当前位置:网站首页>Digital intelligence learning Lake Warehouse Integration Practice and exploration
Digital intelligence learning Lake Warehouse Integration Practice and exploration
2022-06-28 02:37:00 【Digital technology dtwave】
Column words
Shulan technology opens a column 「 Technical school +」, Focus on cutting edge technology , Insight into the wind direction of the industry , Share R & D experience and application practice from the front line .
This column was brought by Bai Song, deputy general manager of Shulan technology R & D center , Share the practice and exploration of Lake warehouse integration .
Introduction
With the accelerating process of social digitalization , Data scale 、 Data types continue to grow rapidly . To meet the demands of more complex business data analysis , Big data infrastructure technology from the database 、 Data warehouse 、 Data Lake 、 And then to the integration of lake and warehouse .
And with many fields 、 The successful landing of the scene , The technical concept of Lake warehouse integration has officially entered the mainstream vision ,AWS、 Ali 、 Huawei 、 Google 、 Tencent and other big companies have launched data Lake service products based on cloud technology . In internationally renowned institutions Gartner released 《Hype Cycle for Data Management 2021》 in , The lake and the warehouse are integrated (Lake house) Included in the technology maturity curve for the first time .
Lake Warehouse Integration essentially breaks the barrier between data warehouse and data lake , Make the fragmented data fusion unified , Reduce relocation in data analysis , Realize unified data management , Conducive to excavation 、 Bring more data value .
Before we begin to explain the integration of lake and warehouse , Let's first understand the data lake and data warehouse .
One 、 Data lake and data warehouse
Refer to the definition of Wikipedia , Data Lake It is a large warehouse for storing all kinds of raw data of enterprises , The data is accessible 、 Handle 、 Analysis and transmission . A data lake is a system or repository that stores data in its natural format , It is usually an object or a file . Data lake is usually a single storage of all data in an enterprise , Include original copies of source system data , And for reporting 、 visualization 、 Analysis and machine learning tasks such as conversion data . Data lakes can include structured data from relational databases , Semi-structured data (CSV、 journal 、XML、JSON), Unstructured data ( E-mail 、 file 、PDF) And binary data ( Images 、 Audio 、 video ).
and Data warehouse It's a theme oriented 、 Integrated 、 Relatively stable 、 Data storage system reflecting historical changes , It aggregates structured data from different sources , It is used for comparison and analysis in the field of business intelligence , A data warehouse is a repository that contains a variety of data , And it is highly modeled .
The differences between data lake and data warehouse are as follows :
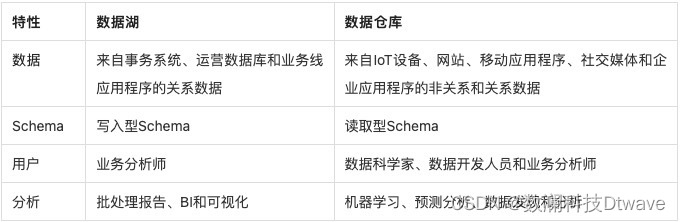
In terms of data storage , The data lake can store structured data 、 Semi structured 、 All unstructured data , Data warehouse can only deal with structured data . Data warehouse should sort out data before processing data 、 Defining data Schema The stock in operation can only be performed after , The data Lake synchronizes the original data as it is , This is machine learning for subsequent data lake 、 Data mining brings infinite possibilities .
Due to the requirements of model paradigm, the business of data warehouse can not change randomly , But for the data Lake , Even if the Internet industry continues to have new applications , The business is constantly changing , The data model is constantly changing , But data can still easily enter the data lake , For data collection 、 cleaning 、 Standardized treatment , It can be completely postponed to the time of business needs . So the data lake is relative to the enterprise , More flexible , It can adapt to the changes of front-end business more quickly .
From the specific application of both , A data warehouse stores structured data , Suitable for fast BI And decision support , and The data lake can store data in any format , Often through mining can play a greater role in data .
Although the application scenarios and architectures of data warehouse and data lake are different , But they are not opposites , In some scenarios, the coexistence of the two can bring more benefits to the enterprise , Therefore, the solution of Lake Warehouse Integration .
Two 、 Lake warehouse integration definition
Intuitive to see , Lake warehouse integration is The enterprise oriented data warehouse technology , Combined with low-cost data Lake storage technology , Provide a unified for enterprises 、 Shareable data base , Avoid traditional data lakes 、 Data movement between data warehouses , Put the raw data 、 Processing and cleaning data 、 Modeling data , Common storage in an integrated system “ Lake warehouse ” in , It can realize high concurrency for business 、 Precision 、 High performance historical data 、 Real time data query service , It can also carry analysis reports 、 The batch 、 Data mining and other analytical businesses .
At present, it is generally accepted in the industry : The integration of lake and warehouse needs to get through the two systems of data warehouse and data lake , Let data and computation flow freely between the lake and the barn , So as to build a complete and organic big data technology ecosystem .
The emergence of Lake Warehouse Integration Scheme , Help enterprises build a new 、 Integrated data platform . Through machine learning and AI Algorithm support , Realize data Lake + The closed loop of data warehouse , Improve business efficiency . The capabilities of data lake and data warehouse are fully combined , Form complementarities , At the same time, it connects with the diversified computing ecology of the upper layer .
at present , The three main open source data Lake schemes in the market are : Delta、Apache Iceberg and Apache hudi.
Delta yes Apache Spark Behind the scenes, commercial companies Databricks To launch the , Domestic Internet companies use less ;Apache Hudi It is a kind of for analytical business 、 Scan optimized data storage abstraction , It enables DFS Data sets support changes within minutes of delay , It also supports the incremental processing of the data set by the downstream system ;Apache Iceberg It is an open table format for large-scale data analysis scenarios , At present, the community's attention can't compare with Delta, It doesn't work as well Hudi Enrich , But it has a highly abstract and very elegant design .
Digital habitat platform, the core product of digital LAN technology, is based on Iceberg and Hudi Building a data Lake , The following describes the practical experience of Shulan technology in the integration of Lake warehouse , It mainly includes technical architecture 、 Data into the lake 、 Data warehouse construction .
3、 ... and 、 Practice of Lake warehouse integration
In the hucang integrated solution provided by Solana Technology , Data is uniformly stored in Iceberg+HDFS On , And use Flink、Spark、Trino Three different engines access the data in the lake to provide different types of services .
be based on Flink+Iceberg To build a quasi real-time data warehouse integrating Lake warehouse , Original T+1 The offline data warehouse is made into a quasi real-time data warehouse , Improve the timeliness of data warehouse as a whole , To better support upstream and downstream businesses . In the data warehouse processing layer , It can be used Trino Make some simple queries , and Iceberg Also support Streaming read, So in the middle layer of the system, you can also directly access Flink, use Flink Do some batch or streaming tasks , The intermediate results are further calculated and then output to the downstream .
In a specific example , hold Mysql Medium demo_users The table data passes through Flink CDC Real time Lake entry , Fall into the data warehouse ODS In the table of layers , Then based on ODS Layer and a real-time stream flink_demo_complaint_data Conduct Join Operation generation DWD Table of layers .

Sample code :
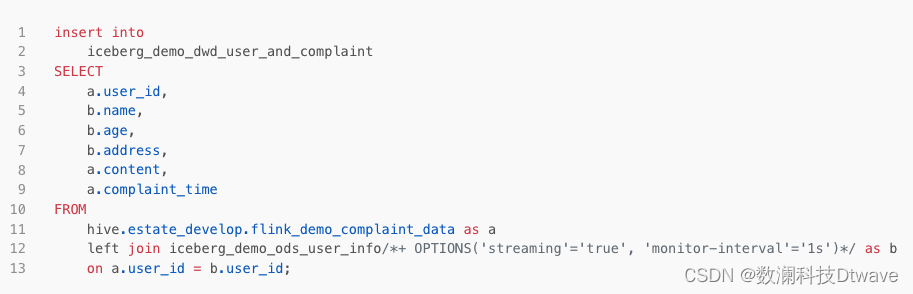
CDC The data entered the lake successfully Iceberg after , We'll also get through the common computing engines , for example Presto(Trino)、Spark、Hive etc. , They can read it in real time Iceberg The latest data in the table .

The figure below is based on Trino Quasi-real-time query Iceberg Table data , Provide customized services to business parties SQL Type of API.

meanwhile , Aiming at the common pain points in the lake warehouse solution in the current market : Lack of data cache layer , Resulting in slower data access ; Lack of a unified programming model , For example, for batches and streams, write Spark and Flink There are two types of SQL. Shulan technology is introduced into Shuqi platform Alluxio and Beam Solve such problems .

be based on Alluxio Data caching
In the current architecture , Computing engine layer passes Iceberg or Hudi Provided API To operate the underlying file storage system , This results in slow data reading and writing . therefore , Consider introducing Alluxio As a data orchestration layer . Speed up the reading and writing of data lake , When Spark、Flink or Trino When asked about file systems ,Alluxio Act as a virtual distributed storage system to accelerate data , And coexist with each computing cluster .
be based on Beam The unified programming model
Apache Beam It's an open source unified programming model , Unified flow and batch , Abstract a unified API Interface . And the generated distributed data processing task should be able to execute in each distributed engine ( for example Spark、Flink) On the implementation , Users can freely switch the execution engine and execution environment of distributed data processing tasks . Therefore, it is planned to introduce Beam As a unified programming model , In the data, the platform product layer provides a unified IDE.

The official website of Shulan technology _ Let the data work
边栏推荐
- Ionic4 realizes half star scoring
- High reliability application knowledge map of Architecture -- the path of architecture evolution
- 架构高可靠性应用知识图谱 ----- 架构演进之路
- js实现时钟
- KVM相关
- 文件傳輸協議--FTP
- Embedded must learn! Detailed explanation of hardware resource interface - based on arm am335x development board (Part 2)
- [JS reverse hundreds of examples] I love to solve 2022 Spring Festival problems and receive red envelopes
- 数智学习 | 流批一体实时数仓建设路径探索
- 一种低成本增长私域流量,且维护简单的方法
猜你喜欢

SQL injection bypass (3)

文件傳輸協議--FTP

Domain Name System

To understand what is synchronous, asynchronous, serial, parallel, concurrent, process, thread, and coroutine

【历史上的今天】6 月 6 日:世界 IPv6 启动纪念日;《俄罗斯方块》发布;小红书成立
文件传输协议--FTP

《低代码解决方案》——覆盖工单、维修和财务全流程的数字化售后服务低代码解决方案

【历史上的今天】6 月 19 日:iPhone 3GS 上市;帕斯卡诞生;《反恐精英》开始测试

系统管理员设置了系统策略,禁止进行此安装。解决方案
SQL 注入绕过(二)
随机推荐
[JS reverse hundreds of examples] I love to solve 2022 Spring Festival problems and receive red envelopes
MySQL优化小技巧
yarn下载报错There appears to be trouble with your network connection. Retrying.
Redis~geospatial (geospatial), hyperloglog (cardinality Statistics)
General timer and interrupt of stm32
SQL 注入绕过(二)
【历史上的今天】6 月 11 日:蒙特卡罗方法的共同发明者出生;谷歌推出 Google 地球;谷歌收购 Waze
我今天忘带手机了
Jenkins - 内置变量访问
Jenkins - accédez à la variable de paramètre personnalisée Jenkins, en traitant les espaces dans la valeur de la variable
Mysql数据库基础:DML数据操作语言
Jenkins - data sharing and transfer between copy artifact plug-in builds
Mysql大合集,你要内容的这里全都有
Machine learning (x) reinforcement learning
Skills in schematic merging
贪吃蛇 C语言
STM32F1与STM32CubeIDE编程实例-金属触摸传感器驱动
OS module and os Learning of path module
SQL injection bypass (3)
数智学习|湖仓一体实践与探索