当前位置:网站首页>【论】A deep-learning model for urban traffic flow prediction with traffic events mined from twitter
【论】A deep-learning model for urban traffic flow prediction with traffic events mined from twitter
2022-06-24 19:27:00 【panbaoran913】
A deep-learning model for urban traffic flow prediction with traffic events mined from twitter
原文,见这里
作者:Aniekan Essien & Ilias Petrounias & Pedro Sampaio & Sandra Sampaio
期刊:
关键字:交通流量预测。LSTM堆叠式自动编码器。深度学习。微博信息预测。智能交通系统
不权威评价:本文的看点是数据有3部分:traffic+weather+twitter.结构式是拓展的深度双向LSTM,缺乏空间结构。并且本文的英文语法错漏百出,非常不利于阅读。如果不是研究在数据上的特色的化,不建议阅读。
摘要
短期交通参数预测是现代城市交通管理控制系统的重要组成部分。当数据驱动的交通模型遇到非经常性或非例行的交通事件时,例如事故、道路封闭和极端天气条件,其预测精度会降低。对社交网络(尤其是twitter)数据的分析挖掘,可以通过补充交通数据和社交媒体帖子中报告的能够扰乱常规交通模式的数据来提高城市交通参数预测。本文提出了一种深度学习的城市交通预测模型,该模型将从推文信息中提取的信息与交通和天气信息相结合。该预测模型采用深度双向长短时记忆 deep Bi-directional Long Short-Term Memory(LSTM)堆栈式自动编码器stacked autoencoder(SAE)架构,利用 微博tweets、交通traffic 和天气weather数据集 进行多步交通流预测。该模型在英国大曼彻斯特的一个城市道路网络上进行了评估。使用真实数据进行大量实证分析的结果表明,与其他经典/统计和机器学习(ML)最先进的模型相比,该方法在提高预测精度方面的有效性。预测精度的提高可以减少道路使用者的挫败感,为企业节省成本,并减少对环境的危害。
1 Introduction
减少交通拥堵水平是世界各地城市的一个重要优先事项,在过去几十年中,这些城市对改善交通速度预测方法和开发 智能交通系统(ITS)有着重要的研究兴趣【26】。ITS的成功主要取决于向交通利益相关者提供的交通信息的质量以及将交通信息应用于制定政策、控制系统和交通预测模型的能力。短期交通预测是一个多学科的研究领域,综合了数学、计算机科学和工程等各个领域的贡献。由于交通的动态性、复杂性和随机性,准确的交通参数预测具有挑战性。与交通预测相关的复杂性源于交通领域的性质,包括物理交通基础设施施加的限制,如道路网络容量、交通法规和管理政策、个体代理人(道路使用者)的行为,以及日历(即一天中的时间、一周中的某一天等)、天气、,事故和事件、事件、道路封闭等等。
交通数据科学经过多年的发展,扩展了用于开发预测模型的大量数据源。早期研究通过影响驾驶行为、出行需求、出行模式、道路安全和交通流特性,调查了天气数据对交通流参数的重要性。此外,多年来的研究表明,降雨会降低交通容量和运行速度,从而增加拥堵和道路网络生产力的损失。例如,[9]的作者报告称,降雨强度通过降低交通速度4-9%影响了城市交通流特征,而高峰时期的交通拥堵与温度强度有显著的关系。尽管天气是交通预报的重要因素,但 ITS 系统中使用的大多数交通预测模型都假定天气晴朗,因此错过了能够更准确地评估交通网络状况的重要环境数据来源。
因此,最近的研究调查了纳入非交通输入数据集对城市交通参数预测的影响,许多(如果不是全部)数据集都提高了预测精度[11,12,22]。例如,一个深度双向LSTM模型,除了使用交通流特征外,还使用降雨和温度数据集进行训练。研究结果表明,与基线数据集(即流量数据集)相比,预测准确性有所提高。在包含非交通输入数据的研究中也得到了类似的结果[22,23]。这可以解释为,数据驱动的交通参数预测通常依赖于应用于历史数据观察的预测分析技术,以提取模式,用于预测未来的观察。这是有效的,因为城市交通数据具有典型的季节性、周期性。例如,早高峰和晚高峰很容易预测,因此可以预测。因此,一个能够从历史数据集中识别和学习这些模式的模型将能够“熟练地”预测未来的交通参数。
然而,在不寻常或非重复发生的情况下,如无法从历史观察推断的事件或事件,即使是最准确的预测模型也会表现出较差的预测性能[12]。非经常性或随机事件/事件的典型例子包括事故、车道封闭、体育和公共事件。考虑到此类事件可能是突然的、意想不到的和/或罕见的,因此有必要开发稳健的预测模型,以便在这些情况下准确预测交通流量。现有的研究已经提出了利用社交媒体数据进行交通参数预测的研究成果,例如,在道路交通预测中使用了基于线性回归的优化技术。作者使用从美国加州性能测量系统(PeMS)获得的在线道路交通数据来测试他们提出的模型。类似地,[30] 代表了一项研究,其中社交媒体数据被用于开发短期流量预测模型。这项研究结合了推特数据来预测体育比赛之前的交通流量,该方法使用四种模型进行评估,即ARIMA、神经网络、支持向量回归和k-近邻(k-NN)。文献[1]提出了一种结合推特数据的卡尔曼滤波模型,用于实时预测公交车到达时间。
深度学习(Deep learning, DL)方法具有先进的图像和语音识别、自然语言处理(natural language processing, NLP)和智能游戏化,也被用于短期交通预测领域[8,25,33]。DL指的是使用堆叠的、多层的架构[16]以分层的方式从高级数据中学习复杂特性的技术。利用在DL架构层上训练的交通预测周期内的社交媒体数据为提高交通预测的准确性提供了额外的机会。本研究旨在为这一领域的研究做出贡献。更具体地说,我们提出了一个深度学习城市交通流预测模型的端到端实现,该模型集成了从交通、天气相关数据和社交媒体推文(可以包含关于非重复或意外事件的信息)中获得的城市交通流预测的实时信息。道路使用者在遇到交通堵塞时,经常会通过微博发布自己的交通状况和位置,为其他道路使用者或交通管理利益相关者提供重要的实时信息。
社交媒体作为一个在线讨论平台,在过去几年里出现了显著的爆炸式增长。例如Facebook、Twitter、Instagram、snapchat等。这些服务被广泛用于交流、新闻报道和广告活动。这些社交媒体平台都提供了应用程序编程接口(api),可以实时检索数据。Twitter是一个流行于短消息(多达280个字符)的公共社交媒体平台,由此产生的数据流可以高速、及时地传播与现实事件相关的信息。由于twitter拥有庞大的用户基础,其获取信息的巨大和差异,许多研究试图利用这个在线数据仓库进行各种数据挖掘目的,如股票市场价格[29],犯罪率预测[39],和流量预测[1,15,41]。
Waze和TomTom等先进的旅行者信息系统Advanced Traveler Information Systems (ATIS)已经利用大众知情的社交媒体数据来改善他们的交通导航和路线引导系统。总的来说,很多twitter账号会报告当前的交通状况,道路使用者可以利用这些账号来推断未来的交通状况,并告知出行方式的选择。例如,在英格兰北部,高速公路英格兰(@HighwaysNWEST),大曼彻斯特交通(TfGM @OfficialTfGM),@nwtrafficnews和Waze (@WazeTrafficMAN)是提供道路交通状况信息的典型例子。除了交通领域主要组织发布的推文外,道路使用者还可以在各自的时间线上发布推文,向(关注者)广播当前的道路交通状况,通过挖掘这些状况来推断未来的交通状况。
因此,我们提出了一种城市交通流预测方法,该方法利用来自推特源的信息,除了与交通和天气相关的数据集外,还可以包含有关非经常性交通事件的信息。[11]中的研究表明,当天气相关(降雨和温度)数据集被集成用于城市交通速度预测时,模型预测性能得到改善。本论文中提出的方法是[11]中提出的方法的增强和增强版本,其目的是提高预测精度。将推文作为表示流量状态的辅助表示的重点是,与其他社交媒体平台相比,推特用户倾向于对事件做出更快的反应。
本研究的贡献有两方面:(1)实证评估了除天气和交通数据集之外的推文是否改善了城市交通流预测,(2)使用推文、天气和交通数据集进行模型训练的端到端深度双向LSTM自编码器交通流预测模型实现。该模型使用来自英国大曼彻斯特斯特雷福德A56(切斯特路)的交通、地理特定推特和天气数据集进行评估。值得注意的是,由于深度学习模型的训练时间较长,添加额外的数据源(tweets)可能会显著影响整体模型的计算需求。因此,我们采用自编码器架构的双向LSTM神经网络。自动编码器,也可以作为降维组件,允许模型在更短的时间内训练,因为输入向量被降低到更小的维空间[16]。
由于交通数据(即时间序列)的空间分布和序列性质,最关键的是要最大限度地利用其中包含的所有数据。LSTM RNNs的基本操作是将按时间顺序排列的输入时间序列数据以链状结构[19]在时间步长t-1到时间步长t的方向上正向或“向前”传播。因此,在顺序数据集中,包含一个双向体系结构可能是有用的,该体系结构考虑向后传播,将反向序列传递给LSTM模型。直观地说,对城市交通数据使用双向LSTM应该会导致更准确的预测,因为它有时可能是有用的“反向学习”数据。例如,向后学习(比方说星期五晚上)可以用来推断星期六清晨或下午的交通情况。例如,如果很多人都在庆祝,直到周五晚上很晚,那么可能会有更少的人在周六早上或下午旅行(例如,New Y ear’s E v e)。另一方面,一个典型的例子是,天气预报说明天会下雪,这可能会影响今天的交通,因为人们可能会想今天出去购物,以避开明天的雪况。文献中的经验结果也表明,使用双向LSTMs进行流量预测比使用单向LSTMs有所改善[3,13]。在我们的模型中,我们加入了bi-directional LSTM,以提高模型的预测性能。此外,由于城市交通数据集的高度复杂和模式结构,双向序列/表示学习可能被证明是一个更稳健的解决方案。
将推文包含在流量预测中遇到的一个重大挑战是确定真实性、准确性和过滤非结构化数据集[15]中的高水平噪声的过程。为了解释这一点,我们调整了我们的算法,以优先处理来自道路交通组织Twitter账户的推文——特别是大曼彻斯特交通(@OfficialTfGM)和Waze (@WazeTrafficMAN)。研究结果表明,当Twitter feed信息包含在内时,模型预测的准确性有了显著提高。
本文的其余部分组织如下。第2节回顾了关于短期流量预测和将推特纳入流量预测的现有相关研究。第3节概述了拟议的方法,包括对关键概念的简要讨论。第4节描述了本研究使用的数据集。第5节概述了实验设置、模型描述和性能评估指标。第6节介绍了研究结果,而我们在第7节总结了研究并提出了未来的工作。
2 Related studies
本节介绍了相关研究的回顾,首先概述了短期交通预测、参数和非参数模型的技术背景。该部分最后回顾了整合Twitter消息的交通预测研究。
2.1 Short-term traffic prediction
短期交通预测技术大致分为参数化方法和非参数化方法。参数化模型是指将输入数据简化为已知函数来总结数据的模型。参数化模型有时被称为基于模型的预测方法,因为模型结构是通过对经验数据[16]的计算模型参数来预定的。自回归综合移动平均(ARIMA)模型[37]是最早的参数预测模型之一。ARIMA模型由差分方程定义:

式(1)中的变量 p p p和 q q q中是大于或等于零的整数,分别表示自回归和移动平均分量。ARIMA(p,d,q)模型的成功应用要求输入时间序列是平稳的。由于这个原因,有时会应用差分法来诱导数据集的平稳性,这涉及到观测值之间的连续差异。因此,计算第三个参数,即差值 ( d ) (d) (d),举例:if d = 0 : y t = y t d=0: y_t=y_t d=0:yt=yt; if d = 1 , y t = y t − 1 d=1,y_t=y_{t-1} d=1,yt=yt−1
然而,该模型的主要假设是均值、方差和自相关的平稳性。这是一个显著的缺点,因为它往往忽略了交通数据集中常见的极值【14】。交通参数往往会在高峰时段出现峰值,以及随着事件或事故的快速波动。因此,ARIMA预测值在应用于交通预测时显示出弱点。
在非参数模型中,算法从数据中“学习”,从而选择最适合训练数据集的函数,这意味着它们可以将许多函数适合特定数据集[16]。k-最近邻(k-NN)通常被认为是最容易实现的非参数机器学习模型[34],在交通量预测中得到了广泛的研究[34,40,43]。驱动该模型的逻辑是,对特征空间中k个最相似的观测值进行分类后,新的观测样本很可能属于这一类别【42】。该模型的参数有:状态向量、距离度量、最近邻数k和预测算法。距离度量衡量样本和测试数据之间的近似程度。这是使用欧几里德距离计算的,表示为:
人工神经网络(ANN)是另一类非参数交通预测模型,其灵感来源于人脑的内部工作机制[5]。这类预测模型除了具有良好的学习能力外,还可以处理多维和非线性数据。ANN模型的基本模型组件是多层感知器(MLP),如式(3)所述:
其中 M M M和 N N N分别表示输入层和隐藏层中的神经元数量, g g g和 h h h是传递函数。 θ θ θ是输入层神经元的权重值,而 φ φ φ是隐藏层的权重或偏差。神经网络通过使用优化算法(如反向传播)来减少误差。然而,当应用于时间序列分析时,传统的神经网络显示出不足之处,因为它们忽略了时间序列数据的时间维度,这导致了递归神经网络(RNN)的发展[7]。
其中, W h x W_{hx} Whx表示输入和递归隐藏节点之间的权重, W h h W_{hh} Whh表示递归节点和隐藏节点自身的前一时间步之间的权重, b b b和 σ σ σ分别表示偏差和非线性(sigmoid)激活。尽管RNN在时间序列预测问题上表现更好,但它们仍有一些问题有待解决。例如,从上面的等式(4)可以看出,随着时间间隔的增加,周期性隐态 h t h_t ht接近零,这导致了梯度递减问题。因此,RNN无法从具有长时间滞后的时间序列中学习。德国工程师霍切雷特(Hochereiter)和施密杜伯(Schmidhuber)[19]的工作解决了这一问题,即长-短期记忆RNN,其主要目标是在时间序列中建模长期时间依赖性。LSTM模型用一个“存储单元”取代了周期性隐藏单元。
图2描述了具有一个内存块的LSTM-NN的体系结构。内存块包含输入、输出和遗忘门,它们分别在每个单元上执行写入、读取和重置功能。乘法门,即 ⊕ ⊕ ⊕ 和 ⊗ ⊗ ⊗, 分别引用矩阵加法和点积运算符,允许模型长时间存储信息,从而消除了传统神经网络模型中常见的消失梯度问题[19]。
在LSTM模型中,时间序列的输入序列是 x = x 1 + x 2 + x 3 , … , x t x= x_1 + x_2 + x_3,…,x_t x= x1 + x2 + x3,…,xt,输出序列 y = y 1 + y 2 + y 3 , … , y t y=y_1 + y_2 + y_3,…,y_t y=y1 + y2 + y3,…,yt是使用提供的历史数据计算的,没有被告知向后追踪多少时间步的。这是通过使用以下方程组实现的:

LSTM深层神经网络已广泛应用于交通预测研究中,例如在[28]中,LSTM-NN模型用于交通速度预测,并将结果与其他非参数算法(支持向量机(SVM)、卡尔曼滤波器和ARIMA)进行比较。结果表明,LSTM模型在预测精度上具有优势。此外,[23]提出了一个LSTM和深度信念网络(DBN)深度学习模型,以利用中国北京的交通和降雨数据预测短期交通速度。实验结果表明,融合天气和交通数据源提高了模型的预测性能。
2.2 Traffic prediction using twitter information
尽管推特已经成为一个流行的社交媒体平台,但仍有机会利用其庞大的用户群中的数据来改进流量预测。[21]在推特上介绍了一项关于社交互动的研究,该研究揭示,推特被广泛采用的驱动过程可能是因为它代表了一个隐藏的网络,大多数信息描述的是无意义的互动。这构成了怀疑论的一个重要前提,这一点在有关使用推特消息进行流量预测的文献中可以看到,在数量稀少的研究中很明显。由于推特平台的开源、公共性,推特上获得的数据可能是主观的、特定于上下文的、包含细微差别的,或者是旨在表达讽刺或讽刺的语句。
尽管存在这些缺点,许多研究试图将推特信息纳入交通预测模型训练中。例如,[1]提出了一个卡尔曼滤波模型,该模型使用整合的twitter交通信息和交通数据进行训练,以预测公共车辆到达时间。该研究利用与道路交通信息相关的实时推特,并对检索到的数据集进行语义分析。与纯交通数据源相比,结果显示出显著的改善。类似地,[15]提出了一个使用语义挖掘的推特流量数据集训练的深层人群流量预测模型。该研究采用了现有的人群流量预测模型——时空残差网络(ST-ResNet),如【44】所示,作为比较的基线模型。端到端预测模型配置 为将推特作为模型训练的额外输入,以便预测城市环境中未来的交通拥挤流量。研究结果表明,与推特数据和交通流量呈正相关,与基线模型相比,预测精度有所提高。同样,[41]提出了一个用于预测道路交通拥堵严重程度的决策树模型,并在泰国曼谷的实时交通网络上对该模型进行了测试。基于C4.5决策树的模型接受来自各种道路交通广播推特用户帐户的推特,并将其与特定地区的大量人群相关联。研究结果表明,加入推特道路交通信息可以提高预测模型的性能。尽管上述研究使用推特获得的数据集进行流量预测,但他们使用推特分析的数据作为模型训练的唯一非流量输入数据集。虽然研究结果表明预测精度有所提高,但我们的经验表明,除了交通数据集外,还包括天气和推特数据,将显著提高深度学习预测模型的预测精度。
3.Methodology
本节介绍神经网络的基本概念及其作为自动编码器的使用。我们首先描述自动编码器,包括其基本逻辑和功能,然后总结提出的深双向LSTM预测模型。所提出的模型是[11]中提出的模型的增强版本,在该模型中,除了将推特消息作为模型训练数据集的额外输入外,我们还使用堆叠式自动编码器进行模型训练。自动编码器的主要优点是学习一组输入数据向量的压缩表示(编码)。换言之,自动编码器兼作时间序列数据中的降维技术和图像分析中的数据压缩工具,可以在短时间内使用非常大的数据集进行训练【16】。因此,与普通的深层LSTM神经网络相比,使用LSTM自动编码器可以在更短的时间内处理高维和大数据。
3.1 Autoencoders
自动编码器 是一种前馈神经网络,它获取输入向量 x x x并将其转换为隐藏表示或“潜在”空间h。换句话说,自动编码器将输入向量压缩为低维“代码”,并尝试从该给定表示重构输出。自动编码器由三个主要组件组成:编码器、代码和解码器。使用等式(13)实现输入向量变换或编码器功能:
堆叠式自动编码器 是一组自动编码器,与自动编码器一样,它以无监督的方式进行学习。学习过程包括分层培训,以最大限度地减少输入和输出向量之间的误差。自动编码器的下一层是前一层的隐藏层,每一层都通过使用优化函数的梯度下降算法进行训练,该优化函数是单个自动编码器层的平方重建误差 J J J。这在(15)中描述。
3.2 Deep bi-directional LSTMs
Deep LSTM网络是一种具有许多(因此称为深层)层的循环网络。它用LSTM存储单元取代传统的循环单元。应用深层LSTM网络的特殊优势在于,它可以从层次上了解复杂数据结构中的长期依赖关系[16]。与单层或双层(即浅层学习/网络)LSTM网络相比,深层LSTM可以分层提取复杂时间序列或序列数据集中的时间依赖关系[18]。
双向LSTMbi-directional LSTM的结构是由两个单向LSTM组成的结构-以相反方向堆叠。因此,在双向LSTM训练周期中应用时间序列的历史和未来向量。通过这种方式,使用两个单独的隐藏层在两个方向上处理数据,然后将其转发到单个输出层。图3显示了双向LSTM的结构。可以看出,网络计算前向隐藏序列 h ⃗ \vec{h} h和后向隐藏序列 h ← h← h←. 然后,通过按逆时间顺序(即从 t t t开始)迭代后向层来计算输出 = T到1),而前向层是从T = 因此,深度双向LSTM是一个深度双向LSTM网络,它是深度学习体系结构中记录的成功的关键组成部分。如前所述,深度学习网络可以在复杂数据集中分层构建层表示。深层双向LSTM是通过垂直叠加多层双向LSTM创建的。这样,一层的输出序列就可以作为下一层的输入序列。
3.3 Data fusion
数据融合 是指处理来自多个数据源的数据的自动检测、集成、预测和组合的多层过程。根据文献[4],数据融合技术有五大类(i)数据输入输出 Data in-data out(DAI-DAO),(ii)数据输入特征输出Data in-feature out(DAIFEO),(iii)特征输入特征输出Feature in-feature out(FEI-FEO),(iv)特征不确定性输出Feature indecision out(FEI-DEO)和(v)决策输入决策输出Decision in-decision out(DEIDEO)。在这项研究中,我们采用了 DAI-DAO 数据融合技术,类似于[11]中提出的融合技术,其中利用了交通和天气信息的组合。如上所述,在该级别融合数据的优势导致更可靠的输出,因为可以避免在特征或预测/决策级别融合期间引入的错误。
3.4 Deep bi-directional LSTM model
图4描述了本文提出的模型体系结构的概述。该模型旨在预测时间t时交通流的下12个时间步(12个5分钟预测,即下一小时的预测交通流)。我们的交通量预测方法遵循使用双向LSTM以无监督的方式进行学习。该模型包括四个主要元素:编码器、重复向量、解码器和完全连接(FC)层(the encoder, repeat vector, decoder, and fully connected (FC) layers)。
第一个组件表示输入层,输入层接受输入向量,包括traffic, weather, tweet data,是一个 m × n m\times n m×n的向量,其中 m m m表示训练数据集中的样本数, n n n表示特征数(本例中为5)。第二组层包括双向LSTM层,它们共同构成编码器层。双向LSTM堆栈读取向量的输入序列。读取最后一个序列后,应用一个重复向量层,该层(顾名思义)重复编码器层要复制的向量序列。然后,解码器层从重复向量层接管序列,并将预测输出为单行向量序列。然后将其传递到FC层,在该层中预测目标序列。LSTM自动编码器的概念超出了本研究的范围,但我们参考了[38]中的工作以了解更多细节。
4 Data description
对于本文记录的实验,数据集由大曼彻斯特交通局Transport for Greater Manchester(TfGM)提供。研究期间获得的天气数据包括每小时的温度(摄氏度)和降水量(毫米)。推特数据来自两(2)个道路交通信息推特用户帐户。这些账户分别是TfGM(@OfficialTfGM)和Waze Manchester(@WazeTrafficMAN)的官方推特句柄。有关数据集准备的详细信息将在以下小节中描述。
4.1 Traffic dataset
该数据集包括5分钟的交通流特征(速度、流量和密度)的历史观测数据,使用电感环路探测器收集。研究区域有十个交通传感器,每个传感器相距0.3英里。研究时间为2016年4月1日至2017年4月16日。研究区域是位于英国大曼彻斯特地区斯特雷特福德的一条主干道Chester road (A56),位于经纬度坐标(53.46281,−2.28398)和(53.43822,−2.31394)之间,如图5中地图上的精确标记所示。选择的这个研究区域是因为它代表了一个理想的测试平台,因为它是从南曼彻斯特住宅区到曼彻斯特市中心的两条主要道路之一。此外,这条路还是通往曼联球场——老特拉福德球场——以及其他休闲场所,如购物中心、俱乐部、餐馆等的主干道。因此,这条路在高峰时间(即旅客上下班的时候)、足球比赛、周末(由于购物中心和其他景点中心)总是交通繁忙。
4.2 Weather data
这项研究的天气数据来自曼彻斯特大学的大气研究中心(CAS)。该数据集包括上一小节所述同一研究期间的每小时降水(以毫米为单位)和温度(以摄氏度为单位)的观测数据。但是,考虑到速度数据包含5分钟的交通参数,为了合并天气数据,估计每小时的数据在组成一个小时的每分钟都是相同的。虽然这可能是一个限制,因为有失去一些丰富的信息的趋势,但与将流量和推特数据聚合到每小时的观察相比,它代表了更好的选择。此外,估计温度在一小时内保持不变并不代表信息的重大损失,因为人们可以辩称,温度在一小时内没有显著变化。甚至流行的天气信息移动应用程序,如天气频道、5 WeatherProHD、6和雅虎!天气,7所有的天气资料以每小时观测一次。
4.3 Tweets data
在这项研究中,编写了python脚本,使用推特流APIFootnote8和tweepyFootnote9包从推特收集推特。为了确保从推特上获得的数据真实且特定于地理位置,我们选择只使用道路交通信息用户(TfGM和Waze)的推特。编写第一个脚本是为了从这两个用户帐户中提取所有推文。通过这种方式,我们将@OfficialTfGM和@WazeTrafficMAN的Twitter用户帐户ID作为API中的follow参数传递。这一步的结果是102675。其次,我们对结果集进行过滤,只包括关于正在考虑的给定路段(切斯特路A56号)的推特。这样,“A56”和“Chester Road”的关键字就被用作python脚本中端点的跟踪参数。这就产生了一个数据集,包含来自两个用户的9275条推文。第四步包括从每条推文中提取时间戳,以获取其日期-时间格式(即dd-mm-yyyy-hh:mm)。脚本的最后一步涉及将推文中的时间戳与合并的交通和天气数据集合并。合并过程涉及在推文的各个时间戳处将数据集编码为1,以反映有关交通状况的推文,或者在没有记录推文的情况下将数据集编码为0。综合数据集包含109728个5分钟聚合交通流量、速度、降雨量、温度和推特变量的观测值。然后使用70:30的列车试验比率对数据集进行分割。表1总结了本研究中使用的数据集的描述性统计数据。

5 Experimental setup
本研究采用重叠滑动窗口方法,将输入的多元时间序列数据重建为监督学习格式,类似于[11]中描述的过程。因此,开发了预测模型,以学习历史时间序列数据集中的特征,从而进行多步骤1小时提前(5分钟预测期的12个步骤)交通流预测,并使用表1所示的聚合数据集进行了训练
5.1 Model description

该框架采用八层双向LSTM堆叠式自动编码器架构。对于所有互连层(输出层除外),使用的激活函数是校正线性单元(ReLU),它将非线性引入学习过程。深度学习网络的性能取决于关键参数,这些参数必须通过超参数优化或超参数化过程预先确定。在本研究中,为了确定最优的超参数集,我们应用了网格搜索框架。这为获得最佳参数集提供了一种可重复且灵活的方法。算法1给出了总体预测算法。我们应用了一个改进的深度双向LSTM交通预测模型,该模型来自于【11】中提出的模型,用于预测前方12个时间步的交通流(即5分钟预测范围内的12个时间步,等于未来一小时的交通量)。[11]中使用的模型是使用交通和天气数据训练的城市交通速度预测模型。因此,我们在本研究中采用了以下深度学习方法(见表2)。
5.2 Model performance evaluation
在这项研究中,我们采用了一种预测评估技术,称为前向验证或后向测试。传统的评估方法(如k-fold交叉验证)不适合用于时间序列数据,因为它们没有考虑输入数据集的时间或顺序/维度。我们采用三种统计预测精度评估指标——平均绝对误差(MAE)、均方根误差(RMSE)和对称平均绝对百分比误差(sMAPE),这些指标由以下等式定义。

5.3 Baseline models
我们将该模型的性能与选定的最先进的基线机器学习模型进行了比较。使用前一节中描述的性能评估指标,我们将建议的模型与以下基线模型进行了比较。(1) 支持向量回归器[32],(2)极端梯度增强(xGBoost)[6]和随机森林回归器[27]。对于每个基线模型,使用相同的训练数据集来确保模型评估过程的公平性和客观性。
5.4 Implementation environment
本研究使用的实验环境是在单个GPU节点上进行的,该节点具有IntelXeonE-2146G [email protected]、32-GB内存和NVIDIA Tesla V100-PCIE 16GB GPU。GPU用于加速模型训练,因为深度学习模型需要大量计算。开发是使用Python 3.6.8、R版本3.5.1和TensorFlow 1.12.0执行的。
6 Results

本研究使用的测试数据集范围为2016年12月23日至2017年4月16日。表3显示了拟议模型和基线模型的绩效评估结果。如表所示,当使用推特消息、天气和流量数据集(即阴影行)时,预测精度有显著提高。还可以看出,本文提出的模型优于传统的机器学习基线,但具有更高的训练时间。图6显示了使用三(3)个输入数据组合训练的各个模型的MAE条形图。可以看出,使用推特、天气和交通数据训练的模型记录的MAE最低。类似地,从表3可以看出,SVR模型与拟议模型的结果相比表现出竞争性。boosting算法返回的结果最差,但训练时间最短。综上所述,与仅使用交通和天气数据集训练的模型相比,结果清楚地表明了显著的改进(减少了误差)。尽管只使用流量的模型训练时间最短,但它们会导致更高的预测误差(MAE、RMSE和sMAPE)。这使得我们可以得出这样的结论:当对组合交通、天气和推特数据源进行训练时,包含推特分析可以显著提高预测精度。
虽然观察到的精度提高方面的收益似乎微乎其微,但值得一提的是,通过减少MAE(即使用交通和天气数据集从8辆/小时减少到使用推特数据集的5.5辆/小时)实现的成本效益是显著的。例如,如果可以量化和计算道路使用者的时间损失,以及由于排放和声音污染造成的拥堵对环境影响的成本,则无需合理化交通预测准确性的提高。此外,准确度的提高可以直接等同于供应链/物流公司(如亚马逊、DHL等)的财务/成本节约。因此,预测误差的看似微不足道或边际减少很容易导致数百万英镑的节约,特别是考虑到所讨论的预测模型考虑了城市交通。此外,更准确的交通预测可以减少驾驶员的沮丧情绪,因为这是一条非常繁忙的道路,尤其是在高峰时间。例如,假设这条路上发生了一起事故。交通管理人员必须使用准确的交通预测,并在此基础上做出适当的决策,即什么也不做,将交通分流到附近的道路,如果有公交专用道,或者改变交通信号灯的频率(如果有)。如果预测不准确,从而导致错误的决策,那么这将给驾驶员带来更多的挫折、更多的延迟交付、更多的噪音/环境污染。
图7显示了表2第3、4和5阶段所述三个预测模型的预测和地面真值(实际)观测的散点图。散点图中的x轴表示实际(地面真实)交通流量值,而y轴表示预测值。子图表标题表示预测模型的R2值,可从表3中推断。

图7中右下角的图形表示在研究区域内车道封闭的特定时期,各个模型的预测值和实际值的多图。车道封闭持续了四天,原因是研究区域的道路建设工程。图7右下角图形中的y轴表示交通流量(辆/小时),而x轴表示车道封闭生效时四天内的5分钟时间步长(48个时间步长)。从图中可以看出,仅使用交通数据集和交通与天气数据集训练的预测模型不如使用集成推特数据集训练的模型准确。然而,使用推特数据集训练的模型在预测中表现最好,因为有几条推特是从推特账户广播的,这提高了预测模型的准确性。
类似地,图8显示了分别使用推特+流量+天气数据集训练的模型的前400个时间步的各自预测性能。对于每个子地块,x轴表示时间步长,y轴表示流量值(veh/h)(对于每个地块的上半部分)以及预测值和实际值之间的绝对误差(对于子地块的下半部分)。从图8中的图形可以看出,所提出的模型准确地捕获了时间模式,并且显著优于机器学习最先进的基准模型。如图所示,建议的模型表现最好,SVR模型次之。在计算时间方面对这两个模型进行比较时,可以看出,当MAE降低约35.4%(即从8.5辆/小时降至5.5辆/小时)时,拟议模型的性能具有竞争力(即583秒vs.496秒或时间增加17%)。

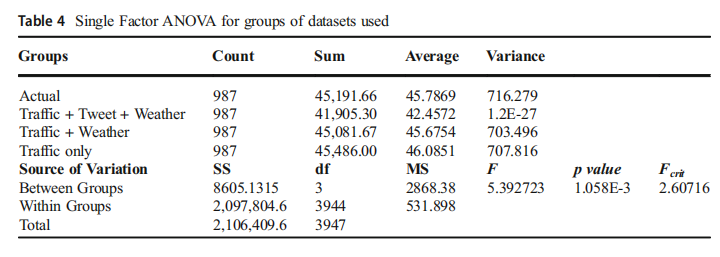
为了测试获得的结果集之间的统计显著性,我们进行了方差分析analysis of variance (ANOVA),因为它估计了组内的方差(即原始数据中的方差/误差)和组间的方差(即实验效果的结果)。在本节中,我们使用方差分析比较了从训练数据集推特+天气+流量、天气+流量和仅使用流量得出的预测结果。以下假设使用方差分析进行检验。
假设陈述使用假设为0.05的显著性水平进行检验(p < 0.05). 表4显示了各训练模式预测值组的单因素方差分析结果(即分别使用推特+天气+交通数据集、交通+天气和仅交通数据集)。假设F大于Fcrit,则无效假设被拒绝,这意味着相应的结果显著不同。从表中可以看出,有显著差异(p < 0.05),因此,假设Fcrit = 2.6072和F = 5.3927,因此F > Fcrit公司。此外,组间的p值显示出统计学意义,支持拒绝无效假设的说法,因为p = 0.001058 < 0.05.
7 Conclusions and future work
在本文中,我们提出了一个城市交通流预测模型,该模型探索了将从推特数据中获得的丰富信息集成到城市交通预测中的有效性,从而扩展了现有的基于天气和交通数据集的城市交通预测模型。【11】中提出的基线模型采用了深度双向LSTM体系结构,该体系结构包括交通流参数以及降雨量和温度。本文提出的增强模型采用了双向LSTM自动编码器方法,该方法接受来自道路交通信息推特账户@OfficialTfGM和@WazeTrafficMAN的地理特定推特作为额外的非交通输入数据。实证分析的结果表明,除了交通、降雨和温度数据集外,加入推特数据还可以将MAE从8辆/小时减少到5.5辆/小时,从而提供更准确的交通流预测模型。在英国大曼彻斯特的一条城市主干道(切斯特路-A56)上,使用历史交通、天气和推特数据集对该模型进行了测试。
本研究中介绍的工作仅限于英国大曼彻斯特的一条主干道。虽然这是一个限制,但使用模型原样来说明大城市中的其他城市道路可以使用一些其他数据功能重用建议的模型体系结构。例如,可以修改数据集、推特位置和推特来源(即曼彻斯特的TfGM、伦敦的TfL等),以适应考虑中的不同位置,同时保留模型架构和组成。另一方面,可以考虑道路之间的相关性(即A路的事故如何影响B路?)具有一些附加数据功能。然而,随着模型计算资源和训练时间的相应增加,扩展该模型以适应非常广泛的地理区域带来了相当大的复杂性挑战。更大的地理区域涉及更多的数据和更高的培训时间要求,因此,增加了精确度较低的可能性,尤其是由于住宅街道和道路上的交通传感设备较不发达。然而,考虑到研究区域考虑了进入曼彻斯特市中心的两条主要管道之一,由于企业拥有其经营场所和大型Arndale购物中心,曼彻斯特市中心吸引了大量交通,因此提议的端到端模式可以复制到其他主干道和高速公路,这将有助于有效管理大曼彻斯特(人口约280万)等主要地理区域的交通拥堵。未来的工作将考虑对推特进行额外的过滤,并包括额外的关键字。然而,还必须考虑权衡,例如,推特的语义分析可能会提高模型性能,但也会增加训练和预处理时间,如【35】所示。其次,在本文中,我们只包括来自交通主管部门(即TfGM和WazeTrafficMAN)的推特数据。有可能包括来自其他道路交通信息推特账户的推特,例如来自曼联足球俱乐部(足球日)或活动公司的推特。
边栏推荐
- leetcode1720_2021-10-14
- [cloud native learning notes] kubernetes Foundation
- Apple mobile phone can see some fun ways to install IPA package
- Pattern recognition - 9 Decision tree
- BPF_ PROG_ TYPE_ SOCKET_ Filter function implementation
- Blender FAQs
- Memcached full profiling – 1 Fundamentals of memcached
- [cloud native learning notes] learn about kubernetes' pod
- 使用Adb连接设备时提示设备无权限
- Antdb database online training has started! More flexible, professional and rich
猜你喜欢
自己总结的wireshark抓包技巧
Wireshark packet capturing skills summarized by myself

Pattern recognition - 1 Bayesian decision theory_ P1

TDengine可通过数据同步工具 DataX读写
Tdengine can read and write through dataX

Memcached comprehensive analysis – 2 Understand memcached memory storage

memcached全面剖析–3. memcached的删除机制和发展方向

关于Unity中的transform.InverseTransformPoint, transform.InverseTransofrmDirection

XTransfer技术新人进阶秘诀:不可错过的宝藏Mentor

Static routing experiment
随机推荐
how to install clustershell
memcached全面剖析–2. 理解memcached的內存存儲
Bld3 getting started UI
123. 买卖股票的最佳时机 III
leetcode1863_2021-10-14
福建省发改委福州市营商办莅临育润大健康事业部指导视察工作
About transform InverseTransformPoint, transform. InverseTransofrmDirection
TCP_ Nodelay and TCP_ CORK
Analyse complète Memcached – 2. Comprendre le stockage de mémoire pour Memcached
C语言-关键字1
Fuzhou business office of Fujian development and Reform Commission visited the health department of Yurun university to guide and inspect the work
Visit Amazon memorydb and build your own redis memory database
Auto. JS to automatically authorize screen capture permission
Blender's simple skills - array, rotation, array and curve
字节的软件测试盆友们你们可以跳槽了,这还是你们心心念念的字节吗?
使用Adb连接设备时提示设备无权限
Kernel Debugging Tricks
[cloud native learning notes] kubernetes Foundation
The first day of handwritten RPC -- review of some basic knowledge
Return of missing persons