当前位置:网站首页>Model effect optimization, try a variety of cross validation methods (system operation)
Model effect optimization, try a variety of cross validation methods (system operation)
2022-06-24 08:07:00 【Tomato risk control】
When we model , This is often the case : After the model is successfully fitted on the training sample set, the performance evaluation indexes are better , But the verification effect on the test sample set is very poor , The reason for this deviation , It is often the over fitting problem of the model ( Pictured 1 Shown ), It directly reflects that the generalization ability of the trained model in the application of new samples is weak . Of course , This phenomenon is very common in actual modeling scenarios , But in order to get a model that meets the business requirements and the performance effect is available , We are bound to take effective measures to solve such problems . In this kind of modeling real business scenario , The idea and method of cross validation play a very important role , essentially , Cross validation can make full use of all training data to evaluate the model , This sets a good condition for the final stable output of the model .

chart 1 The model is over fitted
Cross validation (Cross-Validation), The core idea is to reuse data , Split the modeling sample data set , Then they are combined into different training sets and test sets , Train the model in the training set , In test centralized evaluation model . Under the logical application of the principle of data splitting , You can get many different training sets and test sets , The sample of one training set may be the sample of the next test set . The purpose of cross validation is to estimate the test error of the model effectively , Or generalization capability , Then the performance results are compared according to the model verification , Select the appropriate model with high accuracy . Cross validation in practical applications ,K Folded cross validation is commonly used , But it's important to understand that , There are several other classical methods commonly used in cross validation . In this paper, in order to facilitate everyone in the modeling process can effectively obtain a reasonable model , Several cross validation methods commonly used in actual work scenarios will be introduced in detail , Include HoldOut Cross validation 、K-Fold Cross validation 、 layered K-Fold Cross validation 、Shuffle-Split Cross validation 、Leave-P-Out Cross validation, etc . In order to illustrate the implementation process of each cross validation method , We use specific sample data , The implementation process and output results of each method are given synchronously . The sample data contains 8000 Samples and 12 A field , They are primary keys ID、 Target variable Y、 Characteristic variable X01~X10, Some examples are shown in the figure 2 Shown .

chart 2 Sample data
1、HoldOut Cross validation
HoldOut Cross validation , The whole data set is randomly divided into training set and verification set according to a certain proportion , In a real situation , The split ratio of training set and verification set is generally 7:3 or 8:2. This method is the most basic and simplest cross validation method , Because every time the model is built , The model is fitted only once on the training set , So the task execution speed is very fast , But in order to keep the model relatively stable , It is often possible to split the data many times and train the model , Finally, select the model with better performance . stay Python In language ,HoldOut Cross validation can be done by calling a function train_test_split( ) To select data , The specific code implementation process is shown in the figure 2 Shown ( Take the classification of logistic regression algorithm as an example ), The accuracy index results of the final output model in the training set and the test set are shown in the figure 3 Shown .

chart 3 HoldOut Cross validation code

chart 4 HoldOut Cross validation results
2、K Crossover verification
K Crossover verification (K-Fold), The idea of this method is to split the entire sample data set into K Sub samples of the same size , Each partition sample can be called a “ Fold ”, Therefore, the split sample data can be understood as K fold . among , Some arbitrary 1 Fold data as validation set , And the rest K-1 Fold data as training set . In the process of cross validation , The alternation of training set and verification set will be repeated K Time , That is, each folded partition sample data will be used as a validation set , Other folded data are used as training sets . Final accuracy evaluation after model training , You can take K The average accuracy of the models on the corresponding validation data set . stay Python In language ,K Fold cross validation can be done by calling the function cross_val_score( ) And KFold( ) To select data , The specific code implementation process is shown in the figure 5 Shown ( Take the logistic regression classification algorithm as an example ), The accuracy index results of the final output model in the training set and the test set are shown in the figure 6 Shown .

chart 5 K Fold cross validation code 、

chart 6 K Fold cross validation results
3、 layered K Crossover verification
layered K Crossover verification , Main principles logic and K Fold cross validation is similar , The whole sample data set is still split into K Parts of , The key difference is layering K Fold and cross validation is carried out by stratified sampling of target variables , Make the target variable distribution proportion of each collapsed dataset , Consistent with the target situation of the entire sample data , Effectively solve the imbalance of samples , So it is K Optimized version of cross validation , And it can better meet the needs of actual business scenarios . stay Python In language , layered K Fold cross validation can be done by calling the function cross_val_score( ) And StratifiedKFold( ) To select data , The specific code implementation process is shown in the figure 7 Shown ( Take the logistic regression classification algorithm as an example ), The accuracy index results of the final output model in the training set and the test set are shown in the figure 8 Shown .

chart 7 layered K Fold cross validation code

chart 8 layered K Fold cross validation results
4、Shuffle-Split Cross validation
Shuffle-Split Cross validation ( Monte Carlo cross validation ), Although this method also adopts the idea of random splitting of sample data , But the implementation process has two main advantages , One is that you can freely specify the sample size of the training set and the verification set , The other is to define the number of repetitions of cyclic verification n, comparison K Fold the fixed cross validation K The second repetition is obviously more flexible . In the process of random data splitting , You can specify the sample proportion size of the training set and the verification set , The sum of the two proportions does not have to be 100% The requirements of , When the ratio is less than 1 when , The remaining data will not participate in the training and verification of the model . stay Python In language ,Shuffle-Split Cross validation can be done by calling a function cross_val_score( ) And ShuffleSplit( ) To select data , The specific code implementation process is shown in the figure 9 Shown ( Take the logistic regression classification algorithm as an example ), The accuracy index results of the final output model in the training set and the test set are shown in the figure 10 Shown .

chart 9 Shuffle-Split Cross validation code

chart 10 Shuffle-Split Cross validation results
5、Leave-P-Out Cross validation
Leave-P-Out Cross validation , By specifying p After value ,p Samples as validation set , The remaining np None of them can be used as a training set , And then repeat the process , Until the entire sample data is used as a validation set , The disadvantage of this method is that the task takes a long time , Compared with the previous methods, the application is relatively less . stay Python In language ,Leave-P-Out Cross validation can be done by calling a function cross_val_score( ) And LeavePOut( ) To select data , The specific code implementation process is shown in the figure 11 Shown ( Take the logistic regression classification algorithm as an example ).

chart 11 Leave-P-Out Cross validation results
Combine the above , We combine the actual sample data , This paper introduces several commonly used cross validation methods in the actual working scenario , Include HoldOut、K-Fold、 layered K-Fold、Leave-P-Out、Shuffle-Split Cross validation of . Of course , There are other verification methods , For example, leave a cross validation 、 Time series cross validation, etc , The details need to be determined according to the data samples . however , In the actual modeling process , Whatever cross validation method is used , The purpose is to obtain a model with better comprehensive performance . For several cross validation methods introduced above , In the process of practical application , The following points need to be noted :
(1)HoldOut、K-Fold、Leave-P-Out、Shuffle-Split The cross validation method is not suitable for unbalanced samples , There may be a large deviation between the target value distribution of the training sample and the verification sample , And layering K-Fold Cross validation can effectively solve the problem of sample imbalance ;
(2)Leave-P-Out Cross validation although the extracted data is more detailed , But the task takes a long time , Especially for the model algorithm with complex parameter definition , Generally not recommended ;
(3) The above methods are under the condition of specified parameters , The training set and verification set were obtained by random sampling , The distribution of samples is random , Therefore, it is not suitable for time series sample data with requirements for sorting ;
(4) The cross validation method is applied in practice , Often integrated with grid search , On the one hand, it can effectively avoid the over fitting phenomenon of the model, so as to obtain a more stable model , On the other hand, the model with better performance can be obtained through repeated training of multi parameter configuration . In order to make everyone more familiar with the common methods of model cross validation , We have prepared the sample data synchronized with the content of this article python Code , For your reference , For details, please move to the knowledge planet to view the relevant content .

…
~ Original article
边栏推荐
- Mousse shares listed on Shenzhen Stock Exchange: gross profit margin continued to decline, and marketing failed in the first quarter of 2022
- 调用Feign接口时指定ip
- 宝塔面板安装php7.2安装phalcon3.3.2
- Configure your own free Internet domain name with ngrok
- Baidu map, coordinate inversion, picking coordinate position
- 使用 kubeconfig 文件组织集群访问
- Tuple remarks
- Simple summary of lighting usage
- Pair class notes
- IndexError: Target 7 is out of bounds.
猜你喜欢

闲谈:3AC到底发生了什么?

Swift Extension NetworkUtil(網絡監聽)(源碼)
![[data update] Xunwei comprehensively upgraded NPU development data based on 3568 development board](/img/10/6725b51120a6ae8b16d60f5b1ae904.jpg)
[data update] Xunwei comprehensively upgraded NPU development data based on 3568 development board

Review of postgraduate English final exam
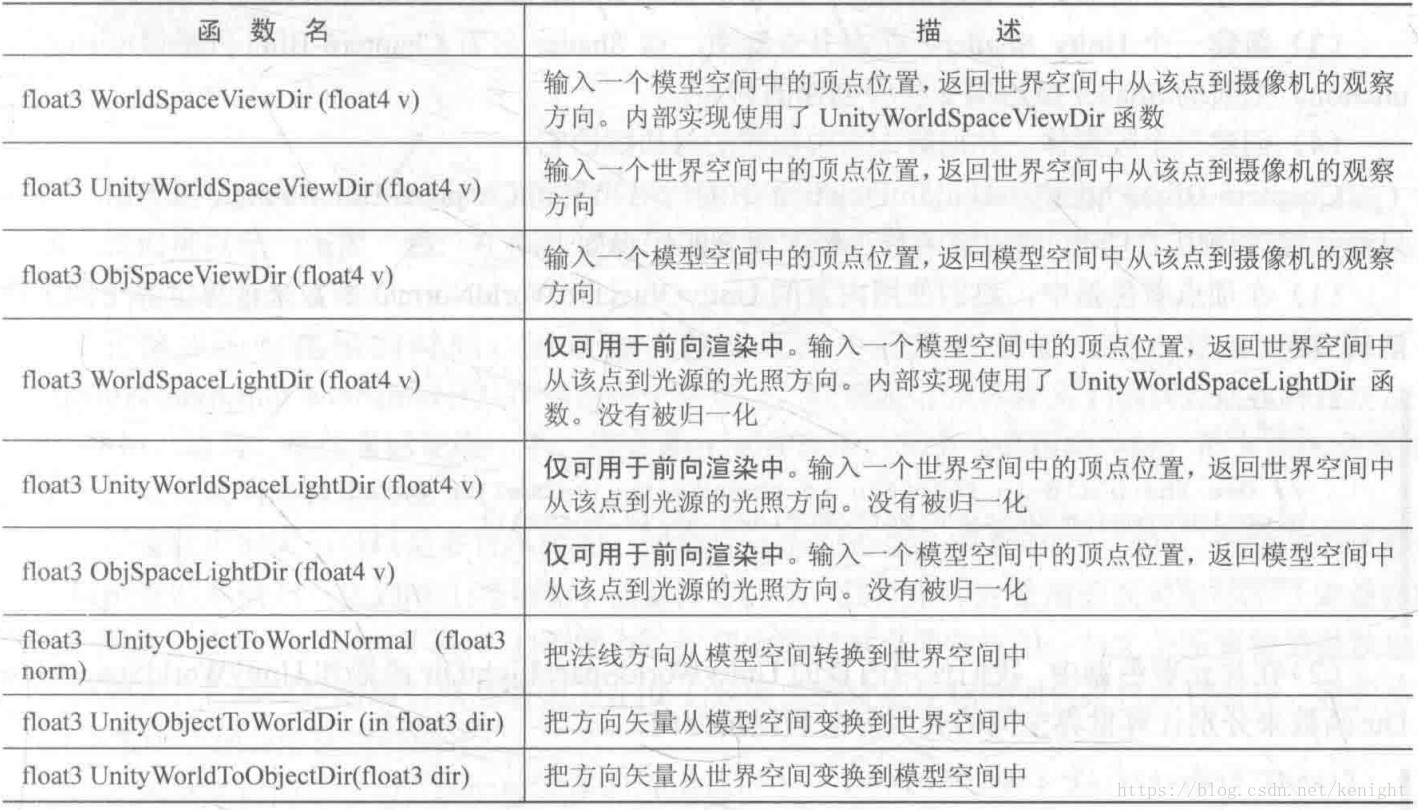
Shader common functions

Error:Kotlin: Module was compiled with an incompatible version of Kotlin. The binary version of its

单片机STM32F103RB,BLDC直流电机控制器设计,原理图、源码和电路方案

火线,零线,地线,你知道这三根线的作用是什么吗?
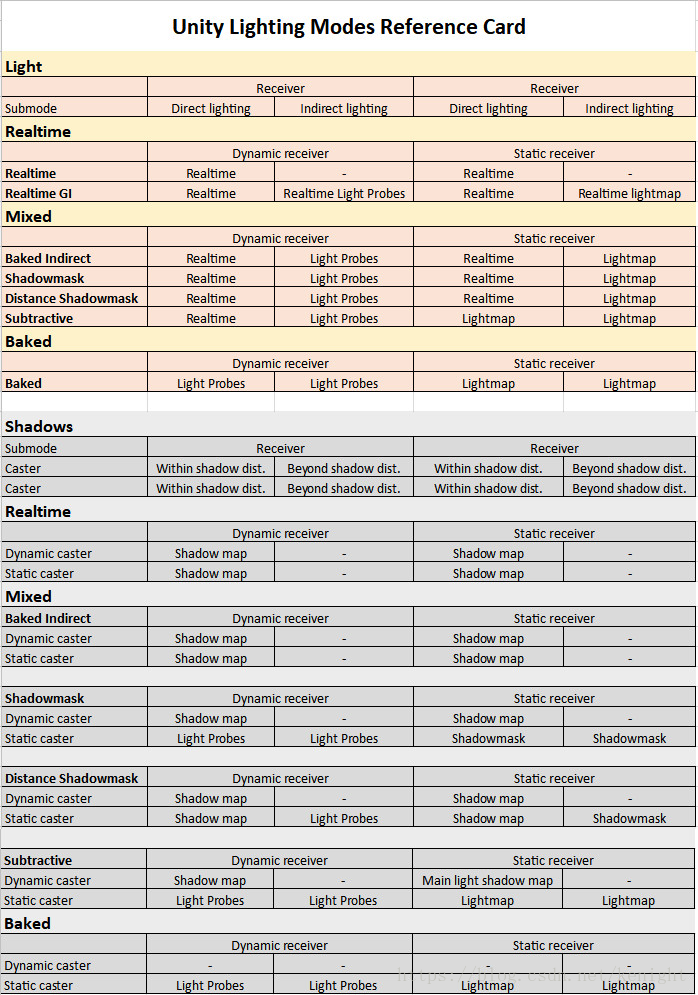
Simple summary of lighting usage

Leetcode 207: course schedule (topological sorting determines whether the loop is formed)
随机推荐
L1-019 谁先倒 (15 分)
Configure your own free Internet domain name with ngrok
js实现查看一个数组对象中是否包含另一个数组对象中的值
Oracle advanced SQL qualified query
5g industrial router Gigabit high speed low delay
Cloud development who is the source code of undercover applet
解决笔记本键盘禁用失败问题
Pipeline concept of graphic technology
Redolog and binlog
Moonwell Artemis现已上线Moonbeam Network
1-4metasploitable2介绍
Introduction of model compression tool based on distiller
Signature analysis of app x-zse-96 in a Q & a community
[008] filter the table data row by row, jump out of the for cycle and skip this cycle VBA
Smart pointer remarks
第 3 篇:绘制三角形
一文理解同步FIFO
Any remarks
BOM notes
Keep one decimal place and two decimal places