当前位置:网站首页>Exploration on the construction path of real-time digital warehouse integrating digital intelligence learning and streaming batch
Exploration on the construction path of real-time digital warehouse integrating digital intelligence learning and streaming batch
2022-06-28 02:37:00 【Digital technology dtwave】
Column words
Shulan technology opens a new column 「 Technical school +」, Focus on cutting edge technology , Insight into the wind direction of the industry , Share R & D experience and application practice from the front line .
This column is brought by liumu, a R & D expert of Shulan technology , Explore the construction path of real-time data warehouse integrating flow and batch .
Introduction
At the beginning of the data warehouse construction process , Enterprise business scenarios are basically based on batch processing , Use mature offline technology to build offline data warehouse , There may also be some real-time processing scenarios in the middle , But most of them will be converted to quasi real-time processing mode , Such as minute scheduling .
With the development of the times , Enterprise business data is growing geometrically , The shortage of traditional offline data warehouse is gradually revealed , The quasi real-time processing method is not enough to meet the business demands , Enterprises begin to build real-time data warehouses .
In the process of real-time warehouse construction , Use the same set of code to realize the flow calculation and batch calculation of big data , So as to ensure the consistency between the processing process and the results “ Stream batch integration ” The technical concept is widely recognized by the industry , And successfully verified in multiple business scenarios , Gradually to the ground .
One 、 Development of flow batch integration technology concept

Look back at , The development of real-time data warehouse technology architecture has mainly experienced Three stages :Lambda framework 、Kappa framework 、 Carrying data Lake Kappa framework .
stay Lambda Architecture , Batch and stream processing are separate , The off-line data acquisition and processing are carried out through periodic scheduling , Intermediate data can also be saved , At the same time, real-time stream processing can quickly provide processed data . Batch processing ensures data accuracy , Stream processing ensures the timeliness of data , The architecture is stable .
But on the other hand ,Lambda The drawbacks of architecture are also obvious , Own batch 、 Stream two different computing engines , Two sets of codes need to be maintained for the same business scenario , It is easy to produce different data results ; Two computing engines , Data development costs 、 Operation and maintenance costs are also relatively high .
In order to solve the above problems , The industry has put forward the technical concept of integrating flow and batch , That is, the computing engine has the low latency of flow computing at the same time 、 High throughput and stability of batch computing , The same set of programming interface is used to realize batch computing and flow computing and ensure the consistency of underlying execution logic , So as to ensure the consistency of the processing process and results .
The integration of flow and batch is mainly reflected in the following four aspects :
Unified metadata : Offline and real-time metadata are stored uniformly .
Unified data storage : That is, the data of offline calculation and real-time calculation are uniformly stored , Avoid data inconsistencies 、 Problems such as repeated storage and repeated calculation .
Unified computing engine : That is, offline computing and real-time computing adopt a unified computing engine , And use the same set of logic or code to cover the two scenarios .
Unified semantics : That is, the unification of semantic development layer , Think about design from the user's point of view , Make the data development process convenient 、 Low threshold 、 high efficiency . Simple understanding can be divided into three categories : Unified development, such as the use of unified SQL or SDK、 Develop based on business model or logical model, such as low code or no code 、 Unified feature development process, such as in flow computing or batch computing AI engineering .
Two 、 Real time data warehouse architecture based on stream batch integration
After the concept of flow batch integration technology was put forward ,Kappa Architecture has come into the mainstream .Kappa The architecture integrates streams and batches , Data caching through message queuing , The result data is stored in KV database (Hbase/ES) or OLAP In the database , For the business party to access and analyze in real time . Data R & D only needs to write a set of processing logic , Ensure the consistency of data , At the same time, the resource consumption and maintenance cost are relatively reduced .

But the architecture also has flaws , The data in the message queue cannot be ad hoc analyzed , And the performance of the message queue itself 、 Storage requirements are very high , The full link depends on message queuing , It is easy to cause incorrect data results caused by data timing , Besides , Message queue backtracking ability is not as good as offline storage .
With the data lake and Flink And other related big data technologies , be based on Flink+ Data lake Kappa framework It has become the mainstream architecture of real-time data warehouse integrating flow and batch .

adopt Flink CDC Technology writes full and incremental raw data to ODS Layer , Use data lake for unified storage , Follow up only through Flink Calculation engine 、 Write a set of code to calculate the data in the data lake , The entire data processing link can be completed , Ensure the consistency of data , Reduced operation and maintenance costs ; meanwhile , Some data Lake technologies are as follows Iceberg It can also be directly connected Presto/Trino Calculation engine , Scenarios that can quickly support ad hoc analysis of real-time data .
3、 ... and 、 A platform for counting —— Stream batch integrated real-time computing platform
Datacenter of digital LAN technology builds a suite of digital habitat platforms , Provide a one-stop flow batch integrated computing platform , Through cluster management 、 Metadata management 、 Data development 、 Operation and maintenance release 、 Visual monitoring alarm and other core function modules , Help enterprises quickly build a real-time data warehouse platform .
at present , The digital habitat platform adopts Flink+Iceberg Technical solution , The metadata of the table is uniformly stored in HiveMeta in , Data files are uniformly stored in HDFS On , Through full hosting, users do not need to care about the architecture principle of the underlying storage computing cluster , Just focus on your own business logic .
The core functions of the digital habitat platform :
- Plug in design , It is suitable for different big data computing clusters from various manufacturers .
- Support rich node libraries , Can quickly expand support for new data sources .
- Provide Wizard mode to create real-time ETL Homework , Full data and incremental data are synchronized and seamlessly connected , It also supports multiple primary key conflict modes at the data writing end .
- Built in a variety of DDL Templates , Reduce development workload 、 Avoid manual input of wrong meter structure , Focus on the task development process .
- Support online SQL Develop built-in SQL format 、 Semantic check 、 Code highlighting, etc , Shielding the underlying native code framework , Lower the development threshold .
- Integrate Flink Web UI, Online real-time monitoring of task operation status and rapid and accurate positioning of abnormal .
- Support visual drag and drop development configuration jobs , The operation process and dependencies are clear .
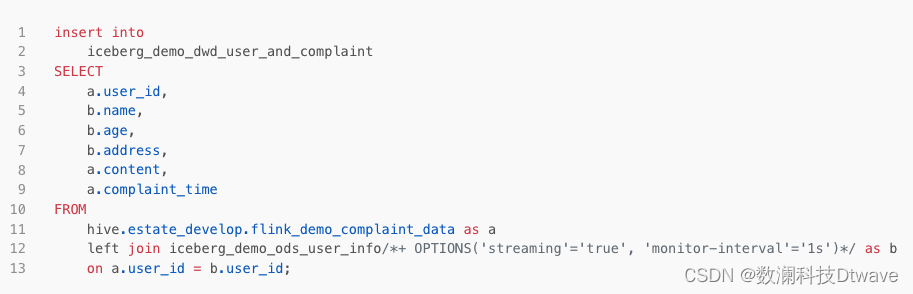
Build a real-time data warehouse based on the data habitat platform , First, collect the data from various data sources through the real-time synchronization task Iceberg in , And then create... On the real-time development platform Flink SQL or Flink Job to calculate and process data , Calculation results can be written Hbase/ES/Mysql etc. , Finally, create a data service API For business application calls .


The official website of Shulan technology _ Let the data work
边栏推荐
- Protocole de transfert de fichiers - - FTP
- File transfer protocol --ftp
- 低代码DSL里面在数仓中的实践
- The system administrator has set the system policy to prohibit this installation. Solution
- Jenkins - accédez à la variable de paramètre personnalisée Jenkins, en traitant les espaces dans la valeur de la variable
- Architecture high reliability application knowledge map ----- microservice architecture map
- JS array random value (random array value)
- 王心凌、谭维维 - 山海(副歌加长版) 在线试听无损FLAC下载
- Skills in schematic merging
- 匿名挂载&具名挂载
猜你喜欢







随机推荐
Fundamentals of scala (3): operators and process control
【历史上的今天】5 月 31 日:Amiga 之父诞生;BASIC 语言的共同开发者出生;黑莓 BBM 停运
文件传输协议--FTP
STM32F1与STM32CubeIDE编程实例-金属触摸传感器驱动
Keil "St link USB communication error" solution
Flutter 使用 CustomPaint 绘制基本图形
Locust performance test - parameterization, no repetition of concurrent cyclic data sampling
【历史上的今天】6 月 2 日:苹果推出了 Swift 编程语言;电信收购联通 C 网;OS X Yosemite 发布
Ti am3352/54/59 industrial core board hardware specification
There appears to be a failure with your network connection Retrying.
我今天忘带手机了
How technicians become experts in technical field
【历史上的今天】6 月 12 日:美国进入数字化电视时代;Mozilla 的最初开发者出生;3Com 和美国机器人公司合并
Teach you how to realize pynq-z2 bar code recognition
Jenkins - 内置变量访问
数智学习 | 流批一体实时数仓建设路径探索
Jenkins - Pipeline concept and creation method
Scoped attribute and lang attribute in style
SQL 注入绕过(三)
「大道智创」获千万级preA+轮融资,推出科技消费机器人