当前位置:网站首页>【pulsar学习】pulsar架构原理
【pulsar学习】pulsar架构原理
2022-06-26 08:49:00 【hhhSir'blog】
【pulsar学习系列】
前面几篇文章主要是介绍怎么将pulsar装起来、用起来。本文主要介绍pulsar的架构原理以及这些独特设计带来的优势。
1 pulsar集群组成
单个 Pulsar 集群由以下三部分组成:
- 一个或多个broker组成的集群:负责处理和负载均衡producer发出的消息并将消息发送给consumer。它与Pulsar configuration store相交互处理对应的任务,将消息存储在Bookeeper实例中(又被称为bookies)。Broker 依赖 ZooKeeper 集群处理特定的任务。
- 一个或多个bookie组成的Bookeeper集群:负责消息的持久化存储。
- zookeeper集群:协调多个pulsar集群的协调任务,里面保存了一些元数据,如配置管理,租户等。

其实根据上面的介绍可以很清晰发现pulsar的分层结构。Pulsar采用“存储和服务分离”的两层架构(这是Pulsar区别于其他MQ系统最重要的一点,也是所谓的“下一代消息系统”的核心)。
Pulsar客户端提供消费者和生产者的接口,但是客户端不与Apache Bookeeper交互,客户端也没有直接的 BookKeeper 访问权限。这种隔离为Pulsar实现安全的多租户统一身份验证模型提供了基础。下图能够体现其存储和服务分离的特点。本文的1.2和1.3节将详细介绍broker层和bookkeeper层的原理。
 存储于服务分离有啥好处嘞?
存储于服务分离有啥好处嘞?
- 对于计算:也就是我们的broker,提供消息队列的读写,不存储任何数据,无状态对于我们扩展非常友好,只要你机器足够,就能随便上。扩容Broker往往适用于增加Consumer的吞吐,当我们有一些大流量的业务或者活动,比如电商大促,可以提前进行broker的扩容。
- 对于存储:也就是我们的bookie,只提供消息队列的存储,如果对消息量有要求的,我们可以扩容bookie,并且我们不需要迁移数据,扩容十分方便。
2 Broker层:无状态服务层
Broker 实际上并不在本地存储任何消息数据。每个主题分区(Topic Partition)由 Pulsar 分配给某个 Broker,该 Broker 称为该主题分区的所有者。 Pulsar 生产者和消费者连接到主题分区的所有者 Broker,以向所有者代理发送消息并消费消息。
Pulsar 的 broker 是一个无状态组件,主要负责运行另外的两个组件:
- 一个 HTTP 服务器(Service discovery),它暴露了 REST 系统管理接口以及在生产者和消费者之间进行 Topic 查找的 API。
- 一个调度分发器(Dispatcher),它是异步的 TCP 服务器,通过自定义二进制协议应用于所有相关的数据传输。
下图显示了一个拥有 4 个 Broker 的 Pulsar 集群,其中 4 个主题分区分布在 4 个 Broker 中。每个 Broker 拥有并为一个主题分区提供消息服务。
如果一个 Broker 失败,Pulsar 会自动将其拥有的主题分区移动到群集中剩余的某一个可用 Broker 中。这里要说的一件事是:由于 Broker 是无状态的,当发生 Topic 的迁移时,Pulsar 只是将所有权从一个 Broker 转移到另一个 Broker,在这个过程中,不会有任何数据复制发生。
3 Bookkeeper层:持久化存储层
Apache BookKeeper 是企业级存储系统,旨在保证高持久性、一致性与低延迟。自 2011 年起,BookKeeper 开始在 Apache ZooKeeper 下作为子项目孵化,并于 2015 年 1 月作为顶级项目成功问世。
BookKeeper有以下特点:
- 使 Pulsar 能够利用独立的日志,称为 ledgers,可以随着时间的推移为 topic 创建多个 ledgers。
- 它为处理顺序消息提供了非常有效的存储。
- 保证了多系统挂掉时 ledgers 的读取一致性。
- 提供不同的 Bookies 之间均匀的 IO 分布的特性。
- 它在容量和吞吐量方面都具有水平伸缩性。能够通过增加 bookies 立即增加容量到集群中,并提升吞吐量。
- Bookies 被设计成可以承载数千的并发读写的 ledgers。 使用多个磁盘设备,一个用于日志,另一个用于一般存储,这样 Bookies 可以将读操作的影响和对于写操作的延迟分隔开。
Apache BookKeeper 是 Apache Pulsar 的持久化存储层。 Apache Pulsar 中的每个主题分区本质上都是存储在 Apache BookKeeper 中的分布式日志。
3.1 相关名词解释
bookis中存了啥数据?咋存的呢?这涉及到很多名词。
如图所示,一个topic实际上是一个Segment流(ledgers),通过这个设计所以Pulsar他并不是一个单纯的消息队列系统,他也可以代替流式系统,所以他也叫流原生平台,可以替代flink等系统。可以看见我们的topic/partition(Event Stream),由多个Segment存储组成,而每个Segment由entry组成,这个可以看作是我们每批发送的消息通常会看作是一个entry。这个Segment(在bookies中称为Ledger)可以看作是我们写入文件的一个基本维度,同一个Segment的数据会写在同一个文件上面,不同Segment将会是不同文件。
bookie又是咋读写这些文件的呢?首先介绍bookie的读写架构图:
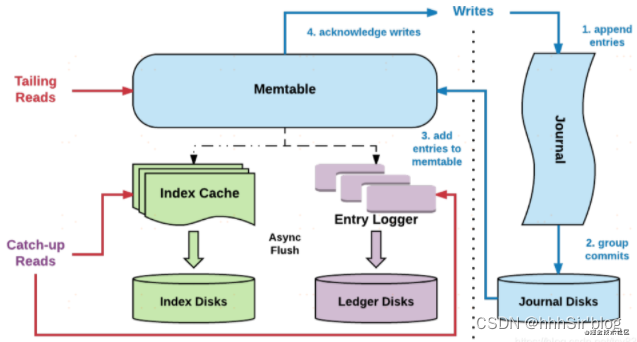
涉及到的名词解释如下:
- Entry,Entry是存储到bookkeeper中的一条记录,其中包含Entry ID,记录实体等。
- Ledger,可以认为ledger是用来存储Entry的,多个Entry序列组成一个ledger。
- Journal,其实就是bookkeeper的WAL(write ahead log),用于存bookkeeper的事务日志,journal文件有一个最大大小,达到这个大小后会新起一个journal文件。
- Entry log,存储Entry的文件,ledger是一个逻辑上的概念,entry会先按ledger聚合,然后写入entry log文件中。同样,entry log会有一个最大值,达到最大值后会新起一个新的entry log文件
- Index file,ledger的索引文件,ledger中的entry被写入到了entry log文件中,索引文件用于entry log文件中每一个ledger做索引,记录每个ledger在entry log中的存储位置以及数据在entry log文件中的长度。
- MetaData Storage,元数据存储,是用于存储bookie相关的元数据,比如bookie上有哪些ledger,bookkeeper目前使用的是zk存储,所以在部署bookkeeper前,要先有zk集群。
了解到上述信息,就可以看懂这个图了:
3.2 读写流程

其实跟一下这个流程,感觉与HBASE好相似呀:
写流程:
- Step1: broker发起写请求,首先对Journal磁盘写入WAL,熟悉mysql的朋友知道redolog,journal和redolog作用一样都是用于恢复没有持久化的数据。
- Step2: 然后再将数据写入index和ledger,这里为了保持性能不会直接写盘,而是写pagecache,然后异步刷盘。
- Step3: 对写入进行ack。
读流程:
- Step1: 先读取index,当然也是先读取cache,再走disk。
- Step2: 获取到index之后,根据index去entry logger中去对应的数据。
这不是铁铁的hbase预写日志和readcache吗?这样设计的好处有:支持高效的读写
在kafka中当我们的topic变多了之后,由于kafka一个topic一个文件,就会导致我们的磁盘IO从顺序写变成随机写。在rocketMq中虽然将多个topic对应一个写入文件,让写入变成了顺序写,但是我们的读取很容易导致我们的pagecache被各种覆盖刷新,这对于我们的IO的影响是非常大的。所以pulsar在读写两个方面针对这些问题都做了很多优化:
- 写流程:顺序写 +pagecache。在写流程中我们的所有的文件都是独立磁盘,并且同步刷盘的只有Journal,Journal是顺序写一个journal-wal文件,顺序写效率非常高。ledger和index虽然都会存在多个文件,但是我们只会写入pagecache,异步刷盘,所以随机写不会影响我们的性能。
- 读流程:broker cache + bookie cache,在pulsar中对于追尾读(tailing read)非常友好基本不会走io,一般情况下我们的consumer是会立即去拿producer发送的消息的,所以这部分在持久化之后依然在broker中作为cache存在,当然就算broker没有cache(比如broker是新建的),我们的bookie也会在memtable中有自己的cache,通过多重cache减少读流程走io。
我们可以发现在最理想的情况下读写的io是完全隔离开来的,所以在Pulsar中能很容易就支持百万级topic,而在我们的kafka和rocketmq中这个是非常困难的。
3.3 Segment为中心的存储的优势
相比kafka以partition为存储的基本对象,pulsar以Segment为中心进行存储的好处如下。这也能帮我们更好的理解pulsar的架构。
无限制的主题分区存储
由于主题分区被分割成 Segment 并在 Apache BookKeeper 中以分布式方式存储,因此主题分区的容量不受任何单一节点容量的限制。 相反,主题分区可以扩展到整个 BookKeeper 集群的总容量,只需添加 Bookie 节点即可扩展集群容量。 这是 Apache Pulsar 支持存储无限大小的流数据,并能够以高效,分布式方式处理数据的关键。 使用 Apache BookKeeper 的分布式日志存储,对于统一消息服务和存储至关重要。
即时扩展,无需数据迁移
由于消息服务和消息存储分为两层,因此将主题分区从一个 Broker 移动到另一个 Broker 几乎可以瞬时内完成,而无需任何数据重新平衡(将数据从一个节点重新复制到另一个节点)。 这一特性对于高可用的许多方面至关重要,例如集群扩展;对 Broker 和 Bookie 失败的快速应对。 我将使用例子在下文更详细地进行解释。
无缝 Broker 故障恢复
下图说明了 Pulsar 如何处理 Broker 失败的示例。 在例子中 Broker 2 因某种原因(例如停电)而断开。 Pulsar 检测到 Broker 2 已关闭,并立即将 Topic1-Part2 的所有权从 Broker 2 转移到 Broker 3。在 Pulsar 中数据存储和数据服务分离,所以当代理 3 接管 Topic1-Part2 的所有权时,它不需要复制 Partiton 的数据。 如果有新数据到来,它立即附加并存储为 Topic1-Part2 中的 Segment x + 1。 Segment x + 1 被分发并存储在 Bookie1, 2 和 4 上。因为它不需要重新复制数据,所以所有权转移立即发生而不会牺牲主题分区的可用性。

无缝集群容量扩展
下图说明了 Pulsar 如何处理集群的容量扩展。 当 Broker 2 将消息写入 Topic1-Part2 的 Segment X 时,将 Bookie X 和 Bookie Y 添加到集群中。 Broker 2 立即发现新加入的 Bookies X 和 Y。然后 Broker 将尝试将 Segment X + 1 和 X + 2 的消息存储到新添加的 Bookie 中。 新增加的 Bookie 立刻被使用起来,流量立即增加,而不会重新复制任何数据。 除了机架感知和区域感知策略之外,Apache BookKeeper 还提供资源感知的放置策略,以确保流量在群集中的所有存储节点之间保持平衡。

无缝的存储(Bookie)故障恢复
下图说明了 Pulsar(通过 Apache BookKeeper)如何处理 bookie 的磁盘故障。 这里有一个磁盘故障导致存储在 bookie 2 上的 Segment 4 被破坏。Apache BookKeeper 后台会检测到这个错误并进行复制修复。

Apache BookKeeper 中的副本修复是 Segment(甚至是 Entry)级别的多对多快速修复,这比重新复制整个主题分区要精细,只会复制必须的数据。 这意味着 Apache BookKeeper 可以从 bookie 3 和 bookie 4 读取 Segment 4 中的消息,并在 bookie 1 处修复 Segment 4。所有的副本修复都在后台进行,对 Broker 和应用透明。
即使有 Bookie 节点出错的情况发生时,通过添加新的可用的 Bookie 来替换失败的 Bookie,所有 Broker 都可以继续接受写入,而不会牺牲主题分区的可用性。
独立的可扩展性
由于消息服务层和持久存储层是分开的,因此 Apache Pulsar 可以独立地扩展存储层和服务层。这种独立的扩展,更具成本效益:
当您需要支持更多的消费者或生产者时,您可以简单地添加更多的 Broker。主题分区将立即在 Brokers 中做平衡迁移,一些主题分区的所有权立即转移到新的 Broker。
当您需要更多存储空间来将消息保存更长时间时,您只需添加更多 Bookie。通过智能资源感知和数据放置,流量将自动切换到新的 Bookie 中。 Apache Pulsar 中不会涉及到不必要的数据搬迁,不会将旧数据从现有存储节点重新复制到新存储节点。
上面的内容来源于一下blog,加上一点自己的总结。特此引用:
下一代消息队列pulsar到底是什么?
Apache Pulsar简介
比拼 Kafka, 大数据分析新秀 Pulsar 到底好在哪
聊聊pulsar:pulsar的核心概念与基础架构
pulsar架构与原理
4 总结
所有的变化,都可能伴随着痛苦和弯路,开放的道路,也不会是阔野坦途,但大江大河,奔涌向前的趋势,不是任何险滩暗礁,能够阻挡的。道之所在,虽千万人吾往矣。
边栏推荐
- How to set the shelves and windows, and what to pay attention to in the optimization process
- How to handle the small program tabbar that does not support parameter transfer
- 【开源】使用PhenoCV-WeedCam进行更智能、更精确的杂草管理
- Jetson TX2 installing the SciPy Library
- 挖财打新债安全吗
- 【微积分】拉格朗日乘子法
- 行为树XML文件 热加载
- dedecms小程序插件正式上线,一键安装无需任何php或sql基础
- ThreadLocal
- 实践是成为网工最快的方法,网络工程师实战项目整理
猜你喜欢

phpcms小程序插件4.0版正式上线

Vipshop work practice: Jason's deserialization application

Understanding of swing transformer

Edit type information

ThreadLocal
编辑类型信息

Phpcms V9 mobile phone access computer station one-to-one jump to the corresponding mobile phone station page plug-in

phpcms v9后台文章列表增加一键推送到百度功能

20220623 getting started with Adobe Illustrator

Detectron2 save (according to maxap50) model during training_ best. PTH weight
随机推荐
Phpcms V9 adds the reading amount field in the background, and the reading amount can be modified at will
Bug encountered in training detectron2: the test set cannot be evaluated during training
dedecms小程序插件正式上线,一键安装无需任何php或sql基础
Runtimeerror: object has no attribute NMS error record when using detectron2
实践是成为网工最快的方法,网络工程师实战项目整理
外部排序和大小堆相关知识
Particles and sound effect system in games104 music 12 game engine
简析ROS计算图级
Data warehouse (3) star model and dimension modeling of data warehouse modeling
Yolov5 advanced level 2 installation of labelimg
Principe et application du micro - ordinateur à puce unique - Aperçu
Error importerror: numpy core. multiarray failed to import
Pycharm [debug] process stuck
cookie session 和 token
Computer mall based on SSM
Self learning neural network sequence -- 2 perceptron
基于SSM的电脑商城
《一周搞定模电》—基本放大电路
Principle and application of single chip microcomputer -- Overview
Self taught neural network series - 1 Basic programming knowledge