当前位置:网站首页>Tips and tricks for neural networks deep learning and training skills summary (updated from time to time)
Tips and tricks for neural networks deep learning and training skills summary (updated from time to time)
2022-07-23 16:57:00 【iioSnail】
List of articles
This article suggests that
This article mainly records the summary of some skills encountered in the process of in-depth learning , In this way, if the effect of training the model is not good, come and see what can be used . Irregular update ( When you learn new knowledge, you will update it )
Debug skill
Overfit A simple Batch
Before the actual training , First find a simple Batch, Try to train it , send model Sure overfit This batch. If the model cannot successfully put loss Drop to close 0, It indicates that there is a problem with the model .
Common mistakes are as follows :
- loss Gradually get bigger : See which symbol is written upside down
- loss bulge : Maybe the learning rate is too high , Cause to diverge
- loss Up and down (oscillate): Try to reduce the learning rate , And check whether there are errors in the data Label, Or data enhancement (Data Augmentation) There's something wrong with the way
- loss The back cannot be lowered (plateau): Try to increase the learning rate , Get rid of Regulation
TODO, The first 4 There are some questions
Data processing
Balance data
Data imbalance : There is too much data in some categories , These categories are called majority class; And there are too few category data , These categories are called minority class
Common treatment methods :
- Undersample: Delete some directly majority class The data of
- Oversample: Make some by yourself minority class The data of , for example ,① Use SMOTE(Synthetic Minority Over-sampling Technique),② Data to enhance (Data Augmentation)
Set the bias of the output layer
For unbalanced datasets, the initial guesses of the network inevitably fall short. Even though the network learns to account for this, setting a better bias at model creation can reduce training times. For the sigmoid layer, the bias can be calculated as (for two classes):
bias = log(pos/negative)
When you create the model, you set this value as the initial bias.
Data to enhance (Data Augmentation)
Image enhancement
use Random image cropping and patching (RICAP) Method . The idea is : Randomly crop a part of multiple pictures , Then put them together into a picture , At the same time, mix the labels of these pictures .
Cutout: Block an area of the picture randomly ( All pixel values are set to 0). Objects used to simulate real images may be blocked by other objects

random erasing: similar cutout, The difference lies in ,cutout Is to set the pixel value of the rectangular area randomly selected in the picture to 0, Equivalent to cutting off ,random erasing Is to replace the original pixel value with a random number or the average value of pixels in the dataset . and ,cutout The size of the area cropped each time is fixed ,Random erasing The size of the replaced area is random .

AutoAugment: Use AutoAugment Automatically select a data enhancement strategy suitable for a specific dataset .
Use Embedding Data compression data
Try not to use one-hot code , But use embedding Compress feature dimensions .
Standardization (Normalization)
For numeric data , It's best to shrink it to [-1,1] In the range of , The purpose is to accelerate convergence .
Label smoothing (LabelSmoothing)
For the classification problem , May adopt Label smoothing (Label-smoothing regularization, LSR) Avoid over fitting . Its specific idea is to reduce our trust in labels , For example, we can change the target value of loss from 1 Slightly lower to 0.9, Or from 0 Rise slightly to 0.1.
Smoothing the label can reduce the size of the model overconfidence The situation of , Thus reducing overfitting.
for example : The label is [0, 0, 0, 1, 0], After smoothing the label , The label changes to [0.05, 0.05, 0.05, 0.8, 0.05].
Hyperparameters
Hyperparametric regulation
The top priority is the super parameter , Or the most important super parameter is Learning rate (Learning Rate)
Batch Size
Choose to be 4 Divisible Batch Size, Or select 2 n 2^n 2n .
Dropout
- dropout It's better to control 20%-50% Between . Because it is too low and the impact is not enough , Too high will easily make the model result worse
- Use a larger network. You are likely to get better performance when dropout is used on a larger network, giving the model more of an opportunity to learn independent representations.(TODO, How to understand this sentence )
- Use dropout on incoming (visible) as well as hidden units. Application of dropout at each layer of the network has shown good results.(TODO, How to understand this sentence )
Learning Rate
- Adam It is said that the best learning rate is 3e-4
- Try to adopt Warmup To adjust the learning rate , The principle is : At first, the model was not very stable , So the learning rate is a little lower , Then slowly increase the learning rate , In a certain time epoches after , Then slowly reduce the learning rate
- The learning rate should increase with batch size Make changes .batch size The bigger it is , The smaller the noise in the gradient , So when batch When I was big , The learning rate can be higher , and batch size When I was a child , The learning rate should be lower . for example ,batch size by 256 The learning rate chosen is 0.1, When we put batch size Become a larger number b when , The learning rate should become 0.1 × b/256
- use AdaBound( You can try it , The author says AdaBound It will make your training process like adam As fast as , And like SGD As good as ).
model building
Number of neurons
For dense layers (dense layer), Input neurons and outputs The number of neurons can best be 64 to be divisible by .
Convolution layer
For the convolution layer , Input layer and output layer channel Better be 4 Multiple , or 2 n 2^n 2n.
For the convolution layer , The number of inputs and outputs can best be 64 to be divisible by
pad image inputs from 3 (RGB) to 4 channels(TODO, Don't understand, )
Feature fusion of different scales ( for example YOLOv3-SPP).
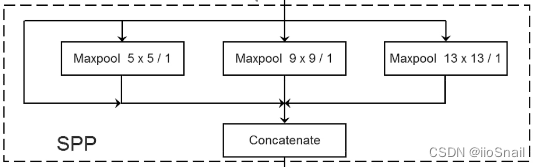 for example , Use the output of the above convolution layer with different sizes maxpooling Layer for down sampling , And integrate their respective results and send them to the next network .
for example , Use the output of the above convolution layer with different sizes maxpooling Layer for down sampling , And integrate their respective results and send them to the next network .Low level features and high-level features are fused . That is, the output of the front convolution layer and the output of the rear convolution layer concat together , Then carry out subsequent convolution
Use Residual block (residual block) Prevent the gradient from disappearing . May refer to ResNet
If the network is too big , You can try to use Depthwise Conv(DW) Convolution + Pointwise Conv(PW) Convolution Come on Reduce network parameters and computation . May refer to MobileV1
Circulation layer (Recurrent Layer)
about Recurrent Layer,Batch Size and Hidden Size It is best to 4 The integer of , Ideally , It is best to 64、128 or 256 Multiple
about Recurrent Layer,Batch Size Better be bigger
Use the pre training model (Pretrained Model)
Pre training model : As a model “ The upstream ” Model , The big factory is pre trained by cattle , Then use the results of this model “ The downstream ” Mission . for example :“BERT” It's a pre training model , Use Bert Can be right Token( word ) Conduct Embedding, Then connect it to your “ The downstream ” Model , Training for specific tasks
Use transfer learning (Transfer Learning)
The migration study : Train others well “ Task specific ” Bring the model , And then put “ Mission ” Change to your own specific task , And then training .
The difference between pre training model and transfer learning ( Personal understanding ):
The pre training model is not specific to specific tasks , such as “Bert”, It's for NLP field , But not for specific tasks , You can take Bert The output of is then connected to the model “ Sentiment analysis ”、“ Part of speech tagging ” Anything is OK .;
But transfer learning uses a task specific model , For example, Zhang San trained a model to analyze emotions , Then you take it as a trained model , Change the last few floors , Then used for part of speech tagging , This is transfer learning .
model training
- Keep regularly : During training , It is best to save the model regularly , Prevent problems such as system crash during training from causing model loss , There's no place to cry , We can only start from scratch . If saved regularly , You can start from the previous Save it (Checkpoint) Start .
- Early stop (EarlyStopping) : To prevent fitting , You can stop training in advance . The common termination strategy is : Use validation data sets to validate model performance , If in n n n individual step Inside , The performance of the model has not been improved , You can stop .
- Distillation of knowledge (Knowledge Distillation) : If you want to train a smaller model ( For example, it should be deployed on mobile devices ), Using the output of a large and high accuracy pre training model as a label is better than using a real label .
- Model EMA(Model Exponentially weighted averages): The parameter update of the model will not only consider this , Will also consider the previous , Can improve the performance of the model . Reference link
TODO
https://arxiv.org/abs/1708.02002 section 3.3
nn.init.kaiming_normal_
class weights
Reference material
Tips and tricks for Neural Networks: https://towardsdatascience.com/tips-and-tricks-for-neural-networks-63876e3aad1a
Tips For Using Dropout: https://machinelearningmastery.com/dropout-regularization-deep-learning-models-keras/
Deep neural network model training tricks( Principle and code summary ):https://mp.weixin.qq.com/s/qw1mDd1Nt1kfU0Eh_0dPGQ
边栏推荐
- 【31. 走迷宫(BFS)】
- 【Flutter -- 布局】弹性布局(Flex 和 Expanded)
- Advanced authentication of uni app [Day12]
- 学习MySQL这一篇就够了
- 面试官:生成订单30分钟未支付,则自动取消,该怎么实现?
- Heartless sword English Chinese bilingual poem 006. to my wife
- Deep learning convolutional neural network paper study alexnet
- 启牛商学院上面开户安全不
- Satisfiability of the equation of leetcode
- How does MySQL query data that is not in the database?
猜你喜欢

TS encapsulates the localstorage class to store information
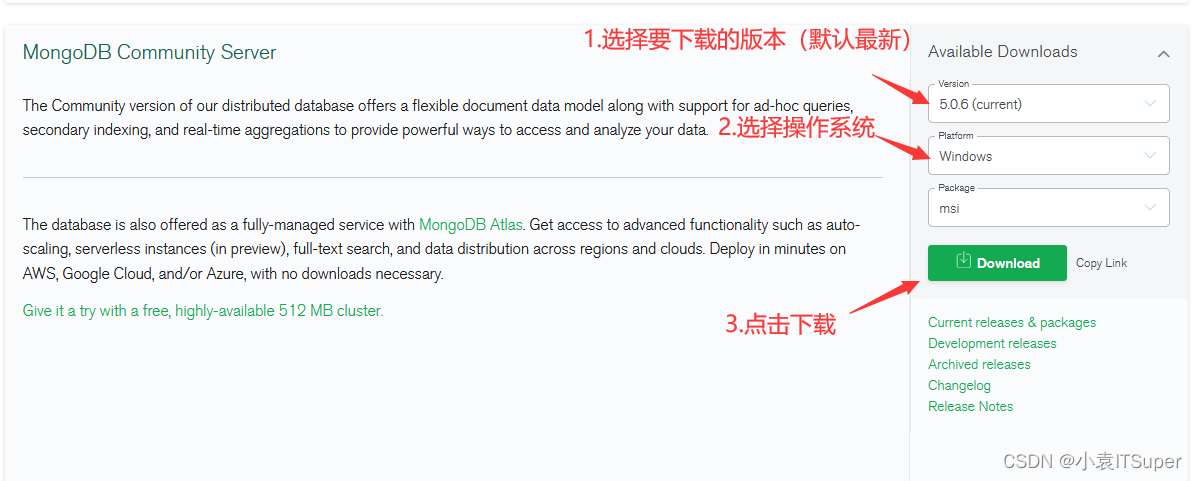
MongoDB数据库+图形化工具下载安装及使用

tensorflow2.X实战系列softmax函数

检测器:用递归特征金字塔和可切换的阿托洛斯卷积检测物体

Using "soup.h1.text" crawler to extract the title will be one more\

【TensorFlow】检测TensorFlow GPU是否可用

Case analysis of building campus information management system with low code

Eureka notes

一款非常棒的开源微社区轻论坛类源码

UPC 2022暑期个人训练赛第12场(B 组合数)
随机推荐
微信小程序wx.hideLoading()会关闭toast提示框
浏览器同源策略
UiPath Studio Enterprise 22.4 Crack
Ie box model and standard box model
深度学习卷积神经网络论文研读-AlexNet
FreeRTOS个人笔记-挂起/解挂任务
Acquisition of positional reliability in accurate target detection
Frequently asked questions about MySQL
Four cores of browser
Bag of tricks for image classification "with convolutional neural networks"
fio性能测试工具
VMware虚拟机的三种网络模式
【30. n-皇后问题】
FreeRTOS个人笔记-延时函数
Priyanka Sharma, general manager of CNCF Foundation: read CNCF operation mechanism
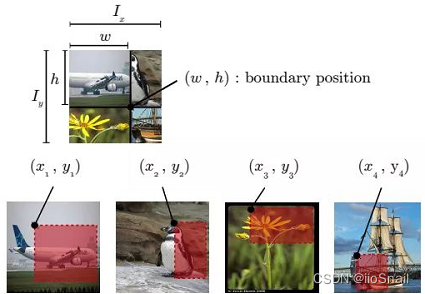
Distance IOU loss: faster and better learning for bounding box regression
AutoCAD基本操作
Direct exchange
三方支付公司有哪些?
面试官:生成订单30分钟未支付,则自动取消,该怎么实现?