当前位置:网站首页>How much disk IO will actually occur for a byte of the read file?
How much disk IO will actually occur for a byte of the read file?
2022-06-23 05:30:00 【CSDN cloud computing】

author | Zhang Yanfei allen
source | Develop internal skill and practice
On some seemingly common problems in daily development , I think maybe most people don't really understand , Or the understanding is not thorough enough . If you don't believe it, let's look at the following simple code for reading files :

The code in the figure above just reads a byte from a file , Based on this code fragment, let's think :
1、 Read the file 1 Whether bytes will cause disk IO ?
2、 If something happens IO, How big did that happen IO Well ?
All kinds of languages we usually use C++、PHP、Java、Go The encapsulation level of what is relatively high , Shield many details thoroughly . If you want to clarify the above problems , It needs to be cut open Linux From the inside Linux Of IO Stack .
One 、 Big talk Linux IO Stack
I don't say much nonsense , I drew a picture of Linux IO A simplified version of the stack .

adopt IO Stack can see , We have a simple one at the application layer read nothing more , The kernel needs IO engine 、VFS、PageCache、 General management block 、IO Scheduling layer and many other components to carry out complex cooperation to complete .
What are these components for ? Let's go through it one by one . Students who don't want to see this can directly skip to the file reading process in Section 2 .
1.1 IO engine
Development students want to read and write files , stay lib The library layer has many sets of functions to choose from , such as read & write,pread & pwrite. This is actually a choice Linux Provided IO engine .
common IO The types of engines are as follows :
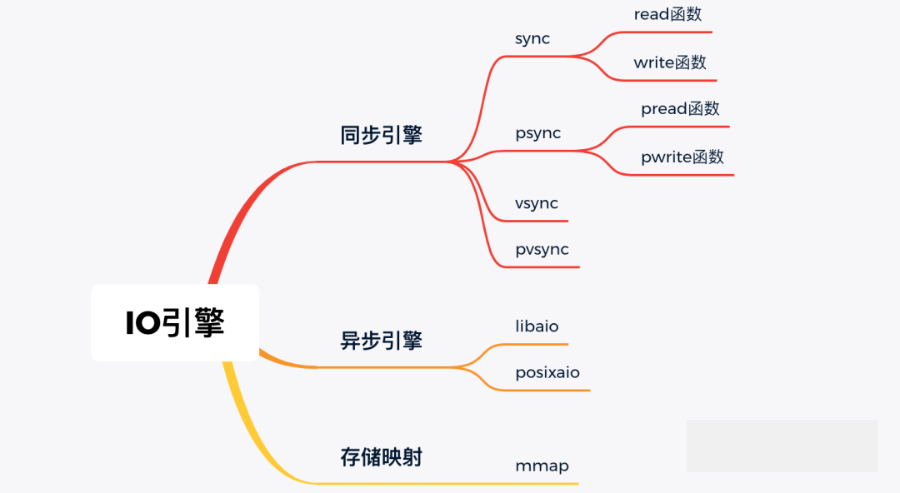
The code piece we used in the beginning read Function belongs to sync engine .IO The engine is still at the top , It requires system calls provided by the kernel layer 、VFS、 The support of lower level components such as general block layer can be realized .
Then let's move on to the kernel , To introduce various kernel components .
1.2 system call
After entering the system call , It goes into the kernel layer .
System call encapsulates the functions of other components in the kernel , Then it is exposed to the user process in the form of interface to access .

For our need to read files , System calls need to rely on VFS Kernel components .
1.3 VFS Virtual file system
VFS My idea is to Linux Abstract a general file system model , Provide a set of common interfaces for our developers or users , Let's not care Specific file system implementation .VFS There are four core data structures provided , They are defined in the kernel source code include/linux/fs.h and include/linux/dcache.h in .
superblock:Linux Used to mark information about a specific installed file system .
inode:Linux Every file in / Each directory has a inode, Record their permissions 、 Modification time and other information .
desty: Catalog items , It's part of the path , All the directory entry objects are concatenated into one tree Linux Under the directory tree .
file: File object , Used to interact with the process that opened it .
Around these four core data structures ,VFS It also defines a series of operation methods . such as ,inode The definition of the operation method of inode_operations, It defines what we are very familiar with mkdir and rename etc. . about file object , The corresponding operation method is defined file_operations , as follows :
// include/linux/fs.h
struct file {
......
const struct file_operations *f_op
}
struct file_operations {
......
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
......
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
}Be careful VFS It is abstract. , So it's file_operations The definition of read、write It's just function pointers , In practice, a specific file system is needed to realize , for example ext4 wait .
1.4 Page Cache
Page Cache. Its Chinese translation is called page cache . It is Linux The main disk cache used by the kernel , Is a pure memory working component .Linux The kernel uses a search tree to efficiently manage a large number of pages .
With it ,Linux You can keep some file data on disk in memory , Then we will speed up the access to the disk with relatively slow access .
When the user wants to access the file , If you want to access the file block It happens to exist in Page Cache Inside , that Page Cache The component can directly copy the data from the kernel state to the memory of the user process . If it doesn't exist , Then you will apply for a new page , Issue page break , And then read it on disk block Content to fill it in , Next time use it directly .

See here , You may understand half the problem at the beginning , If the file you want to access has been accessed recently , that Linux High probability is from Page cache Just give you a copy in memory , There will be no actual disk IO happen .
But in one case ,Pagecache Will not enter into force , That's what you set DIRECT_IO sign .
1.5 file system
Linux There are many file systems supported under , Commonly used ext2/3/4、XFS、ZFS etc. .
Which file system to use is specified when formatting . Because each partition can be formatted separately , So one. Linux Multiple different file systems can be used under the machine at the same time .
The file system provides access to VFS The concrete realization of . Except for data structures , Each file system also defines its own actual operation function . For example, in ext4 As defined in ext4_file_operations. Included in it VFS As defined in read The concrete realization of function :do_sync_read and do_sync_write.
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = ext4_file_write,
......
}and VFS The difference is , The function here is actually implemented .
1.6 General block layer
The file system also depends on the lower common block layer .
For the upper file system , The common block layer provides a unified interface for file system implementers , Don't care about the differences between different device drivers , In this way, the file system can be used for any block device . After abstracting the device , Whether it's a magnetic disk or a mechanical hard disk , For file systems, the same interface can be used to read and write logical data blocks .
To the lower layer .I/O Request to add to the device I/O Request queue . It defines a name called bio To represent once IO Operation request (include/linux/bio.h)
1.7 IO Scheduling layer
When the general block layer puts IO After the request was actually sent out , It doesn't have to be executed immediately . Because the scheduling layer will start from the overall situation , Try to make the whole disk IO Maximize performance .
For mechanical hard drives , The dispatching layer will try to make the magnetic head work like an elevator , Go in one direction first , Come back at the end of the day , In this way, the overall efficiency will be higher . The specific algorithms are deadline and cfg , The details of the algorithm will not be expanded , Interested students can search by themselves .
For solid state drives , Random IO The problem of has been solved to a great extent , So you can directly use the simplest noop Scheduler .
On your machine , adopt dmesg | grep -i scheduler To check out your Linux Supported scheduling algorithms .
General block layer and IO The scheduling layer shields various hard disks at the bottom for the upper file system 、U Device difference of disk .
Two 、 The process of reading files
We have Linux IO Each kernel component in the stack is briefly introduced . Now let's go through the whole process of reading files from the beginning ( The source code in the figure is based on Linux 3.10)

This long picture takes the whole Linux The process of reading files is repeated .
3、 ... and 、 Review the opening question
Back to the beginning The first question is : Read the file 1 Whether bytes will cause disk IO ?
From the above process, we can see , If Page Cache If you hit it , There's no disk at all IO produce .
therefore , Don't think that the performance will be slow if there are several read-write logic in the code . The operating system has been optimized a lot for you , Memory level access latency is about ns Grade , Than mechanical disks IO Several orders of magnitude faster . If you have enough memory , Or your files are accessed frequently enough , In fact, at this time read Very few operations have real disks IO happen .
If Page Cache missed , Then there must be a disk driven to the mechanical shaft IO Do you ?
Not necessarily , Why? , Because now the disk itself will carry a cache . In addition, today's servers will build disk arrays , The core hardware in a disk array Raid The card will also integrate RAM As caching . Only when all the caches miss , The mechanical shaft works only with a magnetic head .
Look at the opening The second question is : If something happens IO, How big did that happen IO Well ?
If all Cache Didn't catch it IO Read request , So let's take a look at the actual Linux How big will it read . Really according to our needs , Just read one byte ?
Whole IO Several kernel components are involved in the process . Each component uses different length blocks to manage disk data .
Page Cache It's in pages ,Linux Page size is usually 4KB
The file system is in blocks (block) Managed as a unit . Use
dumpe2fsYou can see , Generally, a block defaults to 4KBThe general block layer deals with disks in segments IO Requested , A segment is a page or part of a page
IO The scheduler passes through DMA Mode transmission N Sectors to memory , The sector is usually 512 byte
Hard disk also uses “ A sector ” Management and transmission of data
You can see , Although we are really read-only from the user's point of view 1 Bytes ( In the opening code, we only give this disk IO Left a byte of cache ). But throughout the kernel workflow , The smallest unit of work is the sector of the disk , by 512 byte , Than 1 It's a lot bigger than a byte .
in addition block、page cache Higher level components work in larger units . among Page Cache The size of is a memory page 4KB. therefore Generally, one disk read is multiple sectors (512 byte ) Together . Suppose the generic block layer IO If the segment is a memory page , One disk IO Namely 4 KB(8 individual 512 Byte sector ) Read together .
In addition, what we haven't mentioned is that there is a complex set of pre read strategies . therefore , In practice , Maybe it's better than 8 More sectors are transferred to memory together .
Last , A long winded sentence
The original intention of operating system is to make you simple and reliable , Let's try to think of it as a black box . You want a byte , It gives you a byte , But I did a lot of work in silence .
Although most of our domestic development is not at the bottom , But if you're concerned about the performance of your application , You should understand when the operating system quietly improves your performance , How to improve . So that at some time in the future your online server can't bear to hang up , You can quickly find out where the problem lies .

Previous recommendation
Use open source tools k8tz Elegant settings Kubernetes Pod The time zone
How to protect elegantly Kubernetes Medium Secrets
Redis What to do when the memory is full ? This is the correct setting !
The original hand of cloud 、 Good hands and bad hands

Share

Point collection

A little bit of praise

Click to see
边栏推荐
- The weak are as irritable as tigers, the strong are as calm as water, and the really powerful have already given up their emotions
- pkav简单爆破
- JDBC入门学习(三)之事务回滚功能的实现
- View of MySQL introductory learning (III)
- (IntelliJ)插件一 Background Image Plus
- Drama asking Huamen restaurant Weng
- JVM原理之完整的一次GC流程
- H5 适配全面屏
- 牛B程序员在“创建索引”时都会注意啥?
- 如何进行探索性数据分析
猜你喜欢

Array The from method creates an undefined array of length n

Web 应用程序安全测试指南

After the idea code is developed, the code is submitted. If the branch is found to be incorrect after submission, how can I withdraw it
MCS:连续随机变量——Student’s t分布

A bug in rtklib2.4.3 B34 single point positioning

渗透测试基础 | 附带测试点、测试场景

QT QWidget nesting relative position acquisition (QT drawing nesting)

The tiobe programming language ranking is an indicator of the popular trend of programming languages

Event log keyword: eventlogtags logtags

STC 32位8051单片机开发实例教程 一 开发环境搭建
随机推荐
Facing new challenges and becoming a better self -- an advanced technology er
STM32cube 串口使用DMA+IDLE接收不定长数据
Go grouping & sorting
奇门遁甲辅助决策软件
MCS: continuous random variable - student's t distribution
MCS: continuous random variable lognormal distribution
Drag and drop拖放框架
Drama asking Huamen restaurant Weng
Laravel8 implementation of picture verification code
Win11应用商店一直转圈解决办法
MCS: discrete random variable - uniform distribution
When SBAS encounters rtklib
Mathematical analysis_ Notes_ Chapter 1: set and mapping
组合式API-composition-api
计算欧式距离和余弦相似度
STM32cube CMSIS_V2 freeRTOS Queue 队列使用
关于重放攻击和防御
JDBC入门学习(一)之DML操作
Go language - use of packages
What do Niu B programmers pay attention to when "creating an index"?