当前位置:网站首页>Beam search and five optimization methods
Beam search and five optimization methods
2022-06-25 08:24:00 【Happy little yard farmer】
List of articles
Beam Search And optimization
1. Review Beam Search
Reference resources : Wu enda Deep learning note Course 5 Week 3 Sequence Models
review beam search:
Yes greedy search Improved : Expand the search space , It is easier to get the global optimal solution .beam search Contains a parameter beam width B B B, Indicates that the highest score is reserved for each time step B A sequence of , Then use this next time step B B B Candidate sequences continue to be generated .


stay sequence models in ,input text { x < 1 > , … , x < T x > } \{x^{<1>},\dots,x^{<T_x>}\} { x<1>,…,x<Tx>} Input Encoder, Re pass Decoder,softmax The layer will output the word list size ∣ V ∣ |V| ∣V∣ Output probability values .
Beam Search Steps for :
- Find the probability value of the first output P ( y < 1 > ∣ x ) P(y^{<1>}|x) P(y<1>∣x), Take the largest front B B B Save words .
- Calculate the front... Separately B B B In two cases Decoder Output P ( y < 2 > ∣ x , y < 1 > ) P(y^{<2>}|x,y^{<1>}) P(y<2>∣x,y<1>), There will be a B ⋅ ∣ V ∣ B\cdot|V| B⋅∣V∣ results , Maximize the probability of the entire sentence P ( y < 1 > , y < 2 > ∣ x ) = P ( y < 1 > ∣ x ) P ( y < 2 > ∣ x , y < 1 > ) P(y^{<1>},y^{<2>}|x)=P(y^{<1>}|x)P(y^{<2>}|x,y^{<1>}) P(y<1>,y<2>∣x)=P(y<1>∣x)P(y<2>∣x,y<1>), That is the first one. 、 The second word pair has the greatest probability , Choose the one with the highest probability B B B Results and save .
- Every step B B B A network copy , To assess the probability of the next word . Continue calculation and select , Until the end of the sentence appears
<EOS>.
Wu Enda's Andrew Ng Of Coursera In depth learning courses Beam Search Of Refinement, As below Normalization The first part of .
Here I sum up Beam Search There are several types of optimization methods :
- Hypothesis filtering: Filter the generated candidate sequences .
- Normalization: in the light of Beam Search Improvement of score function .
- Decoding with auxiliary language model: Use the auxiliary language model to improve decoder.
- Decoding with lexical constraints: Add restrictions on words or phrases ,decoder You need to refer to the restricted vocabulary when generating .
- Search algorithms: Optimize your search strategy , Looking for more efficient algorithms .
2. Beam Search Refinement
2.1 Hypothesis filtering
By controlling (unkown words) Quantity is right beam search Generated hypotheses Conduct filtering. When one hypothese It contains too much It can be drop fall . It should be noted that ,drop hypotheses Will temporarily reduce beam size.
2.2 Normalization
It's mainly about beam search To improve the score function , Including the length of the output sentence and coverage Add penalty .
2.2.1 Length Normalization
Reference resources : Wu enda Deep learning note Course 5 Week 3 Sequence Models
Beam Search To maximize the probability P ( y < 1 > , … , y < T y > ∣ X ) P(y^{<1>},\dots,y^{<T_y>}|X) P(y<1>,…,y<Ty>∣X), That is, the probability of measuring the whole sentence , It can be expressed as the product of conditional probabilities :
P ( y < 1 > , … , y < T y > ∣ X ) = P ( y < 1 > ∣ X ) P ( y < 2 > ∣ X , y < 1 > ) P ( y < 3 > ∣ X , y < 1 > , y < 2 > ) … P ( y < T y > ∣ X , y < 1 > , y < 2 > , … , y < T y − 1 > ) P(y^{<1>},\dots,y^{<T_y>}|X)=P(y^{<1>}|X)P(y^{<2>}|X,y^{<1>})P(y^{<3>}|X,y^{<1>},y^{<2>})\dots P(y^{<T_y>}|X,y^{<1>},y^{<2>},\dots,y^{<T_y-1>}) P(y<1>,…,y<Ty>∣X)=P(y<1>∣X)P(y<2>∣X,y<1>)P(y<3>∣X,y<1>,y<2>)…P(y<Ty>∣X,y<1>,y<2>,…,y<Ty−1>)
Because every conditional probability is less than 1, Multiple less than 1 Multiply the values of , It will cause the value to go down (numerical underflow). The value is too small , As a result, the floating-point representation of the computer cannot be accurately stored , So we can't maximize this product in practice , It's about taking l o g log log value .
Maximize l o g P ( y ∣ x ) logP(y|x) logP(y∣x) The probability value of summation , The value is more stable , Not prone to numerical error (rounding errors) Or numeric underflow . Because the logarithmic function ( l o g log log function ) Is a strictly monotonically increasing function , Maximize l o g P ( y ∣ x ) logP(y|x) logP(y∣x) And maximize P ( y ∣ x ) P(y|x) P(y∣x) It is equivalent. . In practice , We always record the logarithm sum of probabilities (the sum of logs of the probabilities), Not the product of probability (the production of probabilities).
The conclusion is right beam search Improvement of the objective function of :
- about beam search The original objective function of
a r g max y ∏ t = 1 T y P ( y < t > ∣ X , y < 1 > , … , y < t − 1 > ) arg \max_{y} \prod_{t=1}^{T_y}P(y^{<t>}|X,y^{<1>},\dots,y^{<t-1>}) argymaxt=1∏TyP(y<t>∣X,y<1>,…,y<t−1>)
If a sentence is long , Then the probability of this sentence will be very low , Because multiple less than 1 Multiply the numbers of to get a smaller probability value . This objective function tends to have short output , Because the probability of short sentences is less than 1 The product of the numbers obtained by .
- For the improved beam search The objective function of
a r g max y ∑ t = 1 T y l o g P ( y < t > ∣ X , y < 1 > , … , y < t − 1 > ) arg \max_{y} \sum_{t=1}^{T_y}logP(y^{<t>}|X,y^{<1>},\dots,y^{<t-1>}) argymaxt=1∑TylogP(y<t>∣X,y<1>,…,y<t−1>)
Every probability P ( y ∣ x ) ∈ ( 0 , 1 ] P(y|x)\in(0,1] P(y∣x)∈(0,1], and l o g P ( y ∣ x ) log P(y|x) logP(y∣x) It's a negative number . If the sentence is long , Add up to a lot of items , The more negative the result is . So this objective function will also affect the longer output , Because long sentences always accumulate the value of the objective function will be very small .
- improvement beam search: Introduce normalization , Reduce the penalty for outputting long sentences .
a r g max y 1 T y α ∑ t = 1 T y l o g P ( y < t > ∣ X , y < 1 > , … , y < t − 1 > ) arg \max_{y} \frac{1}{T_y^{\alpha}}\sum_{t=1}^{T_y}logP(y^{<t>}|X,y^{<1>},\dots,y^{<t-1>}) argymaxTyα1t=1∑TylogP(y<t>∣X,y<1>,…,y<t−1>)
α ∈ [ 0 , 1 ] \alpha\in [0,1] α∈[0,1] It's a super parameter , Usually take α = 0.7 \alpha=0.7 α=0.7. The value is tentative , You can try different values , See which one gets the best results .
- α = 0 \alpha=0 α=0, No .
- α = 1 \alpha=1 α=1, Standard length normalization .
stay Beam Search Finally, use the above formula to choose the best sentence .

How to choose B B B?
- B B B The bigger it is (10~100), The more you think about , Get better results , The greater the amount of calculation , The slower the speed .
- B B B Take small (1~10), The results may not be good enough , Fast calculation .
- General choice B = 10 B=10 B=10.
Beam Search And DFS/BFS Different , Is an approximate search algorithm / Heuristic algorithm , Not looking for the global optimum , But to find the local optimum .
In the actual project , How to find out is RNN There's something wrong with the model , still Beam Search Something went wrong. ?
increase B B B Generally, the model will not be affected , It's like adding data sets .


Beam Search Error analysis in :
In the translation task , y ∗ y^* y∗ Indicates the result of human translation , y ^ \hat{y} y^ Represents the result of the algorithm .
use RNN Model calculation P ( y ∗ ∣ x ) P(y^*|x) P(y∗∣x) and P ( y ^ ∣ x ) P(\hat{y}|x) P(y^∣x), That is to compare the expected value probability with the output probability , To discover that RNN still Beam Search The problem of .
Case one : P ( y ∗ ∣ x ) > P ( y ^ ∣ x ) P(y^*|x)>P(\hat{y}|x) P(y∗∣x)>P(y^∣x),Beam Search error .
The probability of expectation is higher , however Beam Search No expectations selected , yes Beam Search The problem of , By increasing B To improve .
The second case : P ( y ∗ ∣ x ) ≤ P ( y ^ ∣ x ) P(y^*|x)\le P(\hat{y}|x) P(y∗∣x)≤P(y^∣x),RNN Model error , Need to be in RNN Spend more time on the model .
RNN The model gives the probability of error P ( y ∗ ∣ x ) P(y^*|x) P(y∗∣x), Give a good sentence a small probability . You can use regularization , Larger training data , Different network structures and other methods are improved .
If length normalization is used , It is necessary to use the normalized value to judge .
The error analysis process is shown in the figure below , First traversal development set, Find out the error caused by the algorithm . for example , P ( y ∗ ∣ x ) = 2 × 1 0 − 10 , P ( y ^ ∣ x ) = 1 × 1 0 − 10 P(y^*|x)=2\times 10^{-10}, P(\hat{y}|x)=1\times 10^{-10} P(y∗∣x)=2×10−10,P(y^∣x)=1×10−10, In the first case ,Beam Search error . The error types are marked in turn , Through this error analysis process , obtain Beam Search and RNN What is the proportion of model errors . If you find that Beam Search Cause most mistakes , Can increase beam width. contrary , If you find that RNN Models cause more errors , Deeper analysis can be done : Whether to add regularization 、 Get more training data 、 Try a different network structure or other solution .

2.2.2 Coverage Normalization
The paper 1:Coverage-based Neural Machine Translation
The paper 2:Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation
There will be Beam Search The objective function of is called Beam Search Scoring function score. Log likelihood as score function , As shown below ,Beam Search Will tend to be shorter sequences . introduce length normalization Normalizing the length can solve this problem .
s c o r e ( x , y ) = ∑ t = 1 T y l o g P ( y t ∣ x , y < t ) score(x,y)=\sum_{t=1}^{T_y}logP(y_t|x,y_{<t}) score(x,y)=t=1∑TylogP(yt∣x,y<t)
2016 Nian Hua is a member of Noah's Ark laboratory The paper 1 mention , Machine translation will exist over translation or undertranslation due to attention coverage . The author puts forward coverage-based atttention Mechanism to solve coverage problem .
Google’s Neural Machine Translation System Of The paper 2<7. Decoder> Put forward length normalization and coverage penalty.coverage penalty It is mainly used for Attention The occasion of , adopt coverage penalty It can make Decoder Focus evenly on the input sequence x Every one of token, Prevent some token Get too much Attention.
The paper 2 Log likelihood 、length normalization and coverage penalty Bind together , You can get new beam search Scoring function , As the formula below shows , among X X X yes source, Y Y Y It is the present. target, l p lp lp yes length normalization, c p cp cp yes coverage penalty, p i , j p_{i,j} pi,j It's No j j j individual target Corresponding to the first i i i One input Attention value . Hyperparameters α \alpha α and β \beta β Each control length normalization and coverage penalty. If α = 0 & β = 0 \alpha=0 \;\& \;\beta=0 α=0&β=0,Decoder Just return it to the normal Beam Search.
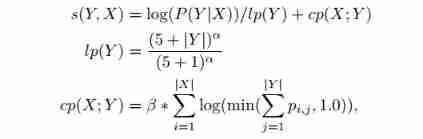
2.2.3 End of sentence Normalization
Reference resources :Beam search
Sometimes Decoder Generating sequences is hard to stop , At this point, you need to control the maximum generation length , You can use the following formula to constrain :
e p ( X , Y ) = γ ∣ X ∣ ∣ Y ∣ ep(X,Y)=\gamma\frac{|X|}{|Y|} ep(X,Y)=γ∣Y∣∣X∣
among ∣ X ∣ |X| ∣X∣ yes source The length of , ∣ Y ∣ |Y| ∣Y∣ It is the present. target The length of , γ \gamma γ yes End of sentence normalization The coefficient of . Then we can know from the above formula ,target The longer the length , The lower the above score , This prevents the generation sequence from stopping .
The improved method of score function , There are still a lot of it , For example, there are papers 《 A Diversity-Promoting Objective Function for Neural Conversation Models》 Maximize mutual information MMI(Maximum Mutual Information) As an objective function , It can also be used as Beam Search The score function of .
2.3 Decoding with auxiliary language model
Beam search You can also use an auxiliary language model To define score function, for example “Shallow Fusion”:
s ( Y , X ) = s T M ( Y , X ) + β ⋅ s L M ( Y ) s(Y,X)=s_{TM}(Y,X)+\beta \cdot s_{LM}(Y) s(Y,X)=sTM(Y,X)+β⋅sLM(Y)
among s L M ( Y ) s_{LM}(Y) sLM(Y) Is the output sequence Y Y Y The language model of L M LM LM Logarithmic probability of , β \beta β It's a super parameter . Note the language model L M LM LM Cannot use two-way RNN, Need to work with the translation model T M TM TM Share the same vocabulary ( Marks and features ).
2.4 Decoding with lexical constraints
Add restrictions to the vocabulary , bring beam search Just find the corresponding... At the input source token, Then limit the generation of words or phrases . In the paper Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search Described in Grid Beam Search Method , Accept simple one-token constraints.
2.5 Search algorithms
The paper 《Best-First Beam Search》 Focus on improving Beam Search Search efficiency , Put forward Best-First Beam Search Algorithm ,Best-First Beam Search Can get and in a shorter time standard Beam Search Same search results . It is mentioned in the paper that Beam Search The time is proportional to the number of calls to the scoring function , As shown in the figure below , Therefore, the author hopes to reduce the number of calls to the scoring function , Thus enhance Beam Search efficiency .

Best-First Beam Search A priority queue is used and a new comparison operator is defined , Thus, the number of calls to the scoring function can be reduced , Stop searching faster .
3. References
Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation
【RNN】 Deep grilling can improve the accuracy of prediction beam search
Coursera In depth learning tutorial Chinese Notes
Wu enda Deep learning note Course 5 Week 3 Sequence Models
Detailed introduction Beam Search And its optimization method
Modeling Coverage for Neural Machine Translation
COVERAGE-BASEDNEURALMACHINETRANSLATION
Coverage-based Neural Machine Translation
A Diversity-Promoting Objective Function for Neural Conversation Models
A Diversity-Promoting Objective Function for Neural Conversation Models Paper reading
Welcome to my official account. 【SOTA Technology interconnection 】, I will share more dry goods .

边栏推荐
- TCP stuff
- Is there any risk in making new bonds
- iframe简单使用 、获取iframe 、获取iframe 元素值 、iframe获取父页面的信息
- Modeling and fault simulation of aircraft bleed system
- Go language learning tutorial (13)
- 4 reasons for adopting "safe left shift"
- leetcode. 13 --- Roman numeral to integer
- [supplementary question] 2021 Niuke summer multi school training camp 4-N
- TCP 加速小记
- Scanpy (VII) spatial data analysis based on scanorama integrated scrna seq
猜你喜欢

Daily question brushing record (III)
Internet of things (intelligent irrigation system - Android end)

CVPR 2022 Oral 2D图像秒变逼真3D物体

VOCALOID notes

C disk drives, folders and file operations

How to calculate the correlation coefficient and correlation degree in grey correlation analysis?

Apache CouchDB Code Execution Vulnerability (cve-2022-24706) batch POC

How to calculate the fuzzy comprehensive evaluation index? How to calculate the four fuzzy operators?

TCP stuff

With the beauty of technology enabled design, vivo cooperates with well-known art institutes to create the "industry university research" plan
随机推荐
Luogu p2839 [national training team]middle (two points + chairman tree + interval merging)
Nodehandle common member functions
Electronics: Lesson 012 - Experiment 13: barbecue LED
企业全面云化的时代——云数据库的未来
VOCALOID notes
Luogu p3313 [sdoi2014] travel (tree chain + edge weight transfer point weight)
Jdbc-dao layer implementation
Network model -- OSI model and tcp/ip model
初体验完全托管型图数据库 Amazon Neptune
Luogu p2048 [noi2010] super Piano (rmq+ priority queue)
With the beauty of technology enabled design, vivo cooperates with well-known art institutes to create the "industry university research" plan
Log in to MySQL 5.7 under ubuntu18 and set the root password
FFT [template]
Want to open an account, is it safe to open an online stock account?
[unexpected token o in JSON at position 1 causes and solutions]
Matlab code format one click beautification artifact
Luogu p1073 [noip2009 improvement group] optimal trade (layered diagram + shortest path)
Force buckle 272 Closest binary search tree value II recursion
How to calculate the positive and negative ideal solution and the positive and negative ideal distance in TOPSIS method?
Scanpy(七)基于scanorama整合scRNA-seq实现空间数据分析