当前位置:网站首页>Pyspark on HPC (Continued): reasonable partition processing and consolidated output of a single file
Pyspark on HPC (Continued): reasonable partition processing and consolidated output of a single file
2022-06-23 08:13:00 【flavorfan】
stay HPC Start task on to local Mode run custom spark, Free choice spark、python Version combination to process data ; Start multiple tasks to process independent partition data in parallel , As long as the processing resources are sufficient , The only thing that limits the speed is the disk io. Local cluster processing requires 2 Weekly data ,2 It'll be done in an hour .HPC Usually there is no database , further BI The presentation or processing needs to be pulled back to the local cluster , At this time, the data block ( Such as a day ) Save your data as tsv.gz Pull back to the local cluster .pyspark dataframe Provide write Of save Method , Can write tsv.gz,spark The default is parallel write , So it's offering outpath Write multiple files under the directory . This is the time , It is necessary to splice several in sequence tsv File and compressed to gz Format .
1. process_to_tsv_path
from pyspark.sql import SparkSession
def process_to_tsv_path(spark, in_file, out_csv_path,tasks=8):
result = (
spark.read.csv(in_file, sep="\t", quote=None, header=True)
.repartition(tasks)
.where(...)
.select(...)
.write.format("com.databricks.spark.csv").save(out_csv_path)
)
return resultrepartition After reading the input file , And according to the file size and application cpu、MEM Proper setting of number ; This will out_csv_path Generate corresponding tasks individual csv file . If you put repartition Output after processing write Before , Then the previous processing has only one partition , Only one... Can be called cpu nucleus ( Corresponding to the number of input files ), Waste calculation . Do a comparative experiment , The author's data processing situation is probably different 5 times .
2. tsv_path_to_gz
import glob, gzip
def tsv_path_to_gz(out_csv_path, tar_file):
interesting_files = sorted(glob.glob(f'{out_csv_path}/*.csv'))
with gzip.open(tar_file, 'wb') as f_out:
for file_name in interesting_files:
with open(file_name, 'rb') as f_in:
f_out.writelines(f_in)边栏推荐
- socket编程——select模型
- 2 corrections de bogues dans l'outil aquatone
- Image segmentation - improved network structure
- Odoo project sends information to wechat official account or enterprise wechat
- Ad object of Active Directory
- Map接口及其子实现类
- C# richTextBox控制最大行数
- Two bug fixes in aquatone tool
- 配置ASMX无法访问
- 生产环境服务器环境搭建+项目发布流程
猜你喜欢

转盘式视觉筛选机及其图像识别系统

qt 不规则图形 消除锯齿

Deep learning ----- different methods to implement lenet-5 model

How to start Jupiter notebook in CONDA virtual environment
深度学习------不同方法实现lenet-5模型
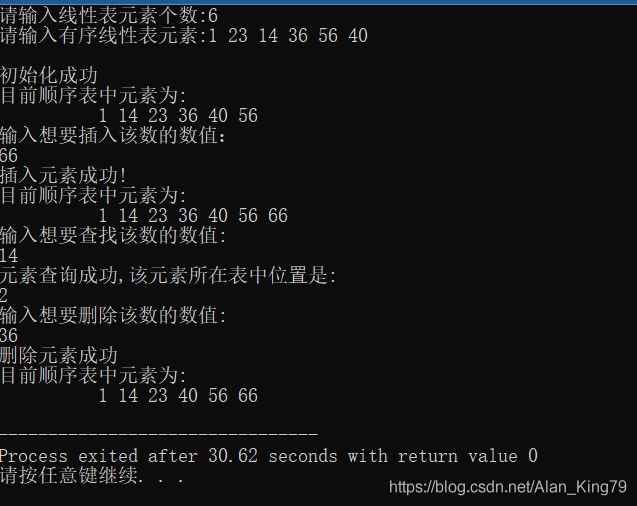
建立一有序的顺序表,并实现下列操作: 1.把元素x插入表中并保持有序; 2.查找值为x的元素,若找到将其删除; 3.输出表中各元素的值。
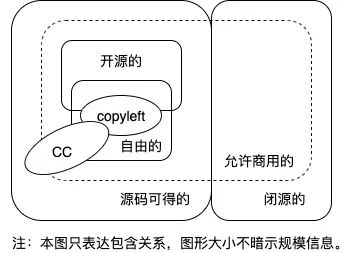
What are open source software, free software, copyleft and CC? Can't you tell them clearly?

【Try to Hack】ip地址

船长阿布的灵魂拷问

Openvino series 19 Openvino and paddleocr for real-time video OCR processing
随机推荐
openvino系列 19. OpenVINO 与 PaddleOCR 实现视频实时OCR处理
Vulnhub | DC: 3 |【实战】
typeScript的介绍与变量定义的基本类型
【Try to Hack】ip地址
Markdown learning
PHP serialization and deserialization CTF
C#打印缩放
APM performance monitoring practice of jubasha app
MySQL slow query record
transform的结构及用法
socket编程(多进程)
C# scrollView 向上滚动还是向下滚动
Do not put files with garbled names into the CFS of NFS protocol
Hackers use new PowerShell backdoors in log4j attacks
转盘式视觉筛选机及其图像识别系统
Imperva- method of finding regular match timeout
Match 56 de la semaine d'acwing [terminé]
How to mine keywords and improve user experience before website construction?
Set接口和Set子实现类
图像分割-改进网络结构