当前位置:网站首页>04 distributed resource management system yarn
04 distributed resource management system yarn
2022-07-24 18:32:00 【& goodbye firefly &】
Catalog
3、 ... and ,YARN Resource scheduling strategy
The content of the article comes from : Nanjing University / Star ring technology course , Big data theory and practice course Ⅰ
Supplement the details by quoting other network resources .
One ,YARN brief introduction
1,YARN The origin of
Hadoop 1.x Medium MapReduce There are congenital defects :
- It's a computing framework , It is also a resource management system ;
- Only put Task Quantity is regarded as resources , Not thinking about CPU And memory ;
- Poor scalability , Upper limit of cluster size 4K;
- The source code is difficult to understand , Upgrade maintenance is difficult ;
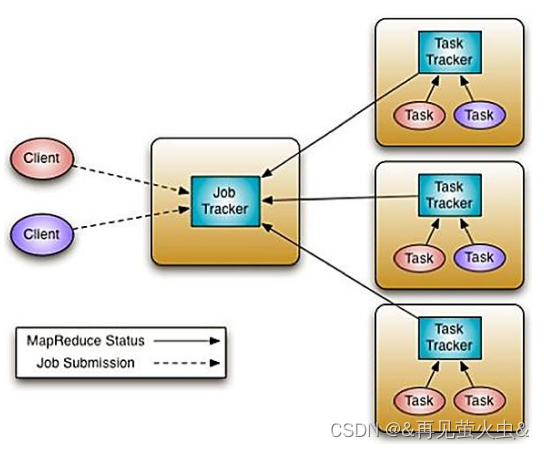
In order to make MR Focus on Computing , So we introduced YARN To be responsible for specific resource management , To improve performance .
2, What is? YARN
YARN,Yet Another Resource Negotiator, Another resource manager
Design objectives : Focus on Resource Management 、 Universal ( Applicable to various calculation frameworks )、 High availability ( Metadata and Master High availability )、 High expansion ( And HDFS Synchronous extension )、 High fault tolerance ( Computational fault tolerance )
YARN The basic idea is to JobTracker Two main functions of ( Resource management and job scheduling / monitor ) Separate , The main method is to create a global ResourceManager(RM) And several for applications ApplicationMaster(AM).ApplicationMaster Assumed the previous TaskTracker Some of my characters ,ResourceManager To undertake the JobTracker Role .

Two ,YARN principle
1, System architecture
1.1 Division of roles
Four characters :ResourceManager、ApplicationMaster( Operation manager )、NodeManager、Client
1, Active ResourceManager(ARM)
- Active resource management node (Master / Cluster unique )
- Unified management of cluster computing resources
- Responsible for starting ApplicationMaster、 Job assignment and monitoring
- Allocate resources to jobs according to certain scheduling strategies
- receive NodeManager Health status and resource reporting information
2,Standby ResourceManager(SRM)
- Hot standby resource management node ( Allow multiple )
- Active standby switching
- -AR After downtime , after Master Election and status information recovery ,SRM Upgrade to ARM
- - restart AM, Kill all running Container
3,ApplicationMaster(AM)
Operation manager
- One on one management : Each job instance is managed by a full-time AM To manage
- Homework analysis : take Job It can be interpreted as several Task Composed of directed acyclic graphs
- Application resources : towards RM apply Job Computing resources needed to run
- Task scheduling and supervision : towards NM Apply for distribution Container And start Task, At the same time monitor Task Operation status and progress
- feedback : towards Client feedback Job Operation status and results
Realization way
- YARN By default MapReduce Of AM Realization , But other computing frameworks need their own job management components ( Such as Spark Driver)
- Adopt asynchronous programming model based on event drive , All events are managed by the central event scheduler
- AM Is an event handler , Register in the central event scheduler , In this way, decoupling can be achieved , In order to ensure that YARN The generality of
4,NodeManager(NM)
- Computing node (Slave / High expansion )
- Manage the resources of a single node
- management Container Life cycle of ( The whole process from creation to destruction )
- towards ResourceManager Report on health and resource usage
5,Container
- Containers : Encapsulation of process related resources , The abstraction of resources , Allocating resources means allocating Container
- There are two kinds of : function AM Of Container 、 function Task Of Container
1.2 design idea
take JobTracker Separation of resource management and operation management functions

1.3 Working mechanism

The basic flow
- Client towards RM Submit the compiled distributed program (Job)
- RM receive Job after , Allocate one NM To start up AM, And will Job Assign to AM, It manages one-on-one
- AM take Job It is resolved into a number of Task Composed of directed acyclic graphs DAG, And from NameNode obtain Task Enter the storage location of the data ( namely Block Storage location ), then towards RM Apply for computing resources
- according to AM The submitted Task Set And the corresponding Block Storage location ,RM by Job Allocate computing resources , namely For each Task Allocate one NM List, And return it to AM( Calculation follows data :NM Where Server Of DataNode It's stored on Task The input of Block)
- according to Task DAG and NM List,AM In parallel / The serial sequence will Task Submit to NM
- NM receive Task, After authentication , start-up Container, function Task, And to AM Report the operation status and progress
- stay Job Operation period ,AM towards Client feedback Job Operation progress and status , And return the final result
1.4 Cluster deployment
Calculation follows data (NodeManager and DataNode On a server , Only in this way can the calculation follow the data )

2,YARN High availability
be based on ZK Of Metadata High availability
- RM state
- Job State and Token( Access authentication )
be based on ZK Of RM High availability ( Active standby switching )
- Master The election
- recovery RM Original status information of
- restart AM, And kill all running Container(task That's too much , And it changes in real time , Bad storage . therefore AM After hanging up ,job dependent task All of them kill fall , Re execution )
Calculation High availability
- Task After failure ,AM It will be dispatched to other NM Re execute ( Default 4 Time )
- Job After failure ,RM Will be in other NM Restart on AM( Default 2 Time )

3、 ... and ,YARN Resource scheduling strategy
1,FIFO Scheduler
Scheduling strategy
- Put all jobs in one queue , The first to get resources in the advanced queue , The homework behind can only wait
shortcoming
- Low resource utilization , Cannot cross run jobs
- Poor flexibility , If you can't cut in line for emergency work , Time consuming jobs slow down the entire queue

2, Capacity scheduler
The core idea
- Make a budget in advance , Share cluster resources under budget guidance
Scheduling strategy
- Cluster resources are shared by multiple queues , Parallelism is the number of queues
- Each queue should preset the resource allocation ratio ( Make a budget in advance , Budget is the guiding principle )
- Idle resources are allocated to “ Actual resources / Budget resources ” The queue with the lowest ratio . For example, there are two queues , queue A Medium resources are occupied 80%, And the queue B Only 10%, Then it is preferentially assigned to the queue B( Stay resilient )
- The queue adopts FIFO Scheduling strategy
characteristic
- Hierarchical queue design : Child queues can use parent queue resources
- Capacity Guarantee : Each queue should preset the resource proportion , Prevent resource monopoly
- Flexible distribution : Free resources can be allocated to any queue , But when multiple queues compete , Will balance proportionally
- Support dynamic management : It can dynamically adjust the capacity of the queue 、 Permissions and other parameters , It can also be dynamically increased 、 Pause queue
- Access control : Users can only submit jobs to their queues , Cannot access other queues
- multi-tenancy : Multiple users share cluster resources

3, Fair scheduler
Scheduling strategy
- Multiple queues share cluster resources fairly
- By way of equal distribution , Dynamic allocation of resources , There is no need to preset the resource allocation ratio , namely “ Don't budget in advance 、 Meet in half 、 Achieve absolute fairness ”
- The scheduling policy can be configured inside the queue :FIFO、Fair( Default )
resource preemption
- Terminate jobs in other queues , Make it give up its occupied resources , then Allocate resources to occupy less than the minimum resource limit Queues ( Keep flexibility by killing the rich and helping the poor )
Queue weight
- When there are jobs waiting in the queue , And when there are idle resources in the cluster , Each queue can obtain different proportions of idle resources according to the weight ( Maintain flexibility through policy preference )

边栏推荐
- Revocable search board
- undefined reference to H5PTopen
- jmeter --静默运行
- Cf. bits and pieces (subset pressing DP + pruning)
- 无关的表进行关联查询及null=null条件
- JMeter -- silent operation
- 2. JS variable type conversion, automatic conversion, manual conversion, what is the difference between parseint(), parsefloat(), number()?
- Ionic4 learning notes 7 -- UI component 1 (no practice, direct excerpt)
- We have to understand the four scopes: application, session, request and page
- Go小白实现一个简易的go mock server
猜你喜欢
![[opencv] - thresholding](/img/4e/88c8c8063de7cb10e44e76e77dbb8e.png)
[opencv] - thresholding

Mid year inventory | in 2022, PAAS will be upgraded again

全国职业院校技能大赛网络安全竞赛——Apache安全配置详解

Ionic4 Learning Notes 6 -- using native ionic4 components in custom components

关于接口的写法 1链式判读 ?. 2方法执行 (finally)一定会执行

Escape character in JS?

6126. Design food scoring system

CF. Bits And Pieces(子集状压dp + 剪枝)

Ionic4 learning notes 5-- custom public module
![[record of question brushing] 20. Valid brackets](/img/81/7edc2ff0003373fe0ab2868b1a872f.png)
[record of question brushing] 20. Valid brackets
随机推荐
移动端实现0.5px的实用方案
Introduction and use of Pinia
JS to achieve progress steps (small exercise)
Is the validity period of the root certificate as long as the server SSL certificate?
下拉列表组件使用 iScroll.js 实现滚动效果遇到的坑
The drop-down list component uses iscrol JS to achieve the rolling effect of the pit encountered
Typora 它依然是我心中的YYDS 最优美也是颜值最高的文档编辑神器 相信你永远不会抛弃它
Ionic4 Learning Notes 6 -- using native ionic4 components in custom components
Array object methods commonly used traversal methods & higher-order functions
The difference between KIB and MIB and KB and MB
Ionic4 learning notes 9 -- an east project 01
Ionic4 learning notes 7 -- UI component 1 (no practice, direct excerpt)
pycharm配置opencv库
CF lomsat gelral (heuristic merge)
Flatten array.Flat (infinity)
Segment tree merge board
Missing value processing
jmeter -- prometheus+grafana服务器性能可视化
mysql 配置文件
树链剖分板子