当前位置:网站首页>[machine learning] wuenda's machine learning assignment ex2 logistic regression matlab implementation
[machine learning] wuenda's machine learning assignment ex2 logistic regression matlab implementation
2022-06-23 03:38:00 【Lydia. na】
List of articles
Content review
1.1 The hypothesis is that
h ( x ) = g ( θ T X ) h(x)=g(\theta ^TX) h(x)=g(θTX)
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
h θ ( x ) h_\theta(x) hθ(x) The role of is , For a given input variable , Calculate the output variable according to the selected parameter =1 The possibility that h θ ( x ) = P ( y = 1 ∣ x ; θ ) h_\theta(x)=P(y=1|x;\theta) hθ(x)=P(y=1∣x;θ)
Hypothesis simplification results in
h ( x ) = 1 1 + e − θ T x h(x)=\frac{1}{1+e^{-\theta ^Tx}} h(x)=1+e−θTx1
1.2 Determine the boundary

The function that separates the regions is the dividing line of the model .
1.3 Cost function
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) l o g ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) l o g ( 1 − x ( i ) ) ) ] J(\theta )=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta (x^{(i)}))-(1-y^{(i)})log(1-x^{(i)}))] J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−x(i)))]
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) \frac{\partial J(\theta )}{\partial \theta _j}=\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x^{(i)} ∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))x(i)
1.4 Advanced optimization
Gradient descent can be used to calculate the cost function and the partial derivative of the cost function . However, there are some more advanced algorithms to solve the above two : The local optimization method is also called conjugate gradient method (BFGS) And finite memory local optimization (LBFGS). Algorithm advantages : There is no need to manually select the learning rate in any of these algorithms α \alpha α, It has an intelligent internal loop , It is called linear search , You can automatically try different learning rates .
1.5 Regularization
Add regularization term to solve over fitting problem .
The cost function of regularized linear regression :
J ( θ ) = 1 2 m ∑ i = 1 m [ ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 m θ j 2 ] J(\theta )=\frac{1}{2m}\sum_{i=1}^{m}[(h_\theta (x^{(i)})-y^{(i)})^2+\lambda \sum_{j=1}^{m}\theta_j^{2}] J(θ)=2m1i=1∑m[(hθ(x(i))−y(i))2+λj=1∑mθj2]
θ j : = θ j ( 1 − a λ m ) − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j :=\theta_j(1-a\frac{\lambda }{m})-a\frac{1}{m}\sum_{i=1}^{m}(h_\theta (x^{(i)})-y^{(i)})x_j^{(i)} θj:=θj(1−amλ)−am1i=1∑m(hθ(x(i))−y(i))xj(i)
Regularized logistic regression model :
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) l o g ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) l o g ( 1 − x ( i ) ) ) ] + λ 2 m ∑ i = 1 m θ j ( i ) J(\theta )=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta (x^{(i)}))-(1-y^{(i)})log(1-x^{(i)}))]+\frac{\lambda }{2m} \sum_{i=1}^{m}\theta _j^{(i)} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−x(i)))]+2mλi=1∑mθj(i)
ex2 Logistic regression operation
2.1 Part 1: Plotting mapping
Data set meaning : The dataset has 100 Student's two exam results ( Deposit in X in ), It is proposed to use logistic regression ( A dichotomous model ), Estimate the admission probability of each student ( Admission indicates output y by 1, On the contrary, output y by 0).
Matlab
The main function
% Extract the data
data = load(‘ex2data1.txt’);
X = data(:, [1, 2]); y = data(:, 3);
% Load sub functions plotData
plotData(X, y);
% Set up x、y Axis
hold on;
% Labels and Legend
xlabel(‘Exam 1 score’)
ylabel(‘Exam 2 score’)
% Add legend
legend(‘Admitted’, ‘Not admitted’)
hold off;
plotData.m
pos = find(y==1); neg = find(y==0);
plot(X(pos, 1),X(pos,2), 'k+', 'LineWidth', 2, 'markersize',7);
plot(X(neg, 1),X(neg,2), 'ko', 'MarkerFaceColor', 'y');
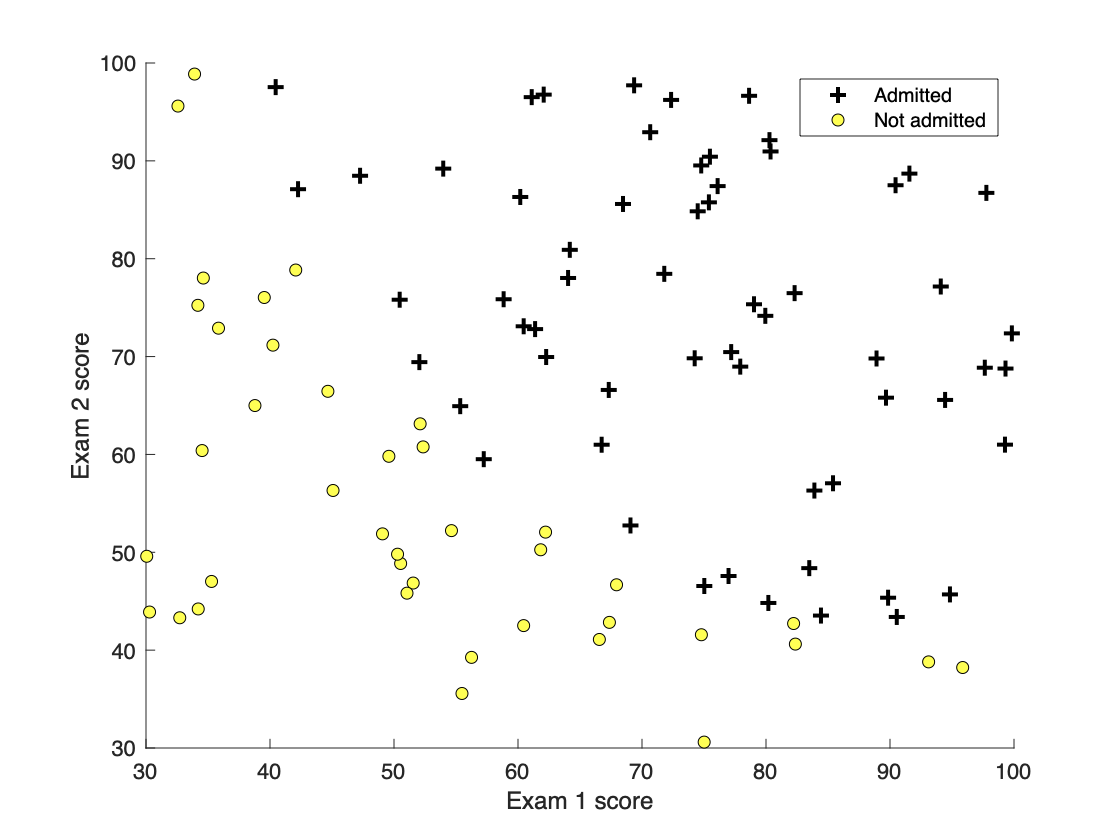
2.2 Part 2: Compute Cost and Gradient Calculation cost and gradient
The main function
% Deposit in X The line of / Number of columns
[m, n] = size(X);
% initialization X、theta
X = [ones(m, 1) X];
initial_theta = zeros(n + 1, 1);
% Compute and display initial cost and gradient
[cost, grad] = costFunction(initial_theta, X, y);
% Compute and display cost and gradient with non-zero theta
test_theta = [-24; 0.2; 0.2];
[cost, grad] = costFunction(test_theta, X, y);
computeCost.m
J = (1/m)*(-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)));
grad =(1/m)*X'*(sigmoid(X*theta)-y);
2.3 Part 3: Optimizing using fminunc utilize fminuc Function optimization
No code is required for this section , according to fminuc Functions and plot Function to draw the decision boundary line .
2.4 Part 4: Predict and Accuracies Prediction and accuracy calculation
The main function
prob = sigmoid([1 45 85] * theta);
p = predict(theta, X);
fprintf(‘Train Accuracy: %f\n’, mean(double(p == y)) * 100);
predict.m
G =sigmoid(X*theta);
for i= 1 :m
if G(i)<0.5
G(i)=0;
else
G(i)=1;
end
end
ex2 The logical regression of regularization
Practical significance : I have a batch of chips tested twice and whether they are qualified or not , Hope to build a logistic regression model , According to the test data of the new chip, we can predict whether it is qualified or not .
3.1 Part 1: Regularized Logistic Regression Regularized logistic regression
First, data falsification , Secondly, the regularization coefficient is loaded λ \lambda λ The cost function of , Get the picture below :
When the decision boundary is no longer a straight line , You need a complex polynomial to represent , And as the polynomial becomes more complex , The higher the degree of fit , The over fitting phenomenon will be achieved , In this case, regular terms can be added to make use of λ \lambda λ To reduce θ \theta θ The effect of parameters .
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) l o g ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) l o g ( 1 − x ( i ) ) ) ] + λ 2 m ∑ i = 1 m θ j ( i ) J(\theta )=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta (x^{(i)}))-(1-y^{(i)})log(1-x^{(i)}))]+\frac{\lambda }{2m} \sum_{i=1}^{m}\theta _j^{(i)} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−x(i)))]+2mλi=1∑mθj(i)

costFunctionReg.m
theta_1 =[0;theta(2:end)];
reg=lambda/(2*m)*theta_1'*theta_1;
J=1/m*(-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)))+reg;
grad=1/m*X'*(sigmoid(X*theta)-y)+lambda/m*theta_1;

3.2 Part 2: Regularization and Accuracies Regularization and accuracy
Similar to the above logistic regression , adopt fminunc Get the minimum cost function theta value , Draw the decision boundary on the graph .
3.3 Compare different regularization parameters
l a m b d a = 0 lambda=0 lambda=0
l a m b d a = 100 lambda=100 lambda=100
From this we can get the appropriate l a m b d a lambda lambda It can effectively avoid the over fitting problem and ensure the fitting degree of the test set data .
Reference article :
Machine learning programming assignments ex2(matlab/octave Realization )- Wu enda coursera
Matlab Wuenda machine learning programming practice ex2: Logical regression Logistic Regression
边栏推荐
- Flink practice tutorial: advanced 7- basic operation and maintenance
- An implementation of universal interface caching Middleware
- YouTube security scenarios
- How to implement collection sorting?
- What are the advantages and difficulties of introducing AI into ISP Technology
- 【owt】owt-client-native-p2p-e2e-test vs2017构建 4 : 第三方库的构建及链接p2pmfc.exe
- Easygbs service is killed because the user redis is infected with the mining virus process. How to solve and prevent it?
- Analysis on the development of China's satellite navigation industry chain in 2021: satellite navigation is fully integrated into production and life, and the satellite navigation industry is also boo
- Initialize MySQL Gorm through yaml file
- Jmeter- (V) simulated user concurrent login for interface test
猜你喜欢

Jmeter- (V) simulated user concurrent login for interface test

Gakataka student end to bundle Version (made by likewendy)

直接插入排序
![Analysis of China's integrated circuit industry chain in 2021: huge downstream market demand [figure]](/img/de/d73805aaf4345ca3d2a7baf85aab8d.jpg)
Analysis of China's integrated circuit industry chain in 2021: huge downstream market demand [figure]

1-1VMware介绍

Svn local computer storage configuration

Banknext microservice: a case study

【owt】owt-client-native-p2p-e2e-test vs2017构建2 :测试单元构建及运行

Analysis on the development of duty-free industry in Hainan Province in 2021: the implementation of the new policy makes the duty-free market in Hainan more "prosperous" [figure]

嵌入式软件测试工具TPT18更新全解析
随机推荐
How to print array contents
How to share small programs released by wechat
Analysis on development history, industrial chain, output and enterprise layout of medical polypropylene in China in 2020 [figure]
Brief introduction to arm architecture
JS Part 4
Static code block, code block, constructor execution order
Generate PDF417 code in batch through TXT file
线上MySQL的自增id用尽怎么办?
2022-01-22: Li Kou 411, the abbreviation of the shortest exclusive word. Give a string number
Not just offline caching- On how to make good use of serviceworker
1058 multiple choice questions (20 points)
Insert sort directly
How to print multiple barcode labels on one sheet of paper
Chapter IV open source projects and deployment
Ultra detailed Apache and PHP installation tutorial windows (2022.1)
【贪心】leetcode991. Broken Calculator
How to get started with apiccloud app and multi terminal development of applet based on zero Foundation
Regeorg actual attack and defense
One of the touchdesigner uses - Download and install
Bi skills - authority control