当前位置:网站首页>面试MySQL
面试MySQL
2022-06-22 17:32:00 【LXMXHJ】
综述
MySQL概述
Oracle 和 MySQL 区别
两个都是
| 区别 | MySQL | Oracle |
|---|---|---|
| 公司 | 瑞典MySQL AB公司 又被sun收购 又被Oracle收购 | 甲骨文公司 |
| 类型 | 中小型数据库 | 大型数据库 |
| 费用 | 开源免费 | 收费 |
| 默认端口号 | 3306 | 1521 |
| 数据库与用户关系 | 一个用户对一个多个数据库 | 一个数据库对应多个用户 |
| 字段自增 | 设置字段为auto increment | 创建序列sequence,添加 序列名.nextval() |
| 字符 | varchar | varchar2 |
| 数字类型 | smallint(2字节) int(4字节) integer(int同义词) bigint(8字节) | number |
| 分页 | select * from table limit(start-1)*limit,limit start 页码,limit是每页显示的条数 | 使用伪列rownum |
对MySQL框架的了解?
MySQl可以分为 Server层 和 存储引擎 两部分。
- Server层:
涵盖MySQL的大多数核心功能,以及所有的内置函数,所有跨引擎的功能都在这一层实现; - 存储引擎:
数据的存储和提取。
构件是插件式的。存储引擎有InnorDB、MyISAM、memory;
MySQL5.5.5 默认是InnorDB,可以通过engine = MyISAM来指定存储引擎;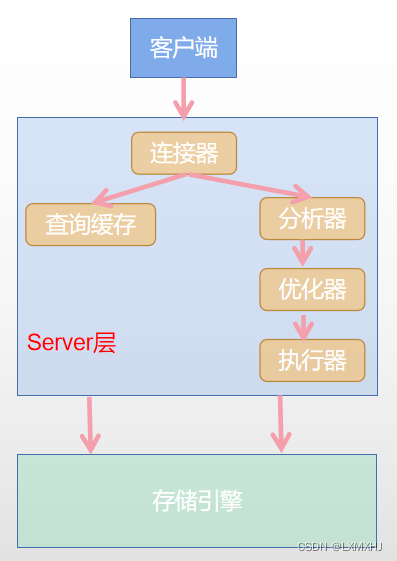
Server层组成部分介绍:
| 成员 | 作用 |
|---|---|
| 连接器 | 管理连接,权限验证 |
| 查询缓存 | 命中则直接返回结果 |
| 分析器 | 词法分析、语法分析 |
| 优化器 | 执行计划生成,索引选择 |
| 执行器 | 操作引擎,返回结果 |
一条SQL语句在数据库框架中的执行流程?
执行过程:
- 应用程序把查询SQL语句发送给服务器端执行;
- 检查缓存中是否存在该查询。存在,返回缓存中的结果;否则,执行下一步;
- 进行SQL的解析、语法检测和预处理,再由优化器生成对应的执行计划;
- MySQL根据执行计划,调用存储引擎的接口进行查询;
- 最终将查询结果返回给客户端。
数据库的三范式是什么?
| 名字 | 含义 | 解释 |
|---|---|---|
| 第一范式(1NF) | 所有域都应该是原子性的 每个列都是不可拆分的 数据库表的每一列都是不可分割的原子数据项,而不是集合、数组、记录等非原子数据项 | 实体的某个属性有多个值时,必须拆分为不同的属性 |
| 第二范式(2NF) | 非主键列完全依赖于主键列,不依赖于其他非主键 | 要求数据库表中的每个实例或记录必须可以被唯一地区分 |
| 第三范式(3NF) | 任何非主属性不依赖于其他非主属性 | 要求一个关系中不包含其它关系已包含的非主键字信息 举例:部门信息表中,主键=部门编号,其余信息有部门名称、部门简介等;员工信息表中列出部门编号后,不再列出部门名称、部门间接等信息 |
专业术语 或 关键词
DB:Database 数据库
DBMS:Database Management System 数据库管理系统
RDBMS:Relative Database Management System 关系型数据库管理系统
数据库:是表的集合,带有相关的数据;
表:一个表是一个数据的矩阵;
列(字段):一个列(数据元素)包含同一类型的数据;
行(记录):一组相关的数据;
数据库 基本操作
查看、创建、修改、删除数据库。
对水平切分和垂直切分的理解?
- 数据库拆分原则:
通过某种特定的条件,按照某个维度,将同一个数据库中的数据分散存放到多个数据库(主机),以达到分散单库(主机)负载的效果; - 拆分模式:
垂直(纵向)拆分、水平拆分。
垂直拆分:专库专用
| 介绍 | 说明 |
|---|---|
| 概念 | 按照业务将表分类,分布到不同的数据库上 |
| 可解决问题 | 降低单节点数据库的负载 |
| 不能解决问题 | 缩表,即每个数据库里面的数据量是没有发生变化的 |
| 优点 | 拆分后业务清晰,拆分规则明确 系统之间整合或者扩展容易 数据维护简单 |
| 缺点 | 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。 事务处理复杂 |
水平拆分 :分库分表
- 概念:
把同一个表拆到不同的数据库中;
不是将表做分类,而是按照某个字段的某种规则来分散到多个库中,每个表中包含一部分数据;
简单理解 = 按照数据行的切分,将某些行又切分到其他的数据库中; - 误解:
水平切分出来的数据表必须保存在不同的MySQL节点上;
其实水平切分出来的数据表也可以保存在一个MySQL节点上; - 为什么说水平切分不一定需要多个MySQL节点呢?
MySQL自带一种数据分区的技术,可以把一张表的数据,按照特殊规则,切分存储在不同的目录下。
若给Linux主机挂载了多块硬盘,可以利用MySQL分区技术,把一张表的数据切分存储在多个硬盘上。
这样就由原来一块硬盘有限的IO能力,升级成了多个磁盘增强型的IO。
数据类型
数值类型、字符串类型、转义字符、日期/时间、二进制类型、变量。
char 和 varchar 的区别?
| 区别 | char | varchar |
|---|---|---|
| 长度 | 固定 char(10) 字符串"abc" 存储10个字节,其中7个是空格 | 可变 varchar(10) 字符串"abc" 只占三个字节 |
| 效率 | 较高 | 较低 |
| 节省空间 | – | 比char节省空间 |
| 存储类型 | – | varchar是oracle开发的数据类型 工业标准可以存储空字符串;oracle还可以存储NULL值 |
varchar(10) 和 varchar(20) 的区别?
varchar(10)最多放10个字符,因此varchar(10)和varchar(20)存储10个及10个以内的字符所占空间一样;
但后者在排序时会消耗更多内存,因为order by col 采用fixed_length计算col长度。
fixed_length 固定长度;
数据表 基本操作
创建、查看、修改数据表结构。
操作 表中的数据
查询、增加、修改、删除、清空表记录。
查询性能的优化方法?
减少请求的数据量
只返回必要的列:尽量避免使用select * 语句;
只返回必要的行:使用limit语句来限制返回的数据;
缓存重复查询的数据;减少服务端扫描的行数
通过索引来覆盖查询;
sql调优
- 创建索引:
尽量避免全表扫描,应考虑where 或order by - 避免在索引上使用计算
在where语句中,如果索引列是计算或者函数的一部分,DBMS的优化器将不会使用索引而使用全表查询 - 使用预编译查询
程序中通常是根据用户的输入来动态执行SQL,这时要尽量使用参数化SQL,可以避免SQL注入漏洞;
数据库会对参数化SQL进行预编译,以后再执行直接使用预编译的结果即可。 - 调整where子句中的连接顺序
DBMS一般采用自上而下的顺序解析where子句; - 尽量将多条sql语句压缩到一句sql中
每次执行sql的时候要经历如下过程:建立网络连接、进行权限校验、进行SQL语句的查询优化、发送执行结果
该过程非常耗时。 - 用where子句替换Having子句
避免使用having,因为having只会在检索出所有记录之后才对结果集进行过滤,而where是在聚合前;
如果可以使用where减少记录的数目,就可以减少开销; - 使用表的别名
sql连接多个表,使用表的别名 可以减少解析的时间 并减少不同表的同名列名的语法歧义 - 用union all 替换union
- 用varchar/nvarchar 替换char / nchar
变长字段存储空间小,可以节省存储空间;
对于查询来说,在一个相对较小的字段内搜索效率高;
视图
创建、查看、修改、删除视图。
索引
创建索引实例、普通索引、唯一索引、主键索引、组合索引、全文索引。
谈谈你对索引的理解?
作用:
索引的出现是为了提高查询效率,相当于数据库的目录;
是对查询性能优化最有效的有段;概念:
在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构;原理:
通过不断缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机事件变成顺序的事件;分类:
hash类型的索引:查询单条快,范围查询慢;
b-tree类型的索引:b+树,层数越多,数据量指数级增长;缺点:
创建索引和维护索引需要耗费时间;
对数据增、删、改时,索引也需要动态维护,降低数据的维护速度;
随着数据量的增大,索引需要占的物理空间也会越大;建立原则:
经常被查询的字段:where子句中出现的;
在分组的字段:即在group by子句中出现的;
存在依赖关系的子表和父表之间的联合查询,即主键或外键字段;
设置唯一完整性约束字段;不适合建立索引:
查询中很少被使用的列 或者 重复值较多的列,不宜建立索引;
一些特殊的数据类型, 不宜建立索引。比如:文本字段(text) 等。
索引的底层使用的是什么数据结构?
索引的数据结构 和 具体存储引擎 的实现有关;
MySQL中使用较多的索引有 Hash索引、B+ 树 索引等;
则对应索引的底层使用的就是 Hash表 、 B + 树;
谈谈你对B+树 的理解?
图示:
| 说明 | 根节点 | 分支节点 除根节点、叶子节点 | 叶子节点 |
|---|---|---|---|
| 儿子数 | 有M个儿子则有m个元素 | 有M个儿子则有m个元素 | – |
| 存储内容 | 关键字(索引)、指针 | 关键字(索引)、指针 | 关键字、数据 |
| 存储 | – | – | 所有根节点、分支节点都存在于子节点中,是最大值或最小值 |
| – | – | 包含所有关键字、指向数据记录的指针 叶子节点本身是根据关键字从小到大顺序链接的 |
作用:
优势1 = 更加高效的单元素查找。
对聚簇索引、稀疏索引 的理解?
- 聚簇索引:
是对磁盘上实际数据重新组织,按照指定的一个或多个列的值 排序的算法。
特点是存储数据的顺序和索引顺序一致。
一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
聚簇索引 和 非聚簇索引(稀疏索引)区别:
聚簇索引:即叶子结点中包含所有完整行记录,叶子节点中包含索引及其他所有字段信息,也就是数据节点;InnoDB 存储引擎中以主键索引构建的 B+tree 即为聚簇索引,
非聚簇索引:其他的皆为稀疏索引;叶子节点仍然是索引节点;
- 稀疏索引:
二级索引、联合索引、MyISAM存储引擎的索引全是稀疏索引。
对哈希索引的理解?
对覆盖索引的理解?
索引的分类?
对最左前缀原则的理解?
怎么知道创建的索引有没有被使用到?或者说怎么才能知道这条语句运行很慢的原因?
什么情况下索引会失效?即查询不走索引?
事务
存储索引
MyISAM、InnoDB、Memory。
为什么InnorDB存储索引采用B+树 而不是 B 树?
InnoDB 和 MyISAM的比较?
约束
主键约束、外键约束、唯一约束、检查约束、非空约束、默认值约束。
20 主从复制中涉及哪三个线程?
边栏推荐
- Sort---
- d的dip1000,1
- "Half of Zhejiang's Venture Capital Circle" must be state-owned assets
- Excuse me, when cdc2.0 reads mysql, there should be no table lock. An error was just reported, access D
- 使用完整功能模仿设计法
- Pytorch——报错解决:“torch/optim/adamw.py” beta1, UnboundLocalError: local variable ‘beta1‘
- 阻碍华为5G手机的关键芯片取得突破,国产芯片已取得一成份额
- Preliminary controller input of oculus learning notes (1)
- Nuxt - create nuxt app
- Babbitt | yuancosmos daily must read: it is said that Tencent has established XR department, and yuancosmos sector has risen again. Many securities companies have issued reports to pay attention to th
猜你喜欢
DBMS in Oracle_ output. put_ Example of line usage

JVM快速入门

如何持续突破性能表现? | DX研发模式

docker: Error response from daemon: Conflict. The container name “/mysql“ is already in use by conta
High voltage direct current (HVDC) model based on converter (MMC) technology and voltage source converter (VSC) (implemented by MATLAB & Simulink)
Set of redis data structure

SystemVerilog (12) - $unit declaration space

2022 Chongqing preschool education industry exhibition 𞓜 hi tech Toy Puzzle decompression Toy Expo

Babbitt | yuancosmos daily must read: it is said that Tencent has established XR department, and yuancosmos sector has risen again. Many securities companies have issued reports to pay attention to th

What happened to this page when sqlserver was saving

随机推荐
Modèle de langage de pré - formation, Bert, roformer Sim aussi connu sous le nom de simbertv2
At 19:30 today, the science popularization leader said that he would take you to explore how AI can stimulate human creativity
JVM快速入门
High voltage direct current (HVDC) model based on converter (MMC) technology and voltage source converter (VSC) (implemented by MATLAB & Simulink)
What is the experience of writing a best seller
Grafana 9 is officially released, which is easier to use and more cool!
wpa_cli参数说明
wpa_supplicant的状态机迁移
排序---
每天5分钟玩转Kubernetes | Dashboard典型使用场景
问下 cdc 2.2.1监控sqlServer是不支持监控多库的吗?
中国移动手机用户缓慢增长,但努力争取高利润的5G套餐用户
腾讯云国际版云服务器欠费说明
Golang implements redis (10): local atomic transactions
centerOS 安装mangodb
静态链表(一)
docker: Error response from daemon: Conflict. The container name “/mysql“ is already in use by conta
炒股开户选择哪个券商公司是最安全最好呢
Concepts and solutions of redis' cache penetration, cache avalanche and cache breakdown problems
Array implementation of circular linked list