当前位置:网站首页>Flink accumulator Counter 累加器 和 计数器
Flink accumulator Counter 累加器 和 计数器
2022-08-05 05:14:00 【bigdata1024】
Accumulators(累加器)是非常简单的,通过一个add操作累加最终的结果,在job执行后可以获取最终结果
最简单的累加器是counter(计数器):你可以通过Accumulator.add(V value)这个方法进行递增。在任务的最后,flink会吧所有的结果进行合并,然后把最终结果发送到client端。累加器在调试或者你想更快了解你的数据的时候是非常有用的。
Flink现在有一下内置累加器。每个累加器都实现了Accumulator接口。
- IntCounter, LongCounter 和 DoubleCounter:下面是一个使用计数器的例子。
- Histogram(直方图):针对离线箱子数量的直方图实现。内部是一个map,从integer到integer。你可以使用它来计算分布式的值。例如:分布式的单词统计程序。
如何使用累加器
第一步你需要在你想要使用的地方创建一个自定义的transformation算子,在算子中创建一个累加器对象(在这是一个counter)。
private IntCounter numLines = new IntCounter();第二步你需要注册这个累加器对象,通常在rich函数的open方法里面。在这里你也可以定义一个名字
getRuntimeContext().addAccumulator("num-lines", this.numLines);
现在你可以在任何操作中使用这个累加器,包含open方法和close方法
this.numLines.add(1);最终的总结果将会存储在从execute()中返回的JobExecutionResult对象中。(这个操作需要等待任务执行完成)
myJobExecutionResult.getAccumulatorResult("num-lines")所有的累加器在一个job任务中都是只共享一个单独的命名空间,所以你可以在你的job任务中的不同算子函数中使用相同的累加器,flink内部会合并所有名称相同的累加器。
在使用累加器和迭代器的时候注意:目前累加器的最终结果只能在任务执行结束之后才能获得。我们也计划在下一次迭代的时候返回上一次迭代的结果。你可以使用聚合器来计算每个迭代统计等数据
自定义累加器
实现自定义的累加器只需要实现Accumulator接口即可。随意创建一个pull请求,如果你认为你的自定义累加器应该附加在flink上面。
你可以选择实现Accumulator 或者 SimpleAccumulator
Accumulator<V,R>是最灵活的。它定了一个V类型的值可以进行累加,和一个R类型的值作为最终结果。例如:针对一个直方图,V是一个数字,R是一个直方图。
SimpleAccumulator的情况下,这两种类型都是一样的,例如:counters累加器。
获取更多大数据资料,视频以及技术交流请加群:

边栏推荐
- 2023 International Conference on Information and Communication Engineering (JCICE 2023)
- Basic properties of binary tree + oj problem analysis
- 【读书】长期更新
- Qt produces 18 frames of Cupid to express his love, is it your Cupid!!!
- Transformation 和 Action 常用算子
- Returned object not currently part of this pool
- 序列基础练习题
- Detailed Explanation of Redis Sentinel Mode Configuration File
- phone call function
- 【After a while 6】Machine vision video 【After a while 2 was squeezed out】
猜你喜欢








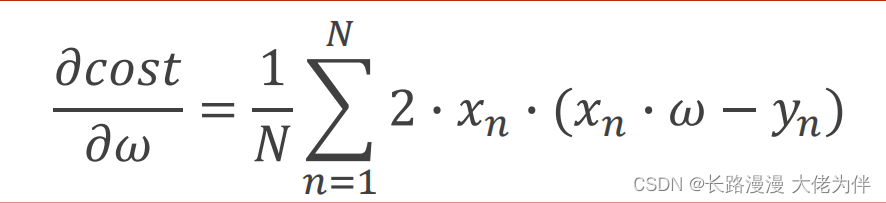
随机推荐
HQL语句执行过程
day12函数进阶作业
分布式和集群
entry point injection
学习总结week2_3
[Go through 3] Convolution & Image Noise & Edge & Texture
ES6 生成器
What are the characteristics of the interface of the physical layer?What does each contain?
Lecture 5 Using pytorch to implement linear regression
What field type of MySQL database table has the largest storage length?
redis 持久化
第二讲 Linear Model 线性模型
SQL(二) —— join窗口函数视图
js实现数组去重
【过一下 17】pytorch 改写 keras
[Software Exam System Architect] Software Architecture Design ③ Domain-Specific Software Architecture (DSSA)
redis persistence
Lecture 4 Backpropagation Essays
Difference between for..in and for..of
Machine Learning (2) - Machine Learning Fundamentals