当前位置:网站首页>【Flink】Flink源码分析——批处理模式JobGraph的创建
【Flink】Flink源码分析——批处理模式JobGraph的创建
2022-06-26 03:35:00 【九师兄】

1.概述
转载:Flink源码分析——批处理模式JobGraph的创建 仅供自己学习。
Flink不管是流处理还是批处理都是将我们的程序编译成JobGraph进行提交的,之前我们分析过流处理模式下的JobGraph创建,现在我们来分析一下批处理模式下的JobGraph创建。
本文以本地模式为例,分析JobGraph的创建
我们仍然以WordCount为例子来分析JobGraph的创建过程,WordCount代码
val env = ExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.getConfig.setExecutionMode(ExecutionMode.BATCH)
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?",
"li wen tao li wen tao li wen tao"
)
text.flatMap {
_.toLowerCase.split("\\W+").filter{
_.nonEmpty } }
.map {
(_, 1) }
.groupBy(0)
.sum(1)
.writeAsText("D:\\IDEASPARK\\flink\\wordcount", WriteMode.OVERWRITE)
env.execute()
这个WordCount执行之后生成的DataSet关系图如下所示:
DataSource ——> FlatMapOperator ——> MapOperator ——> ScalaAggregateOperator ——> DataSink
注意这里的Operator并非是指算子层面的operator,而是在数据集层面的operator,这些operator也还是DataSet的子类型(DataSink除外)
首先看一下执行入口,在本地模式下,会执行LocalEnvironment.execute()方法,先创建执行计划Plan,再开始执行这个计划
//LocalEnvironment
public JobExecutionResult execute(String jobName) throws Exception {
if (executor == null) {
startNewSession();
}
Plan p = createProgramPlan(jobName);
// Session management is disabled, revert this commit to enable
//p.setJobId(jobID);
//p.setSessionTimeout(sessionTimeout);
JobExecutionResult result = executor.executePlan(p);
this.lastJobExecutionResult = result;
return result;
}
这个执行计划Plan很简单,里面只包含了一些sinks,先创建执行计划的过程就是将WordCount代码中创建的每个DataSet转换成对应算子层面的operator。
2.创建执行计划Plan
首先我们来看看createProgramPlan()源码实现
//ExecutionEnvironment
public Plan createProgramPlan(String jobName, boolean clearSinks) {
...
//创建一个translator转换器,从sink开始转换
OperatorTranslation translator = new OperatorTranslation();
Plan plan = translator.translateToPlan(this.sinks, jobName);
...
return plan;
}
//OperatorTranslation
public Plan translateToPlan(List<DataSink<?>> sinks, String jobName) {
List<GenericDataSinkBase<?>> planSinks = new ArrayList<>();
//从sink开始进行向上的深度优先遍历
for (DataSink<?> sink : sinks) {
planSinks.add(translate(sink));
}
Plan p = new Plan(planSinks);
p.setJobName(jobName);
return p;
}
private <T> GenericDataSinkBase<T> translate(DataSink<T> sink) {
// translate the input recursively
//从sink开始递归的向上去进行转换
Operator<T> input = translate(sink.getDataSet());
// translate the sink itself and connect it to the input
GenericDataSinkBase<T> translatedSink = sink.translateToDataFlow(input);
translatedSink.setResources(sink.getMinResources(), sink.getPreferredResources());
return translatedSink;
}
private <T> Operator<T> translate(DataSet<T> dataSet) {
while (dataSet instanceof NoOpOperator) {
dataSet = ((NoOpOperator<T>) dataSet).getInput();
}
// check if we have already translated that data set (operation or source)
Operator<?> previous = this.translated.get(dataSet);
if (previous != null) {
... //已经转换过了
}
Operator<T> dataFlowOp;
if (dataSet instanceof DataSource) {
DataSource<T> dataSource = (DataSource<T>) dataSet;
dataFlowOp = dataSource.translateToDataFlow();
dataFlowOp.setResources(dataSource.getMinResources(), dataSource.getPreferredResources());
}
else if (dataSet instanceof SingleInputOperator) {
SingleInputOperator<?, ?, ?> singleInputOperator = (SingleInputOperator<?, ?, ?>) dataSet;
dataFlowOp = translateSingleInputOperator(singleInputOperator);
dataFlowOp.setResources(singleInputOperator.getMinResources(), singleInputOperator.getPreferredResources());
}
else if (dataSet instanceof TwoInputOperator) {
TwoInputOperator<?, ?, ?, ?> twoInputOperator = (TwoInputOperator<?, ?, ?, ?>) dataSet;
dataFlowOp = translateTwoInputOperator(twoInputOperator);
dataFlowOp.setResources(twoInputOperator.getMinResources(), twoInputOperator.getPreferredResources());
}else if
...
this.translated.put(dataSet, dataFlowOp);
// take care of broadcast variables
translateBcVariables(dataSet, dataFlowOp);
return dataFlowOp;
}
private <I, O> org.apache.flink.api.common.operators.Operator<O> translateSingleInputOperator(SingleInputOperator<?, ?, ?> op) {
@SuppressWarnings("unchecked")
SingleInputOperator<I, O, ?> typedOp = (SingleInputOperator<I, O, ?>) op;
@SuppressWarnings("unchecked")
DataSet<I> typedInput = (DataSet<I>) op.getInput();
//在遇到SingleInputOperator节点是继续向上递归,那么整个的递归过程就是从sink后续遍历,先转换source,再依次向下进行转换
Operator<I> input = translate(typedInput);
org.apache.flink.api.common.operators.Operator<O> dataFlowOp = typedOp.translateToDataFlow(input);
...
return dataFlowOp;
}
大致实现就是从sink开始进行向上递归的转换,整个的递归过程就是从sink进行深度优化遍历,先转换source,再依次向下进行转换,转换的方法就是调用每个DataSet(或者DataSink)的translateToDataFlow()方法,将DataSet转换成算子层面的Operator,然后将上一级转换后的Operator当做输入input。
下面看一下每种DataSet(或DataSink)的translateToDataFlow()方法
//
protected GenericDataSourceBase<OUT, ?> translateToDataFlow() {
String name = this.name != null ? this.name : "at " + dataSourceLocationName + " (" + inputFormat.getClass().getName() + ")";
if (name.length() > 150) {
name = name.substring(0, 150);
}
@SuppressWarnings({
"unchecked", "rawtypes"})
GenericDataSourceBase<OUT, ?> source = new GenericDataSourceBase(this.inputFormat,
new OperatorInformation<OUT>(getType()), name);
source.setParallelism(parallelism);
if (this.parameters != null) {
source.getParameters().addAll(this.parameters);
}
if (this.splitDataProperties != null) {
source.setSplitDataProperties(this.splitDataProperties);
}
return source;
}
//MapOperator
protected MapOperatorBase<IN, OUT, MapFunction<IN, OUT>> translateToDataFlow(Operator<IN> input) {
String name = getName() != null ? getName() : "Map at " + defaultName;
// create operator
MapOperatorBase<IN, OUT, MapFunction<IN, OUT>> po = new MapOperatorBase<IN, OUT, MapFunction<IN, OUT>>(function,
new UnaryOperatorInformation<IN, OUT>(getInputType(), getResultType()), name);
// set input
po.setInput(input);
// set parallelism
if (this.getParallelism() > 0) {
// use specified parallelism
po.setParallelism(this.getParallelism());
} else {
// if no parallelism has been specified, use parallelism of input operator to enable chaining
po.setParallelism(input.getParallelism());
}
return po;
}
//ScalaAggregateOperator
protected org.apache.flink.api.common.operators.base.GroupReduceOperatorBase<IN, IN, GroupReduceFunction<IN, IN>> translateToDataFlow(Operator<IN> input) {
// sanity check
if (this.aggregationFunctions.isEmpty() || this.aggregationFunctions.size() != this.fields.size()) {
throw new IllegalStateException();
}
// construct the aggregation function
AggregationFunction<Object>[] aggFunctions = new AggregationFunction[this.aggregationFunctions.size()];
int[] fields = new int[this.fields.size()];
StringBuilder genName = new StringBuilder();
for (int i = 0; i < fields.length; i++) {
aggFunctions[i] = (AggregationFunction<Object>) this.aggregationFunctions.get(i);
fields[i] = this.fields.get(i);
genName.append(aggFunctions[i].toString()).append('(').append(fields[i]).append(')').append(',');
}
genName.setLength(genName.length() - 1);
@SuppressWarnings("rawtypes")
RichGroupReduceFunction<IN, IN> function = new AggregatingUdf(getInputType(), aggFunctions, fields);
String name = getName() != null ? getName() : genName.toString();
// distinguish between grouped reduce and non-grouped reduce
//这种是针对未分组的reduce
if (this.grouping == null) {
// non grouped aggregation
UnaryOperatorInformation<IN, IN> operatorInfo = new UnaryOperatorInformation<>(getInputType(), getResultType());
GroupReduceOperatorBase<IN, IN, GroupReduceFunction<IN, IN>> po =
new GroupReduceOperatorBase<IN, IN, GroupReduceFunction<IN, IN>>(function, operatorInfo, new int[0], name);
po.setCombinable(true);
// set input
po.setInput(input);
// set parallelism
po.setParallelism(this.getParallelism());
return po;
}
//这种是针对的是分组的reduce,我们的WordCount代码走这里
if (this.grouping.getKeys() instanceof Keys.ExpressionKeys) {
// grouped aggregation
int[] logicalKeyPositions = this.grouping.getKeys().computeLogicalKeyPositions();
UnaryOperatorInformation<IN, IN> operatorInfo = new UnaryOperatorInformation<>(getInputType(), getResultType());
GroupReduceOperatorBase<IN, IN, GroupReduceFunction<IN, IN>> po =
new GroupReduceOperatorBase<IN, IN, GroupReduceFunction<IN, IN>>(function, operatorInfo, logicalKeyPositions, name);
//默认就开启combiner了,数据预先进行聚合,减少数据传输
po.setCombinable(true);
// set input
po.setInput(input);
// set parallelism
po.setParallelism(this.getParallelism());
SingleInputSemanticProperties props = new SingleInputSemanticProperties();
for (int keyField : logicalKeyPositions) {
boolean keyFieldUsedInAgg = false;
for (int aggField : fields) {
if (keyField == aggField) {
keyFieldUsedInAgg = true;
break;
}
}
if (!keyFieldUsedInAgg) {
props.addForwardedField(keyField, keyField);
}
}
po.setSemanticProperties(props);
po.setCustomPartitioner(grouping.getCustomPartitioner());
return po;
}
else if (this.grouping.getKeys() instanceof Keys.SelectorFunctionKeys) {
throw new UnsupportedOperationException("Aggregate does not support grouping with KeySelector functions, yet.");
}
else {
throw new UnsupportedOperationException("Unrecognized key type.");
}
}
//DataSink
protected GenericDataSinkBase<T> translateToDataFlow(Operator<T> input) {
// select the name (or create a default one)
String name = this.name != null ? this.name : this.format.toString();
GenericDataSinkBase<T> sink = new GenericDataSinkBase<>(this.format, new UnaryOperatorInformation<>(this.type, new NothingTypeInfo()), name);
// set input
sink.setInput(input);
// set parameters
if (this.parameters != null) {
sink.getParameters().addAll(this.parameters);
}
// set parallelism
if (this.parallelism > 0) {
// use specified parallelism
sink.setParallelism(this.parallelism);
} else {
// if no parallelism has been specified, use parallelism of input operator to enable chaining
sink.setParallelism(input.getParallelism());
}
if (this.sortKeyPositions != null) {
// configure output sorting
Ordering ordering = new Ordering();
for (int i = 0; i < this.sortKeyPositions.length; i++) {
ordering.appendOrdering(this.sortKeyPositions[i], null, this.sortOrders[i]);
}
sink.setLocalOrder(ordering);
}
return sink;
}
经过转换,上述WordCount转换成的算子层面的Operator就如下所示:
GenericDataSourceBase --> FlatMapOperatorBase --> MapOperatorBase --> GroupReduceOperatorBase --> GenericDataSinkBase
上级operator作为下级operator的input,这样一级一级的进行链接起来。
3.编译成OptimizedPlan
接下来就到了执行这个计划的代码了,也就是executor.executePlan§,关于JobGraph的实现大致如下:
创建一个优化器,对Plan进行优化,编译成OptimizedPlan
创建JobGraph生成器,再对OptimizedPlan进行编译成JobGraph
public JobExecutionResult executePlan(Plan plan) throws Exception {
if (plan == null) {
throw new IllegalArgumentException("The plan may not be null.");
}
synchronized (this.lock) {
... //启动本地集群环境
try {
// TODO: Set job's default parallelism to max number of slots
final int slotsPerTaskManager = jobExecutorServiceConfiguration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS, taskManagerNumSlots);
final int numTaskManagers = jobExecutorServiceConfiguration.getInteger(ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 1);
plan.setDefaultParallelism(slotsPerTaskManager * numTaskManagers);
//下面几行代码是JobGraph创建的关键过程
Optimizer pc = new Optimizer(new DataStatistics(), jobExecutorServiceConfiguration);
OptimizedPlan op = pc.compile(plan);
JobGraphGenerator jgg = new JobGraphGenerator(jobExecutorServiceConfiguration);
JobGraph jobGraph = jgg.compileJobGraph(op, plan.getJobId());
return jobExecutorService.executeJobBlocking(jobGraph);
}
finally {
if (shutDownAtEnd) {
stop();
}
}
}
}
4.优化器Optimizer
优化器Optimizer对原始计划进行编译,编译的过程大致实现如下:
创建
GraphCreatingVisitor,对原始的Plan进行优化,将每个operator优化成OptimizerNode,OptimizerNode之间通过DagConnection相连,DagConnection相当于一个边模型,有source和target,可以表示OptimizerNode的输入和输出对
OptimizerNode再进行优化,将每个OptimizerNode优化成PlanNode,PlanNode之间通过Channel相连,Channel也相当于是一个边模型,可以表示PlanNode的输入和输出。这个过程会做很多优化,比如对GroupReduceNode会增加combiner的节点,对Channel会设置ShipStrategyType和DataExchangeMode,ShipStrategyType表示的两个节点之间数据的传输策略,比如进行hash分区,范围分区等,DataExchangeMode表示的是两个节点间数据交换的模式,有PIPELINED和BATCH
//Optimizer类
public OptimizedPlan compile(Plan program) throws CompilerException {
final OptimizerPostPass postPasser = getPostPassFromPlan(program);
return compile(program, postPasser);
}
private OptimizedPlan compile(Plan program, OptimizerPostPass postPasser) throws CompilerException {
...
final ExecutionMode defaultDataExchangeMode = program.getExecutionConfig().getExecutionMode();
final int defaultParallelism = program.getDefaultParallelism() > 0 ?
program.getDefaultParallelism() : this.defaultParallelism;
...
//对原始的Plan进行优化,将每个operator优化成OptimizerNode
GraphCreatingVisitor graphCreator = new GraphCreatingVisitor(defaultParallelism, defaultDataExchangeMode);
program.accept(graphCreator);
// if we have a plan with multiple data sinks, add logical optimizer nodes that have two data-sinks as children
// each until we have only a single root node. This allows to transparently deal with the nodes with
// multiple outputs
OptimizerNode rootNode;
if (graphCreator.getSinks().size() == 1) {
rootNode = graphCreator.getSinks().get(0);
}
else if (graphCreator.getSinks().size() > 1) {
Iterator<DataSinkNode> iter = graphCreator.getSinks().iterator();
rootNode = iter.next();
while (iter.hasNext()) {
rootNode = new SinkJoiner(rootNode, iter.next());
}
}
else {
throw new CompilerException("Bug: The optimizer plan representation has no sinks.");
}
// now that we have all nodes created and recorded which ones consume memory, tell the nodes their minimal
// guaranteed memory, for further cost estimations. We assume an equal distribution of memory among consumer tasks
rootNode.accept(new IdAndEstimatesVisitor(this.statistics));
// We need to enforce that union nodes always forward their output to their successor.
// Any partitioning must be either pushed before or done after the union, but not on the union's output.
UnionParallelismAndForwardEnforcer unionEnforcer = new UnionParallelismAndForwardEnforcer();
rootNode.accept(unionEnforcer);
// We are dealing with operator DAGs, rather than operator trees.
// That requires us to deviate at some points from the classical DB optimizer algorithms.
// This step builds auxiliary structures to help track branches and joins in the DAG
BranchesVisitor branchingVisitor = new BranchesVisitor();
rootNode.accept(branchingVisitor);
// Propagate the interesting properties top-down through the graph
InterestingPropertyVisitor propsVisitor = new InterestingPropertyVisitor(this.costEstimator);
rootNode.accept(propsVisitor);
// perform a sanity check: the root may not have any unclosed branches
if (rootNode.getOpenBranches() != null && rootNode.getOpenBranches().size() > 0) {
throw new CompilerException("Bug: Logic for branching plans (non-tree plans) has an error, and does not " +
"track the re-joining of branches correctly.");
}
// the final step is now to generate the actual plan alternatives
//对OptimizerNode再进行优化,对每个OptimizerNode优化成PlanNode
List<PlanNode> bestPlan = rootNode.getAlternativePlans(this.costEstimator);
if (bestPlan.size() != 1) {
throw new CompilerException("Error in compiler: more than one best plan was created!");
}
// check if the best plan's root is a data sink (single sink plan)
// if so, directly take it. if it is a sink joiner node, get its contained sinks
PlanNode bestPlanRoot = bestPlan.get(0);
List<SinkPlanNode> bestPlanSinks = new ArrayList<SinkPlanNode>(4);
if (bestPlanRoot instanceof SinkPlanNode) {
bestPlanSinks.add((SinkPlanNode) bestPlanRoot);
} else if (bestPlanRoot instanceof SinkJoinerPlanNode) {
((SinkJoinerPlanNode) bestPlanRoot).getDataSinks(bestPlanSinks);
}
// finalize the plan
//创建最终的优化过的计划OptimizedPlan
OptimizedPlan plan = new PlanFinalizer().createFinalPlan(bestPlanSinks, program.getJobName(), program);
plan.accept(new BinaryUnionReplacer());
plan.accept(new RangePartitionRewriter(plan));
// post pass the plan. this is the phase where the serialization and comparator code is set
postPasser.postPass(plan);
return plan;
}
5.将Operator转换成OptimizerNode
GraphCreatingVisitor对原始Plan进行优化成OptimizerNode
首先我们来看看原始Plan进行优化成OptimizerNode的过程,代码实现在program.accept(graphCreator)
//Plan
public void accept(Visitor<Operator<?>> visitor) {
for (GenericDataSinkBase<?> sink : this.sinks) {
sink.accept(visitor);
}
}
//GenericDataSinkBase
public void accept(Visitor<Operator<?>> visitor) {
boolean descend = visitor.preVisit(this);
if (descend) {
this.input.accept(visitor);
visitor.postVisit(this);
}
}
//SingleInputOperator
public void accept(Visitor<Operator<?>> visitor) {
if (visitor.preVisit(this)) {
this.input.accept(visitor);
for (Operator<?> c : this.broadcastInputs.values()) {
c.accept(visitor);
}
visitor.postVisit(this);
}
}
//GenericDataSourceBase
public void accept(Visitor<Operator<?>> visitor) {
if (visitor.preVisit(this)) {
visitor.postVisit(this);
}
}
从代码中可以看到,整个accept()过程就是一个递归遍历的过程,有点类似于中序遍历的过程。先从sink(GenericDataSinkBase)开始,由下至上对每个operator执行visitor.preVisit()方法,再由上至下对每个operator执行visitor.postVisit()。
既然核心方法在visitor.preVisit()和visitor.postVisit(),那我们就来看看GraphCreatingVisitor的这两个方法。
preVisit()
public boolean preVisit(Operator<?> c) {
// check if we have been here before
if (this.con2node.containsKey(c)) {
return false;
}
final OptimizerNode n;
// create a node for the operator (or sink or source) if we have not been here before
if (c instanceof GenericDataSinkBase) {
DataSinkNode dsn = new DataSinkNode((GenericDataSinkBase<?>) c);
this.sinks.add(dsn);
n = dsn;
}
else if (c instanceof GenericDataSourceBase) {
n = new DataSourceNode((GenericDataSourceBase<?, ?>) c);
}
else if (c instanceof MapOperatorBase) {
n = new MapNode((MapOperatorBase<?, ?, ?>) c);
}
else if (c instanceof MapPartitionOperatorBase) {
n = new MapPartitionNode((MapPartitionOperatorBase<?, ?, ?>) c);
}
else if (c instanceof FlatMapOperatorBase) {
n = new FlatMapNode((FlatMapOperatorBase<?, ?, ?>) c);
}
else if (c instanceof FilterOperatorBase) {
n = new FilterNode((FilterOperatorBase<?, ?>) c);
}
else if (c instanceof ReduceOperatorBase) {
n = new ReduceNode((ReduceOperatorBase<?, ?>) c);
}
else if (c instanceof GroupCombineOperatorBase) {
n = new GroupCombineNode((GroupCombineOperatorBase<?, ?, ?>) c);
}
else if (c instanceof GroupReduceOperatorBase) {
n = new GroupReduceNode((GroupReduceOperatorBase<?, ?, ?>) c);
}
else if (c instanceof InnerJoinOperatorBase) {
n = new JoinNode((InnerJoinOperatorBase<?, ?, ?, ?>) c);
}
else if (c instanceof OuterJoinOperatorBase) {
n = new OuterJoinNode((OuterJoinOperatorBase<?, ?, ?, ?>) c);
}
else if (c instanceof CoGroupOperatorBase) {
n = new CoGroupNode((CoGroupOperatorBase<?, ?, ?, ?>) c);
}
else if (c instanceof CoGroupRawOperatorBase) {
n = new CoGroupRawNode((CoGroupRawOperatorBase<?, ?, ?, ?>) c);
}
else if (c instanceof CrossOperatorBase) {
n = new CrossNode((CrossOperatorBase<?, ?, ?, ?>) c);
}
else if (c instanceof BulkIterationBase) {
n = new BulkIterationNode((BulkIterationBase<?>) c);
}
else if (c instanceof DeltaIterationBase) {
n = new WorksetIterationNode((DeltaIterationBase<?, ?>) c);
}
else if (c instanceof Union){
n = new BinaryUnionNode((Union<?>) c);
}
else if (c instanceof PartitionOperatorBase) {
n = new PartitionNode((PartitionOperatorBase<?>) c);
}
else if (c instanceof SortPartitionOperatorBase) {
n = new SortPartitionNode((SortPartitionOperatorBase<?>) c);
}
else if (c instanceof BulkIterationBase.PartialSolutionPlaceHolder) {
...
}
else if (c instanceof DeltaIterationBase.WorksetPlaceHolder) {
...
}
else if (c instanceof DeltaIterationBase.SolutionSetPlaceHolder) {
...
}
else {
throw new IllegalArgumentException("Unknown operator type: " + c);
}
this.con2node.put(c, n);
// set the parallelism only if it has not been set before. some nodes have a fixed parallelism, such as the
// key-less reducer (all-reduce)
if (n.getParallelism() < 1) {
// set the parallelism
int par = c.getParallelism();
if (n instanceof BinaryUnionNode) {
// Keep parallelism of union undefined for now.
// It will be determined based on the parallelism of its successor.
par = -1;
} else if (par > 0) {
if (this.forceParallelism && par != this.defaultParallelism) {
par = this.defaultParallelism;
Optimizer.LOG.warn("The parallelism of nested dataflows (such as step functions in iterations) is " +
"currently fixed to the parallelism of the surrounding operator (the iteration).");
}
} else {
par = this.defaultParallelism;
}
n.setParallelism(par);
}
return true;
}
preVisit()方法非常简单,仅仅是判断输入Operator的类型,来创建对应的OptimizerNode,然后设置并行度
postVisit()
public void postVisit(Operator<?> c) {
OptimizerNode n = this.con2node.get(c);
// first connect to the predecessors
n.setInput(this.con2node, this.defaultDataExchangeMode);
n.setBroadcastInputs(this.con2node, this.defaultDataExchangeMode);
// if the node represents a bulk iteration, we recursively translate the data flow now
if (n instanceof BulkIterationNode) {
...
}
else if (n instanceof WorksetIterationNode) {
...
}
}
postVisit()方法也很简单,就是对每个Operator对应的OptimizerNode设置input。defaultDataExchangeMode在这里默认就是ExecutionMode.PIPELINED,也可以通过env.getConfig.setExecutionMode(ExecutionMode.BATCH)来进行设置默认的ExecutionMode。ExecutionMode表示的是两个节点间数据交换的模式,有PIPELINED和BATCH,
PIPELINED模式数据像流水线一样的进行传输,上游任务和下游任务能够同时进行生产和消费数据;BATCH模式需要等上游的任务数据全部处理完之后才会开始下游的任务,中间数据会spill到磁盘上。
下面看看每种OptimizerNode的setInput()方法
//DataSourceNode
public void setInput(Map<Operator<?>, OptimizerNode> contractToNode, ExecutionMode defaultDataExchangeMode) {
}
//SingleInputNode
public void setInput(Map<Operator<?>, OptimizerNode> contractToNode, ExecutionMode defaultExchangeMode)
throws CompilerException
{
// see if an internal hint dictates the strategy to use
final Configuration conf = getOperator().getParameters();
final String shipStrategy = conf.getString(Optimizer.HINT_SHIP_STRATEGY, null);
final ShipStrategyType preSet;
//默认情况下这里都是null
if (shipStrategy != null) {
if (shipStrategy.equalsIgnoreCase(Optimizer.HINT_SHIP_STRATEGY_REPARTITION_HASH)) {
preSet = ShipStrategyType.PARTITION_HASH;
} else if (shipStrategy.equalsIgnoreCase(Optimizer.HINT_SHIP_STRATEGY_REPARTITION_RANGE)) {
preSet = ShipStrategyType.PARTITION_RANGE;
} else if (shipStrategy.equalsIgnoreCase(Optimizer.HINT_SHIP_STRATEGY_FORWARD)) {
preSet = ShipStrategyType.FORWARD;
} else if (shipStrategy.equalsIgnoreCase(Optimizer.HINT_SHIP_STRATEGY_REPARTITION)) {
preSet = ShipStrategyType.PARTITION_RANDOM;
} else {
throw new CompilerException("Unrecognized ship strategy hint: " + shipStrategy);
}
} else {
preSet = null;
}
// get the predecessor node
Operator<?> children = ((SingleInputOperator<?, ?, ?>) getOperator()).getInput();
OptimizerNode pred;
DagConnection conn;
if (children == null) {
throw new CompilerException("Error: Node for '" + getOperator().getName() + "' has no input.");
} else {
pred = contractToNode.get(children);
conn = new DagConnection(pred, this, defaultExchangeMode);
if (preSet != null) {
conn.setShipStrategy(preSet);
}
}
// create the connection and add it
setIncomingConnection(conn);
pred.addOutgoingConnection(conn);
}
//DataSinkNode
public void setInput(Map<Operator<?>, OptimizerNode> contractToNode, ExecutionMode defaultExchangeMode) {
Operator<?> children = getOperator().getInput();
final OptimizerNode pred;
final DagConnection conn;
pred = contractToNode.get(children);
conn = new DagConnection(pred, this, defaultExchangeMode);
// create the connection and add it
this.input = conn;
pred.addOutgoingConnection(conn);
}
setInput()方法就是创建了DagConnection把OptimizerNode连接在了一起。这个DagConnection就是一个边的模型,作为下游节点OptimizerNode的输入,同时作为上游节点OptimizerNode的输出。这里的DagConnection里的ShipStrategy和ExecutionMode还都是默认情况下的,不是最终的状态。
简单看一下DagConnection的结构
public class DagConnection implements EstimateProvider, DumpableConnection<OptimizerNode> {
private final OptimizerNode source; // The source node of the connection
private final OptimizerNode target; // The target node of the connection.
private final ExecutionMode dataExchangeMode; // defines whether to use batch or pipelined data exchange
private InterestingProperties interestingProps; // local properties that succeeding nodes are interested in
private ShipStrategyType shipStrategy; // The data shipping strategy, if predefined.
private TempMode materializationMode = TempMode.NONE; // the materialization mode
private int maxDepth = -1;
private boolean breakPipeline; // whet
这样,经过优化器初步的优化,WordCount整个计划变成了如下的拓扑结构:
DataSourceNode --> FlatMapNode --> MapNode --> GroupReduceNode --> DataSinkNode
每个OptimizerNode之间通过DagConnection进行连接
6.将OptimizerNode进一步优化成PlanNode
接下来是进一步的优化,将OptimizerNode优化成PlanNode,PlanNode是最终的优化节点类型,它包含了节点的更多属性,节点之间通过Channel进行连接,Channel也是一种边模型,同时确定了节点之间的数据交换方式ShipStrategyType和DataExchangeMode,ShipStrategyType表示的两个节点之间数据的传输策略,比如是否进行数据分区,进行hash分区,范围分区等; DataExchangeMode表示的是两个节点间数据交换的模式,有PIPELINED和BATCH,和ExecutionMode是一样的,ExecutionMode决定了DataExchangeMode。
代码实现在rootNode.getAlternativePlans(),这个rootNode也就是DataSinkNode
public List<PlanNode> getAlternativePlans(CostEstimator estimator) {
// check if we have a cached version
if (this.cachedPlans != null) {
return this.cachedPlans;
}
// calculate alternative sub-plans for predecessor
//递归的向上创建PlanNode,再创建当前节点,后序遍历
List<? extends PlanNode> subPlans = getPredecessorNode().getAlternativePlans(estimator);
List<PlanNode> outputPlans = new ArrayList<PlanNode>();
final int parallelism = getParallelism();
final int inDop = getPredecessorNode().getParallelism();
final ExecutionMode executionMode = this.input.getDataExchangeMode();
final boolean dopChange = parallelism != inDop;
final boolean breakPipeline = this.input.isBreakingPipeline();
InterestingProperties ips = this.input.getInterestingProperties();
for (PlanNode p : subPlans) {
for (RequestedGlobalProperties gp : ips.getGlobalProperties()) {
for (RequestedLocalProperties lp : ips.getLocalProperties()) {
//创建Channel,并对channel进行参数化赋值
Channel c = new Channel(p);
gp.parameterizeChannel(c, dopChange, executionMode, breakPipeline);
lp.parameterizeChannel(c);
c.setRequiredLocalProps(lp);
c.setRequiredGlobalProps(gp);
// no need to check whether the created properties meet what we need in case
// of ordering or global ordering, because the only interesting properties we have
// are what we require
//创建一个SinkPlanNode,channel作为SinkPlanNode的输入
outputPlans.add(new SinkPlanNode(this, "DataSink ("+this.getOperator().getName()+")" ,c));
}
}
}
// cost and prune the plans
for (PlanNode node : outputPlans) {
estimator.costOperator(node);
}
prunePlanAlternatives(outputPlans);
this.cachedPlans = outputPlans;
return outputPlans;
}
从这个代码看到,getAlternativePlans()又是一个递归的遍历,是后续递归遍历,从上(source)到下(sink)的去创建PlanNode和Channel。getAlternativePlans()的核心就是创建PlanNode和Channel
Channel的数据结构如下,比较重要的两个参数就是ShipStrategyType和DataExchangeMode
public class Channel implements EstimateProvider, Cloneable, DumpableConnection<PlanNode> {
private PlanNode source;
private PlanNode target;
private ShipStrategyType shipStrategy = ShipStrategyType.NONE;
private DataExchangeMode dataExchangeMode;
private LocalStrategy localStrategy = LocalStrategy.NONE;
private FieldList shipKeys;
private FieldList localKeys;
private boolean[] shipSortOrder;
private boolean[] localSortOrder;
我们先来分析一下sink端创建Channel,并对channel进行参数化赋值的过程,重点在RequestedGlobalProperties.parameterizeChannel()方法。parameterizeChannel()方法就是给Channel设置ShipStrategyType和DataExchangeMode
public void parameterizeChannel(Channel channel, boolean globalDopChange,
ExecutionMode exchangeMode, boolean breakPipeline) {
...
// if we request nothing, then we need no special strategy. forward, if the number of instances remains
// the same, randomly repartition otherwise
//这些一般对应了MapNode、FilterNode等
if (isTrivial() || this.partitioning == PartitioningProperty.ANY_DISTRIBUTION) {
ShipStrategyType shipStrategy = globalDopChange ? ShipStrategyType.PARTITION_RANDOM :
ShipStrategyType.FORWARD;
DataExchangeMode em = DataExchangeMode.select(exchangeMode, shipStrategy, breakPipeline);
channel.setShipStrategy(shipStrategy, em);
return;
}
final GlobalProperties inGlobals = channel.getSource().getGlobalProperties();
// if we have no global parallelism change, check if we have already compatible global properties
//DataSinkNode、GroupCombineNode会走这里
if (!globalDopChange && isMetBy(inGlobals)) {
DataExchangeMode em = DataExchangeMode.select(exchangeMode, ShipStrategyType.FORWARD, breakPipeline);
channel.setShipStrategy(ShipStrategyType.FORWARD, em);
return;
}
// if we fall through the conditions until here, we need to re-establish
ShipStrategyType shipType;
FieldList partitionKeys;
boolean[] sortDirection;
Partitioner<?> partitioner;
switch (this.partitioning) {
case FULL_REPLICATION:
shipType = ShipStrategyType.BROADCAST;
partitionKeys = null;
sortDirection = null;
partitioner = null;
break;
case ANY_PARTITIONING:
//如果是ANY_PARTITIONING就直接执行HASH_PARTITIONED的步骤了,GroupReduceNode会走这里
case HASH_PARTITIONED:
shipType = ShipStrategyType.PARTITION_HASH;
partitionKeys = Utils.createOrderedFromSet(this.partitioningFields);
sortDirection = null;
partitioner = null;
break;
case RANGE_PARTITIONED:
shipType = ShipStrategyType.PARTITION_RANGE;
partitionKeys = this.ordering.getInvolvedIndexes();
sortDirection = this.ordering.getFieldSortDirections();
partitioner = null;
if (this.dataDistribution != null) {
channel.setDataDistribution(this.dataDistribution);
}
break;
case FORCED_REBALANCED:
shipType = ShipStrategyType.PARTITION_FORCED_REBALANCE;
partitionKeys = null;
sortDirection = null;
partitioner = null;
break;
case CUSTOM_PARTITIONING:
shipType = ShipStrategyType.PARTITION_CUSTOM;
partitionKeys = Utils.createOrderedFromSet(this.partitioningFields);
sortDirection = null;
partitioner = this.customPartitioner;
break;
default:
throw new CompilerException("Invalid partitioning to create through a data exchange: "
+ this.partitioning.name());
}
DataExchangeMode exMode = DataExchangeMode.select(exchangeMode, shipType, breakPipeline);
channel.setShipStrategy(shipType, partitionKeys, sortDirection, partitioner, exMode);
}
通过代码可以看到,Channel的ShipStrategyType和DataExchangeMode跟当前节点的partitioning属性和程序设置的ExecutionMode模式有关。对于像MapNode、FilterNode、FlatMapNode的partitioning属性为PartitioningProperty.ANY_DISTRIBUTION,GroupCombineNode、DataSinkNode它的partitioning是PartitioningProperty.RANDOM_PARTITIONED,GroupReduceNode它的partitioning是PartitioningProperty.ANY_PARTITIONING。
这种情况下MapNode、FilterNode、FlatMapNode、GroupCombineNode、DataSinkNode的ShipStrategyType都是FORWARD,GroupReduceNode的ShipStrategyType是PARTITION_HASH
具体DataExchangeMode的选择代码如下,可以看到,即使我们设置了ExecutionMode,最终的DataExchangeMode也不一定就和ExecutionMode一样,它还跟ShipStrategyType有关,比如DataSink,即使我们设置了ExecutionMode=BATCH,最终DataExchangeMode也还是PIPELINED
//DataExchangeMode
public static DataExchangeMode select(ExecutionMode executionMode, ShipStrategyType shipStrategy,
boolean breakPipeline) {
if (shipStrategy == null || shipStrategy == ShipStrategyType.NONE) {
throw new IllegalArgumentException("shipStrategy may not be null or NONE");
}
if (executionMode == null) {
throw new IllegalArgumentException("executionMode may not mbe null");
}
if (breakPipeline) {
return getPipelineBreakingExchange(executionMode);
}
else if (shipStrategy == ShipStrategyType.FORWARD) {
return getForForwardExchange(executionMode);
}
else {
return getForShuffleOrBroadcast(executionMode);
}
}
public static DataExchangeMode getForForwardExchange(ExecutionMode mode) {
return FORWARD[mode.ordinal()];
}
public static DataExchangeMode getForShuffleOrBroadcast(ExecutionMode mode) {
return SHUFFLE[mode.ordinal()];
}
public static DataExchangeMode getPipelineBreakingExchange(ExecutionMode mode) {
return BREAKING[mode.ordinal()];
}
private static final DataExchangeMode[] FORWARD = new DataExchangeMode[ExecutionMode.values().length];
private static final DataExchangeMode[] SHUFFLE = new DataExchangeMode[ExecutionMode.values().length];
private static final DataExchangeMode[] BREAKING = new DataExchangeMode[ExecutionMode.values().length];
// initialize the map between execution modes and exchange modes in
static {
FORWARD[ExecutionMode.PIPELINED_FORCED.ordinal()] = PIPELINED;
SHUFFLE[ExecutionMode.PIPELINED_FORCED.ordinal()] = PIPELINED;
BREAKING[ExecutionMode.PIPELINED_FORCED.ordinal()] = PIPELINED;
FORWARD[ExecutionMode.PIPELINED.ordinal()] = PIPELINED;
SHUFFLE[ExecutionMode.PIPELINED.ordinal()] = PIPELINED;
BREAKING[ExecutionMode.PIPELINED.ordinal()] = BATCH;
FORWARD[ExecutionMode.BATCH.ordinal()] = PIPELINED;
SHUFFLE[ExecutionMode.BATCH.ordinal()] = BATCH;
BREAKING[ExecutionMode.BATCH.ordinal()] = BATCH;
FORWARD[ExecutionMode.BATCH_FORCED.ordinal()] = BATCH;
SHUFFLE[ExecutionMode.BATCH_FORCED.ordinal()] = BATCH;
BREAKING[ExecutionMode.BATCH_FORCED.ordinal()] = BATCH;
}
既然是递归向上调用,那我们再来看看SingleInputNode的getAlternativePlans()
public List<PlanNode> getAlternativePlans(CostEstimator estimator) {
// check if we have a cached version
if (this.cachedPlans != null) {
return this.cachedPlans;
}
boolean childrenSkippedDueToReplicatedInput = false;
// calculate alternative sub-plans for predecessor
//也是向上递归的调用,先获取父节点对应的PlanNode
final List<? extends PlanNode> subPlans = getPredecessorNode().getAlternativePlans(estimator);
final Set<RequestedGlobalProperties> intGlobal = this.inConn.getInterestingProperties().getGlobalProperties();
...
final ArrayList<PlanNode> outputPlans = new ArrayList<PlanNode>();
final ExecutionMode executionMode = this.inConn.getDataExchangeMode();
final int parallelism = getParallelism();
final int inParallelism = getPredecessorNode().getParallelism();
final boolean parallelismChange = inParallelism != parallelism;
final boolean breaksPipeline = this.inConn.isBreakingPipeline();
// create all candidates
for (PlanNode child : subPlans) {
...
if (this.inConn.getShipStrategy() == null) {
// pick the strategy ourselves
for (RequestedGlobalProperties igps: intGlobal) {
//创建Channel并参数化
final Channel c = new Channel(child, this.inConn.getMaterializationMode());
igps.parameterizeChannel(c, parallelismChange, executionMode, breaksPipeline);
...
for (RequestedGlobalProperties rgps: allValidGlobals) {
if (rgps.isMetBy(c.getGlobalProperties())) {
c.setRequiredGlobalProps(rgps);
//创建当前节点对应的PlanNode,添加到outputPlans中
addLocalCandidates(c, broadcastPlanChannels, igps, outputPlans, estimator);
break;
}
}
}
} else {
...
}
}
...
return outputPlans;
}
前面都一样,都是在获取到父节点的PlanNode之后,创建Channel,给Channel设置ShipStrategyType和ExecutionMode。创建PlanNode的过程在addLocalCandidates()中,addLocalCandidates()最终都会调用每个SingleInputNode中OperatorDescriptorSingle.instantiate()方法。
//MapDescriptor
public SingleInputPlanNode instantiate(Channel in, SingleInputNode node) {
return new SingleInputPlanNode(node, "Map ("+node.getOperator().getName()+")", in, DriverStrategy.MAP);
}
//FlatMapDescriptor
public SingleInputPlanNode instantiate(Channel in, SingleInputNode node) {
return new SingleInputPlanNode(node, "FlatMap ("+node.getOperator().getName()+")", in, DriverStrategy.FLAT_MAP);
}
//FilterDescriptor
public SingleInputPlanNode instantiate(Channel in, SingleInputNode node) {
return new SingleInputPlanNode(node, "Filter ("+node.getOperator().getName()+")", in, DriverStrategy.FLAT_MAP);
}
我们着重看的是GroupReduceNode节点创建PlanNode的过程:
//GroupReduceWithCombineProperties
public SingleInputPlanNode instantiate(Channel in, SingleInputNode node) {
if (in.getShipStrategy() == ShipStrategyType.FORWARD) {
if(in.getSource().getOptimizerNode() instanceof PartitionNode) {
LOG.warn("Cannot automatically inject combiner for GroupReduceFunction. Please add an explicit combiner with combineGroup() in front of the partition operator.");
}
// adjust a sort (changes grouping, so it must be for this driver to combining sort
if (in.getLocalStrategy() == LocalStrategy.SORT) {
if (!in.getLocalStrategyKeys().isValidUnorderedPrefix(this.keys)) {
throw new RuntimeException("Bug: Inconsistent sort for group strategy.");
}
in.setLocalStrategy(LocalStrategy.COMBININGSORT, in.getLocalStrategyKeys(),
in.getLocalStrategySortOrder());
}
return new SingleInputPlanNode(node, "Reduce ("+node.getOperator().getName()+")", in,
DriverStrategy.SORTED_GROUP_REDUCE, this.keyList);
} else {
// non forward case. all local properties are killed anyways, so we can safely plug in a combiner
//再新建一个用于combiner的Channel,属性规定为ShipStrategyType.FORWARD, DataExchangeMode.PIPELINED
Channel toCombiner = new Channel(in.getSource());
toCombiner.setShipStrategy(ShipStrategyType.FORWARD, DataExchangeMode.PIPELINED);
// create an input node for combine with same parallelism as input node
GroupReduceNode combinerNode = ((GroupReduceNode) node).getCombinerUtilityNode();
combinerNode.setParallelism(in.getSource().getParallelism());
//创建一个用于combiner的SingleInputPlanNode,它的父节点就是原GroupReduceNode的父节点
SingleInputPlanNode combiner = new SingleInputPlanNode(combinerNode, "Combine ("+node.getOperator()
.getName()+")", toCombiner, DriverStrategy.SORTED_GROUP_COMBINE);
combiner.setCosts(new Costs(0, 0));
combiner.initProperties(toCombiner.getGlobalProperties(), toCombiner.getLocalProperties());
// set sorting comparator key info
combiner.setDriverKeyInfo(in.getLocalStrategyKeys(), in.getLocalStrategySortOrder(), 0);
// set grouping comparator key info
combiner.setDriverKeyInfo(this.keyList, 1);
//创建一个reduce端的Channel
Channel toReducer = new Channel(combiner);
toReducer.setShipStrategy(in.getShipStrategy(), in.getShipStrategyKeys(),
in.getShipStrategySortOrder(), in.getDataExchangeMode());
if (in.getShipStrategy() == ShipStrategyType.PARTITION_RANGE) {
toReducer.setDataDistribution(in.getDataDistribution());
}
toReducer.setLocalStrategy(LocalStrategy.COMBININGSORT, in.getLocalStrategyKeys(),
in.getLocalStrategySortOrder());
//创建GroupReduceNode节点对应SingleInputPlanNode
return new SingleInputPlanNode(node, "Reduce ("+node.getOperator().getName()+")",
toReducer, DriverStrategy.SORTED_GROUP_REDUCE, this.keyList);
}
}
GroupReduceNode节点在创建PlanNode的过程中会创建两个PlanNode,一个PlanNode(GroupCombine)对应combiner过程,一个PlanNode(GroupReduce)对应reduce过程
最后我们再看source节点的getAlternativePlans(),过程比较简单,创建了SourcePlanNode节点,因为source没有输入,所有没有创建Channel的过程
public List<PlanNode> getAlternativePlans(CostEstimator estimator) {
if (this.cachedPlans != null) {
return this.cachedPlans;
}
SourcePlanNode candidate = new SourcePlanNode(this, "DataSource ("+this.getOperator().getName()+")",
this.gprops, this.lprops);
...
// since there is only a single plan for the data-source, return a list with that element only
List<PlanNode> plans = new ArrayList<PlanNode>(1);
plans.add(candidate);
this.cachedPlans = plans;
return plans;
}
经过getAlternativePlans()方法执行完,所有的PlanNode都已经创建了。此时的WordCount拓扑结果图如下:
SourcePlanNode --> SingleInputPlanNode(FlatMap) --> SingleInputPlanNode(Map) --> SingleInputPlanNode(GroupCombine) --> SingleInputPlanNode(GroupReduce) --> SinkPlanNode
各个PlanNode通过Channel进行链接。Channel描述了两个节点之间数据交换的方式和分区方式等属性
7.封装成OptimizedPlan
在上述所有的PlanNode都创建完毕后,就将其封装成OptimizedPlan。源码在PlanFinalizer.createFinalPlan()。其大致的实现就是将节点添加到sources、sinks、allNodes中,还可能会为每个节点设置任务占用的内存等
public OptimizedPlan createFinalPlan(List<SinkPlanNode> sinks, String jobName, Plan originalPlan) {
this.memoryConsumerWeights = 0;
// traverse the graph
for (SinkPlanNode node : sinks) {
node.accept(this);
}
// assign the memory to each node
...
return new OptimizedPlan(this.sources, this.sinks, this.allNodes, jobName, originalPlan);
}
public boolean preVisit(PlanNode visitable) {
// if we come here again, prevent a further descend
if (!this.allNodes.add(visitable)) {
return false;
}
if (visitable instanceof SinkPlanNode) {
this.sinks.add((SinkPlanNode) visitable);
}
else if (visitable instanceof SourcePlanNode) {
this.sources.add((SourcePlanNode) visitable);
}
...
// double-connect the connections. previously, only parents knew their children, because
// one child candidate could have been referenced by multiple parents.
for (Channel conn : visitable.getInputs()) {
conn.setTarget(visitable);
conn.getSource().addOutgoingChannel(conn);
}
for (Channel c : visitable.getBroadcastInputs()) {
c.setTarget(visitable);
c.getSource().addOutgoingChannel(c);
}
// count the memory consumption
...
return true;
}
@Override
public void postVisit(PlanNode visitable) {
}
到此,执行计划就编译完成了。下一步就是根据这个执行计划来生成JobGraph了。
8.创建JobGraph
JobGraph的创建在JobGraphGenerator.compileJobGraph()方法。核心方法在OptimizedPlan.accept()方法中。该方法会创建JobGraph的所有顶点、边、中间结果集,即JobVertex、JobEdge、IntermediateDataSet
Optimizer pc = new Optimizer(new DataStatistics(), jobExecutorServiceConfiguration);
OptimizedPlan op = pc.compile(plan);
JobGraphGenerator jgg = new JobGraphGenerator(jobExecutorServiceConfiguration);
JobGraph jobGraph = jgg.compileJobGraph(op, plan.getJobId());
大致的实现步骤如下:
核心方法在program.accept()中,这个过程会调用JobGraphGenerator.preVisit()和JobGraphGenerator.postVisit()方法。preVisit()会创建JobVertex,postVisit()会将JobVertex进行连接,创建JobEdge、中间结果集IntermediateDataSet
将所有需要chain的节点信息添加到它属于的JobVertex的配置中
创建JobGraph实例,将步骤1中创建的所有的JobVertex添加到JobGraph中,返回这个实例
//JobGraphGenerator类
public JobGraph compileJobGraph(OptimizedPlan program, JobID jobId) {
if (program == null) {
throw new NullPointerException("Program is null, did you called " +
"ExecutionEnvironment.execute()");
}
if (jobId == null) {
jobId = JobID.generate();
}
this.vertices = new HashMap<PlanNode, JobVertex>();
this.chainedTasks = new HashMap<PlanNode, TaskInChain>();
this.chainedTasksInSequence = new ArrayList<TaskInChain>();
this.auxVertices = new ArrayList<JobVertex>();
this.iterations = new HashMap<IterationPlanNode, IterationDescriptor>();
this.iterationStack = new ArrayList<IterationPlanNode>();
this.sharingGroup = new SlotSharingGroup();
// this starts the traversal that generates the job graph
//JobGraph创建的核心方法
program.accept(this);
...
// now that the traversal is done, we have the chained tasks write their configs into their
// parents' configurations
//将那些需要被chain的节点添加到JobVertex的配置中去
for (TaskInChain tic : this.chainedTasksInSequence) {
TaskConfig t = new TaskConfig(tic.getContainingVertex().getConfiguration());
t.addChainedTask(tic.getChainedTask(), tic.getTaskConfig(), tic.getTaskName());
}
// ----- attach the additional info to the job vertices, for display in the runtime monitor
attachOperatorNamesAndDescriptions();
// ----------- finalize the job graph -----------
// create the job graph object
//创建JobGraph对象,将上述创建的顶点都添加到JobGraph中
JobGraph graph = new JobGraph(jobId, program.getJobName());
try {
graph.setExecutionConfig(program.getOriginalPlan().getExecutionConfig());
}
catch (IOException e) {
throw new CompilerException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
graph.setAllowQueuedScheduling(false);
graph.setSessionTimeout(program.getOriginalPlan().getSessionTimeout());
// add vertices to the graph
for (JobVertex vertex : this.vertices.values()) {
vertex.setInputDependencyConstraint(program.getOriginalPlan().getExecutionConfig().getDefaultInputDependencyConstraint());
graph.addVertex(vertex);
}
for (JobVertex vertex : this.auxVertices) {
graph.addVertex(vertex);
vertex.setSlotSharingGroup(sharingGroup);
}
Collection<Tuple2<String, DistributedCache.DistributedCacheEntry>> userArtifacts =
program.getOriginalPlan().getCachedFiles().stream()
.map(entry -> Tuple2.of(entry.getKey(), entry.getValue()))
.collect(Collectors.toList());
addUserArtifactEntries(userArtifacts, graph);
// release all references again
this.vertices = null;
this.chainedTasks = null;
this.chainedTasksInSequence = null;
this.auxVertices = null;
this.iterations = null;
this.iterationStack = null;
// return job graph
return graph;
}
accept()方法跟之前的accept()是一样的,都是先从sink开始,由下至上对每个PlanNode执行visitor.preVisit()方法,再由上至下对每个PlanNode执行visitor.postVisit()。这里的visitor就是JobGraphGenerator
//OptimizedPlan类
public void accept(Visitor<PlanNode> visitor) {
for (SinkPlanNode node : this.dataSinks) {
node.accept(visitor);
}
}
//SinkPlanNode、SingleInputPlanNode类
public void accept(Visitor<PlanNode> visitor) {
if (visitor.preVisit(this)) {
this.input.getSource().accept(visitor);
for (Channel broadcastInput : getBroadcastInputs()) {
broadcastInput.getSource().accept(visitor);
}
visitor.postVisit(this);
}
}
//SourcePlanNode类
public void accept(Visitor<PlanNode> visitor) {
if (visitor.preVisit(this)) {
visitor.postVisit(this);
}
}
9.创建JobVertex
那么我们先来看JobGraphGenerator.preVisit()方法。从方法中我们可以看到,preVisit()方法就是创建JobGraph顶点的过程,这里我们关注的主要是三种节点类型,SinkPlanNode、SourcePlanNode、SingleInputPlanNode
public boolean preVisit(PlanNode node) {
// check if we have visited this node before. in non-tree graphs, this happens
if (this.vertices.containsKey(node) || this.chainedTasks.containsKey(node) || this.iterations.containsKey(node)) {
// return false to prevent further descend
return false;
}
// the vertex to be created for the current node
final JobVertex vertex;
try {
if (node instanceof SinkPlanNode) {
vertex = createDataSinkVertex((SinkPlanNode) node);
}
else if (node instanceof SourcePlanNode) {
vertex = createDataSourceVertex((SourcePlanNode) node);
}
...
else if (node instanceof SingleInputPlanNode) {
vertex = createSingleInputVertex((SingleInputPlanNode) node);
}
...
else {
throw new CompilerException("Unrecognized node type: " + node.getClass().getName());
}
}
catch (Exception e) {
throw new CompilerException("Error translating node '" + node + "': " + e.getMessage(), e);
}
// check if a vertex was created, or if it was chained or skipped
if (vertex != null) {
// set parallelism
int pd = node.getParallelism();
vertex.setParallelism(pd);
vertex.setMaxParallelism(pd);
vertex.setSlotSharingGroup(sharingGroup);
// check whether this vertex is part of an iteration step function
...
// store in the map
this.vertices.put(node, vertex);
}
// returning true causes deeper descend
return true;
}
10.创建sink节点的JobVertex:
OutputFormatVertex继承了JobVertex,作为sink节点的JobVertex,Task类型为DataSinkTask。那么这里我们可以分析到,sink是不与其他的节点进行chain链接的。而是单独作为一个顶点存在,在执行过程中,sink也将单独作为一组task来执行。这和流处理模式是有区别的。
private JobVertex createDataSinkVertex(SinkPlanNode node) throws CompilerException {
final OutputFormatVertex vertex = new OutputFormatVertex(node.getNodeName());
final TaskConfig config = new TaskConfig(vertex.getConfiguration());
vertex.setResources(node.getMinResources(), node.getPreferredResources());
vertex.setInvokableClass(DataSinkTask.class);
vertex.setFormatDescription(getDescriptionForUserCode(node.getProgramOperator().getUserCodeWrapper()));
// set user code
config.setStubWrapper(node.getProgramOperator().getUserCodeWrapper());
config.setStubParameters(node.getProgramOperator().getParameters());
return vertex;
}
11. 创建source节点的JobVertex:
InputFormatVertex同样继承了JobVertex,作为source节点的JobVertex,Task任务类型为DataSourceTask。
private InputFormatVertex createDataSourceVertex(SourcePlanNode node) throws CompilerException {
final InputFormatVertex vertex = new InputFormatVertex(node.getNodeName());
final TaskConfig config = new TaskConfig(vertex.getConfiguration());
vertex.setResources(node.getMinResources(), node.getPreferredResources());
vertex.setInvokableClass(DataSourceTask.class);
vertex.setFormatDescription(getDescriptionForUserCode(node.getProgramOperator().getUserCodeWrapper()));
// set user code
config.setStubWrapper(node.getProgramOperator().getUserCodeWrapper());
config.setStubParameters(node.getProgramOperator().getParameters());
config.setOutputSerializer(node.getSerializer());
return vertex;
}
12 创建SingleInputPlanNode的JobVertex:
这也是大多数情况下的顶点创建过程。大致的过程就是首先判断当前节点能否和之前的节点进行链接chain。如果能chain,就先放到chainedTasks中,如果不能进行chain,就创建一个新节点JobVertex,没有迭代算子的情况下Task任务类型是BatchTask。能进行chain的条件大致如下:
1、节点的ChainDriverClass不能为空,ChainDriverClass描述了节点间进行chain的驱动类型
2、节点类型不能为NAryUnionPlanNode、BulkPartialSolutionPlanNode、WorksetPlanNode、IterationPlanNode
3、节点间的数据交换模式为FORWARD
4、本地策略为NONE
5、上游节点只有一个输出
6、上下游节点并行度一致
7、该节点没有广播数据输入
private JobVertex createSingleInputVertex(SingleInputPlanNode node) throws CompilerException {
final String taskName = node.getNodeName();
final DriverStrategy ds = node.getDriverStrategy();
// check, whether chaining is possible
boolean chaining;
{
Channel inConn = node.getInput();
PlanNode pred = inConn.getSource();
chaining = ds.getPushChainDriverClass() != null &&
!(pred instanceof NAryUnionPlanNode) && // first op after union is stand-alone, because union is merged
!(pred instanceof BulkPartialSolutionPlanNode) && // partial solution merges anyways
!(pred instanceof WorksetPlanNode) && // workset merges anyways
!(pred instanceof IterationPlanNode) && // cannot chain with iteration heads currently
inConn.getShipStrategy() == ShipStrategyType.FORWARD &&
inConn.getLocalStrategy() == LocalStrategy.NONE &&
pred.getOutgoingChannels().size() == 1 &&
node.getParallelism() == pred.getParallelism() &&
node.getBroadcastInputs().isEmpty();
...
}
final JobVertex vertex;
final TaskConfig config;
if (chaining) {
vertex = null;
config = new TaskConfig(new Configuration());
this.chainedTasks.put(node, new TaskInChain(node, ds.getPushChainDriverClass(), config, taskName));
} else {
// create task vertex
vertex = new JobVertex(taskName);
vertex.setResources(node.getMinResources(), node.getPreferredResources());
vertex.setInvokableClass((this.currentIteration != null && node.isOnDynamicPath()) ? IterationIntermediateTask.class : BatchTask.class);
config = new TaskConfig(vertex.getConfiguration());
//Driver是节点处理数据的核心类
config.setDriver(ds.getDriverClass());
}
// set user code
config.setStubWrapper(node.getProgramOperator().getUserCodeWrapper());
config.setStubParameters(node.getProgramOperator().getParameters());
// set the driver strategy
config.setDriverStrategy(ds);
for (int i = 0; i < ds.getNumRequiredComparators(); i++) {
config.setDriverComparator(node.getComparator(i), i);
}
// assign memory, file-handles, etc.
assignDriverResources(node, config);
return vertex;
}
通过PlanNode从下至上的调用JobGraphGenerator.preVisit()方法,所有的JobVertex现在都被创建出来了。
连接JobVertex
下面来看看JobGraphGenerator.postVisit(),这个方法的调用是从上至下(source到sink)调用的。大致实现如下:
1、如果是source节点,不做任何操作,直接返回
2、如果PlanNode是需要进行chain的节点,即chain在JobVertex头结点之后的节点。那么会给该节点设置它应该属于的那个JobVertex。
3、如果PlanNode是JobVertex的头节点,那么会将该节点对应的JobVertex与之前的JobVertex进行连接。这个过程会创建JobEdge,中间结果集IntermediateDataSet
public void postVisit(PlanNode node) {
try {
//如果是source节点,直接返回,不做任何操作
if (node instanceof SourcePlanNode || node instanceof NAryUnionPlanNode || node instanceof SolutionSetPlanNode) {
return;
}
// check if we have an iteration. in that case, translate the step function now
...
final JobVertex targetVertex = this.vertices.get(node);
// check whether this node has its own task, or is merged with another one
//targetVertex == null这种情况是针对那些需要chain的PlanNode节点
if (targetVertex == null) {
// node's task is merged with another task. it is either chained, of a merged head vertex
// from an iteration
final TaskInChain chainedTask;
if ((chainedTask = this.chainedTasks.get(node)) != null) {
// Chained Task. Sanity check first...
final Iterator<Channel> inConns = node.getInputs().iterator();
if (!inConns.hasNext()) {
throw new CompilerException("Bug: Found chained task with no input.");
}
final Channel inConn = inConns.next();
...
JobVertex container = chainedTask.getContainingVertex();
if (container == null) {
final PlanNode sourceNode = inConn.getSource();
container = this.vertices.get(sourceNode);
if (container == null) {
// predecessor is itself chained
container = this.chainedTasks.get(sourceNode).getContainingVertex();
if (container == null) {
throw new IllegalStateException("Bug: Chained task predecessor has not been assigned its containing vertex.");
}
} else {
// predecessor is a proper task job vertex and this is the first chained task. add a forward connection entry.
new TaskConfig(container.getConfiguration()).addOutputShipStrategy(ShipStrategyType.FORWARD);
}
//给这些节点设置他们应该属于的JobVertex
chainedTask.setContainingVertex(container);
}
// add info about the input serializer type
chainedTask.getTaskConfig().setInputSerializer(inConn.getSerializer(), 0);
// update name of container task
String containerTaskName = container.getName();
if (containerTaskName.startsWith("CHAIN ")) {
container.setName(containerTaskName + " -> " + chainedTask.getTaskName());
} else {
container.setName("CHAIN " + containerTaskName + " -> " + chainedTask.getTaskName());
}
//update resource of container task
container.setResources(container.getMinResources().merge(node.getMinResources()),
container.getPreferredResources().merge(node.getPreferredResources()));
this.chainedTasksInSequence.add(chainedTask);
return;
}
else if (node instanceof BulkPartialSolutionPlanNode ||
node instanceof WorksetPlanNode)
{
// merged iteration head task. the task that the head is merged with will take care of it
return;
} else {
throw new CompilerException("Bug: Unrecognized merged task vertex.");
}
}
...
//下面的代码是针对有JobVertex的PlanNode节点,也即JobVertex中的头节点
// create the config that will contain all the description of the inputs
final TaskConfig targetVertexConfig = new TaskConfig(targetVertex.getConfiguration());
// get the inputs. if this node is the head of an iteration, we obtain the inputs from the
// enclosing iteration node, because the inputs are the initial inputs to the iteration.
final Iterator<Channel> inConns;
if (node instanceof BulkPartialSolutionPlanNode) {
...
} else if (node instanceof WorksetPlanNode) {
...
} else {
inConns = node.getInputs().iterator();
}
...
int inputIndex = 0;
while (inConns.hasNext()) {
Channel input = inConns.next();
//translateChannel会连接两个JobVertex,创建JobEdge和中间结果集IntermediateDataSet
inputIndex += translateChannel(input, inputIndex, targetVertex, targetVertexConfig, false);
}
// broadcast variables
...
} catch (Exception e) {
throw new CompilerException(
"An error occurred while translating the optimized plan to a JobGraph: " + e.getMessage(), e);
}
}
我们主要看两个顶点之间的连接过程,在translateChannel()方法。调用方法链为:
JobGraphGenerator.translateChannel() --> JobGraphGenerator.connectJobVertices() --> JobVertex.connectNewDataSetAsInput()。经过这个过程,JobVertex进行了连接,JobEdge和中间结果集IntermediateDataSet都创建出来了。这时JobGraph基本已经构建完毕了
//JobGraphGenerator类
private int translateChannel(Channel input, int inputIndex, JobVertex targetVertex,
TaskConfig targetVertexConfig, boolean isBroadcast) throws Exception
{
final PlanNode inputPlanNode = input.getSource();
final Iterator<Channel> allInChannels;
if (inputPlanNode instanceof NAryUnionPlanNode) {
...
} else {
allInChannels = Collections.singletonList(input).iterator();
}
...
// expand the channel to all the union channels, in case there is a union operator at its source
while (allInChannels.hasNext()) {
final Channel inConn = allInChannels.next();
...
final PlanNode sourceNode = inConn.getSource();
JobVertex sourceVertex = this.vertices.get(sourceNode);
TaskConfig sourceVertexConfig;
if (sourceVertex == null) {
// this predecessor is chained to another task or an iteration
//这种情况下sourceNode是一个被chain的节点,不是JobVertex的头节点。这时候获取它属于的那个JobVertex
final TaskInChain chainedTask;
final IterationDescriptor iteration;
if ((chainedTask = this.chainedTasks.get(sourceNode)) != null) {
// push chained task
if (chainedTask.getContainingVertex() == null) {
throw new IllegalStateException("Bug: Chained task has not been assigned its containing vertex when connecting.");
}
sourceVertex = chainedTask.getContainingVertex();
sourceVertexConfig = chainedTask.getTaskConfig();
} else if ((iteration = this.iterations.get(sourceNode)) != null) {
// predecessor is an iteration
sourceVertex = iteration.getHeadTask();
sourceVertexConfig = iteration.getHeadFinalResultConfig();
} else {
throw new CompilerException("Bug: Could not resolve source node for a channel.");
}
} else {
// predecessor is its own vertex
sourceVertexConfig = new TaskConfig(sourceVertex.getConfiguration());
}
//连接两个顶点JobVertex
DistributionPattern pattern = connectJobVertices(
inConn, inputIndex, sourceVertex, sourceVertexConfig, targetVertex, targetVertexConfig, isBroadcast);
...
// the local strategy is added only once. in non-union case that is the actual edge,
// in the union case, it is the edge between union and the target node
addLocalInfoFromChannelToConfig(input, targetVertexConfig, inputIndex, isBroadcast);
return 1;
}
//JobGraphGenerator类
private DistributionPattern connectJobVertices(Channel channel, int inputNumber,
final JobVertex sourceVertex, final TaskConfig sourceConfig,
final JobVertex targetVertex, final TaskConfig targetConfig, boolean isBroadcast)
throws CompilerException
{
// ------------ connect the vertices to the job graph --------------
final DistributionPattern distributionPattern;
switch (channel.getShipStrategy()) {
case FORWARD:
distributionPattern = DistributionPattern.POINTWISE;
break;
case PARTITION_RANDOM:
case BROADCAST:
case PARTITION_HASH:
case PARTITION_CUSTOM:
case PARTITION_RANGE:
case PARTITION_FORCED_REBALANCE:
distributionPattern = DistributionPattern.ALL_TO_ALL;
break;
default:
throw new RuntimeException("Unknown runtime ship strategy: " + channel.getShipStrategy());
}
//resultType影响ResultPartition的类型,分为PIPELINED和BLOCKING,BLOCKING会将数据spill到磁盘
final ResultPartitionType resultType;
switch (channel.getDataExchangeMode()) {
case PIPELINED:
resultType = ResultPartitionType.PIPELINED;
break;
case BATCH:
// BLOCKING results are currently not supported in closed loop iterations
//
// See https://issues.apache.org/jira/browse/FLINK-1713 for details
resultType = channel.getSource().isOnDynamicPath()
? ResultPartitionType.PIPELINED
: ResultPartitionType.BLOCKING;
break;
case PIPELINE_WITH_BATCH_FALLBACK:
throw new UnsupportedOperationException("Data exchange mode " +
channel.getDataExchangeMode() + " currently not supported.");
default:
throw new UnsupportedOperationException("Unknown data exchange mode.");
}
//在这里创建JobEdge和IntermediateDataSet
JobEdge edge = targetVertex.connectNewDataSetAsInput(sourceVertex, distributionPattern, resultType);
// -------------- configure the source task's ship strategy strategies in task config --------------
...
return distributionPattern;
}
//JobVertex类
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType) {
IntermediateDataSet dataSet = input.createAndAddResultDataSet(partitionType);
JobEdge edge = new JobEdge(dataSet, this, distPattern);
this.inputs.add(edge);
dataSet.addConsumer(edge);
return edge;
}
对所有的PlanNode执行完JobGraphGenerator.postVisit()之后,JobEdge和中间结果集IntermediateDataSet都创建出来了,这时JobGraph基本已经构建完毕了。这时program.accept()方法也执行完毕了。
再回到上述的JobGraphGenerator.compileJobGraph()方法,program.accept()方法也执行完毕后,会将那些需要chain起来的节点信息添加到他们对应的JobVertex配置中。随后创建JobGraph实例,将program.accept()方法创建的所有的JobVertex添加到JobGraph。到此,JobGraph就创建完毕了。
以WordCount为例,JobGraph创建完的拓扑如下:
InputFormatVertex(CHAIN DataSource -> FlatMap -> Map -> Combine (SUM(1))
——> IntermediateDataSet ——> JobEdge ——>
JobVertex(Reduce (SUM(1)) )——> IntermediateDataSet ——> JobEdge ——> InputFormatVertex(DataSink (TextOutputFormat)
13.总结:
本文以WordCount为例,JobGraph创建的总体步骤如下:
1、在创建完整个的执行程序时,会创建很多DataSet,比如map、filter、reduce等算子都会创建一个新的DataSet。上一个DataSet作为下个DataSet的input,进行了连接。WordCount程序初始状态如下:DataSource ——> FlatMapOperator ——> MapOperator ——> ScalaAggregateOperator ——> DataSink。注意这里的Operator并非是指算子层面的operator,而是DataSet,这些operator也还是DataSet的子类型(DataSink除外)
2、创建执行计划Plan。将上述1中的DataSet进行转换,转换成算子层面的Operator。大致实现就是从sink开始进行向上深度优化遍历递归的转换,先转换source,再依次向下进行转换,转换的方法就是调用每个DataSet(或者DataSink)的translateToDataFlow()方法,将DataSet转换成算子层面的Operator,然后将上一级转换后的Operator当做下个Operator的input输入。WordCount转换成的算子层面的Operator就如下所示:GenericDataSourceBase --> FlatMapOperatorBase --> MapOperatorBase --> GroupReduceOperatorBase --> GenericDataSinkBase
3、使用优化器对Plan进行优化,编译成OptimizedPlan。首先会使用GraphCreatingVisitor对原始的Plan进行优化,将每个operator优化成OptimizerNode,OptimizerNode之间通过DagConnection相连,DagConnection相当于一个边模型,用来连接两个节点。OptimizerNode的创建过程是通过Plan.accept()方法。先从sink(GenericDataSinkBase)开始,由下至上对每个operator执行visitor.preVisit()方法,用于创建OptimizerNode;再由上至下对每个operator执行visitor.postVisit(),用于连接两个OptimizerNode。WordCount整个计划变成了如下的拓扑结构:
DataSourceNode --> FlatMapNode --> MapNode --> GroupReduceNode --> DataSinkNode
每个OptimizerNode之间通过DagConnection进行连接
4、将OptimizerNode进一步编译成PlanNode,封装成OptimizedPlan。代码在OptimizerNode.getAlternativePlans(),又是一个递归的遍历,是后续递归遍历,从上(source)到下(sink)的去创建PlanNode和Channel。PlanNode之间通过Channel相连,Channel也相当于是一个边模型,连接两个节点。这个过程会做很多优化,比如对GroupReduceNode会增加combiner的节点,对Channel会设置ShipStrategyType和DataExchangeMode,ShipStrategyType表示的两个节点之间数据的传输策略,比如进行hash分区,范围分区等,DataExchangeMode表示的是两个节点间数据交换的模式,有PIPELINED和BATCH。PIPELINED模式数据像流水线一样的进行传输,上游任务和下游任务能够同时进行生产和消费数据;BATCH模式需要等上游的任务数据全部处理完之后才会开始下游的任务,中间数据会spill到磁盘上。此时的WordCount拓扑结果图如下:
SourcePlanNode --> SingleInputPlanNode(FlatMap) --> SingleInputPlanNode(Map) --> SingleInputPlanNode(GroupCombine) --> SingleInputPlanNode(GroupReduce) --> SinkPlanNode
各个PlanNode通过Channel进行链接
5、创建JobGraph。在4中创建完所有的OptimizedPlan之后,使用JobGraphGenerator编译成JobGraph。核心代码在OptimizedPlan.accept(jobGraphGenerator)。主要的实现和步骤3类似,先从上至下(从SinkPlanNode至SourcePlanNode)执行JobGraphGenerator.preVisit()方法,在从上至下(从SourcePlanNode至SinkPlanNode)执行JobGraphGenerator.postVisit()。preVisit()方法用来创建JobVertex,保存那些需要被chain在一起的节点。postVisit()方法用于连接两个JobVertex,创建JobEdge和中间结果集IntermediateDataSet,把那些需要被chain在一起的节点设置他们属于的JobVertex。
6、postVisit()方法执行完毕之后所有的JobVertex都创建出来了,JobEdge和IntermediateDataSet也都被创建出来了。接下来就构建一个JobGraph实例,将JobVertex都添加进去,将那些需要被chain在一起的节点都添加到JobVertex的配置中,整个JobGraph就构建完成了。以WordCount为例,JobGraph创建完的拓扑如下:
InputFormatVertex(CHAIN DataSource -> FlatMap -> Map -> Combine (SUM(1))
——> IntermediateDataSet ——> JobEdge ——>
JobVertex(Reduce (SUM(1)) )——> IntermediateDataSet ——> JobEdge ——> InputFormatVertex(DataSink (TextOutputFormat)
边栏推荐
猜你喜欢
![MySQL advanced Chapter 1 (installing MySQL under Linux) [2]](/img/24/0795ebd2a0673d48c5e0f9d18842d1.png)
MySQL advanced Chapter 1 (installing MySQL under Linux) [2]

小米电视的网页和珠宝的网页
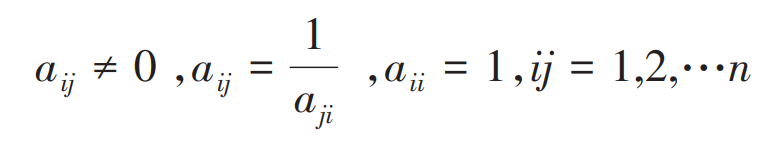
Evaluation - analytic hierarchy process

ABP framework Practice Series (II) - Introduction to domain layer

Open Camera异常分析(一)

Tupu software is the digital twin of offshore wind power, striving to be the first
After Ali failed to start his job in the interview, he was roast by the interviewer in the circle of friends (plug)

(15)Blender源码分析之闪屏窗口显示菜单功能

Uni app, the text implementation expands and retracts the full text

ABP framework
随机推荐
Xiaomi TV's web page and jewelry's web page
xml 解析bean工具类
Procédures stockées MySQL
Restful API interface design standards and specifications
What does virtualization mean? What technologies are included? What is the difference with private cloud?
I/O 虚拟化技术 — VFIO
Camera-CreateCaptureSession
Android gap animation translate, scale, alpha, rotate
(15)Blender源码分析之闪屏窗口显示菜单功能
链路监控 pinpoint
Uni app swiper rotation chart (full screen / card)
Graphics card, GPU, CPU, CUDA, video memory, rtx/gtx and viewing mode
Request object, send request
QPS的概念和实现
解决uniapp插件robin-editor设置字体颜色和背景颜色报错的问题
169. 多数元素
MySQL高级篇第一章(linux下安装MySQL)【下】
动态线段树leetcode.715
Uni app custom selection date 1 (September 16, 2021)
Uni app custom selection date 2 (September 16, 2021)