当前位置:网站首页>Feature extraction tool transformer Bert
Feature extraction tool transformer Bert
2022-07-24 19:15:00 【Coding~Man】
How to quickly learn a language model :
word2vec: Use the headword to predict the context or use the context to predict the headword .
GPT: Use the previous word to predict the next word .
bert: Predict this word with its own characteristics .
First step : Figure out how data becomes tag data . That is, what the input and output and labels are .
The second step : Figure out the model structure .
Third parts : What is the loss function , It's usually singmord II. Classification and softmax Many classification .
The word vector : Convert words into vector representations .
A good word vector should have the following characteristics :
1: Satisfy similarity , relevant , such as : The word vectors of two similar words should also be similar .
2: Satisfy additivity . such as : Word vector China + Word vector capital = Word vector Beijing 
How to train word vectors
such as :“ The structure of the network is shown in the figure below ”, How to convert this sentence into a word vector .
Every time 5 Word :“ The structure of the network “, In the middle of the ” Of “ As label , On the left and right ” The Internet structure “ As input . Design a network, such as the following network , Each word is set to 200 The vector of the dimension , Put this 4 Words as input , Extracting features , Take the extracted features one by one softmax classifier , The category is the number of words in the dictionary , That is, you can get a word vector . There's an output , Label is the middle word . Then constantly sweep back the sentence “ The structure of collaterals is like ”. A large number of annotation samples will be produced . Through the context prediction, the middle word is called CBOW. The other is to predict the words on both sides through the words in the middle , be called Skip-gram.
Transformer Model :
multi-head attention: Get the correlation between any two words .
Add up attention The vector sum after is not added attention Add the vectors of , Later norm( Layer normalization ). Then connect a feedforward neural network (feed formard)( Two layer neural network ), Then carry out residual error and normalization .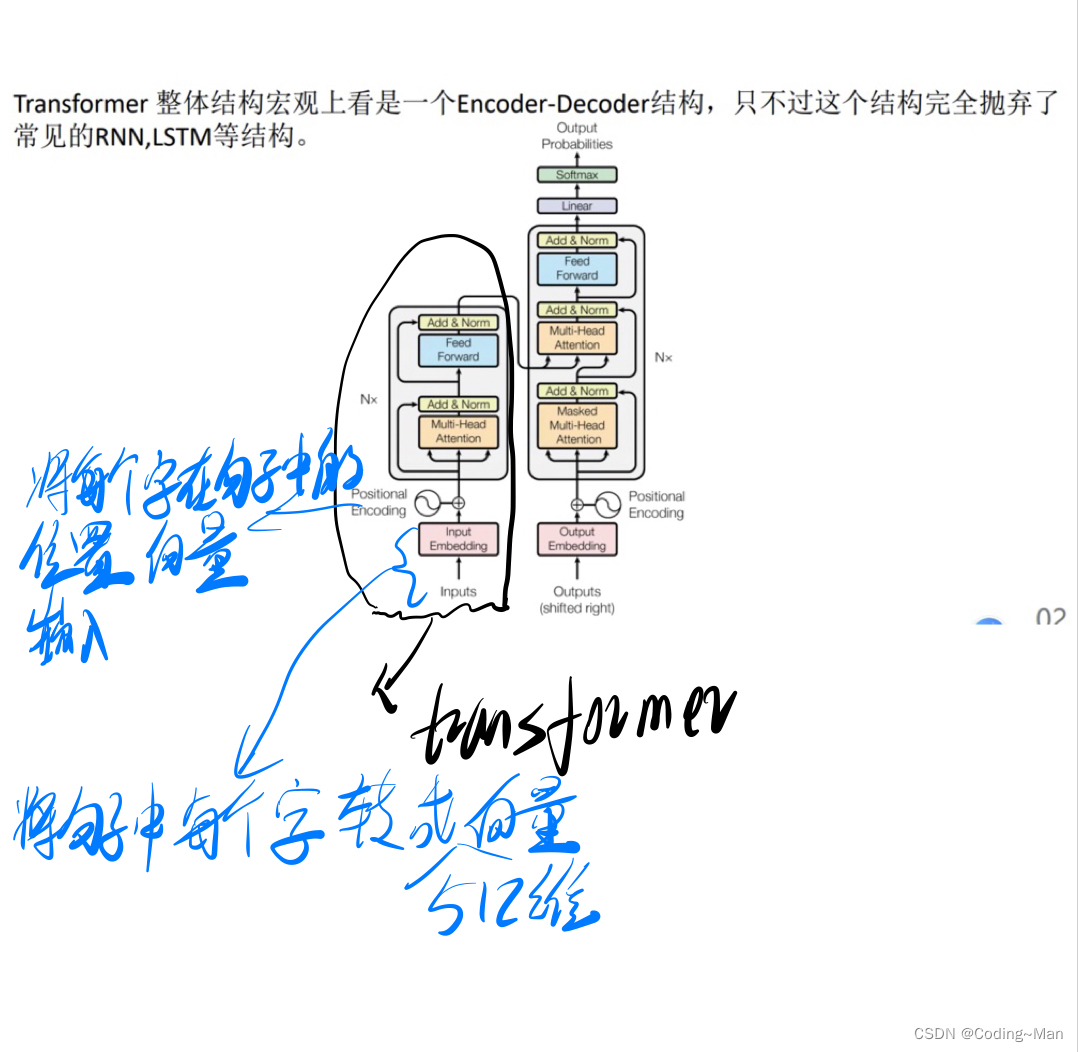
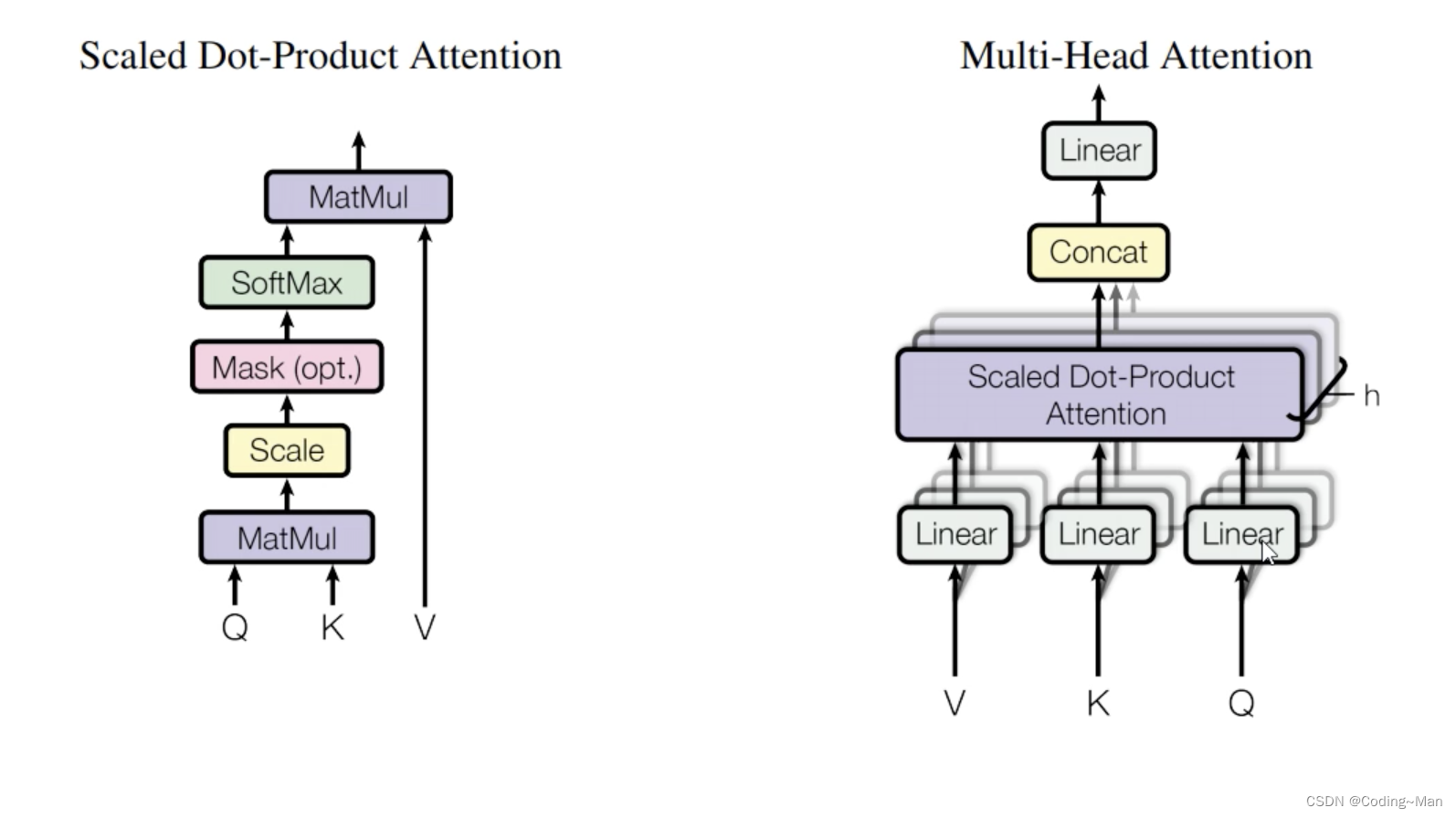
Multi-Head attention:
Linear:WX+B X Namely VKQ.
Will go through Linear Put the data after ,Scaled Dot-Product Attention.
V,K,Q yes 512768 dimension 512 Is the number of words ,768 It is the dimension of every word .h=768/64=12 Share , That is, each word is divided into 12 Share . Turned into 5126412. One is divided into 12 Group , Each group 51264 dimension , Make each group Scaled Dot-Product Attention. take Q and K Do matrix multiplication MatMul (512*512 The matrix of dimensions ), Normalizing ,Scale, It's going on Mask( Put in bitchsize Unequal 1 In time Mask), Put short sentences padding Growing sentences , And then it's going on SoftMax.

Language model :Bert
Architecture diagram :
Tag building :
1: Prediction task , In an article , If two sentences are continuous, the label is 1, It is 0.「SEP」 It's a spacer .
2: Masking language model , Random selection 15% Word usage of 「MASK」 Replace . for example :Input Medium dog By MASK Replace , take Input Put in model ,MASK There will be feature output at the position of ,MASK The label of the location of is dog. That is, use the characteristics of this word to predict itself . Then take this feature and make a classification , The classification label is dog
Put in Bert Model ,bert It's just one. 12 Layer of transformer
After drawing, every word has a feature .
The prediction task of the next sentence : take CLS The features represented are the predicted features of the upper and lower sentences , The label is 0/1, Calculate the loss .
Word prediction task : Take the feature represented by the shielded word as the prediction feature , The label is the word itself , Put this word in softmax In the classifier , The loss can be calculated .
Finally, add up the above two losses , Joint optimization .
边栏推荐
猜你喜欢

Crazy God redis notes 11
![[today in history] July 24: caldera v. Microsoft; Amd announced its acquisition of ATI; Google launches chromecast](/img/7d/7a01c8c6923077d6c201bf1ae02c8c.png)
[today in history] July 24: caldera v. Microsoft; Amd announced its acquisition of ATI; Google launches chromecast

What are the benefits of knowledge management in enterprises?

2022 Hangdian multi school second session 1009 shuangq (Mathematics)

OPENGL学习(三)GLUT二维图像绘制

asp. Net coree file upload and download example

卷积神经网络感受野计算指南

Techempower web framework performance test 21st round results release --asp Net core continue to move forward

深度学习中Dropout原理解析

【JVM学习03】类加载与字节码技术
随机推荐
Unity框架之ConfigManager【Json配置文件读写】
Principle and application of database
Calendar common methods
Convolutional Neural Networks in TensorFlow quizs on Coursera
Interceptors and filters
Typora user manual
Summary of articles in 2020
Chapter 4 compound type
Crazy God redis notes 11
How does PostgreSQL decide PG's backup strategy
SATA protocol OOB essay
Colon sorting code implementation
拦截器和过滤器
Profile environment switching
Meshlab & PCL ISS key points
asp. Net coree file upload and download example
PCIe link initialization & Training
Oneinstack installation and configuration PHP 8.1 and MySQL 8.0-oneinstack site building novice tutorial
BUUCTF-pwn[1]
Clion configuring WSL tool chain