当前位置:网站首页>Deeply understand Flink SQL execution process based on flink1.12
Deeply understand Flink SQL execution process based on flink1.12
2022-06-25 11:39:00 【Direction_ Wind】
notice https://blog.csdn.net/super_wj0820/article/details/95623380 The article , I feel a surge of emotion , It's so good , I have to copy it , If there is any impact on the original author, please confide in me , I'll delete it right away .
Compared with the original article , This blog will explain the content and operation of the original article , Put more detailed screenshots and operation process , And later codegen Yes flinksql Extended implementation of syntax , If there is a task problem, I would like you to point out .
Here's the catalog title
- 1 Flink SQL Parsing engine
- 2. sketch Flink Table/SQL Execute the process
- 3. With Flink SQL Demo For cut in , In depth understanding of Flink Streaming SQL
- 3.1 Take the code of the official website for example
- 3.3 combination Flink SQL Execute the process And debugging Detailed instructions
- 3.3.1 preview AST、Optimized Logical Plan、Physical Execution Plan
- 3.3.2 SQL Analytic stage (SQL–>SqlNode)
- 3.3.3 SqlNode verification (SqlNode–>SqlNode)
- 3.3.4 Semantic analysis (SqlNode–>RelNode/RexNode)
- 3.3.5 Optimization stage (Logical RelNode–>FlinkLogicalRel)
- 3.3.6 Generate a physical plan (LogicalRelNode–>Physic Plan)
- 3.3.7 Generate DataStream(Physic Plan–>DataStream)
- 3.4 summary Flink Sql Execute the process
- 4. CodeGen
- 5. flink Grammar extension
1 Flink SQL Parsing engine
1.1SQL Parser
flink In execution sql When the sentence is , Can't be like java/scala Code to use directly , It needs to be parsed into a computer executable language , Yes sql Statement .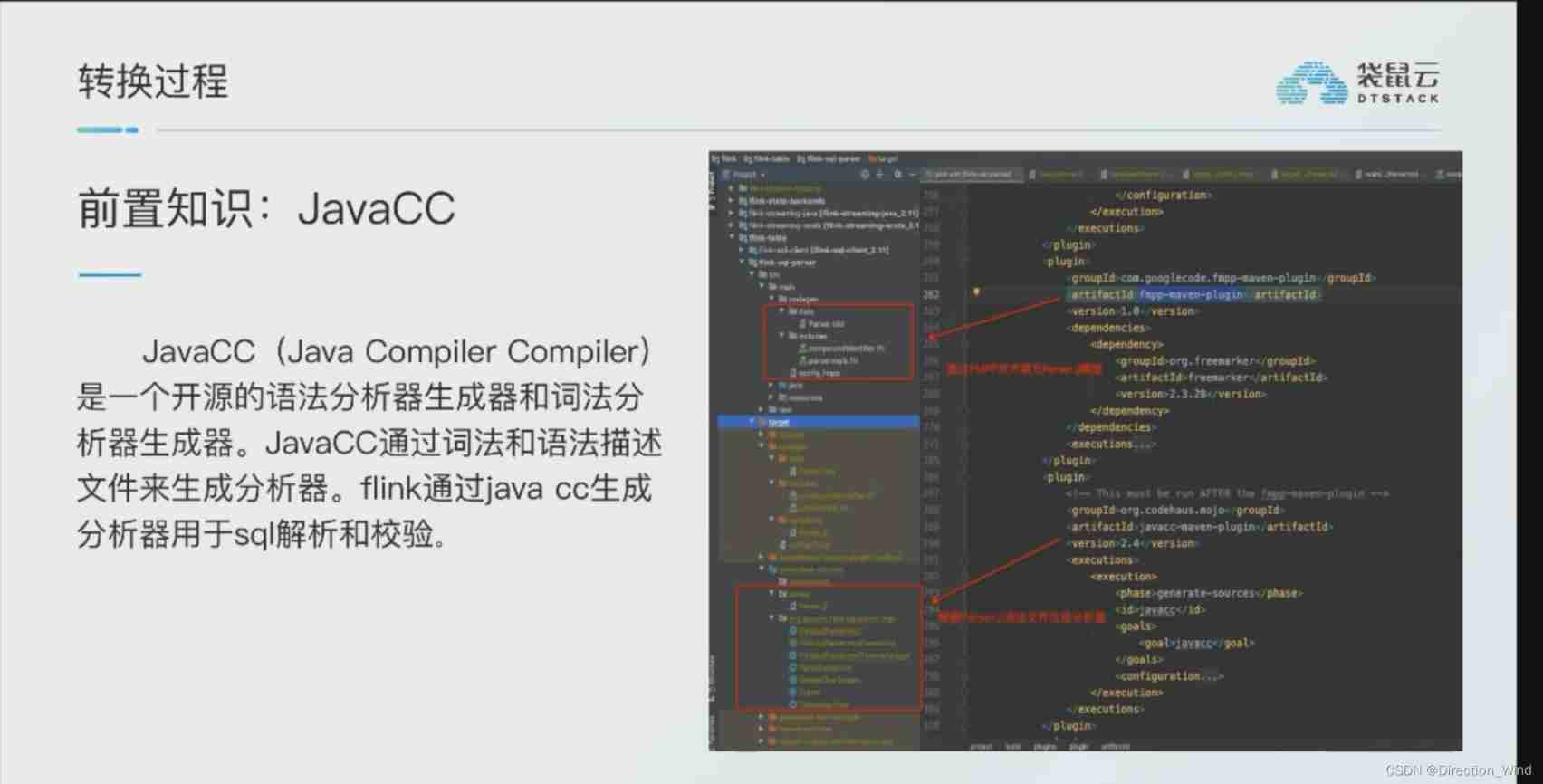 I don't think what I said here is particularly accurate , Should be flink It uses an open source SQL Parsing tool Apache Calcite ,Calcite Use Java CC Yes sql Statement is parsed .
I don't think what I said here is particularly accurate , Should be flink It uses an open source SQL Parsing tool Apache Calcite ,Calcite Use Java CC Yes sql Statement is parsed .
So let's briefly say Calcite Tools , Sort out Calcite Basic concepts of :
The specific concept in the above picture is explained as :
| type | describe | characteristic |
|---|---|---|
| RelOptRule | transforms an expression into another. Yes expression Do equivalent conversion | According to the RelOptRuleOperand To the target RelNode Tree for rule matching , After matching successfully , Will call... Again matches() Method ( It returns true by default ) Carry out further inspection . If mathes() The result is true , Call onMatch() convert . |
| ConverterRule | Abstract base class for a rule which converts from one calling convention to another without changing semantics. | It is RelOptRule Subclasses of , It is specially used for data source conversion (Calling convention),ConverterRule Generally, the corresponding Converter To complete the work , for instance :JdbcToSparkConverterRule call JdbcToSparkConverter To finish. JDBC Table To Spark RDD Transformation . |
| RelNode | relational expression,RelNode It will be identified input RelNode Information , This makes up a tree RelNode Trees | Represents a processing operation on data , Common operations are Sort、Join、Project、Filter、Scan etc. . It's about the whole thing Relation The operation of , It's not the logic of processing specific data . |
| Converter | A relational expression implements the interface Converter to indicate that it converts a physical attribute, or RelTrait of a relational expression from one value to another. | Used to put a kind of RelTrait Convert to another RelTrait Of RelNode. Such as JdbcToSparkConverter You can put JDBC Inside table Convert to Spark RDD. If you need to be in a RelNode Dealing with logical tables from heterogeneous systems ,Calcite Ask to use first Converter Convert the logic tables of heterogeneous systems into the same Convention. |
| RexNode | Row-level expression | Row expression ( Scalar expression ), What is implied is the processing logic of a row of data . Each row expression has a data type . This is because in the Valdiation In the process of , The compiler deduces the result type of the expression . Common line expressions include literals RexLiteral, Variable RexVariable, Function or operator call RexCall etc. . RexNode adopt RexBuilder Build . |
| RelTrait | RelTrait represents the manifestation of a relational expression trait within a trait definition. | Used to define the physical properties of logical tables (physical property), Three major trait The type is :Convention、RelCollation、RelDistribution; |
| Convention | Calling convention used to repressent a single data source, inputs must be in the same convention | Inherited from RelTrait, There are few types , Represents a single data source , One relational expression Must be in the same convention in ; |
| RelTraitDef | There are three main types :ConventionTraitDef: Used to represent the data source RelCollationTraitDef: Used to define the fields involved in sorting ;RelDistributionTraitDef: Used to define the distribution of data on physical storage ( such as :single、hash、range、random etc. ); | |
| RelOptCluster | An environment for related relational expressions during the optimization of a query. | palnner Runtime environment , Save context information ; |
| RelOptPlanner | A RelOptPlanner is a query optimizer: it transforms a relational expression into a semantically equivalent relational expression, according to a given set of rules and a cost model. | This is the optimizer ,Calcite Support RBO(Rule-Based Optimizer) and CBO(Cost-Based Optimizer).Calcite Of RBO (HepPlanner) It's called a heuristic optimizer (heuristic implementation ), It simply presses AST The tree structure matches all known rules , Until no rules can match ;Calcite Of CBO It's called a volcanic optimizer (VolcanoPlanner) The cost optimizer also matches and applies the rules , When the cost reduction of the whole tree becomes stable , Optimization completed , The cost optimizer relies on more accurate cost estimates .RelOptCost and Statistic Related to cost estimation ; |
| RelOptCost | defines an interface for optimizer cost in terms of number of rows processed, CPU cost, and I/O cost. | The optimizer cost model relies on ; |
1.2Calcite Processing flow
Sql The general process of the following figure can be divided into four stages ,Calcite The same is true
analysis check Optimize perform :
about flink The process parsed in is :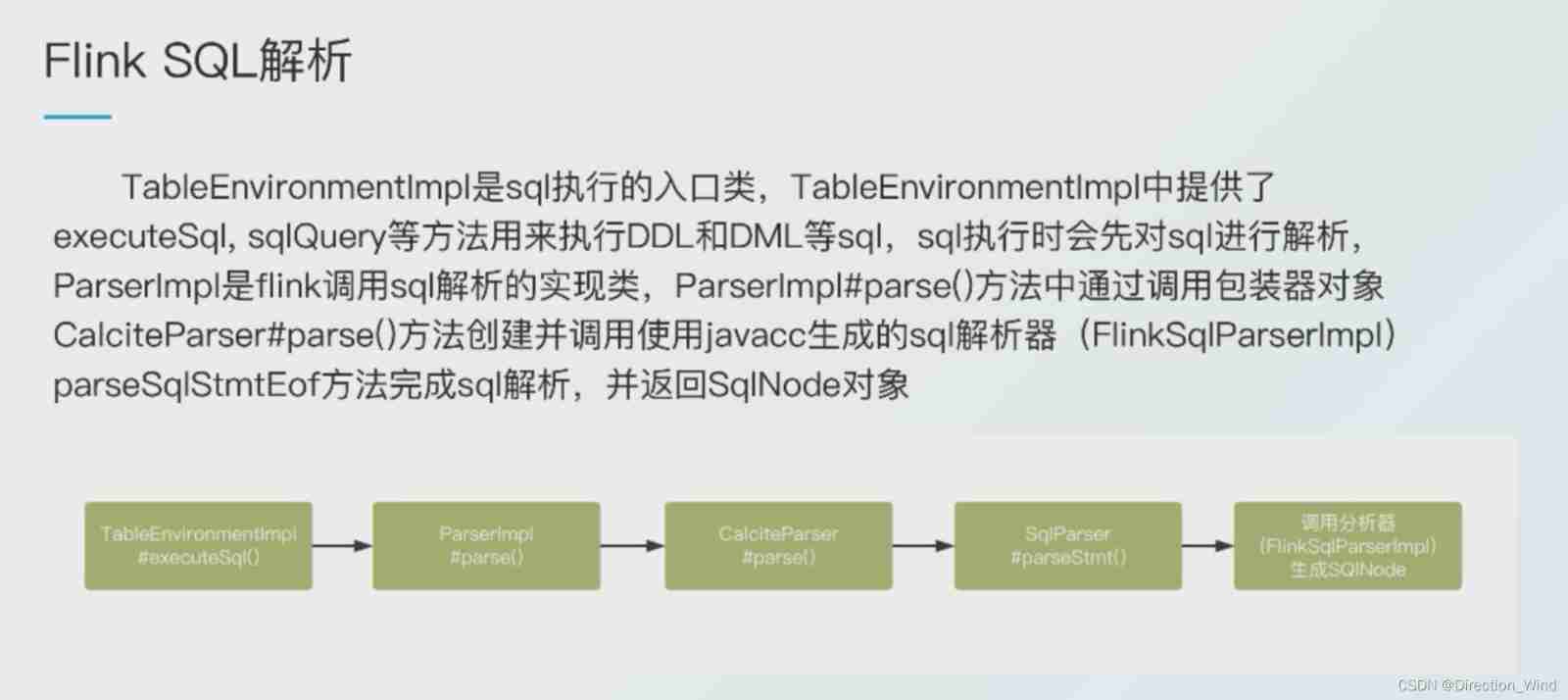
Here for the convenience of narration , hold SQL The implementation of is divided into the following five stages ( Compared with the above, there is another stage of Independence ):
1.2.1 SQL Analytic stage (SQL–>SqlNode)
Calcite Use JavaCC do SQL analysis ,JavaCC according to Calcite As defined in Parser.jj file , Generate a series of java Code , Generated Java The code will put SQL convert to AST Data structure of ( Here is SqlNode type ).
Javacc Achieve one SQL Parser, It has the following two functions , It is necessary to jj Defined in the file .
- List item Design morphology and semantics , Definition SQL Specific elements in ;
- Implement lexical analyzer (Lexer) And parsers (Parser), Finish right SQL Parsing , Complete the corresponding conversion .
namely : hold SQL Convert into AST ( Abstract syntax tree ), stay Calcite of use SqlNode To express ;
1.2.2 SqlNode verification (SqlNode–>SqlNode)

Go through the first step above , Will generate a SqlNode object , It's an unproven abstract syntax tree , Now we enter a grammar checking stage , You need to know metadata information before syntax checking , This check will include the table name 、 Field name 、 Function name 、 Check of data type .
namely : Syntax check , Syntax verification based on metadata information , After verification, it is still used SqlNode Express AST Grammar tree ;
1.2.3 Semantic analysis (SqlNode–>RelNode/RexNode)
After the second step , there SqlNode It's a grammar check SqlNode Trees , The next step is to SqlNode convert to RelNode/RexNode, That is to generate the corresponding logical plan (Logical Plan)
namely : Semantic analysis , according to SqlNode And meta information construction RelNode Trees , That's the original version of the logical plan (Logical Plan);
1.2.4 Optimization stage (RelNode–>RelNode)
The fourth stage , That is to say Calcite At the heart of , Where the optimizer optimizes , Such as the downward pressure of filtration conditions (push down), It's going on join Before operation , to filter operation , In this way, you don't need to be in the join The total amount was calculated join, Reduce participation join And so on .
stay Calcite in , Two types are available planner:HepPlanner and VolcanoPlanner, For details, please refer to the following .
namely : Logical planning optimization , The core of the optimizer , According to the logic generated above, plan according to the corresponding rules (Rule) To optimize ;
1.2.5 Generate ExecutionPlan
This step is to turn the final implementation plan into Graph chart , The following process is similar to the real java The code flow is consistent
1.3 Calcite Optimizer
The role of the optimizer : Convert the relational algebraic expression generated by the parser into an execution plan , For execution engine execution , In the process , Will apply some rules to optimize , To help generate more efficient execution plans .
Calcite in RelOptPlanner yes Calcite The base class of the optimizer in :
Calcite Two implementations of the optimizer are provided in :
HepPlanner: It's rule-based optimization RBO The implementation of the , It's a heuristic optimizer , Match according to rules , Until the limit of times is reached (match Time limit ) Or it doesn't show up again rule match That's the case ;
VolcanoPlanner: It is based on cost optimization CBO The implementation of the , It iterates all the time rules, Until I find cost The smallest paln.
Ali's blink It's just sql A lot of work has been done in the optimization part , Including micro batch ,TopN, hotspot , The de duplication and other parts have been greatly optimized in the underlying algorithm , Through the measured ,7 In the case of a sky window , Half an hour scrolling window for aggregation operation , Even better than using it directly process API Better performance , Use less resources
2. sketch Flink Table/SQL Execute the process
Flink Table API&SQL Keep a unified interface for relational queries between streaming data and static data , And used Calcite Query optimization framework and SQL parser.
The design is based on Flink Constructed API Built ,Flink Of core API And all the engine improvements will be automatically applied to Table API and SQL On .
The following is the execution process of the two views , The processing operation is introduced from two aspects :

2.1 Flink Sql Execute the process
One stream sql From submit to calcite analysis 、 Optimization last to flink The engine performs , It is generally divided into the following stages :
- Sql Parser: take sql Statement passing java cc It can be interpreted as AST( Grammar tree ), stay calcite of use SqlNode Express AST;
- Sql Validator: Combined with digital dictionary (catalog) To verify sql grammar ;
- Generate Logical Plan: take sqlNode It means AST convert to LogicalPlan, use relNode Express ;
- Generate optimized LogicalPlan: Based on calcite rules To optimize logical Plan, Then based on the flink Some optimizations for customization rules To optimize logical Plan;
- Generate Flink PhysicalPlan: This is also based on flink Inside rules, take optimized LogicalPlan Convert into Flink Physical execution plan for ;
- Turn the physical execution plan into Flink ExecutionPlan: Call the corresponding tanslateToPlan Method conversion and utilization CodeGen Meta programming Flink All kinds of operators of .
2.3 Flink Table/SQL Execute the process Of similarities and differences
You can see it ,Table API And SQL In obtaining RelNode And then it's the same process , Just get RelNode In a different way :
- Table API : By using RelBuilder Come and get it RelNode(LogicalNode And Expression Convert to RelNode And RexNode), The specific implementation will not be expanded here ;
- SQL : By using Planner. First, through parse Method is used by the user SQL Text conversion from SqlNode It means parse tree. Then passed validate Method , Use meta information to resolve Field , Determine the type , Validation, etc . Finally through rel Methods will SqlNode convert to RelNode;
stay flink There are two kinds of API Perform relational queries ,Table API and SQL. These two kinds of API All queries will contain registered Table Of catalog To verify , Except at the beginning of the transition from computational logic to logical plan A little different , After that, it was almost the same . At the same time stream and batch Your query looks exactly the same . It's just flink Depending on the nature of the data source ( Streaming and static ) Use different rules to optimize , After the final optimization plan To turn into a routine Flink DataSet or DataStream Program .
3. With Flink SQL Demo For cut in , In depth understanding of Flink Streaming SQL
3.1 Take the code of the official website for example
Code :
package apps.alg;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
/** * Simple example for demonstrating the use of SQL on a Stream Table in Java. * * <p>This example shows how to: * - Convert DataStreams to Tables * - Register a Table under a name * - Run a StreamSQL query on the registered Table * */
public class test {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
// set up execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStream<Order> orderA = env.fromCollection(Arrays.asList(
new Order(1L, "beer", 3),
new Order(1L, "diaper", 4),
new Order(3L, "rubber", 2)));
DataStream<Order> orderB = env.fromCollection(Arrays.asList(
new Order(2L, "pen", 3),
new Order(2L, "rubber", 3),
new Order(4L, "beer", 1)));
// register DataStream as Table
tEnv.registerDataStream("OrderA", orderA, "user, product, amount");
tEnv.registerDataStream("OrderB", orderB, "user, product, amount");
// union the two tables
Table result = tEnv.sqlQuery("SELECT " +
"* " +
"FROM " +
"( " +
"SELECT " +
"* " +
"FROM " +
"OrderA " +
"WHERE " +
"user < 3 " +
"UNION ALL " +
"SELECT " +
"* " +
"FROM " +
"OrderB " +
"WHERE " +
"product <> 'rubber' " +
") OrderAll " +
"WHERE " +
"amount > 2");
System.out.println(tEnv.explain(result));
tEnv.toAppendStream(result, Order.class).print();
env.execute();
}
// *************************************************************************
// USER DATA TYPES
// *************************************************************************
/** * Simple POJO. */
public static class Order {
public Long user;
public String product;
public int amount;
public Order() {
}
public Order(Long user, String product, int amount) {
this.user = user;
this.product = product;
this.amount = amount;
}
@Override
public String toString() {
return "Order{" +
"user=" + user +
", product='" + product + '\'' +
", amount=" + amount +
'}';
}
}
}
introduce pom:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency
If you want to in IDEA Execute debugging in You can refer to
https://blog.csdn.net/Direction_Wind/article/details/122843896
This post operates
surface OrderA Define three fields :user, product, amount, Do it separately first select Inquire about , And then the query results union, Do it last select, The outermost layer is added with a Filter, To trigger Filter Push down and merge . The result of running the code is :
3.3 combination Flink SQL Execute the process And debugging Detailed instructions
3.3.1 preview AST、Optimized Logical Plan、Physical Execution Plan
The program method can print To be carried out Sql The abstract syntax tree of (Abstract Syntax Tree)、 Optimized logical plan and physical plan :
== Abstract Syntax Tree ==
== Optimized Logical Plan ==
== Physical Execution Plan ==
== Abstract Syntax Tree ==
LogicalProject(user=[$0], product=[$1], amount=[$2])
+- LogicalFilter(condition=[>($2, 2)])
+- LogicalUnion(all=[true])
:- LogicalProject(user=[$0], product=[$1], amount=[$2])
: +- LogicalFilter(condition=[<($0, 3)])
: +- LogicalTableScan(table=[[default_catalog, default_database, OrderA]])
+- LogicalProject(user=[$0], product=[$1], amount=[$2])
+- LogicalFilter(condition=[<>($1, _UTF-16LE'rubber')])
+- LogicalTableScan(table=[[default_catalog, default_database, OrderB]])
== Optimized Logical Plan ==
Union(all=[true], union=[user, product, amount])
:- Calc(select=[user, product, amount], where=[AND(<(user, 3), >(amount, 2))])
: +- DataStreamScan(table=[[default_catalog, default_database, OrderA]], fields=[user, product, amount])
+- Calc(select=[user, product, amount], where=[AND(<>(product, _UTF-16LE'rubber':VARCHAR(2147483647) CHARACTER SET "UTF-16LE"), >(amount, 2))])
+- DataStreamScan(table=[[default_catalog, default_database, OrderB]], fields=[user, product, amount])
== Physical Execution Plan ==
Stage 1 : Data Source
content : Source: Collection Source
Stage 2 : Data Source
content : Source: Collection Source
Stage 3 : Operator
content : SourceConversion(table=[default_catalog.default_database.OrderA], fields=[user, product, amount])
ship_strategy : FORWARD
Stage 4 : Operator
content : Calc(select=[user, product, amount], where=[((user < 3) AND (amount > 2))])
ship_strategy : FORWARD
Stage 5 : Operator
content : SourceConversion(table=[default_catalog.default_database.OrderB], fields=[user, product, amount])
ship_strategy : FORWARD
Stage 6 : Operator
content : Calc(select=[user, product, amount], where=[((product <> _UTF-16LE'rubber':VARCHAR(2147483647) CHARACTER SET "UTF-16LE") AND (amount > 2))])
ship_strategy : FORWARD
3.3.2 SQL Analytic stage (SQL–>SqlNode)
And what I mentioned earlier Calcite The processing flow is consistent , here Flink analysis Flink SQL Grammar and lexical analysis Completely dependent on Calcite Provided SqlParser.
stay tEnv.sqlQuery() In the method , Below Step-1 That is to say SQL Analytic process , The parameter for To be resolved SQL, Return the parsed SqlNode object .
*TableEnvironment.scala*
def sqlQuery(query: String): Table = {
val planner = new FlinkPlannerImpl(getFrameworkConfig, getPlanner, getTypeFactory)
// Step-1: SQL Analytic stage (SQL–>SqlNode), hold SQL Convert into AST ( Abstract syntax tree ), stay Calcite of use SqlNode To express
val parsed = planner.parse(query)
if (null != parsed && parsed.getKind.belongsTo(SqlKind.QUERY)) {
// Step-2: SqlNode verification (SqlNode–>SqlNode), Syntax check , Syntax verification based on metadata information , After verification, it is still used SqlNode Express AST Grammar tree ;
val validated = planner.validate(parsed)
// Step-3: Semantic analysis (SqlNode–>RelNode/RexNode), according to SqlNode And meta information construction RelNode Trees , That's the original version of the logical plan (Logical Plan)
val relational = planner.rel(validated)
new Table(this, LogicalRelNode(relational.rel))
} else {
...
}
}
After being parsed SqlNode AST, Every SQL The composition is translated into a node :
You can see it If parallelism is enabled ,unionall The statements that are repeated twice are at the same order level , Two identical operations for the parser .
3.3.3 SqlNode verification (SqlNode–>SqlNode)
SQL In being SqlParser After the parsing , obtain SqlNode Composed of Abstract syntax tree (AST), And then according to the registered Catalog For the SqlNode AST To verify .
The following statement registers OrderA and OrderB:
tEnv.registerDataStream(“OrderA”, orderA, “user, product, amount”);
tEnv.registerDataStream(“OrderB”, orderB, “user, product, amount”);
Step-2 That is to say SQL Analytic process , The parameter for To be verified SqlNode AST, Return the verified SqlNode object .
be relative to Calcite Native SQL check ,Flink Expanded the scope of syntax verification , Such as Flink Support for custom FunctionCatalog, Used to verify SQL Function The number and type of input parameters of , Specific usage and details will be supplemented later .
The following is SQL The process of verification :
**FlinkPlannerImpl.scala**
private def validate(sqlNode: SqlNode, validator: FlinkCalciteSqlValidator): SqlNode = {
try {
sqlNode.accept(new PreValidateReWriter(
validator, typeFactory))
// do extended validation.
sqlNode match {
case node: ExtendedSqlNode =>
node.validate()
case _ =>
}
// no need to validate row type for DDL and insert nodes.
if (sqlNode.getKind.belongsTo(SqlKind.DDL)
|| sqlNode.getKind == SqlKind.INSERT
|| sqlNode.getKind == SqlKind.CREATE_FUNCTION
|| sqlNode.getKind == SqlKind.DROP_FUNCTION
|| sqlNode.getKind == SqlKind.OTHER_DDL
|| sqlNode.isInstanceOf[SqlLoadModule]
|| sqlNode.isInstanceOf[SqlShowCatalogs]
|| sqlNode.isInstanceOf[SqlShowCurrentCatalog]
|| sqlNode.isInstanceOf[SqlShowDatabases]
|| sqlNode.isInstanceOf[SqlShowCurrentDatabase]
|| sqlNode.isInstanceOf[SqlShowTables]
|| sqlNode.isInstanceOf[SqlShowFunctions]
|| sqlNode.isInstanceOf[SqlShowViews]
|| sqlNode.isInstanceOf[SqlShowPartitions]
|| sqlNode.isInstanceOf[SqlRichDescribeTable]
|| sqlNode.isInstanceOf[SqlUnloadModule]) {
return sqlNode
}
sqlNode match {
case explain: SqlExplain =>
val validated = validator.validate(explain.getExplicandum)
explain.setOperand(0, validated)
explain
case _ =>
validator.validate(sqlNode)
}
}
catch {
case e: RuntimeException =>
throw new ValidationException(s"SQL validation failed. ${e.getMessage}", e)
}
}
thus ,Flink The engine has User business Turn it into The following abstract syntax tree (AST), this AST No optimization strategy has been applied , It's just Sql Native mapping of nodes :
== Abstract Syntax Tree ==
3.3.4 Semantic analysis (SqlNode–>RelNode/RexNode)
Passing by SQL Analytic and SQL After verification SqlNode, Just will SQL Resolved to java On the fixed node of the data structure , There is no information about the relationship between related nodes and the type of each node , Therefore, it is also necessary to SqlNode Convert to logical plan (RelNode).
stay tEnv.sqlQuery() In the method , Step-3 That is to say SQL Analytic process , The parameter for Verified SqlNode, The return contains RelNode The information of RelRoot object .
The following is the process of building a logical plan :
private def rel(validatedSqlNode: SqlNode, sqlValidator: FlinkCalciteSqlValidator) = {
try {
assert(validatedSqlNode != null)
val sqlToRelConverter: SqlToRelConverter = createSqlToRelConverter(sqlValidator)
sqlToRelConverter.convertQuery(validatedSqlNode, false, true)
// we disable automatic flattening in order to let composite types pass without modification
// we might enable it again once Calcite has better support for structured types
// root = root.withRel(sqlToRelConverter.flattenTypes(root.rel, true))
// TableEnvironment.optimize will execute the following
// root = root.withRel(RelDecorrelator.decorrelateQuery(root.rel))
// convert time indicators
// root = root.withRel(RelTimeIndicatorConverter.convert(root.rel, rexBuilder))
} catch {
case e: RelConversionException => throw new TableException(e.getMessage)
}
}
private def createSqlToRelConverter(sqlValidator: SqlValidator): SqlToRelConverter = {
new SqlToRelConverter(
createToRelContext(),
sqlValidator,
sqlValidator.getCatalogReader.unwrap(classOf[CalciteCatalogReader]),
cluster,
convertletTable,
sqlToRelConverterConfig)
}
thus , User pass StreamTableEnvironment object Registered Calatlog Information and Business Sql all Transformed into Logical plan (Logical Plan), meanwhile ,TableApi and SqlApi Also in the Logical Plan It is agreed here , The subsequent optimization stage 、 Generate physical plan and generate DataStream, It's all the same process .
3.3.5 Optimization stage (Logical RelNode–>FlinkLogicalRel)
tEnv.sqlQuery() return Table object , stay Flink in ,Table Objects can be passed through TableApi Generate , It can also be done through SqlApi Generate ,TableApi and SqlApi So far we have reached an agreement .
In the business code ,toAppendStream The method will carry out Logical Plan The optimization of the 、 Generate physical plan and generate DataStream The process of :
tEnv.toAppendStream(result, Order.class).print();
Tracking code , Will enter StreamTableEnvironment.scala Of translate Method , Here I make a demonstration :
1 Hold down ctrl Left click to jump into toAppendStream Method
2 ctrl+H see StreamTableEnvironment Interface toAppendStream Implementation class of 
3 Get into StreamTableEnvironmentImpl Class view toAppendStream Method 
You can see return toDataStream(table, modifyOperation); Click to enter toDataStream
4 Click to enter translate operator , The operation is the same as that in section 2 Step View the specific implementation of the interface 
You can get real translate Implementation method
override def translate(
tableOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
val planner = createDummyPlanner()
tableOperations.asScala.map {
operation =>
val (ast, updatesAsRetraction) = translateToRel(operation)
// Step-4: Optimization stage + Step-5: Generate a physical plan
val optimizedPlan = optimizer.optimize(ast, updatesAsRetraction, getRelBuilder)
// Step-6: Turn into DataStream
val dataStream = translateToCRow(planner, optimizedPlan)
dataStream.getTransformation.asInstanceOf[Transformation[_]]
}.filter(Objects.nonNull).asJava
}
//translate operation Concrete DataStreamRelNode Convert to The flow of The actual operation is executed
private def translateToCRow(planner: StreamPlanner, logicalPlan: RelNode): DataStream[CRow] = {
// Recursively call the... Of each node in turn translateToPlan Method , take DataStreamRelNode Turn into DataStream, The resulting DataStreamGraph
logicalPlan match {
case node: DataStreamRel =>
getExecutionEnvironment.configure(
config.getConfiguration,
Thread.currentThread().getContextClassLoader)
node.translateToPlan(planner)
case _ =>
throw new TableException("Cannot generate DataStream due to an invalid logical plan. " +
"This is a bug and should not happen. Please file an issue.")
}
}
3.3.5.1 FlinkRuleSets
Calcite The framework allows us to use rules to optimize logical planning ,Flink stay Optimize In the process , Use FlinkRuleSets Define optimization rules to optimize :

here , Briefly describe each RuleSet The role of :
- DATASTREAM_NORM_RULES:Transform window to LogicalWindowAggregate
- DATASET_OPT_RULES:translate to Flink DataSet nodes
- TABLE_SUBQUERY_RULES:Convert sub-queries before query decorrelation
The specific implementation of rules is also in the same Class package 
Such as :DataStreamGroupWindowAggregateRule by GROUPING SETS Relevant rules
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */
package org.apache.flink.table.plan.rules.datastream
import org.apache.calcite.plan.{
RelOptRule, RelOptRuleCall, RelTraitSet}
import org.apache.calcite.rel.RelNode
import org.apache.calcite.rel.convert.ConverterRule
import org.apache.flink.table.api.TableException
import org.apache.flink.table.plan.nodes.FlinkConventions
import org.apache.flink.table.plan.nodes.datastream.DataStreamGroupWindowAggregate
import org.apache.flink.table.plan.nodes.logical.FlinkLogicalWindowAggregate
import org.apache.flink.table.plan.schema.RowSchema
import scala.collection.JavaConversions._
class DataStreamGroupWindowAggregateRule
extends ConverterRule(
classOf[FlinkLogicalWindowAggregate],
FlinkConventions.LOGICAL,
FlinkConventions.DATASTREAM,
"DataStreamGroupWindowAggregateRule") {
override def matches(call: RelOptRuleCall): Boolean = {
val agg: FlinkLogicalWindowAggregate = call.rel(0).asInstanceOf[FlinkLogicalWindowAggregate]
// check if we have grouping sets
val groupSets = agg.getGroupSets.size() != 1 || agg.getGroupSets.get(0) != agg.getGroupSet
if (groupSets || agg.indicator) {
throw new TableException("GROUPING SETS are currently not supported.")
}
!groupSets && !agg.indicator
}
override def convert(rel: RelNode): RelNode = {
val agg: FlinkLogicalWindowAggregate = rel.asInstanceOf[FlinkLogicalWindowAggregate]
val traitSet: RelTraitSet = rel.getTraitSet.replace(FlinkConventions.DATASTREAM)
val convInput: RelNode = RelOptRule.convert(agg.getInput, FlinkConventions.DATASTREAM)
new DataStreamGroupWindowAggregate(
agg.getWindow,
agg.getNamedProperties,
rel.getCluster,
traitSet,
convInput,
agg.getNamedAggCalls,
new RowSchema(rel.getRowType),
new RowSchema(agg.getInput.getRowType),
agg.getGroupSet.toArray)
}
}
object DataStreamGroupWindowAggregateRule {
val INSTANCE: RelOptRule = new DataStreamGroupWindowAggregateRule
}
about flink1.12 The real integration of flow and batch has not been realized yet , For batch / Stream application , Use different Rule To optimize , The following is the optimization process of flow processing rules :
**StreamOptimizer.scala**
/** * Generates the optimized [[RelNode]] tree from the original relational node tree. * * @param relNode The root node of the relational expression tree. * @param updatesAsRetraction True if the sink requests updates as retraction messages. * @return The optimized [[RelNode]] tree */
def optimize(
relNode: RelNode,
updatesAsRetraction: Boolean,
relBuilder: RelBuilder): RelNode = {
// Optimize subqueries , according to TABLE_SUBQUERY_RULES application HepPlanner Rule optimization
val convSubQueryPlan = optimizeConvertSubQueries(relNode)
// Expansion plan optimization , according to EXPAND_PLAN_RULES and POST_EXPAND_CLEAN_UP_RULES application HepPlanner Rule optimization
val expandedPlan = optimizeExpandPlan(convSubQueryPlan)
val decorPlan = RelDecorrelator.decorrelateQuery(expandedPlan, relBuilder)
val planWithMaterializedTimeAttributes =
RelTimeIndicatorConverter.convert(decorPlan, relBuilder.getRexBuilder)
// Normalize flow calculation , according to DATASTREAM_NORM_RULES application HepPlanner Rule optimization
val normalizedPlan = optimizeNormalizeLogicalPlan(planWithMaterializedTimeAttributes)
// Logical planning optimization , according to LOGICAL_OPT_RULES application VolcanoPlanner Rule optimization
val logicalPlan = optimizeLogicalPlan(normalizedPlan)
val logicalRewritePlan = optimizeLogicalRewritePlan(logicalPlan)
// Optimize flow computing , according to DATASTREAM_OPT_RULES application Volcano Rule optimization
val physicalPlan = optimizePhysicalPlan(logicalRewritePlan, FlinkConventions.DATASTREAM)
// Decorative flow calculation , according to DATASTREAM_DECO_RULES application HepPlanner Rule optimization
optimizeDecoratePlan(physicalPlan, updatesAsRetraction)
}
It can also be seen from the above process ,Flink be based on FlinkRuleSets Of rule In the process of transformation , It includes Optimize logical Plan The process of , It also includes generating Flink PhysicalPlan The process of .
Flink Logical planning optimization
from 3.3.5.1 The optimization process of section can be seen ,Flink It's going on logical Plan Before optimization , Will be applied HepPlanner in the light of TABLE_SUBQUERY_RULES、EXPAND_PLAN_RULES、POST_EXPAND_CLEAN_UP_RULES、DATASTREAM_NORM_RULES These rules are preprocessed , After that To apply VolcanoPlanner in the light of LOGICAL_OPT_RULES The optimization rules listed in , Try using different rules to optimize , An optimization that attempts to calculate the optimum plan return , The simple point is one relNode Pass in different optimization rules , One time optimization , Get the best results .
VolcanoPlanner The optimization operation of is :
** Optimizer.scala **
protected def optimizeLogicalPlan(relNode: RelNode): RelNode = {
val logicalOptRuleSet = getLogicalOptRuleSet
val logicalOutputProps = relNode.getTraitSet.replace(FlinkConventions.LOGICAL).simplify()
if (logicalOptRuleSet.iterator().hasNext) {
runVolcanoPlanner(logicalOptRuleSet, relNode, logicalOutputProps)
} else {
relNode
}
1. Logic RelNode :normalizedPlan
application HepPlanner in the light of Preprocessing rules After pretreatment , You'll get Logic RelNode :
contrast Sql After parsing, we get SqlNode Find out , Logic RelNode Also hold Sql Composed of The mapping information , besides , comparison SqlNode,Logic RelNode Add the... Of each node rowType Type information .
2. Optimized Logical RelNode :logicalPlan
VolcanoPlanner according to FlinkRuleSets.LOGICAL_OPT_RULES Find the best execution Planner, And converted to Flink Logical RelNode return :
3.3.6 Generate a physical plan (LogicalRelNode–>Physic Plan)
application VolcanoPlanner in the light of FlinkRuleSets.DATASTREAM_OPT_RULES, take Optimized Logical RelNode Convert to Flink Physic Plan (Flink Logical RelNode -> DataStream RelNode).
here , The user's execution plan has been optimized as follows :
== Optimized Logical Plan ==
If it is RetractStream You will also use FlinkRuleSets.DATASTREAM_DECO_RULES Conduct Retract features A package of :
thus ,Step-4: Optimization stage + Step-5: Generate a physical plan Completed .
3.3.7 Generate DataStream(Physic Plan–>DataStream)
StreamTableEnvironment.scala Of translate The last step in the method ,Step-6: Turn into DataStream, Here, the user's business Sql It turns into Stream Api perform . There are the above mentioned translateToCRow Method to a real stream . For the optimized logical plan ( Actually converted to physical plan DataStreamRel), Traverse each node from outside to inside , take DataStreamRel Node Turn into DataStream, Take the following physical plan as an example :
== Optimized Logical Plan ==
Call recursively in turn DataStreamUnion、DataStreamCalc、DataStreamScan Class Rewrite the translateToPlan Method , The node's DataStreamRel Realization Turn into DataStream Implementation of the execution plan .
About DataStreamRel The class inheritance relationship of is shown in the following figure ,RelNode yes Calcite Defined Sql Node relationship data structure ,FlinkRelNode Inherited from RelNode, It has three implementations , Namely FlinkLogicalRel、DataStreamRel、DataSetRel, They correspond to each other Flink Inside Yes Sql Of expression Description of logical plan and physical plan .


3.4 summary Flink Sql Execute the process

4. CodeGen
Let's start with codegen:
Codegen Is based on ObjectWeb ASM Low overhead java Code generator , He can fill in the rules and conditions in advance , By compiling the code , Automatic generation java class 
Call each node recursively DataStreamRel Of translateToPlan When the method is used , Make use of CodeGen Meta programming Flink All kinds of operators of , It's equivalent to our direct use of Flink Of DataSet or DataStream API Developed programs .
Or on top Demo For example , Follow up DataStreamScan Of translateToPlan In the method , You will find the relevant logic :
- First generate function The string form of the code , And encapsulate it into GeneratedFunction object ;
- And then use CodeGen Compile ;
- In need of use Function When using reflection to load .
Follow up Expand flink grammar ( Such as join Dimension table ) when , It is necessary for the above steps , Splicing generation function String form of .

5. flink Grammar extension
To understand the Flink Sql After the execution process of , You can Flink Sql Do grammar 、 Functional expansion .
stay Flink In the old version ,Flink I won't support it COUNT(DISTINCT aaa) grammar , But if you need to be right Flink Expand this function , Need to combine As mentioned earlier Flink Sql Execute the process , Make corresponding changes .
Modify the point :
- It's going on Rule When rules match , Let go, right Distinct The limitation of
- DataStreamRelNode To DataStream In the process , Splicing CodeGen The required Function String
5.1 It's going on Rule When rules match , Let go, right Distinct The limitation of
stay DATASTREAM_OPT_RULES.DataStreamGroupWindowAggregateRule Let go of... In the middle Distinct The limitation of :
5.2 Attached below is a utilize codegen To generate examples of the required classes :
Create a new project , Copy from the source code codegen Code folder 
In the configuration file , Add good ,sql Reserved words , keyword , Class name and other information , Not much here , Students in need can baidu specific principles and technologies
Create a new one SqlUseFunction.java This is what I mentioned above function The string form of the code ,
stay flink in , It is through Assemble to assemble a class , call codegen To compile and get the inherited abstract class SqlNode Methods , So I can't find it in the developed source code codegen Something related to , But in fact, he was involved in the work .
package com;
import org.apache.calcite.sql.*;
import org.apache.calcite.sql.parser.SqlParserPos;
import org.apache.calcite.util.ImmutableNullableList;
import java.util.List;
public class SqlUseFunction extends SqlCall {
private static final SqlSpecialOperator OPERATOR = new SqlSpecialOperator("USE FUNCTION",
SqlKind.OTHER_FUNCTION);
private final SqlIdentifier funcName;
private final SqlNodeList funcProps;
/** * SqlUseFunction constructor. * * @param pos sql define location * @param funcName function name * @param funcProps function property * */
public SqlUseFunction(SqlParserPos pos, SqlIdentifier funcName, SqlNodeList funcProps) {
super(pos);
this.funcName = funcName;
this.funcProps = funcProps;
}
@Override
public void unparse(SqlWriter writer, int leftPrec, int rightPrec) {
writer.keyword("USE FUNCTION");
funcName.unparse(writer, leftPrec, rightPrec);
if (funcProps != null) {
writer.keyword("WITH");
SqlWriter.Frame frame = writer.startList("(", ")");
for (SqlNode c : funcProps) {
writer.sep(",");
c.unparse(writer, 0, 0);
}
writer.endList(frame);
}
}
@Override
public SqlOperator getOperator() {
return OPERATOR;
}
@Override
public List<SqlNode> getOperandList() {
return ImmutableNullableList.of(funcName, funcProps);
}
}
pom Specify in the file , Use fmpp technology , as well as codegen Address, etc
<build>
<plugins>
<!-- adding fmpp code gen -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<id>copy-fmpp-resources</id>
<phase>initialize</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/codegen</outputDirectory>
<resources>
<resource>
<directory>src/main/codegen</directory>
<filtering>false</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<!-- from calcite-core.jar Extract parser syntax template , And put it in ${project.build}freemarker The directory where the template is located -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.8</version>
<executions>
<execution>
<id>unpack-parser-template</id>
<phase>initialize</phase>
<goals>
<goal>unpack</goal>
</goals>
<configuration>
<artifactItems>
<artifactItem>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.18.0</version>
<type>jar</type>
<overWrite>true</overWrite>
<outputDirectory>${project.build.directory}/</outputDirectory>
<includes>**/Parser.jj</includes>
</artifactItem>
</artifactItems>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<configuration>
<cfgFile>${project.build.directory}/codegen/config.fmpp</cfgFile>
<outputDirectory>target/generated-sources</outputDirectory>
<templateDirectory>${project.build.directory}/codegen/templates</templateDirectory>
</configuration>
<groupId>com.googlecode.fmpp-maven-plugin</groupId>
<artifactId>fmpp-maven-plugin</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
</dependencies>
<executions>
<execution>
<id>generate-fmpp-sources</id>
<phase>generate-sources</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>javacc-maven-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>generate-sources</phase>
<id>javacc</id>
<goals>
<goal>javacc</goal>
</goals>
<configuration>
<sourceDirectory>${project.build.directory}/generated-sources/</sourceDirectory>
<includes>
<include>**/Parser.jj</include>
</includes>
<lookAhead>2</lookAhead>
<isStatic>false</isStatic>
<outputDirectory>${project.build.directory}/generated-sources/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
边栏推荐
- 4 life distributions
- Handler、Message、Looper、MessageQueue
- [shangyun boutique] energy saving and efficiency improvement! Accelerating the transformation of "intelligent manufacturing" in the textile industry
- Kingbasees plug-in DBMS of Jincang database_ OUTPUT
- Dynamic programming to solve stock problems (Part 1)
- Geographic location system based on openstreetmap+postgis paper documents + reference papers + project source code and database files
- Customize to prevent repeated submission of annotations (using redis)
- Comparison between relu and SIGMOD
- C disk uses 100% cleaning method
- 西山科技冲刺科创板:拟募资6.6亿 郭毅军夫妇有60%表决权
猜你喜欢

Query method and interrupt method to realize USART communication

龙书虎书鲸书啃不动?试试豆瓣评分9.5的猴书

牛客网:主持人调度

一个数学难题,难倒两位数学家

redis的dict的扩容机制(rehash)

Comment TCP gère - t - il les exceptions lors de trois poignées de main et de quatre vagues?

基于SSH的高校实验室物品管理信息系统的设计与实现 论文文档+项目源码及数据库文件

What is the development history, specific uses and structure of the chip

c盘使用100%清理方法

翌圣生物冲刺科创板:25%收入来自新冠产品销售 拟募资11亿
随机推荐
Arrays.asList()
Spark tuning tool -- detailed explanation of sparklens
记一次有趣的逻辑SRC挖掘
Detailed explanation of Spark's support source code for Yan priority
TCP如何处理三次握手和四次挥手期间的异常
Bayes
Leetcode 1249. 移除无效的括号(牛逼,终于做出来了)
JVM 原理简介
如何实现移动端富文本编辑器功能
SQL injection vulnerability (type chapter)
Redis6 note02 configuration file, publish and subscribe, new data type, jedis operation
Shichuang Energy sprint Technology Innovation Board: le chiffre d'affaires annuel prévu de 1,1 milliard de RMB est de 0,7 milliard de RMB, en baisse de 36%
c盘使用100%清理方法
JVM shutdown hook details
龙书虎书鲸书啃不动?试试豆瓣评分9.5的猴书
Big Endian 和 Little Endian
Shichuang energy rushes to the scientific innovation board: it plans to raise 1.1 billion yuan, with an annual revenue of 700million yuan and a 36% decrease in net profit
What is the development history, specific uses and structure of the chip
Idea uses the fast request interface for debugging
Kingbasees plug-in DBMS of Jincang database_ UTILITY