by Lent Set weight , The performance of the training set provides an important indicator . When λent large , Entropy drops too fast , The model strongly favors a few classes . When λent When the selection is within a certain range , Good performance , Insensitive to precision values . therefore , Whether network or data set , We used the same for all the experiments λent = 0.001. about (9) The weight in λadv, There are similar arguments . In all experiments, we have determined that λadv= 0.001.
4.2. result
We compare the experimental results of these methods with different baselines . Our model is in two UDA State of the art performance is achieved in the benchmark . In the following content , We show how our approach behaves in different settings , The training set and the basics cnn.
GTA5→Cityscapes
We are on the table 1 It was reported in Cityscapes On the verification set mIoU(%) Semantic segmentation performance . Our first kind Direct entropy minimization method , In the table 1-a called MinEnt, Based on VGG-16 and resnet -101 Of cnn The performance comparable to the most advanced baselines has been achieved on . In the absence of balance with the category [51] Under the circumstances ,MinEnt Than self training (ST) Methods perform better . And [41] comparison , be based on resnet -101 Of MinEnt Shows similar results , But there is no training using the discriminator network . The light cost of entropy loss greatly reduces the training time . Another advantage of our entropy method is that it is easy to train . in fact , Training countermeasure networks is often considered a difficult task , Because it is unstable . We observe a more stable behavior training model with entropy loss .
Interestingly , We found that in some cases , Only when entropy loss is applied in a certain range, the effect is the best . This phenomenon is based on resnet -101 Model observed . in fact , By training entropy before each target sample 30% The pixel , We can get a better model . The model is shown in table 1-a called MinEnt+ER. We are GTA5→Cityscapes Using this strategy in the settings, we get 43.1% Of mIoU. See page for more details 4.3 section .
Our second method uses the counter training in the weighted self information space , namely AdvEnt, Show continuous improvement over baseline on both base Networks . Generally speaking ,AdvEnt Work better than MinEnt good . stay GTA5→CityscapesUDA Setting up ,AdvEnt Reached the most advanced mIoU 43.8. These results confirm the importance of structural adaptation . Using a vgg -16 Network of , Compared with direct entropy minimization , The adaptation of weighted self information space brings +3.3% mIoU Improvement . Based on resnet101 Network of , Minor improvements , namely +1.5% mIoU. We speculate , because GTA5 Semantic layout and Cityscapes The semantic layout in is very similar , therefore ResNet-101 Etc. with high capacity CNN Basic partition network F We can learn some spatial priors from the supervision of source samples . For things like VGG-16 In this way Low capacity base model , It is more beneficial to carry out additional regularization and confrontation training in structured space .
adopt combination MinEnt and AdvEnt The results of the two models , We observed that compared with the results of a single model , The performance has been greatly improved . The combination is in Cityscapes The verification set implements 45.5% Of mIoU. The information learned by the two models is Complementary . in fact , although Entropy loss penalizes independent pixel level prediction , But the antagonistic loss acts more on the image level , Scene topology . And [41] similar , In order to communicate with others UDA Methods to make a more meaningful comparison , In the table 2-a in , We showed UDA Model and oracle The performance gap between , That is to say Cityscapes A fully supervised model on a training set . Compared with the model trained by other methods , Our single and integrated model is similar to oracle Of mIoU The gap is smaller .
In the figure 3 in , We show some qualitative results of our model . Without domain adaptation , The model trained only on source monitoring will produce noisy segment prediction and high entropy activation , In some classes ( Such as “building” and “car”) There are a few exceptions . For all that , There are still many completely wrong self-confidence predictions ( Low entropy ). On the other hand , Our model can produce correct predictions with high confidence . We observed that , Overall speaking , And MinEnt The model compares ,AdvEnt The model achieves lower prediction entropy .
chart 3: GTA5 Qualitative results in →Cityscapes Set up . Column (a) The input image and the corresponding semantic segmentation are displayed . Column (b)、(c) and (d) The segmentation results are displayed ( Bottom ) And the predicted entropy map generated by different methods ( Top ). It's best to watch in color .
SYNTHIA→Cityscapes
surface 1-b Shows the... Of the urban landscape validation set 16 Classes and 13 The result of a subset of classes . We noticed that , And GTA5 and Cityscapes Compared with the scene image in ,SYNTHIA Scene image in Covers more different viewpoints . This leads to different behaviors of our methods .
Based on VGG-16 On the Internet ,MinEnt The model shows results comparable to the latest methods . And self training [51] comparison , Our model is in 16 Classes and 13 Class subsets respectively reach +3.6% and +4.7%. However , Compared with stronger baseline such as category balance self training , We observe categories “ road ” A marked decline . We think this is due to SYNTHIA and Cityscapes A huge gap in layout . To solve this problem , We introduce the source domain Category accounts for prior knowledge , As the first 3.3 Section . By using The category ratio priori constrains the target output distribution , As shown in the table 1b Medium CP Shown , We are 16 Classes and 13 Class subset MinEnt Improved +2.9%mIoU. Through confrontational training , We have an extra growth 1%. Based on ResNet-101 On the Internet ,AdvEnt The model achieves the most advanced performance . And [41] Retraining model ( namely Adapt SegMap*) comparison , The emergence of this model will 16 Classes and 13 Class subset mIoUs Improved respectively +1.2% and +1.8%. With the above GTA5 Consistent result , stay SYNTHIA Two models of training on MinEnt and AdvEnt The collection of is in 16 Classes and 13 Class subsets respectively reach 41.2% and 48.0% The best mIoU. According to the table 2-b, Our model and oracle Of mIoU The gap is the smallest .
4.3. Discuss
The first 4.2 The experimental results in section verify the advantages of our method . To further drive performance , We propose two different methods to regulate training in two specific environments . This section discusses our experimental choices and explains the intuition behind them .
GTA5→Cityscapes: Train in a certain entropy range
In this setting , We observed that the use was based on ResNet-101 The performance of network model mining can be improved by training on the target pixels with entropy in a specific range . Interestingly , first-class MinEnt The model is in front of each target sample 30% Trained on the highest entropy pixel , More than ordinary model 0.8% Of mIoU. We noticed that , High entropy pixels are “ Most easily confused ” The pixel , in other words , The segmentation model is uncertain between multiple classes . One reason is based on ResNet-101 The model has good generality in this particular environment . therefore , stay “ The most puzzling ” In the prediction of , A considerable number of predictions are correct , but “ Low confidence ”. Minimizing the entropy loss on such a set will still push the model towards the ideal direction . However , This assumption does not apply based on VGG-16 Model of .
SYNTHIA→Cityscapes: Use a priori knowledge of class proportions
As mentioned earlier ,SYNTHIA The layout and perspective of the city landscape Cityscapes Obviously different . This difference can cause very bad predictions for some classes , This prediction is then further encouraged by minimizing entropy or using it as a marker agent in self-training . therefore , It can lead to strong class bias , Or in extreme cases , Some classes are completely missing from the target domain . stay Adding a class ratio earlier encourages the existence of all classes , Thus, it is helpful to avoid such degenerate solutions . As described in Section .3.3, We use µ To relax the source analogy priority , for example µ=0 Indicates no priority , and µ=1 Indicates that the exact analogy priority is enforced .µ=1 Not ideal , Because this means that each target image should follow the class ratio of the source domain . We choice µ=0.5 So that the target class ratio is slightly different from the source analogy ratio .
**UDA Application in target detection **
The proposed entropy based method is not limited to semantic segmentation , And it can be applied to UDA Other identification tasks , Such as target detection . We are UDA Object detection device Cityscapes The experiment was carried out in the laboratory Cityscapes→Cityscapes Foggy, And [3] The similarity in . Entropy loss and antagonism loss are directly applied to the existing detection architecture SSD-300[22], Compared to the baseline model trained only on the source , Significantly improved detection performance . Average accuracy (mAP) for , And 14.7% Compared to the baseline performance ,MinEnt and AdvEnt Model mAP Respectively 16.9% and 26.2%. stay [3] in , The author reports 27.6%mAP The performance is slightly better , Use faster RCNN[29], This is a more complex detection architecture than ours . We noticed that , Our detection system works at a lower resolution ( namely 300×300) The images were trained and tested . Despite these disadvantages , Our baseline improvements (+11.5% Use AdvEnt Map ) Greater than [3] Improvements reported in (+8.8%). Such a preliminary result shows that the entropy based method can UDA Possibility of testing on . surface 3 Each category is reported IoU, chart 4 It shows the qualitative results of urban landscape fog . 

5. Conclusion
In this work , We propose two complementary entropy based semantic segmentation methods . Our model is in two challenging “ synthesis –> real ” The benchmark has reached the most advanced level . The integration of the two models further improves performance . In the UDA On , We show a promising result , And I believe that using a more robust detection architecture can achieve better performance .
reference
[1] L. Bottou. Large-scale machine learning with stochastic gradient descent. In COMPSTAT. 2010. 5
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. PAMI, 2018. 1, 5
[3] Y. Chen, W. Li, C. Sakaridis, D. Dai, and L. Van Gool. Domain adaptive faster R-CNN for object detection in the wild. In CVPR, 2018. 8
[4] Y. Chen, W. Li, and L. Van Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In CVPR, 2018. 2
[5] Y.-H. Chen, W.-Y. Chen, Y.-T. Chen, B.-C. Tsai, Y.-C. F. Wang, and M. Sun. No more discrimination: Cross city adaptation of road scene segmenters. In ICCV, 2017. 2
[6] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The Cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 5
[7] G. Csurka. Domain adaptation for visual applications: A comprehensive survey. Springer. 2
[8] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. CARLA: An open urban driving simulator. In CoRL, 2017. 2
[9] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The Pascal visual object classes challenge: A retrospective. IJCV, 2015. 5
[10] Y. Ganin and V. Lempitsky. Unsupervised domain adaptation by backpropagation. In ICML, 2015. 1, 2
[11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014. 3, 4
[12] Y. Grandvalet and Y. Bengio. Semi-supervised learning by entropy minimization. In NIPS, 2005. 3
[13] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 5
[14] J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. Efros, and T. Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In ICML, 2018. 1, 2, 5, 6, 7
[15] J. Hoffman, D. Wang, F. Yu, and T. Darrell. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 1, 2, 5, 6, 7
[16] W. Hong, Z. Wang, M. Yang, and J. Yuan. Conditional generative adversarial network for structured domain adaptation. In CVPR, 2018. 2
[17] H. Jain, J. Zepeda, P. Pérez, and R. Gribonval. Subic: A supervised, structured binary code for image search. In ICCV, 2017. 3
[18] H. Jain, J. Zepeda, P. Pérez, and R. Gribonval. Learning a complete image indexing pipeline. In CVPR, 2018. 3
[19] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2015. 5
[20] S. Laine and T. Aila. Temporal ensembling for semisupervised learning. arXiv preprint arXiv:1610.02242, 2016. 3
[21] D.-H. Lee. Pseudo-label: The simple and efficient semisupervised learning method for deep neural networks. In ICML Workshop, 2013. 3
[22] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg. SSD: single shot multibox detector. In ECCV, 2016. 8
[23] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 1
[24] M. Long, Y. Cao, J. Wang, and M. I. Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015. 1, 2
[25] M. Long, H. Zhu, J. Wang, and M. I. Jordan. Unsupervised domain adaptation with residual transfer networks. In NIPS, 2016. 1, 2, 3
[26] Z. Murez, S. Kolouri, D. Kriegman, R. Ramamoorthi, and K. Kim. Image to image translation for domain adaptation. In CVPR, 2018. 3
[27] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in PyTorch. In NIPS Workshop, 2017. 5
[28] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. 5
[29] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 8
[30] S. R. Richter, V. Vineet, S. Roth, and V. Koltun. Playing for data: Ground truth from computer games. In ECCV, 2016. 1, 2, 5
[31] G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, 2016. 1, 2, 5
[32] K. Saito, Y. Ushiku, T. Harada, and K. Saenko. Adversarial dropout regularization. In ICLR, 2018. 1, 2
[33] K. Saito, K. Watanabe, Y. Ushiku, and T. Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, 2018. 2
[34] S. Sankaranarayanan, Y. Balaji, A. Jain, S. Nam Lim, and R. Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In CVPR, 2018. 1, 2
[35] A. Shafaei, J. J. Little, and M. Schmidt. Play and learn: Using video games to train computer vision models. In BMVC, 2016. 2
[36] C. E. Shannon. A mathematical theory of communication. Bell system technical journal, 1948. 3
[37] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 5
[38] J. T. Springenberg. Unsupervised and semi-supervised learning with categorical generative adversarial networks. ICLR, 2016. 2, 3
[39] A. Tarvainen and H. Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semisupervised deep learning results. In NIPS, 2017. 3
[40] M. Tribus. Thermostatics and thermodynamics. van Nostrand, 1970. 4
[41] Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, 2018. 2, 4, 5, 6, 7
[42] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017. 1, 2
[43] Z. Wu, X. Han, Y.-L. Lin, M. Gokhan Uzunbas, T. Goldstein, S. Nam Lim, and L. S. Davis. DCAN: Dual channel-wise alignment networks for unsupervised scene adaptation. In ECCV, 2018. 1, 2, 3
[44] H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In CVPR, 2017. 1
[45] Y. Zhang, P. David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, 2017. 3
[46] Y. Zhang, Z. Qiu, T. Yao, D. Liu, and T. Mei. Fully convolutional adaptation networks for semantic segmentation. In CVPR, 2018. 3
[47] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In CVPR, 2017. 1
[48] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In ICCV, 2017. 2
[49] X. Zhu. Semi-supervised learning literature survey. Technical Report 1530, Computer Sciences, University of Wisconsin-Madison, 2005. 2
[50] X. Zhu, H. Zhou, C. Yang, J. Shi, and D. Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In ECCV, September 2018. 3
[51] Y. Zou, Z. Yu, B. V. Kumar, and J. Wang. Unsupervised domain adaptation for semantic segmentation via classbalanced self-training. In ECCV, 2018. 1, 2, 3, 4, 5, 6, 7
边栏推荐
- 投资理财产品的年限要如何选?
- Page electronic clock (use js to dynamically obtain time display)
- 1.6.3 use tcpdump to observe DNS communication process
- Even if you are not good at anything, you are growing a little bit [to your 2021 summary]
- Mysql interactive_ Timeout and wait_ Timeout differences
- How to use the Magic pig system reinstallation master
- Tanhaoqiang C language practice
- Word of the Day
- Critical dependency: require function is used in a way in which dependencies
- Baidu ueeditor set toolbar initial value
猜你喜欢

IronOCR 2022.1 Crack

Eyeshot 2022 Released

Enhanced paste quill editor

Array and simple function encapsulation cases

Notes on non replacement elements in the line (padding, margin, and border)

XSS (cross site script attack) summary (II)

Eyeshot Ultimate 2022 Crack By Xacker

How to open the DWG file of the computer

1.5.3 use tcpdump to observe ARP communication process

Small sample learning data set
随机推荐
I got to know data types and function variables for the first time. I learned data types and function variables together today and yesterday, so I saved them in the first issue to record.
Go Context - Cancelation and Propagation
Database query optimization method
The article is on the list. Welcome to learn
[pan Wai 1] Huawei computer test
Characteristics of ES6 arrow function
The construction and usage of wampserver framework
Only these four instructions are required to operate SQL data
Ranorex Studio 10.1 Crack
Precise delay based on Cortex-M3 and M4 (systick delay of system timer can be used for STM32, aducm4050, etc.)
Extend the toolbar of quill editor
Page electronic clock (use js to dynamically obtain time display)
C language - minesweeping
Flex flexible layout for mobile terminal page production
Conflict between v-mode and v-decorator in Ant Design
Try block and exception handling
Array and simple function encapsulation cases
JS handwriting depth clone array and object
Mysql interactive_ Timeout and wait_ Timeout differences
Large number operation (capable of square root, power, permutation and combination, logarithm and trigonometric value)