当前位置:网站首页>2021:Zero-shot Visual Question Answering using Knowledge Graphs使用知识图的零次视觉问答
2021:Zero-shot Visual Question Answering using Knowledge Graphs使用知识图的零次视觉问答
2022-06-27 03:05:00 【weixin_42653320】
摘要
现在的方法主要采用不同组件的管道方法来学习知识匹配和提取、特征学习等,但是当某些组件性能不佳时,这种管道方法就会受到影响,从而导致错误的传播和整体性能变差。而且,大多现有方法忽视答案偏见问题--即很多答案在训练期间中未出现过。为弥补这些差距,本文提出一种使用知识图谱和基于掩码的学习机制的零次VQA算法,以更好融入外部知识,并为F-VQA数据集提出新的基于答案的零镜头VQA分割。实验表明,我们的方法在未见的答案的零次VQA中实现最佳性能,同时显著增强了通用VQA任务中现有的端到端模型。
一、介绍
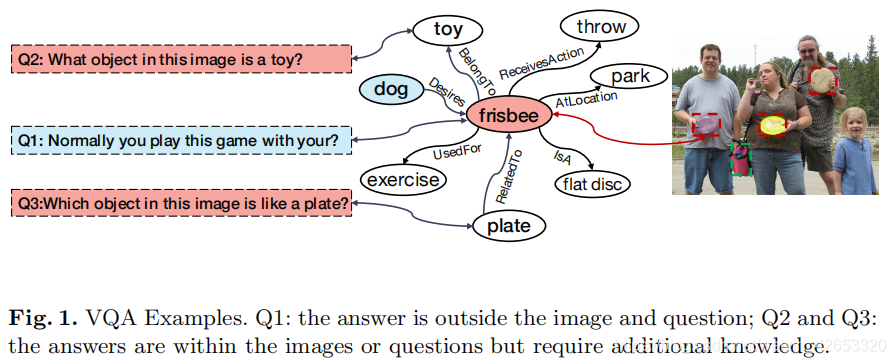
大多数现有的VQA不能解决这种答案不能从图像中直接获得,而是依赖外部知识的开放世界场景理解。如图1,Q1的答案在问题和图像之外,Q2和Q3的答案在图像或问题中但需要额外的知识。
一些为开放视觉场景理解而用外部知识的VQA方法有:Marino et al.[16]广泛利用来自Web的非结构化文本信息作为外部信息,但未能解决文本中的噪声(不相关的信息)。Wang et al.[27]首先从图像中提取视觉概念,然后将它们链接到外部知识图(KG),然后,可以将相应的问题转换为对KG的一系列查询(如SPARQL查询)以检索答案。Zhu等人[31]相反,通过结合视觉概念之间的空间关系和描述性语义关系,以及从KGs中检索到的支持事实,构建一个多模态异构图,然后应用一个模态感知图卷积网络来推断答案。然而,如果管道中的一个模块运行得不好,所有这些方法的性能都会受到巨大的影响。尽管一些端到端模型如[13,2]已经被提出以避免错误级联,但它们仍然是相当初步的,特别是在利用外部知识方面,在许多VQA任务上的性能比管道方法更差。
VQA中另一个重要问题是对有标签的训练数据的依赖,对于新类型的问题或答案,以及图像中新出现的对象,需要收集带标记的元组并从零开始训练模型。针对这一限制,提出Zero-shot VQA(ZS-VQA)旨在预测训练样本中从未出现过的对象、问题或答案。Teney等人解决包含新词的问题,而[22,9]解决包含新对象的图像。然而,这些VQA模型仍然只关注于封闭世界场景理解,没有考虑看不见的答案,且很少充分利用KG。本文利用KG来研究开放世界场景理解的VQA,需要外部知识回答问题,和ZS-VQA,专门解决新答案的子任务。
本文我们提出一种使用KG的ZS-VQA算法和一种基于掩码的学习机制,同时提出了一种新的零次事实VQA(ZS-F-VQA)数据集,即评估ZS-VQA的看不见的答案。首先,分别学习三种不同的特征映射空间,即关系的语义空间、支持实体的对象空间和答案的知识空间,它们都将图像-问题对(I-Q对)与相应目标的联合嵌入对齐。通过所有选择的支持实体和关系的组合,掩码根据映射表决定,映射表包含在一个事实KG中的所有三元组,指导看不见的答案预测的对齐过程。特别是,这些掩码可以作为硬掩码或软掩码使用,这取决于VQA的任务。硬掩码用于ZS-VQA任务;例如,使用ZS-F-VQA数据集,我们的方法实现了最先进的性能,并远优于其他方法(30∼40%)。另一方面,软掩码用于标准的VQA任务;例如,使用F-VQA数据集,我们的方法对基线端到端方法取得了稳定的改进(6∼9%),很好地缓解了管道模型的误差级联问题。
综上所述,主要贡献总结如下:1)提出一个使用KGs的增强ZS-VQA算法,通过掩码来调整答案预测分数,掩码是基于在两个特征空间中的支持实体/关系和融合I-Q对间的排列。2)定义了一个新的ZS-VQA问题,需要外部知识,并考虑看不见的答案,因此开发了一个ZS-F-VQA数据集进行评估。3)我们的基于KG的ZS-VQA算法相当灵活,它可以成功地解决依赖于外部知识的正常VQA任务和ZS-VQA任务,并可以直接增强到现有的端到端的模型。
二、相关工作
2.1 视觉问答
基于知识的VQA:为研究VQA合成外部知识,提出F-VQA,OK-VQA和KVQA数据集,F-VQA中的每个问题都是指相关KG中的一个特定事实的三元组,比如ConceptNet。而OK-VQA是手动标记的,而没有一个有引导的KG作为参考,这导致了其困难。KVQA的目标是问题关于特征间关系的世界知识。我们提出的框架利用端到端和管道方法的优势,我们提高了模型的可转移性,同时有效避免了错误级联,使它对不同任务非常通用,具有鲁棒性,实现了优越的性能。
2.2 零次VQA
零次以解决在不看到训练样本时处理这些新的类。Teney等人[25]首先提出零镜头VQA(ZS-VQA),并在语言语义方面引入新概念,如果问题或答案中至少有一个新单词,测试样本被视为是看不见的。Ramakrishnan等人[22]通过非结构化外部数据(从视觉和语义层面)预训练将先验知识整合到模型中。Farazi等人[9]将ZS-VQA重新表述为一个转移学习任务,它应用近距离观察的实例(I-Q对)来推理看不见的概念。这些方法的一个主要局限性是,它们很少考虑关于答案本身的不平衡和低资源问题。开放答案VQA要求模型从固定的可能的K个答案类别中选择激活程度最高的答案,但模型不能解决看不见的答案,因为答案是孤立的,没有特定的意义。此外,VQA被定义为一个分类问题,而没有利用足够的语义信息的答案。本文提出的ZS-VQA方法通过使用KGs,结合了更丰富、更相关的知识,从而很好地利用了现有的常识,并经常给出更准确的答案。
三、参数
视觉问答和零次VQA
数据集通过一组独特的三元组表示,我们表示Dtrzsl={(i,q,a)|i∈I,q∈Q,a∈As}和Dtezsl={(i,q,a)|i∈I,q∈Q,a∈Au},其中As和Au分别表示已看到的答案集和看不见的答案集。ZS-VQA比普通的VQA要难得多,因为图像和问题中的信息对于作为训练样本中从未出现过的答案是不充分的。具体地说,我们研究了ZS-VQA测试阶段的两种设置:一种是标准ZSL,其中测试样本(i,q,a)的候选答案是Au,另一种是广义ZSL(GZSL),以Au∪As作为候选答案。应该注意的是,常规的VQA只用看到的答案预测,而GZSL设置下的VQA用看到的和看不见的答案预测。
知识图(KG)
KGs已被广泛应用于知识表示和知识管理中。我们使用的KG是Wang等人对三个KGs(DBpedia、ConceptNet、WebChild)选择的子集。它用于建立先验知识连接,其中包括一组答案节点和概念(工具)节点,以丰富答案之间的关系。此外,还应用不同的关系(边)来表示事实图(三元组)。
以图1为例,所有的(i,q)对可以根据答案源分为两类:1)答案在图像和问题之外,答案的数据源来自包含QA支持的三元组的外部KG。2)答案可以在图像或问题中找到,这种情况下,图像/问题中通常有多个对象可以通过一些隐式的常识关系进行筛选,然后一个事实元祖可以发挥知道答案的作用。
四、方法

4.1 主要思想
我们的主要思想是基于当前基于知识的VQA方法的两个缺陷。首先,在这些方法中,通常构建中间模型,并以一种管道方法涉及KG查询,导致错误传播和泛化差。其次,他们中的大多数将VQA定义为一个分类问题,没有利用对答案的足够知识,无法预测看不见的答案,或在候选答案很少或没有重叠的数据集之间转移。如图1中,如果训练集中没有出现“飞盘”,那传统的VQA将无法在测试阶段识别词汇外的答案(OOV)问题。而其他考虑到答案语义的方法已经失去了关系信息。
通过利用语义嵌入特征作为答案表示,我们将VQA从一个分类任务转换为一个映射任务。参数学习后,问题与图像联合嵌入的分布可以部分接近包含阴影知识的答案分布,我们称之为关于答案的知识空间。此外,我们还独立地定义了另外两个特征空间:关于关系的语义空间和关于支持实体的对象空间。语义空间的目标是根据三元组中的语义信息将(i,q)联合特征投射成一种关系,而对象空间的目标是在(i,q)和一个支持实体(即KG上的实体)之间建立相关的联系。将其结合在一起起到指导回答的作用。为了克服第2.1节中提出的这些限制,我们提供了一种在这种情况下的软/硬掩码方法,以有效地增强对齐过程,同时减轻错误级联。
4.2 建立多个特征空间
我们在一个答案和相应的(i,q)对间建立连接,通过将它们投影到一个共同的特征空间并彼此建立联系。首先,利用q和i之间的融合特征提取器Fθ(i、q)来组合多模态信息,同时,我们将Gφ(a)定义为答案a的表示。我们遵循来自[12]的兼容性概率模型(PMC),并增加损失温度τ以进行更好的优化:

其中,A在设置为标准ZSL时表示Au,否则保持不变,而a是(in,qn)的正确答案。为了学习参数以最大化整个PMC模型的可能性,我们使用以下损失函数:

其中加权函数α(a、b)测量预测答案b对目标函数的贡献程度。在测试过程中,给定学习到的Fθ(i、q)和Gφ(a),我们可以应用以下决策规则来预测对(i、q)对的答案ˆa:

上述特征投影过程可以在VQA中学习需要外部知识的浅层知识。然而,由于网络的性能不够好,因此它不足以用少量的训练数据来建模丰富的先验知识。
可以用知识增强模型将图像或问题中的元素与显式[27]或隐式[9]方式的KG实体匹配以很好地解决开放世界场景理解问题。在我们的方法中,图像/问题和KG之间的对齐是由多个特征空间隐式地完成的,而不是简单的对象检测。我们利用另外两个特征空间进行答案修正:
1)语义空间关注(i、q)中的语言信息,作为KG中三重关系r投影的指导。特别是,q的信号在这部分比i更重要。
2)与识别给定图像的正确类别的传统图像分类相比,对象空间更有可能是一个关于支持实体分类器的特征空间,它同时观察图像和文本的显著特征。具体来说,支持实体e嵌入和(i,q)联合嵌入之间的对齐避免了对复杂知识的直接学习,同时作用于随后的答案掩码过程以及在语义空间中得到的预测关系r。
类似地,我们将它们的嵌入函数定义为Gφ*(r),Gφ(e),相应的(i,q)联合嵌入函数作为Fθ*(i,q),Fθ(i,q)。预训练好的单词向量包含了现实世界自然语言中的潜在语义,为得到答案、关系和支持实体的初始化表示,我们使用GloVe嵌入,同时比较KG嵌入[4]或ConceptNet嵌入[15]。
此外,应考虑同样方式的不同表面形式。[12]利用WUPS分数的加权函数α(a,b),它依赖于a和b之间的语义相似性分数。我们发现它在奇数和复数消歧的情况下很有效,但在许多密集消歧情况下失败。因此,我们应用NLTK工具(例如,WordNetLemmatizer)来实现更准确的词分割和最小编辑距离(MED)的概念消除歧义。
4.3 通过知识的答案掩码
掩码被广泛用于语言模型预训练,以提高机器对文本的理解。两个例子是屏蔽训练语料库中的部分单词(如BERT)和掩蔽常识概念(如AMS),但他们很少考虑预测结果中知识的直接约束,忽略了人类知道如何在现有先验知识的指导下做出合理的决定。与所有这些方法不同,我们提出了一种VQA的答案掩蔽策略。
与学习到的Fθ*和Fθ,我们得到了两个独立特征空间中的不相交融合嵌入,分别作为后续实体和关系匹配的基础:对于给定的(i,q)对,向量相似度Sim计算是通过用于关系的Fθ*(i,q)TGφ*(rn),和用于支持实体的Fθ(i,q)TGφ(en)。那些对应前k个Sim值的e和r分别构成候选集Cent和Crel。然后收集目标集合Ctar如下:
![]()
Ctar通过以下方式计算对所有答案an∈A的掩蔽策略的贡献:

其中,s表示掩码的分数,这是硬掩码和软掩码间的主要区别。软分数大大降低管道方法通过整个模型造成的错误级联,同时,硬掩码的重要性在于其在ZSL设置中的优越性能。最后,对(i,q)对的预测答案ˆa被识别为:

应该注意的是,由于软掩码的存在,候选目标不能仅仅被视为候选答案,它修正了答案的概率,而不是简单地限制了答案的范围。
五、实验
5.1 数据集和指标
(1)F-VQA
包含2190张图像,5286个问题和193449个事实的KG。每个(i,q,a)都由从公共结构化数据库(如ConceptNet,DBPedia和WebChild)中提取的相应常识事实三元组支持。KG有101K个实体和1833个关系,共833个实体被用作答案节点。
(2)ZS-F-VQA
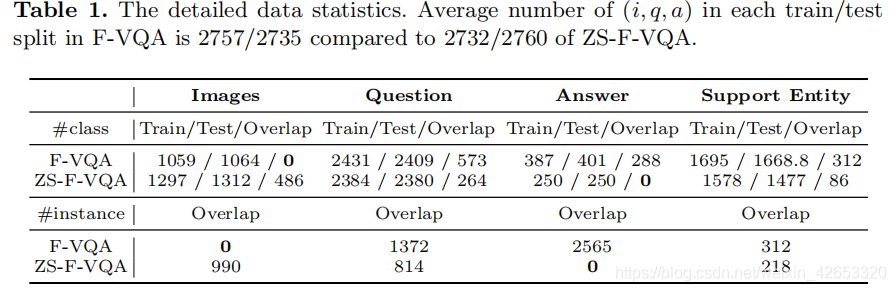
ZS-F-VQA数据集是针对零次问题的F-VQA数据集的一个新分支。首先,我们得到F-VQA数据集的原始训练/测试分割,并将它们结合在一起,只留下根据其出现频率出现在前500的三元组。接下来,将这组答案随机划分为新的训练分割和测试分割,比率为1:1。参照F-VQA标准数据集,划分过程重复5次。对于原始F-VQA数据集中的每个(i,q,a)三联体,如果是a∈As,它将被划分为训练集,否则被分为测试集。如表1,#class表示消除重复数据后的数据数,#instance表示样本数。我们将“Overlap”表示为训练和测试三元组中元素集的交叉的大小。请注意,F-VQA中的训练和测试集之间的答案实例重叠为2565,而ZS-F-VQA中为0。
(3)评估指标
我们通过准确性来衡量性能,并选择[email protected]、[email protected]、[email protected]和MRR/MR一起来判断模型的综合性能。[email protected]表示正确答案在按概率排序的top-k预测答案中排名。平均倒数排名(MRR)测量与平均排名(Mr)相比的正确预测答案的平均倒数值。我们报告的所有结果都是所有分割中的平均值。
5.2 实现细节
(1)融合模型
我们遵循[12]使用多层感知器(MLP)和堆叠注意力网络(SAN)[29]作为基于网格的视觉融合模型的表示。同时,我们选择Up-Down[2]和双线性注意网络(BAN)[13]来衡量自下而上问题对外部知识VQA问题的影响。此外,我们在相同的设置下直接与一些基线(如Qqmaping[27])进行比较。在所有这些方法中,SAN被选为我们的基本特征提取器Fθ,以获得其更好的性能(见图2)。
(2)视觉特征
为获得in,我们从在ImageNet上预训练的ResNet-152(14×14×2048张量)的第4层输出中提取视觉特征。同时应用基于ResNet-101的Faster R-CNN预训练,以获得自下而上的图像区域特征。每幅图像的对象数量被固定为36,具有1024个输出尺寸特征。
(3)文本特征
每个问题和答案的单词都用300维的GloVe向量来表示。然后将相关嵌入式单词序列(平均长度为9.5)输入Bi-GRU。我们也试图在GRU中嵌入答案,但发现由于训练集不够大,平均答案长度只有1.2,它会导致过拟合。所以我们只是通过平均其单词嵌入来表示答案。
训练期间,我们使用Adam优化器,小批量大小为128。采用dropout和批处理标准化来稳定培训。在前7个时期,我们使用一个逐渐的学习速率预热(2.5×(时代+1)×5×10−4),在14到47个时期,每3个时期以0.7的速度衰减它,并在休息时期保持不变。同时,设置损失温度τ为0.01,当patience为30时,提前停止。对模型进行离线训练,因此训练时间通常不影响该方法的应用。在预测中,我们目前考虑了每个测试样本的500个候选答案。这使得评估的计算可以负担得起。
5.3 整体结果

在F-VQA上的结果,为证明我们的模型在广义VQA条件下的有效性。kr和ke表示Top-k的Sim值。有趣的是,UpDn和BAN的行为比SAN差,这可能是由于参数和训练数据有限(小于3000)导致模型过拟合造成的。我们模型在不同程度上都优于基于分类器或基于映射的模型。我们模型的稳定改善(相比于SAN+)表明,将我们的模型添加到其他端到端框架中也可以得到稳定性能改进。最重要的是,我们提出的基于KG的框架独立于融合模型,使得多场景迁移和多模型替换成为可能。

在ZS-F-VQA上的结果,在ZS-VQA上的工作优于传统的基于分类的VQA模型,因为在测试和训练集间没有答案标签重叠。我们在ZSL/GZSL设置下设置了更大的参数k,以减轻硬掩码造成的对候选答案的强约束。从整体上看,基于SAN+模型,我们模型的性能得到了显著提高。
最重要的是,这些模型在具有不同参数设置的各自指标下获得了最先进的性能。以GZSL设置的结果为例,我们的方法在[email protected]时提高了29.39%(从0.22%到29.39%),在[email protected]时提高了44.17%,在[email protected]时提高了75.34%。当设置转换为标准ZSL时,我们也有类似的观察结果。总结,这些观察结果证明了模型在ZSL/GZSL场景中的有效性,但它也反映了模型对kr和ke之间权衡的依赖性。
5.4 消融实验

(1)答案嵌入的选择
为在特征投影表现中比较答案嵌入的影响, KGE技术可以用于完成包含缺失实体或链接的KG,同时产生嵌入节点和链接作为它们的表示。特别是,我们采用TransE[4]作为x(.)。并在我们的KG上进行训练。至于h(a),我们使用了由预训练的常识嵌入模型[15]生成的基于BERT的节点表示,该模型利用了大规模常识KG中节点的结构和语义上下文。表4中表示,当独立工作时,word2vec表示(78.44%)的答案超过了基于图的方法(KGE71.94%和ConceptNet嵌入77.34%),尽管它们包含更多信息。我们猜测,当数据集的大小很小时,神经网络的复杂性限制了模型对输入表示的敏感性。最后,我们简单地选择GloVe作为所有输入的初始表示。
(2)掩码分数的影响

由于高维空间向量的稀疏性,Fθ(i,q)TGφ(fn))在实验中观察到的值相当小。这也是我们定义τ来扩展向量相似性(除了加速模型收敛之外)的另一个原因。考虑到sim((i,q),an)分布从145到232,我们只取100作为硬掩码和软掩码间的分界线,它足够大,可以在测试阶段将错误的答案纠正为一个正确的答案。图3中显示,在ZSL和GZSL VQA场景中,软掩码(即低分数)和硬掩码(即高分)之间的结果差距完全不同。考虑以下原因:1)首先,在数据稀缺时,不要试图依靠网络对复杂的常识知识建模:当应用于ZS-FVQA时,我们注意到模型只是学习先验浅知识表示和看不见答案的差转移能力。在这种情况下,附加知识的较强的指导能力对回答预测做出了很大的贡献。2)其次,如果训练样本足够,管道模式造成的错误级联可能成为模型性能的限制:当应用于标准F-VQA时,模型本身已经对正确答案有了很高的信心,外部知识应该适当地放宽约束。我们观察到,过度强大的指导(即硬掩码)在此时成为一个负担,所以软掩码作为一个软约束是需要的。这反映了定义不同掩码的必要性。
(3)支持实体和关系的影响

图4中,我们注意到,[email protected]和[email protected]不能同时达到最佳,尽管模型在不同的k下总是经常超过基线。这种现象是合理的,因为目标候选集越更严格,越有可能成功地在一个更小范围内预测答案,由于支持实体/关系的错误预测而丢失其他真实答案的代价。MRR和MR之间的对比反映了这一观点(见表3)。
5.5 可解释性

与最佳基线模型SAN+[12]相比,我们可视化了我们的方法的输出和中间过程。图5(上面)显示了ZS-F-VQA数据集中四个实例的支持实体、关系和答案以及SAN+和groundtruth预测的答案。它表明,正常的模型倾向于将答案与问题/图像中的意义内容直接保持一致,或与所看到的答案相匹配,这是一种伴随着过拟合的懒惰的学习方式。某种程度上,这种存储在结构化数据中的困难的常识知识被利用,以起到引导的作用。我们的方法也可以推广到预测多个答案,因为概率模型可以计算所有候选的分数来选择前k答案(参见图5示例2中的答案“tv”)。
我们的方法在广义VQA设置下也工作良好,如图5所示(下)所示。对于那些更简单的答案,它可以增加概率(示例6)以进行正确的预测。更重要的是,与ZSL设置中的硬掩码(暗阴影)不同,这里的软掩码策略有效地减轻了错误级联,从而减少了对先前模型的错误的影响(例如,对支持实体的预测失败会导致示例5上的错误掩码)。
六、总结
我们提出一种通过知识图的零次VQA模型解决利用外部知识的问题。我们方法成功的关键因素是考虑答案本身包含的知识和来自知识图的外部常识知识。同时,我们将VQA从传统的分类任务转换为基于映射的对齐任务,以解决看不见的答案预测。在多模型上的实验支持了我们的主张,即该方法不仅可以在零次场景中取得出色的性能,而且可以在不同端到端模型的一般VQA任务上取得稳定的进展。接下来,我们将进一步研究KG构造和KG嵌入方法,为更鲁棒但是紧凑的语义以解决KG-VQA。此外,我们将与K-ZSL[11]一起发布和改进ZS-VQA代码和数据。
边栏推荐
- ESP8266
- Super détaillé, 20 000 caractères détaillés, mangez à travers es!
- servlet与JSP期末复习考点梳理 42问42答
- paddlepaddle 19 动态修改模型的最后一层
- Cvpr2022 | pointdistiller: structured knowledge distillation for efficient and compact 3D detection
- 事业观、金钱观与幸福观
- PAT甲级 1021 Deepest Root
- P5.js death planet
- Precautions for using sneakemake
- Easy to use plug-ins in idea
猜你喜欢
![[micro service sentinel] degradation rules slow call proportion abnormal proportion abnormal constant](/img/4d/4d4424b609a3c0cd36c5c79daa8861.png)
[micro service sentinel] degradation rules slow call proportion abnormal proportion abnormal constant

lottie. JS creative switch button animal head

Yiwen teaches you Kali information collection

Pat class a 1024 palindromic number

What if asreml-r does not converge in operation?

【一起上水硕系列】Day 6
PAT甲级 1018 Public Bike Management

TopoLVM: 基于LVM的Kubernetes本地持久化方案,容量感知,动态创建PV,轻松使用本地磁盘

Stack overflow vulnerability

Calculation of average wind direction and speed (unit vector method)
随机推荐
Brief introduction of 228 dropout methods of pytorch and fast implementation of dropblock with 4 lines of code based on dropout
Window 加密壳实现
1、项目准备与新建
Flink学习4:flink技术栈
PAT甲级 1021 Deepest Root
2022茶艺师(高级)上岗证题库模拟考试平台操作
Getting started with bluecms code auditing
Installing the Damon database using the command line
Implementation of window encryption shell
Learn from Taiji Maker - mqtt Chapter 2 (I) QoS service quality level
servlet与JSP期末复习考点梳理 42问42答
Yiwen teaches you Kali information collection
DAMA、DCMM等数据管理框架各个能力域的划分是否合理?有内在逻辑吗?
SAI钢笔工具如何使用,入门篇
Precautions for using sneakemake
Human soberness: bottom logic and top cognition
Paddlepaddle 19 dynamically modify the last layer of the model
Stack overflow vulnerability
记录unity 自带读取excel的方法和遇到的一些坑的解决办法
Uninstallation of Dameng database