当前位置:网站首页>NLP paper reading | improving semantic representation of intention recognition: isotropic regularization method in supervised pre training
NLP paper reading | improving semantic representation of intention recognition: isotropic regularization method in supervised pre training
2022-06-23 16:51:00 【Zhiyuan community】
Intention recognition (intent detection) It is the core module of task oriented dialogue system , There are few annotation data , So we study how to train an excellent intention classifier with a small amount of data (few-shot intent detection) It has high practical value .
In recent years BERT Such as pre training language model (pre-trained language model,PLM) In each NLP Dominate the task , And research shows that , Will be PLM Before applying to a task , Use the annotation data of the related task to align PLM Conduct supervised pre training (supervised pre-training, In fact, that is fine-tuning), It can effectively improve the effect of subsequent fine-tuning . For intention recognition , First, mark the data pairs with a few open dialogues PLM Fine tuning (IntentBERT)[1], It has greatly improved the model .
however ,IntentBERT It has strong anisotropy (anisotropy), Anisotropy is a geometric property , The meaning in vector space is that the distribution is related to the direction , Semantic vectors are squeezed into a narrow conical space , In this way, the cosine similarity of vectors is very high , Not a very good indication , And isotropic (isotropy) It is the same in all directions , Evenly distributed . Anisotropy is thought to cause PLM Only sub optimal performance can be achieved in each downstream task ( Indicates a degradation problem ) An important factor of , However, the isotropic technique can be used to adjust the embedded vector space , And the performance of the model on many tasks has been greatly improved . Previous isotropic techniques , Some have not been fine tuned PLM(off-the-shelf PLM) Adjustment , But for fine tuned PLM(fine-tuned PLM), These techniques may have negative effects on model performance [2]; Some are conducted during the supervision training isotropic batch normalization, But a lot of training data is needed [3], Not suitable for intent recognition tasks with missing data .
There is a paper recently 《Fine-tuning Pre-trained Language Models for Few-shot Intent Detection: Supervised Pre-training and Isotropization》, The isotropic technique is proposed to improve few-shot intent detection Of supervised pre-training, In this work , The author first studied isotropization and supervised pre-training (fine-tuning) The relationship between , Then two simple and effective isotropic regularization methods are proposed (isotropization regularizer), Pictured 1 Shown , And achieved good results , Let's take a look at the specific methods of this paper .


Paper title
Fine-tuning Pre-trained Language Models for Few-shot Intent Detection: Supervised Pre-training and Isotropization
Author of the paper
Haode Zhang, Haowen Liang, Yuwei Zhang, Liming Zhan, Xiao-Ming Wu, Xiaolei Lu, Albert Y.S. Lam
Author's unit
Department of Computing, The Hong Kong Polytechnic University, Hong Kong S.A.R.
University of California, San Diego
Nanyang Technological University, Singapore
Fano Labs, Hong Kong S.A.R.
Thesis link
https://arxiv.org/abs/2205.07208
Project code
https://github.com/fanolabs/isoIntentBert-main
Pilot Study
The author first did some preliminary experiments , To understand isotropy and fine tuning PLM The interaction between .
In this paper, the following formula is used to calculate isotropy :


among 




![\mathrm{I}(\mathbf{V}) \in [0, 1]](/img/ed/1815b8d0cc01149523a32ec978e314)


The paper compares PLM Isotropy before and after fine tuning , Results such as table 1 Shown , You can see PLM After fine adjustment , Its isotropy decreases , That is, fine-tuning may cause the feature space to become more anisotropic .

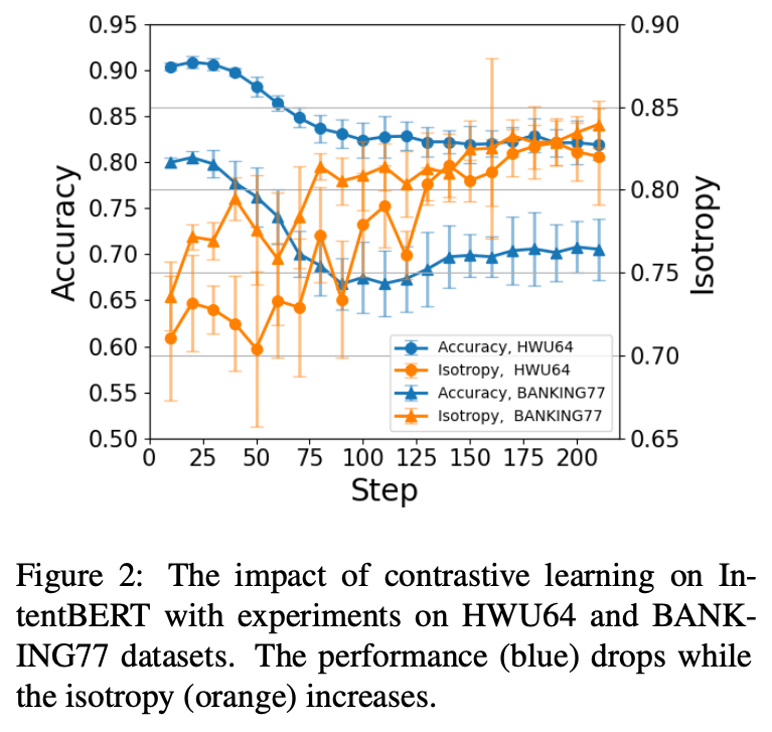

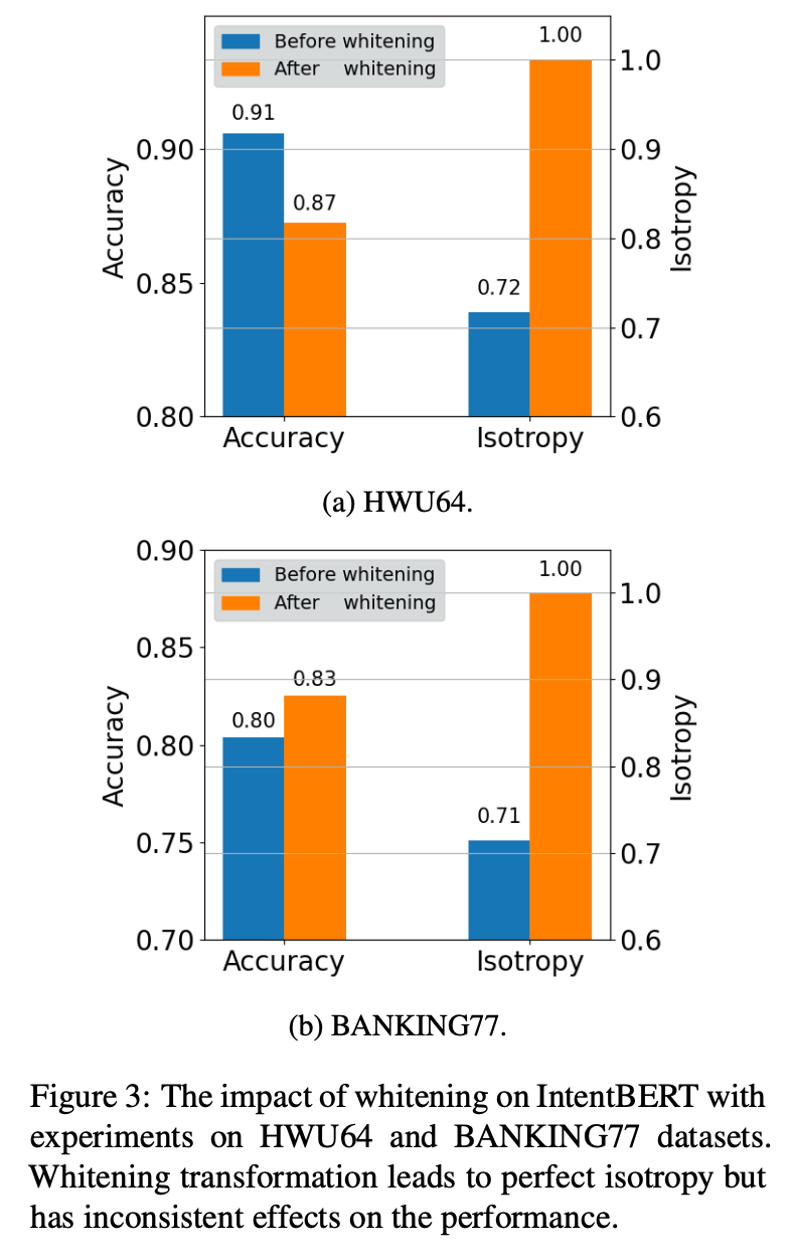
Then the paper compares the two previous isotropic techniques :
- dropout-based contrastive learning [4]
- whitening transformation [5]
Applied to the fine-tuned PLM Effect on , Pictured 2、3 Shown , You can see that except Figure 3(b), Other results are the isotropic improvement of the model , Performance degradation on tasks , This suggests that isotropic techniques may reduce fine-tuned PLM Performance of .
Method
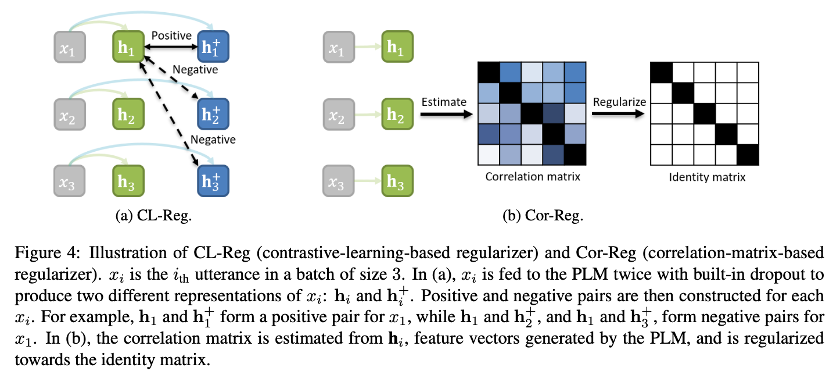
Whereas isotropic techniques may reduce fine-tuned PLM Performance of , So the author combines the isotropic technique with the training process , Two regularization methods are proposed , Pictured 4 Shown , Make the model more isotropic in the training process .

1. Supervised Pre-training for Few-shot Intent Detection
The current intention recognition model is basically PLM Add a classifier ( It is generally a linear layer ), Set the input sentence to PLM The semantic expression after is 

among 



The training process of model parameters can be described as :

among 

2. Regularizing Supervised Pre-training with Isotropization
The method proposed in this paper is to add a regular term to the objective function (regularizer), To increase isotropy :

among 
Contrastive-learning-based Regularizer
The first type of regular term is the one mentioned above dropout-based contrastive learning loss, But it was just applied to fine-tuned PLM On , This is for fine-tuning in :





Correlation-matrix-based Regularizer
The above regular term based on contrastive learning belongs to the implicit method , The paper also introduces an explicit method . The ideal isotropy is that the vectors are uniformly distributed in the feature space , That is, each dimension of the eigenvector has zero covariance and uniform variance , It can be expressed as a covariance matrix with uniform diagonal elements and zero non diagonal elements . We can directly add static features to the feature vector of the model to achieve isotropy , But the scale is not easy to grasp , So the author takes the difference between the model feature space and the ideal isotropy as the regular term of the objective function :

among 



Using the above two regular terms at the same time, we get :

The experimental results in this paper show that the effect of the two regular terms is better .
Experimental setup and results
1. Experimental setup
Data sets
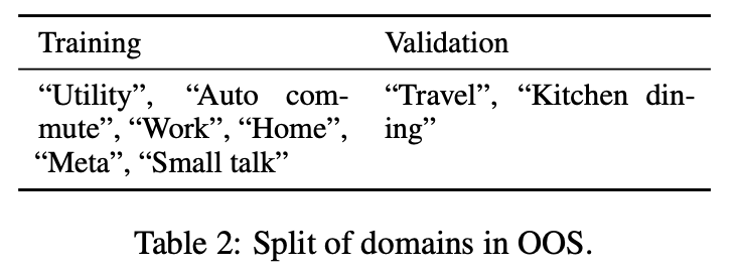
Used in the paper OOS Datasets as training and validation datasets , It contains 10 There are... Areas in total 150 Intention categories , The author removed the “Banking” and “Credit Cards” Data in two areas , Because the data and test sets of these two fields BANKING77 Semantically similar , The rest 8 In fields ,6 Used as a training set ,2 Used as validation set , As shown in the table 2 Shown .

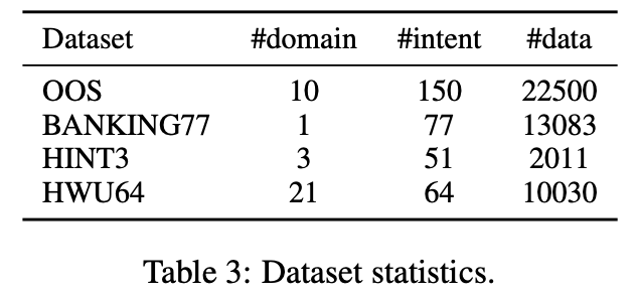
The paper uses the following data sets as test sets , The statistical information of the data set is shown in table 3 Shown :
- BANKING77: Intent recognition data set about banking services ;
- HINT3: Cover 3 Fields ,“Mattress Products Re- tail”、“Fitness Supplements Retail” and “Online Gaming”;
- HWU64: contain 21 Large scale data sets in three fields .

Parameter setting
The methods used in the paper are PLM by BERT and RoBERTa, take [CLS] The output of the position is used as a formula (3) In means , Use logistic regression to classify , Select the appropriate parameters through the validation set , Parameter settings are shown in the table 4 Shown .

Baseline model
be based on BERT There are BERT-Freeze( frozen off-the-shelf PLM)、IntentBERT( Identify data pairs with public intent BERT Conduct supervised pre training ),IntentBERT-ReImp It is reproduced by the author for the sake of fair comparison IntentBERT, There are also several dialogues or NLI The data continues with the pre trained model :
- CONVBERT
- TOD-BERT
- DNNC-BERT
- USE-ConveRT
- CPFT-BERT
be based on RoBERTa The models of are :
- RoBERTa-Freeze
- WikiHowRoBERTa
- DNNC-RoBERTa
- CPFT-RoBERTa
- IntentRoBERTa
Last , The author put whitening transformation Apply to PLM On , To make a comparison with the thesis method :
- BERT-White
- RoBERTa-White
- IntentBERT-White
- IntentRoBERTa-White
Training details
- Pytorch、Python
- Hugging Face Of bert-base-uncased and roberta-base
- Adam Optimizer , Learning rate 2e-05,weight decay by 1e-03
- Nvidia RTX 3090 GPUs
- On the verification set 100 Stop training without improving
- Random seed set {1, 2, 3, 4, 5}
evaluation
stay C-way K-shot Test on the task , That is, for each task , Take the C Intention categories , Each category K Data , Use this 

2. Main Results


The experimental results are shown in the table 5、 surface 6 Shown , It can be seen that the results of the proposed method are better than other methods ,Cor-Reg The result is better than CL-Reg, When two regular terms are used together, better results can be obtained .

The paper also compares the isotropic difference between the model trained by the paper method and the general model , It can be seen that the isotropy of the model is directly proportional to its performance on the task .
3. Ablation Experiment and analysis
Moderate isotropy is helpful
The author explores isotropy and few-shot intent detection Performance on the task , Its adjustment Cor-Reg The weight of gets higher isotropy , Then test the model performance , The result is shown in Fig. 5 Shown , It can be seen that the medium isotropic model has better performance .

Correlation matrix is better than covariance matrix as regularizer
The author in Cor-Reg The correlation matrix is used instead of the covariance matrix , Although the covariance matrix has more information about variance than the correlation matrix , But that's why , It is difficult to determine the scale of each variance . In the experiment , The correlation matrix is replaced by the covariance matrix , The non diagonal elements in the original identity matrix are set to 0, The diagonal element is set to 1、0.5 Or the average of the diagonal elements of the covariance matrix , Expressed as Cov-Reg-1、Cov-Reg-0.5、 and Cov- Reg-mean, The experimental results are shown in the table 8 Shown , You can see that several settings of the covariance matrix are worse than the correlation matrix .


The performance gain is not from the reduction in model variance
L1 and L2 Regularization can improve performance by reducing model variance , And the author will show 7 The performance improvement in the is attributed to the improvement in isotropy . In order to explore whether the performance improvement after using the regular term comes from variance or isotropy , The author gives L2 just Set different weights for items , Get multiple results , But not as good as CL-Reg and Cor-Reg, Pictured 6 Shown .

The computational overhead is small
The author counted the simultaneous use of CL-Reg and Cor-Reg When , One epoch The cost of each calculation process in the , The scale is shown in the figure 7 Shown , It can be seen that the calculation cost of regular items is not too large .

summary
This paper first analyzes PLM After fine tuning the intention recognition task 、 The anisotropy of its characteristic space , Then two kinds of regular terms based on contrastive learning and correlation matrix are proposed , To increase the isotropy of the feature space of the model in fine-tuning , And give the model in few-shot intent detection The performance of the task has been greatly improved . Because the method proposed in this paper is aimed at PLM Of , So it can also be used for other tasks based on PLM On the model of . Interested students can read the original paper by themselves , Feel free to leave a comment .
Welcome to your attention 「 Lan Zhou NLP Thesis reading 」 special column ! Pay attention to our official account (ID: Lanzhou Technology ) Join the exchange group ~ Official website :https://langboat.com.
The author of this article : Ganzifa Lanzhou technology algorithm intern Natural Language Processing Laboratory of Zhengzhou University (ZZUNLP) Second year master , At present, the research on text error correction is under way . E-mail: [email protected]
reference
[1] Zhang H, Zhang Y, Zhan L M, et al. Effectiveness of Pre-training for Few-shot Intent Classification[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. 2021: 1114-1120.
[2] Rajaee S, Pilehvar M T. An Isotropy Analysis in the Multilingual BERT Embedding Space[J]. arXiv preprint arXiv:2110.04504, 2021.
[3] Zhou W, Lin B Y, Ren X. IsoBN: fine-tuning BERT with isotropic batch normalization[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(16): 14621-14629.
[4] Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 6894-6910.
[5] Su J, Cao J, Liu W, et al. Whitening sentence representations for better semantics and faster retrieval[J]. arXiv preprint arXiv:2103.15316, 2021.
边栏推荐
- leetcode:30. 串联所有单词的子串【Counter匹配 + 剪枝】
- 官方零基础入门 Jetpack Compose 的中文课程来啦!
- How to select an oscilloscope? These 10 points must be considered!
- 供求两端的对接将不再是依靠互联网时代的平台和中心来实现的
- 谈谈redis缓存击穿透和缓存击穿的区别,以及它们所引起的雪崩效应
- How to select securities companies? Is it safe to open a mobile account?
- Counter attack by flour dregs: MySQL 66 question! Suggested collection
- 聚焦:ZK-SNARK 技术
- Jmeter压力测试教程
- 科大讯飞神经影像疾病预测方案!
猜你喜欢

【历史上的今天】6 月 23 日:图灵诞生日;互联网奠基人出生;Reddit 上线

IFLYTEK neuroimaging disease prediction program!
JS常见的报错及异常捕获
科大讯飞神经影像疾病预测方案!

Opengauss database source code analysis series articles -- detailed explanation of dense equivalent query technology (Part 1)
聚焦:ZK-SNARK 技术

元宇宙带来的社会结构和资本制度演变
Stick to five things to get you out of your confusion

ASEMI超快恢复二极管ES1J参数,ES1J封装,ES1J规格
2022 Jiufeng primary school (Optics Valley No. 21 primary school) student source survey
随机推荐
Code examples of golang goroutine, channel and time
stylegan2:analyzing and improving the image quality of stylegan
[today in history] June 23: Turing's birthday; The birth of the founder of the Internet; Reddit goes online
Reading and writing JSON files by golang
Opengauss database source code analysis series articles -- detailed explanation of dense equivalent query technology (Part 2)
坚持五件事,带你走出迷茫困境
Readimg: read picture to variable variable variable
How did Tencent's technology bulls complete the overall cloud launch?
TensorRT Paser加载onnx 推理使用
The connection between supply and demand will no longer depend on the platform and center of the Internet Era
短视频平台开发,点击输入框时自动弹出软键盘
安全舒适,全新一代奇骏用心诠释老父亲的爱
I successfully joined the company with 27K ByteDance. This interview notes on software testing has benefited me for life
JSON in MySQL_ Extract function description
Amadis发布OLA支付处理标准
npm install 问题解决(nvm安装与使用)
多年亿级流量下的高并发经验总结,都毫无保留地写在了这本书中
IFLYTEK neuroimaging disease prediction program!
R语言使用yardstick包的rmse函数评估回归模型的性能、评估回归模型在每个交叉验证(或者重采样)的每一折fold上的RMSE、以及整体的均值RMSE(其他指标mae、mape等计算方式类似)
Code implementation of golang binary search method