当前位置:网站首页>[machine translation] scones -- machine translation with multi tag tasks
[machine translation] scones -- machine translation with multi tag tasks
2022-07-25 09:58:00 【Tobi_ Obito】
《Jam or Cream First?Modeling Ambiguity in Neural MachineTranslation with SCONES》 https://arxiv.org/pdf/2205.00704.pdf
https://arxiv.org/pdf/2205.00704.pdf
Preface
Previously, I was responsible for a multi-level and multi label classification project , So the difference from multi classification to multi label is very clear , Recently, I got interested in this paper , Then the method is very simple , It is basically a standard multi label task mode . Simple as it is , But this is not for flowers “ Flower board ”, It accurately captures the problems caused by current machine translation training methods ——decoding Process model output layer softmax Suppressed “ Not ground truth But reasonable ” The possibility of word formation , And into multiple binary classifications +sigmoid The common form of multi label task avoids this problem , So the focus shifts to how to split and model into multiple binary tasks and effective multi tags loss The design of the .
From multi classification to multi label
Here is a quick introduction Multi label (multi-label) classification A typical mode of .
Put aside the model structure , The common single label multi classification task for model output processing is : Yes logit Conduct softmax Activation completes normalization ( Probabilistic ), And then to Multi category cross entropy Train as a loss .
Then can we use the above mode to do multi label classification tasks directly ? What's the problem ?
1. Multi category cross entropy (CE) Are not compatible
The calculation requirements of multi classification cross entropy ground truth Must be one-hot Of , And multi label tasks ground truth Obviously multi-hot Of . Then can you draw the gourd directly ? Since multi classification cross entropy is a choice one-hot Medium 1 Calculate the probability of location , So many labels to choose multi-hot Medium 1 Is it possible to calculate the cross entropy of position probability and then sum it , But there are 2 A question : First of all , The uncertainty brought by summation guides ; second , The normalization of probability .
For the first question , Imagine the following : For a sample with two correct labels ( Might as well set label=[1,1]), The predicted value is [0.3, 0.7] or [0.7, 0.3] When calculating the cross entropy according to the above summation method, the calculation result is exactly the same , This means that in the case of multiple correct labels, there is no discrimination for each correct label . The reader may think : It's not a problem , Just know which labels are correct , Discrimination is not necessary , But in fact, due to the combination diversity of multiple tags , It will greatly increase the difficulty of learning . The second problem is fatal .
For the second question , Because the prediction vector prob Is calculated by logit adopt softmax After probabilistic , It means that the sum of all elements in the prediction vector is 1, Under the above calculation method ,label=[1,1] It brings “ guide ” Is to make the prediction vector tend to [0.5, 0.5], that label=[1,1,1] be “ guide ” The prediction vector tends to [0.3, 0.3, 0.3], Then the prediction threshold cannot be set ( Multiple tags obviously need to select the prediction results that exceed the threshold , Instead of selecting the maximum directly in the case of single label ), This makes it impossible to predict . This problem can be vividly described as softmax As a result of “ Correct labels inhibit each other ” problem .
A typical way to solve the above problems is to put aside probability , Treat the classification of each label as 2. Classified tasks , The dimension of the prediction vector output from the model remains unchanged , But every position is split 、 Look independently as a label 1/0 Dichotomous problem , In this way, the prediction results of multiple tags can be obtained through a fixed threshold : Label the position where the predicted value exceeds the threshold as 1. such as , The threshold for 0.5, Prediction vector [0.3, 0.9, 0.7] It means that the prediction result is [0, 1, 1]. Then the specific method is : Pass one at each position of the model output sigmoid Limit values to [0, 1] Within the interval , Reuse Two categories cross entropy (BCE) Calculate the loss and train .
In machine translation “ Multi label ”
Set the multi label mode as logit->sigmoid->bce loss, So how to model a translation task as a multi label task ? The prediction of each translated word is regarded as multi label classification , correct ( Or reasonable ) Words of are regarded as positive labels ,vocab All other words in are considered negative labels , So it is modeled as ( Thesis formula 5、6、7、8):
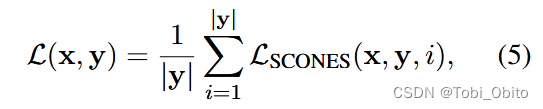

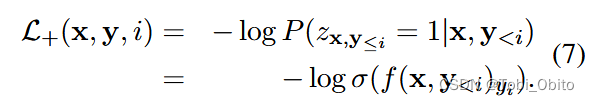

To sum up, it is divided into each translation step,ground truth word As a positive label , Not ground truth word(in vocab) As a negative label , from α Adjust two loss.
Conclusion
The method of this paper ends here , At the end of the paper, I specially emphasized the above loss Especially similar to Noise-Contrastive Estimation(NCE) The difference between , But I think the difference lies more in the application of ideas , The only technical difference is that negative labels are no longer noise in translation tasks , It is vocab Medium all Not ground truth word . Looking back, the discovery method is basically a multi label classification method , Through this simple idea, we solved softmax It brings about the mutual inhibition of reasonable word translation . Finally, the experiment proves that this method really achieves the expectation , Effectively alleviated softmax+ce Form brings beam search curse problem , To put it bluntly, the translation inhibition of reasonable words has been alleviated , Thus, it shows a good effect on the translation experiment results of synonymous sentences , And the speed is relatively more advantageous ( Small beam size Can achieve greater than the traditional way beam size Better results ), So that we can achieve the same level performance The translation speed is faster .
边栏推荐
- Mlx90640 infrared thermal imaging sensor temperature measurement module development notes (III)
- TM1637带秒点四位LED显示器模块ARDUINO驱动程序
- 单目深度估计基础理论和论文学习总结
- 工程监测无线中继采集仪和无线网络的优势
- ISP image signal processing
- ADC introduction
- First knowledge of opencv4.x --- image convolution
- Swift creates weather app
- Introduction to armv8 architecture
- 预测2021年:加速实现RPA以外的超自动化成果
猜你喜欢

看一个双非二本(0实习)大三学生如何拿到阿里、腾讯的offer

Creation of adjacency table of undirected connected graph output breadth depth traversal

First acquaintance with opencv4.x --- ROI interception

单目深度估计自监督模型Featdepth解读(上)——论文理解和核心源码分析

SOC芯片内部结构

ROS分布式操作--launch文件启动多个机器上的节点

First knowledge of opencv4.x --- image convolution

js利用requestAnimationFrame实时检测当前动画的FPS帧率
OC -- Inheritance and polymorphic and pointer

Mlx90640 infrared thermal imager temperature measurement module development instructions
随机推荐
AI模型风险评估 第1部分:动机
Introduction to armv8 architecture
深入理解pytorch分布式并行处理工具DDP——从工程实战中的bug说起
Mlx90640 infrared thermal imaging sensor temperature measurement module development notes (II)
Mlx90640 infrared thermal imager temperature measurement module development instructions
VScode配置ROS开发环境:修改代码不生效问题原因及解决方法
CDA LEVELⅠ2021新版模拟题二(附答案)
Introduction to armv8 general timer
单目深度估计自监督模型Featdepth解读(下)——openMMLab框架使用
Linked list -- basic operation
About student management system (registration, login, student side)
ADC简介
ADC introduction
手持振弦VH501TC采集仪传感器的连接与数据读取
First knowledge of opencv4.x --- box filtering
Segmentation based deep learning approach for surface defect detection
无线中继采集仪的常见问题
ROS分布式操作--launch文件启动多个机器上的节点
Visualization of sensor data based on raspberry pie 4B
AMD EPYC 9664旗舰规格曝光:96核192线程 480MB缓存 3.8GHz频率