当前位置:网站首页>Spark history server performance improvement (I) -- Application List
Spark history server performance improvement (I) -- Application List
2022-06-25 11:21:00 【pyiran】
Spark History Server The home page of
Spark History Server(SHS) The homepage shows a certain period of time (spark.history.fs.cleaner.maxAge, default 7d) All of application list , Contains applicationId, name, attemptId, start time, end time, duration, user, eventlog Download link .

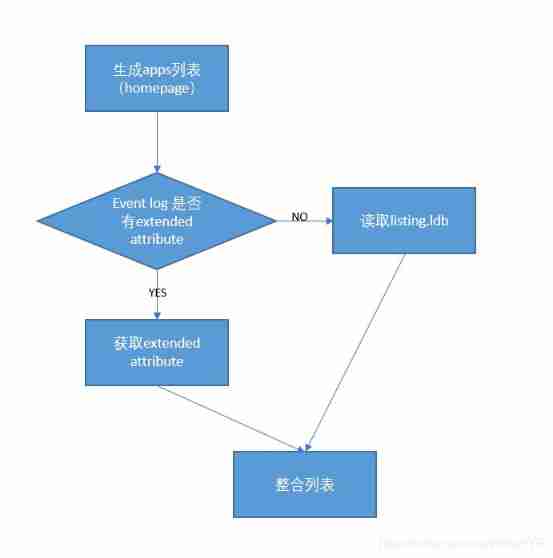
SHS How to generate app list
SHS Is based on event log To generate application list, This can not avoid the need to SHS To read and parse log. From the code we can see , Need analysis :SparkListenerApplicationStart,SparkListenerApplicationEnd,SparkListenerEnvironmentUpdate,sparkVersion.
When application still running Under the circumstances ,SHS There is no need to read SparkListenerApplicationEnd You can get the required list information , So you only need to parse a small number of event log The content can be completed .
But for the ending application, You need to read end event To get the end time , And we cannot guarantee event log The last piece of data is end event, So in the earliest days SHS It is necessary to traverse all event To generate list information . The generated list information will be cached in levelDB in , Corresponding to listing.ldb.
private[history] class AppListingListener(
reader: EventLogFileReader,
clock: Clock,
haltEnabled: Boolean) extends SparkListener {
private val app = new MutableApplicationInfo()
private val attempt = new MutableAttemptInfo(reader.rootPath.getName(),
reader.fileSizeForLastIndex, reader.lastIndex)
private var gotEnvUpdate = false
private var halted = false
override def onApplicationStart(event: SparkListenerApplicationStart): Unit = {
app.id = event.appId.orNull
app.name = event.appName
attempt.attemptId = event.appAttemptId
attempt.startTime = new Date(event.time)
attempt.lastUpdated = new Date(clock.getTimeMillis())
attempt.sparkUser = event.sparkUser
checkProgress()
}
override def onApplicationEnd(event: SparkListenerApplicationEnd): Unit = {
attempt.endTime = new Date(event.time)
attempt.lastUpdated = new Date(reader.modificationTime)
attempt.duration = event.time - attempt.startTime.getTime()
attempt.completed = true
}
override def onEnvironmentUpdate(event: SparkListenerEnvironmentUpdate): Unit = {
// Only parse the first env update, since any future changes don't have any effect on
// the ACLs set for the UI.
if (!gotEnvUpdate) {
def emptyStringToNone(strOption: Option[String]): Option[String] = strOption match {
case Some("") => None
case _ => strOption
}
val allProperties = event.environmentDetails("Spark Properties").toMap
attempt.viewAcls = emptyStringToNone(allProperties.get(UI_VIEW_ACLS.key))
attempt.adminAcls = emptyStringToNone(allProperties.get(ADMIN_ACLS.key))
attempt.viewAclsGroups = emptyStringToNone(allProperties.get(UI_VIEW_ACLS_GROUPS.key))
attempt.adminAclsGroups = emptyStringToNone(allProperties.get(ADMIN_ACLS_GROUPS.key))
gotEnvUpdate = true
checkProgress()
}
}
override def onOtherEvent(event: SparkListenerEvent): Unit = event match {
case SparkListenerLogStart(sparkVersion) =>
attempt.appSparkVersion = sparkVersion
case _ =>
}
def applicationInfo: Option[ApplicationInfoWrapper] = {
if (app.id != null) {
Some(app.toView())
} else {
None
}
}
And for a lot of long running Of job Come on , for example streaming job, event log It will be very big in the end , In order to read a small amount of list information, you need to traverse all event log It is obviously inefficient , therefore SHS The function of fast parsing is introduced . We said earlier ,end event Not necessarily the last line , But it must be event log The end part of appears , So by opening “spark.history.fs.inProgressOptimization.enabled” And set up “spark.history.fs.endEventReparseChunkSize”, We can enable the quick parsing function . The principle of this function is , When application At the end , In order to obtain end evnet, We will start from the last “endEventReparseChunkSize” Size starts looking end event.
val lookForEndEvent = shouldHalt && (appCompleted || !fastInProgressParsing)
if (lookForEndEvent && listener.applicationInfo.isDefined) {
val lastFile = logFiles.last
Utils.tryWithResource(EventLogFileReader.openEventLog(lastFile.getPath, fs)) { in =>
val target = lastFile.getLen - reparseChunkSize
if (target > 0) {
logInfo(s"Looking for end event; skipping $target bytes from $logPath...")
var skipped = 0L
while (skipped < target) {
skipped += in.skip(target - skipped)
}
}
val source = Source.fromInputStream(in).getLines()
// Because skipping may leave the stream in the middle of a line, read the next line
// before replaying.
if (target > 0) {
source.next()
}
bus.replay(source, lastFile.getPath.toString, !appCompleted, eventsFilter)
}
}
logInfo(s"Finished parsing $logPath")
SHS Improve performance
To further improve the generation application list The speed of , Take advantage of HDFS Of extend attribute function .
SPARK-23607
Spark Driver
Driver Part of what needs to be done , Just writing event log At the same time , For the sake of log File creation extended attribute. for example “user.startTime”. This part is in EventLoggingListener.scala You can simply add .
SHS
SHS What needs to be done , Is generating list When , Go get it event log Of extended attributes, these attributes Is stored in the namenode In memory , So the reading speed is very fast . The main changes focus on FsHistoryProvider.scala in .
边栏推荐
- Arrays.asList()
- SQL注入漏洞(绕过篇)
- Hangzhou / Beijing neitui Ali Dharma academy recruits academic interns in visual generation (talent plan)
- 子类A继承父类B, A a = new A(); 则父类B构造函数、父类B静态代码块、父类B非静态代码块、子类A构造函数、子类A静态代码块、子类A非静态代码块 执行的先后顺序是?
- Kingbasees plug-in DBMS of Jincang database_ OUTPUT
- Jincang database kingbasees plug-in force_ view
- [observation] objectscale: redefining the next generation of object storage, reconstruction and innovation of Dell Technology
- Multiple environment variables
- Some assembly instructions specific to arm64
- wait()、notify()和notifyAll()、sleep()、Condition、await()、signal()
猜你喜欢
![[file containing vulnerability-03] six ways to exploit file containing vulnerabilities](/img/4f/495c852eb0e634c58e576d911a2c14.png)
[file containing vulnerability-03] six ways to exploit file containing vulnerabilities

中国信通院沈滢:字体开源协议——OFL V1.1介绍及合规要点分析

SQL injection vulnerability (bypass)

视频会议一体机的技术实践和发展趋势

Getting started with Apache Shenyu

牛客网:主持人调度

Software testing to avoid being dismissed during the probation period

Advanced single chip microcomputer -- development of PCB (2)

仿真与烧录程序有哪几种方式?(包含常用工具与使用方式)

今天16:00 | 中科院计算所研究员孙晓明老师带大家走进量子的世界
随机推荐
Use of comparable (for arrays.sort)
Handler、Message、Looper、MessageQueue
Query method and interrupt method to realize USART communication
杭州/北京内推 | 阿里达摩院招聘视觉生成方向学术实习生(人才计划)
Compilation of learning from Wang Shuang (1)
Hangzhou / Beijing neitui Ali Dharma academy recruits academic interns in visual generation (talent plan)
C disk uses 100% cleaning method
Android: generic mapping analysis of gson and JSON in kotlin
Wait (), notify (), notifyAll (), sleep (), condition, await (), signal()
芯片的发展史和具体用途以及结构是什么样的
COSCon'22 讲师征集令
Démarrer avec Apache shenyu
如何实现移动端富文本编辑器功能
过拟合原因及解决
金仓数据库 KingbaseES 插件dbms_session
Jincang database kingbasees plug-in identity_ pwdexp
Arrays. asList()
Double buffer transparent encryption and decryption driven course paper + project source code based on minifilter framework
Shen Lu, China Communications Institute: police open source Protocol - ofl v1.1 Introduction and Compliance Analysis
Double tampon transparent cryptage et décryptage basé sur le cadre minifilter