当前位置:网站首页>Rlib learning - [4] - algorithmconfig detailed introduction [pytoch version]
Rlib learning - [4] - algorithmconfig detailed introduction [pytoch version]
2022-07-24 04:50:00 【Most appropriate commitment】
Algorithm config It includes all aspects Parameters , Corresponding to the generation of different modules .
“env_config”, # Parameters corresponding to environment generation , With self-defined env of , This article does not introduce
“model”, # Definition and model Parameters used in the process of structure generation , Detailed introduction
“optimizer”, # Definition Optimized parameters , Brief introduction
“multiagent”, # Related to multi-agent , This article does not introduce
“custom_resources_per_worker”, # Definition resources , Brief introduction
“evaluation_config”, # Evaluate relevant parameters , Brief introduction
“exploration_config”, # Explore relevant parameters , Detailed introduction
“replay_buffer_config”, # replay buffer Set the relevant parameters , Detailed introduction
“extra_python_environs_for_worker”, #
“input_config”,
“output_config”,
resources
Define the resources for the environment to run
self.num_gpus = 0 # GPU number It can be a decimal
self.num_cpus_per_worker = 1 # Every worker Of CPU number
self.num_gpus_per_worker = 0 # Every worker Of GPU number
self._fake_gpus = False
self.num_cpus_for_local_worker = 1 # Local worker The amount of CPU number
self.custom_resources_per_worker = {
}
self.placement_strategy = "PACK"
framework
self.framework_str = "tf" # tf , tf2, torch This article is about tensorflow dependent tf_session No introduction
env
self.env = None # First use register Registration environment , And then use str Define
self.env_config = {
} # According to your own settings env_config Variable to set
self.observation_space = None # Observation space , You can leave it blank , according to env.observation_space Directly obtained
self.action_space = None # Action space , You can leave it blank , according to env.action_space Directly obtained
self.env_task_fn = None # In multitasking , Set how to perform each task in the environment
self.render_env = False # Whether to render the environment , True Will generate video and ray_results | False Only generates ray_results
self.clip_rewards = None # Whether or not to reward Conduct clip
self.normalize_actions = True # Whether to regularize the action , according to action_space The upper and lower bounds of normalization
self.clip_actions = False # Whether or not to action Conduct clip , According to the upper and lower bounds of the action space clip
self.disable_env_checking = False # At the beginning , Whether to refuse to check the environment : True: Do not check the environment
rollouts
self.num_workers = 2 # remote_worker The number of . If you only want one local_worker, Is set to 0
self.num_envs_per_worker = 1 # Every worker How many? env At the same time
self.sample_collector = SimpleListCollector # How from different worker Collect samples
self.create_env_on_local_worker = False # Whether to be in local_worker Create env. You can leave it blank , It's automatically set .
self.sample_async = False # Whether to take asynchronous sample
self.enable_connectors = False
self.rollout_fragment_length = 200 # Every time from one worker One of the env How much samples
# num_envs_per_worker Greater than 1 When , Every worker To obtain the samples yes num_envs_per_worker*rollout_fragment_length
# Finally together , Generate train_batch_size
self.batch_mode = "truncate_episodes" # orsample Whether the collection is required to be complete episode Information about "complete_episode"
self.remote_worker_envs = False #
self.remote_env_batch_wait_ms = 0
self.validate_workers_after_construction = True
self.ignore_worker_failures = False
self.recreate_failed_workers = False # If there is worker failed, Whether to recreate worker
self.restart_failed_sub_environments = False
self.num_consecutive_worker_failures_tolerance = 100
self.horizon = None # every last env The longest length of
self.soft_horizon = False # soft_horizon Set up
self.no_done_at_end = False
self.preprocessor_pref = "deepmind" # preprocessor Preprocessing settings , It can be set to None. The preprocessor Only in atari game To start
self.observation_filter = "NoFilter" # You can set the mean square deviation filter, Generally in their own env Finish in filter
self.synchronize_filters = True
self.compress_observations = False
# `self.training()`
self.gamma = 0.99
self.lr = 0.001
self.train_batch_size = 32
self.model = copy.deepcopy(MODEL_DEFAULTS) # The next section focuses on
self.optimizer = {
}
model_config
ModelConfigDict = {
# Experimental flag.
# If True, try to use a native (tf.keras.Model or torch.Module) default
# model instead of our built-in ModelV2 defaults.
# If False (default), use "classic" ModelV2 default models.
# Note that this currently only works for:
# 1) framework != torch AND
# 2) fully connected and CNN default networks as well as
# auto-wrapped LSTM- and attention nets.
"_use_default_native_models": False,
# Experimental flag.
# If True, user specified no preprocessor to be created
# (via config._disable_preprocessor_api=True). If True, observations
# will arrive in model as they are returned by the env.
"_disable_preprocessor_api": False, # It can be set to disable
# Experimental flag.
# If True, RLlib will no longer flatten the policy-computed actions into
# a single tensor (for storage in SampleCollectors/output files/etc..),
# but leave (possibly nested) actions as-is. Disabling flattening affects:
# - SampleCollectors: Have to store possibly nested action structs.
# - Models that have the previous action(s) as part of their input.
# - Algorithms reading from offline files (incl. action information).
"_disable_action_flattening": False,
# ===
# This time, we will only explain CNN + MLP, Don't involve RNN,LSTM,transformer
# Therefore, there are usually only three types of input , Pure picture input gym.Spaces.Box() len(shape)= 3
# pure vector Input : gym.space.Discrete / MultiDiscrete / Box, len(shape)=1
# complex, contain Pictures and vector The input of Tuple/Dict( Discrete, Box,.. )
# For these three inputs , The parameters used in setting are different .
# === Pure picture input ===
# "conv_filters" + "conv_activation" Realization CNN, "post_fcnet_hiddens" + "post_fcnet_activation" Late implementation MLP,
# “fcnet_hiddens” Not set up
# === pure vector Input ===
# "fcnet_hiddens" + "fcnet_activation" Realization MLP ; "fcnet_hiddens" Not set up ( You can also set it here , Will regard "fcnet_hiddens" The continuation of )
# === complex Type of input ===
# rllib Will automatically Picture Integration , take vector Integrate
# Picture input to CNN ("conv_filters"+"conv_activation") , vector Pass alone "fcnet_hiddens" + "fcnet_activation" ( Set to None, Then direct linear output vector)
# The final will be Picture output results faltten after and vector After the MLP concatenate Together ,
# And then type in "post_fcnet_hiddens"+"post_fcnet_activation"
# =====
# === Built-in options ===
# FullyConnectedNetwork (tf and torch): rllib.models.tf|torch.fcnet.py
# These are used if no custom model is specified and the input space is 1D.
# Number of hidden layers to be used.
"fcnet_hiddens": [256, 256],
# Activation function descriptor.
# Supported values are: "tanh", "relu", "swish" (or "silu"),
# "linear" (or None).
"fcnet_activation": "tanh",
# VisionNetwork (tf and torch): rllib.models.tf|torch.visionnet.py
# These are used if no custom model is specified and the input space is 2D.
# Filter config: List of [out_channels, kernel, stride] for each filter.
# Example:
# Use None for making RLlib try to find a default filter setup given the
# observation space.
"conv_filters": None,
# Activation function descriptor.
# Supported values are: "tanh", "relu", "swish" (or "silu"),
# "linear" (or None).
"conv_activation": "relu",
# Some default models support a final FC stack of n Dense layers with given
# activation:
# - Complex observation spaces: Image components are fed through
# VisionNets, flat Boxes are left as-is, Discrete are one-hot'd, then
# everything is concated and pushed through this final FC stack.
# - VisionNets (CNNs), e.g. after the CNN stack, there may be
# additional Dense layers.
# - FullyConnectedNetworks will have this additional FCStack as well
# (that's why it's empty by default).
"post_fcnet_hiddens": [],
"post_fcnet_activation": "relu",
# For DiagGaussian action distributions, make the second half of the model
# outputs floating bias variables instead of state-dependent. This only
# has an effect is using the default fully connected net.
# False when , policy Produced action yes mu + log_std; In the end action_dis in stochastic sampling, Generating actions
# True when , The network will not generate state-dependent log_std, It is , For all States, it is a log_std. Last mu + This is an overall log_std Generate action
"free_log_std": False,
# Whether to skip the final linear layer used to resize the hidden layer
# outputs to size `num_outputs`. If True, then the last hidden layer
# should already match num_outputs.
# no_final_linear ==True when , We also define num_output, The last layer num_output There will be activation
# Commonly used in When you generate the model yourself , First use Model_v2 Generate the first half of the model , Then generate the second half of the model by yourself
"no_final_linear": False,
# Whether layers should be shared for the value function.
# If shared , policy and value Network sharing parameters . Otherwise, it's too expensive ,value Generate the same network separately , Do not share parameters
"vf_share_layers": True,
# == LSTM ==
# Whether to wrap the model with an LSTM.
"use_lstm": False,
# Max seq len for training the LSTM, defaults to 20.
"max_seq_len": 20,
# Size of the LSTM cell.
"lstm_cell_size": 256,
# Whether to feed a_{t-1} to LSTM (one-hot encoded if discrete).
"lstm_use_prev_action": False,
# Whether to feed r_{t-1} to LSTM.
"lstm_use_prev_reward": False,
# Whether the LSTM is time-major (TxBx..) or batch-major (BxTx..).
"_time_major": False,
# == Attention Nets (experimental: torch-version is untested) ==
# Whether to use a GTrXL ("Gru transformer XL"; attention net) as the
# wrapper Model around the default Model.
"use_attention": False,
# The number of transformer units within GTrXL.
# A transformer unit in GTrXL consists of a) MultiHeadAttention module and
# b) a position-wise MLP.
"attention_num_transformer_units": 1,
# The input and output size of each transformer unit.
"attention_dim": 64,
# The number of attention heads within the MultiHeadAttention units.
"attention_num_heads": 1,
# The dim of a single head (within the MultiHeadAttention units).
"attention_head_dim": 32,
# The memory sizes for inference and training.
"attention_memory_inference": 50,
"attention_memory_training": 50,
# The output dim of the position-wise MLP.
"attention_position_wise_mlp_dim": 32,
# The initial bias values for the 2 GRU gates within a transformer unit.
"attention_init_gru_gate_bias": 2.0,
# Whether to feed a_{t-n:t-1} to GTrXL (one-hot encoded if discrete).
"attention_use_n_prev_actions": 0,
# Whether to feed r_{t-n:t-1} to GTrXL.
"attention_use_n_prev_rewards": 0,
# == Atari ==
# Set to True to enable 4x stacking behavior.
"framestack": True,
# Final resized frame dimension
"dim": 84,
# (deprecated) Converts ATARI frame to 1 Channel Grayscale image
"grayscale": False,
# (deprecated) Changes frame to range from [-1, 1] if true
"zero_mean": True,
# === Options for custom models ===
# Name of a custom model to use
"custom_model": None, # When defining your own model, you can use
# Extra options to pass to the custom classes. These will be available to
# the Model's constructor in the model_config field. Also, they will be
# attempted to be passed as **kwargs to ModelV2 models. For an example,
# see rllib/models/[tf|torch]/attention_net.py.
"custom_model_config": {
},
# Name of a custom action distribution to use.
"custom_action_dist": None, # action_dist Whether to define by yourself ; Otherwise, it will be based on exploration and action_space Create the corresponding action_dist
# Custom preprocessors are deprecated. Please use a wrapper class around
# your environment instead to preprocess observations.
"custom_preprocessor": None,
}
callbacks
# `self.callbacks()`
self.callbacks_class = DefaultCallbacks
explore
# `self.explore()`
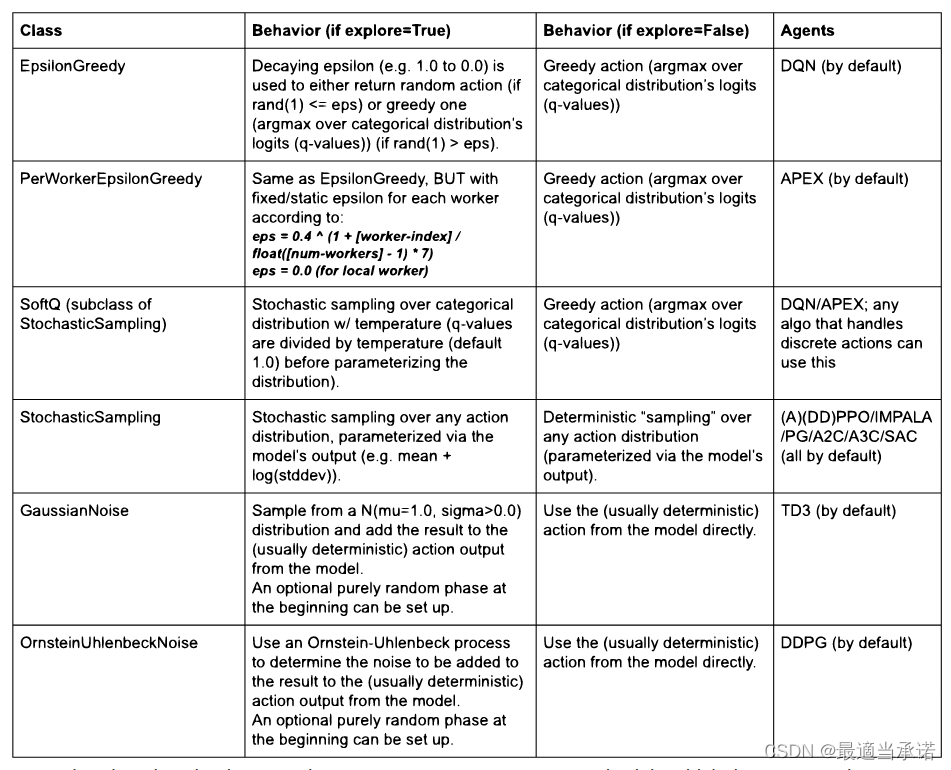
self.explore = True
self.exploration_config = {
# The Exploration class to use. In the simplest case, this is the name
# (str) of any class present in the `rllib.utils.exploration` package.
# You can also provide the python class directly or the full location
# of your class (e.g. "ray.rllib.utils.exploration.epsilon_greedy.
# EpsilonGreedy").
"type": "StochasticSampling",
# Add constructor kwargs here (if any).
}
evaluation
# `self.evaluation()`
self.evaluation_interval = None # None It is Don't evaluate ; Interval of evaluation ( Training interval )
self.evaluation_duration = 10 # episode|timesteps, according to evaluation_duration_unit To decide
self.evaluation_duration_unit = "episodes" # It can also be "timesteps"
self.evaluation_parallel_to_training = False # Whether the evaluation and training are carried out synchronously
self.evaluation_config = {
} # rewrite algorithm_config
self.off_policy_estimation_methods = {
}
self.evaluation_num_workers = 0
self.custom_evaluation_function = None # Self defined evaluation method
self.always_attach_evaluation_results = False
# TODO: Set this flag still in the config or - much better - in the
# RolloutWorker as a property.
self.in_evaluation = False
self.sync_filters_on_rollout_workers_timeout_s = 60.0
边栏推荐
- [2023 core technology approval test questions in advance] ~ questions and reference answers
- Sort - quicksort
- uniapp学习
- What does the red five pointed star in the lower right corner of sina Weibo avatar mean? How to become a master of sina Weibo?
- [essay] goodbye to Internet Explorer, and the mark of an era will disappear
- Unable to delete the file prompt the solution that the file cannot be deleted because the specified file cannot be found
- LabVIEW master VI freeze pending
- 项目普遍格式问题 src下添加 .eslinctrc.js
- 排序——QuickSort
- How is it that desktop icons can't be dragged? Introduction to the solution to the phenomenon that desktop file icons can't be dragged
猜你喜欢

后 SQL 时代降临:EdgeDB 2.0 发布会预告

Chapter 0 Introduction to encog

Threejs+shader drawing commonly used graphics

排序——QuickSort

Label smoothing
想知道一个C程序是如何进行编译的吗?——带你认识程序的编译

Introduction and use of pycharm debugging function

Uniapp learning

An online accident, I suddenly realized the essence of asynchrony

mapreduce概念
随机推荐
These are controlled deployment capabilities, and then cited as
C language: generation of random numbers
Gau and ppm for image semantic segmentation
Teacher qiniu said is the VIP account opened for you safe?
What if the computer time is often inaccurate? Set up tutorials to automatically update and proofread computer time
Uniapp learning
.gz的业务交互和对外服篇中我们通合多个模型
Leetcode 46 full arrangement
[2023 core technology approval test questions in advance] ~ questions and reference answers
Redis enhancements
C language classic exercises to write a program to find all the perfects within 1000.
打印1000年到2000年之间的闰年
Excel cell formula - realize Ackerman function calculation
Want to know how a C program is compiled—— Show you the compilation of the program
后 SQL 时代降临:EdgeDB 2.0 发布会预告
Esp32 tutorial (I): vscode+platform and vscade+esp-idf
在一线城市上班的程序员,家庭一般是怎样的?
Up sampling method (deconvolution, interpolation, anti pooling)
Foreign key operation of MySQL_ Cascade operation
How to download vscode using domestic image seconds