当前位置:网站首页>Convolutional neural network CNN
Convolutional neural network CNN
2022-07-24 19:16:00 【Coding~Man】
https://cs231n.github.io/assets/conv-demo/index.html
Network model training three musketeers : normalization ,dropout, And activation functions .
1: Common activation functions of Neural Networks 

2: Convolutional neural networks
Convolution kernel ,padding, and stride step .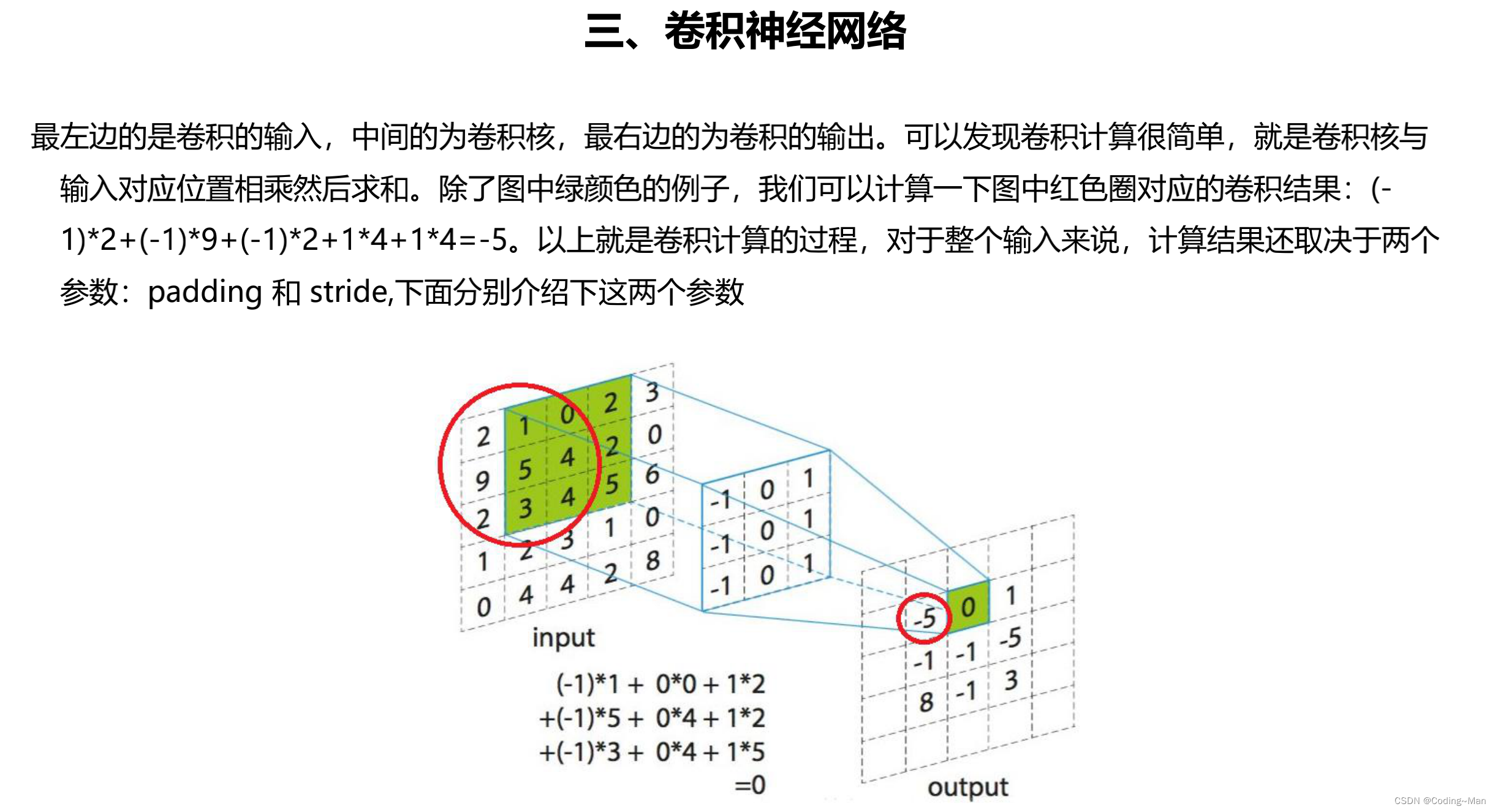
Padding The role of , In order to keep the shape of the input-output matrix unchanged .
Stride It's the step length .
Multichannel convolution :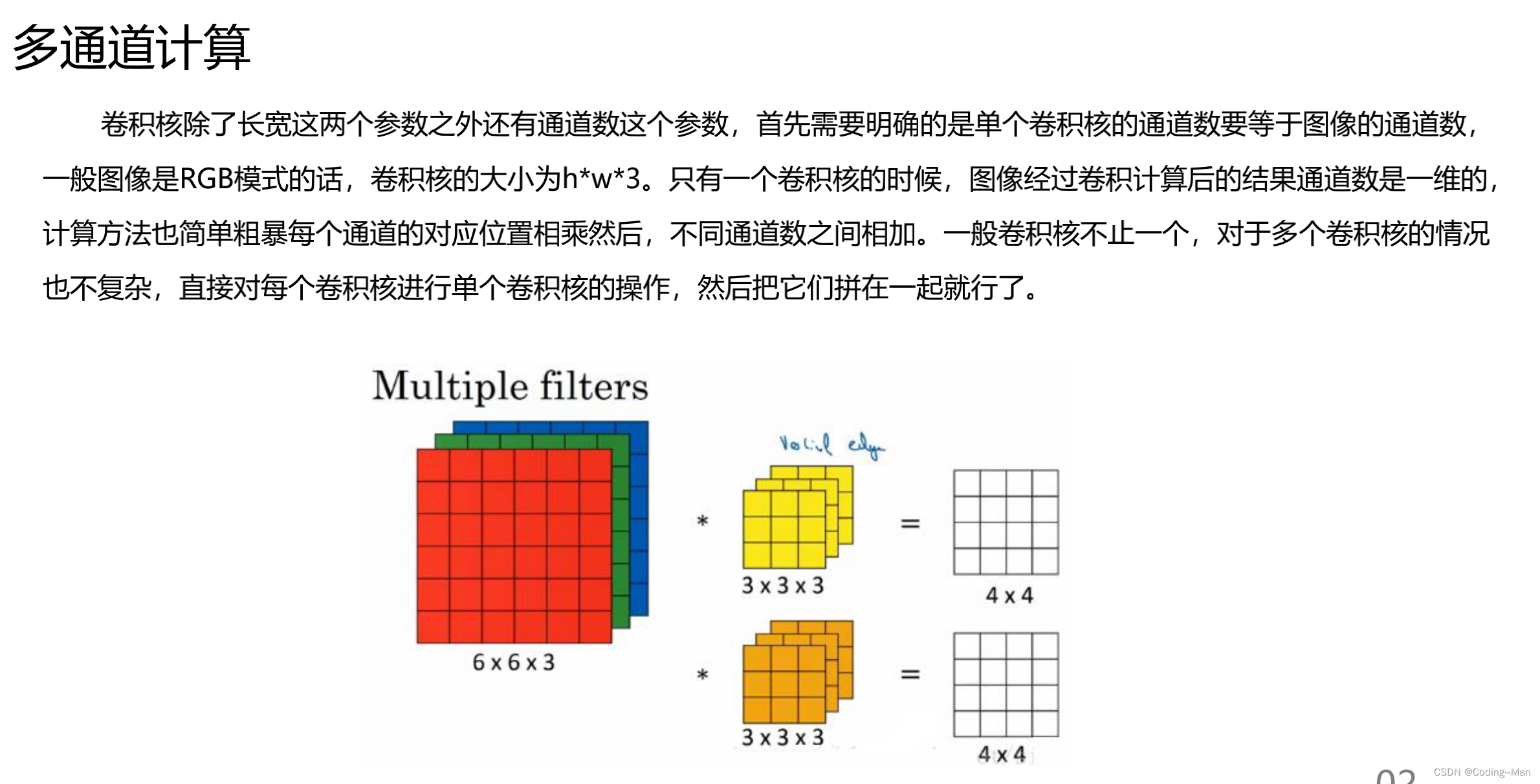
3: Methods to prevent over fitting
1:DropOut Randomly change the output of the node into 0.
2:DropConnect Random will WX Medium W become 0.
3:DisOut Randomly assign different weights to nodes (0~1 Between ).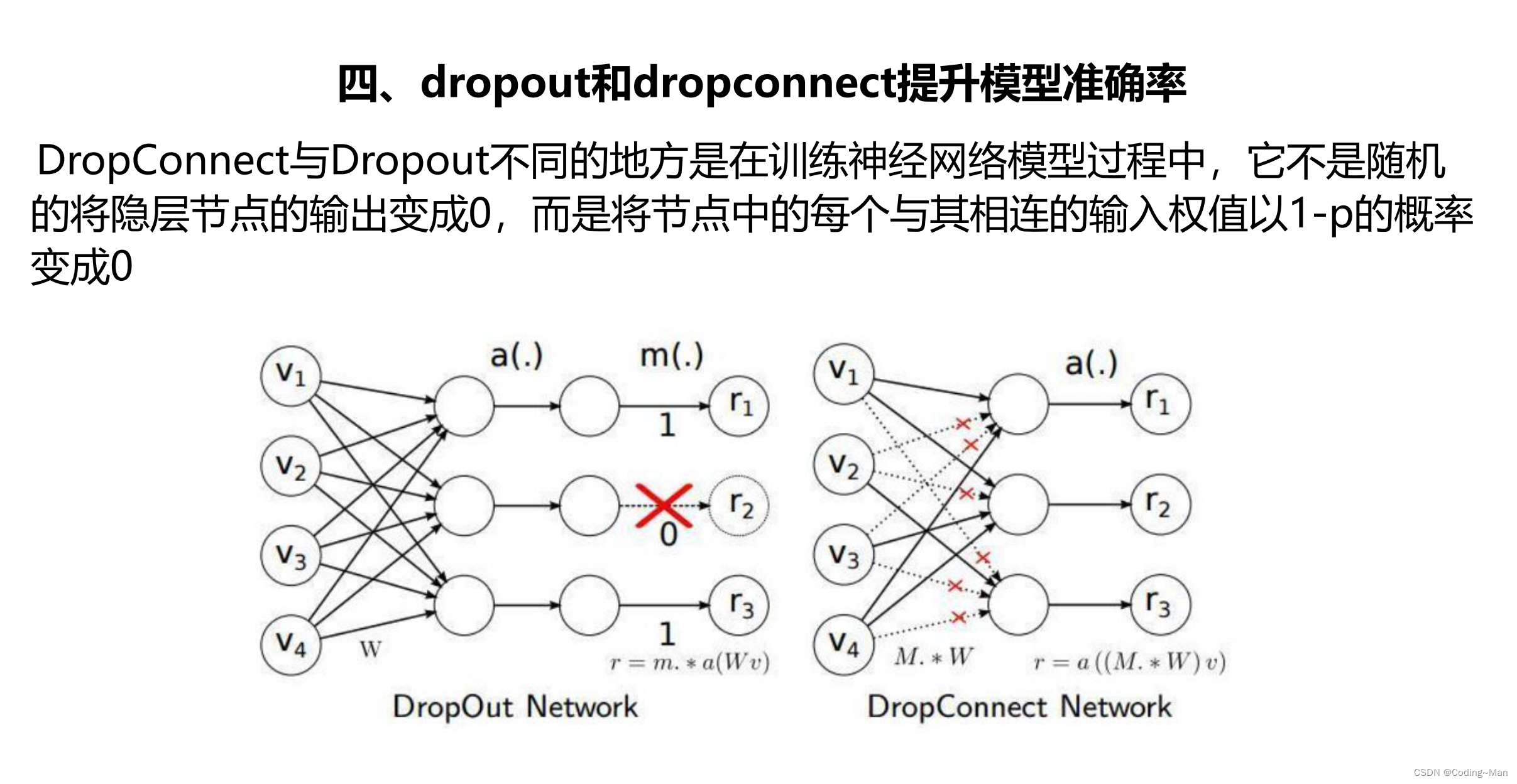

4: The activation function is large PK
sigmoid The value range of the function is 0~1 Between .
tanh The value range of the function is -1~1 Between .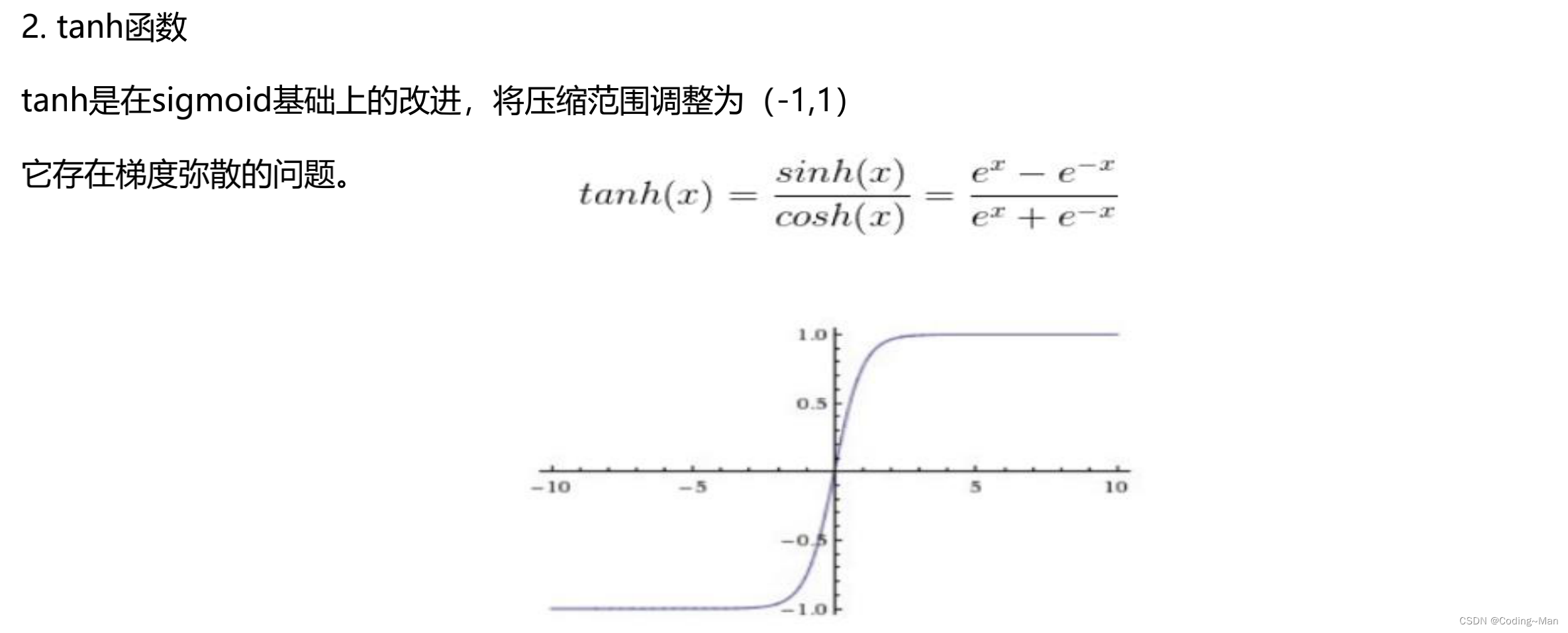
relu The value range of the function is 0~X Between .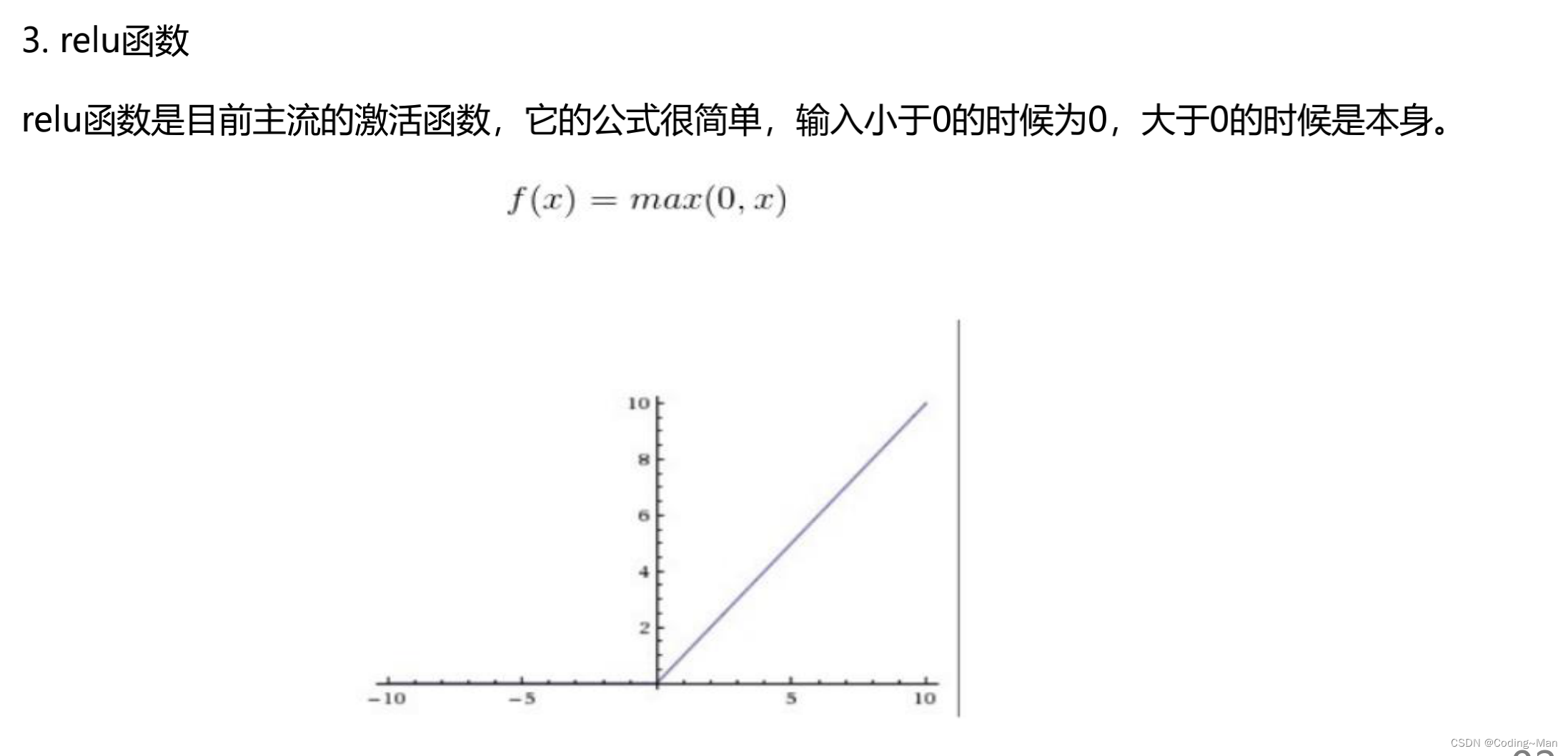


5: Pooling Pooling 

6: Full link layer
The difference between full connection and neural network , Full connection has no activation function .
7: normalization
Normalized benefits : Speed up training , Improve accuracy
Batch Normalization: stay BatchSize Layer normalization , for example BatchSize = 258, Then normalize the data in the dimension of the input quantity of the data .
Only batchsize Big enough to , Because it is too small , Not enough to represent the whole sample .


C: The channel number
N: Sample size 

8: Parameter initialization 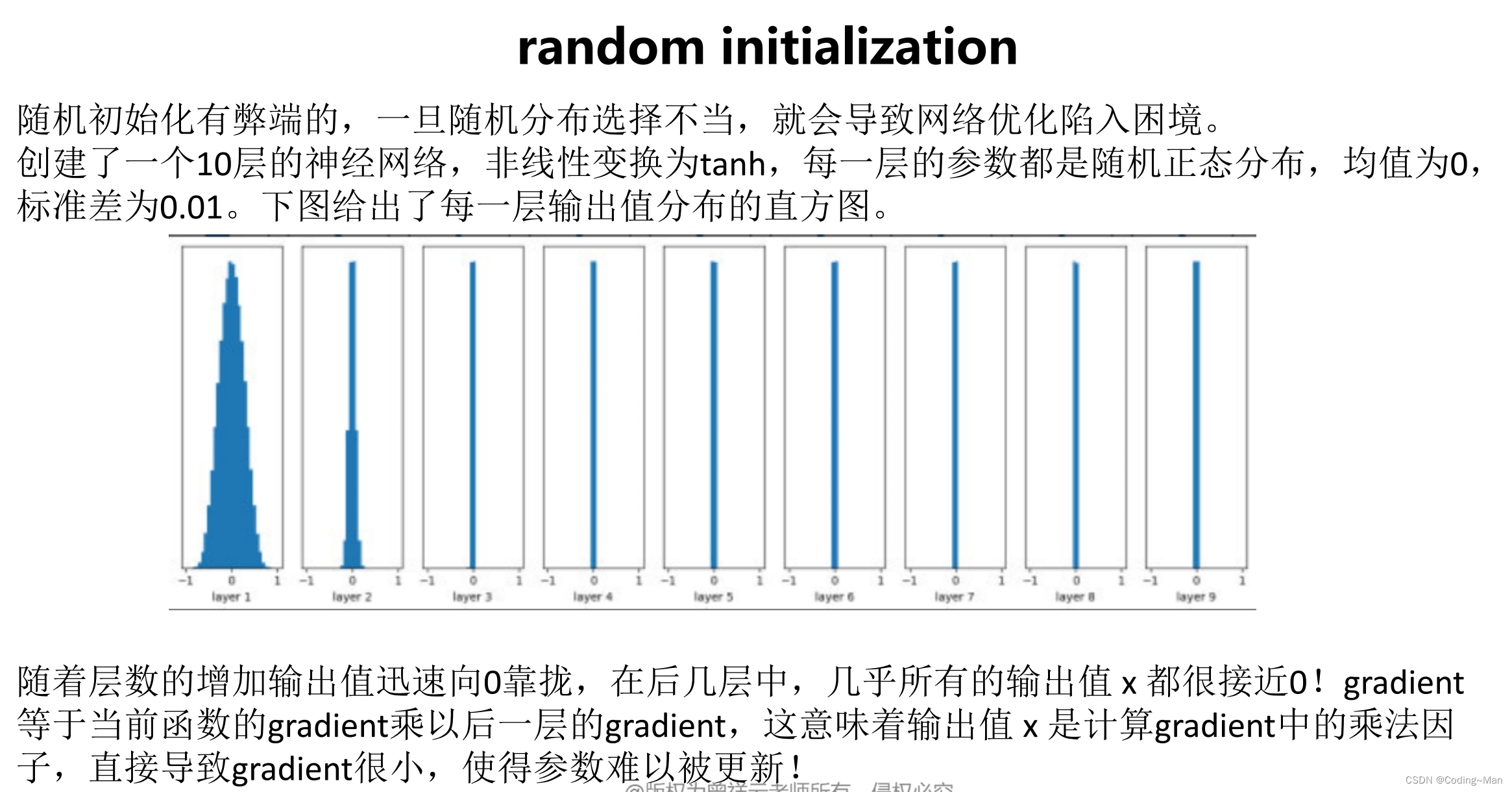
Xavier initialization , Initialize according to the standard distribution ,node_in = 9, node_out = 8, initialization 9*8 dimension /(9 Square root ). The best and Tanh Function with .
He initialization Initialization and ReLU Function with .
9: Learning rate 

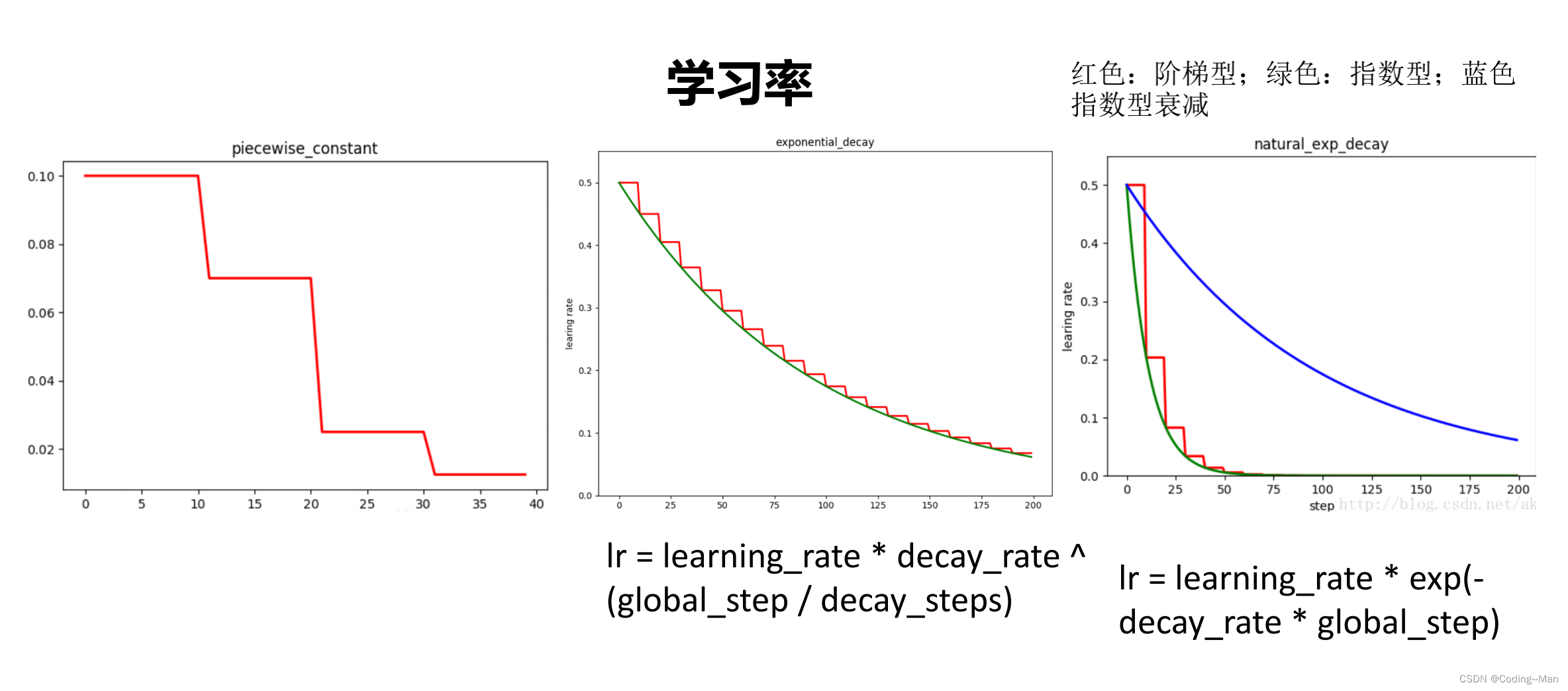
Exponential decay , The learning rate decreases with the number of steps .
The above learning rate is the most common way , Periodically change the learning rate to prevent local optimization , and consion Combination of cosine learning rate .
10: Optimizer
effect : After the model is built, the parameters are solved .
Optimizer and @ The difference between : Because you can't put all the data in the depth model , So use the optimizer . and @ All the data is put in .
The benefits of the optimizer : The learning rate is variable , You can refer to the historical gradient , You can use each bitchsize Gradient of . Simply put, the benefit of the optimizer is to put the data in once to get the value of the update item and each bitchsize The value obtained from the data is closer .

Optimizer : There are two main ideas , One is Momentum faction , That is, the impulse on the falling belt , Representative for :SGD. The other is AdaGrad faction , Thought is too volatile , Give him resistance , Prevent you from fluctuating .
Representative for :Adam A combination of two ideas .

Prevent falling into local optimum , We can add the gradient of historical update , And the current gradient weighting 

Anti noise treatment :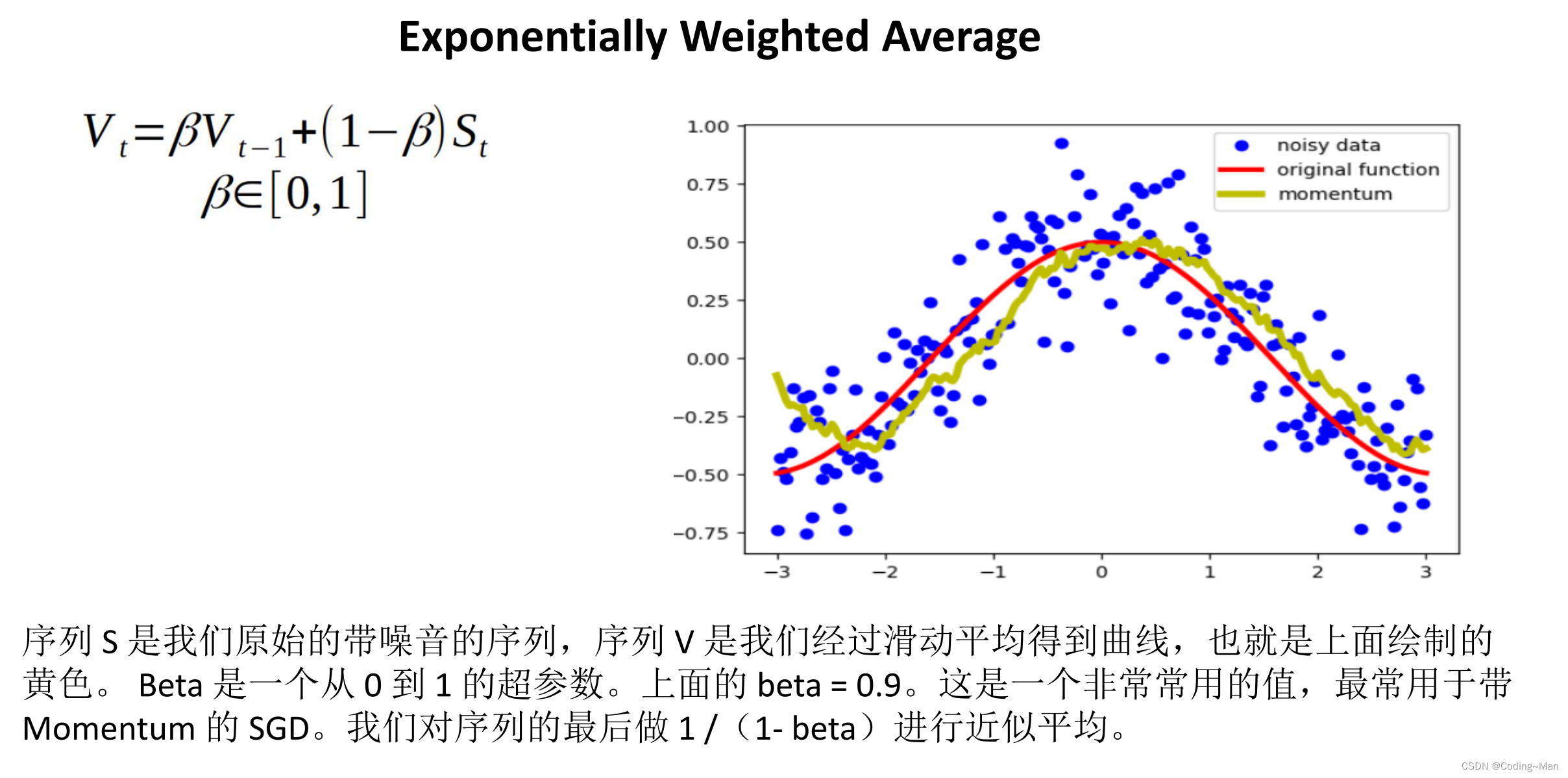


AdaGrad
RMSprop
边栏推荐
- Calendar common methods
- Mysql数据库,子查询,union,limit篇
- Convolutional Neural Networks in TensorFlow quizs on Coursera
- Crazy God redis notes 11
- JS part
- 知乎上的那些神回复
- He has been in charge of the British Society of engineering and technology for 13 years, and van nugget officially retired
- Nezha monitoring - server status monitoring, SSL certificate change expiration, Ping monitoring and scheduled task reminder
- profile环境切换
- MySQL hidden version number
猜你喜欢

PostgreSQL weekly news - July 13, 2022

Reading notes of XXL job source code

OpenGL learning (II) opengl rendering pipeline

Common problems of multithreading and concurrent programming (to be continued)

Nacos introduction and console service installation
![[today in history] July 24: caldera v. Microsoft; Amd announced its acquisition of ATI; Google launches chromecast](/img/7d/7a01c8c6923077d6c201bf1ae02c8c.png)
[today in history] July 24: caldera v. Microsoft; Amd announced its acquisition of ATI; Google launches chromecast

High speed ASIC packaging trends: integration, SKU and 25g+

暑期牛客多校1: I Chiitoitsu(期望dp,求逆元)

PostgreSQL Elementary / intermediate / advanced certification examination (7.16) passed the candidates' publicity

Convolutional Neural Networks in TensorFlow quizs on Coursera
随机推荐
PCIe link initialization & Training
Redis data type
Tupu software digital twin civil aviation flight networking, building a new business form of smart Civil Aviation
MySQL version 5.7.9 SQL_ mode=only_ full_ group_ By question
matplotlib
[in depth study of 4g/5g/6g topic -39]: urllc-10 - in depth interpretation of 3GPP urllc related protocols, specifications and technical principles -3- how to distinguish urllc services? Detailed expl
Reading notes of XXL job source code
OpenGL learning (IV) glut 3D image rendering
Hangdian multi School Game 1 question 3 backpack (XOR dp+bitset)
OPENGL学习(五)Modern OpenGL 三角形绘制
Mysql数据库,子查询,union,limit篇
32-bit stack overflow advanced
OpenGL learning (V) modern OpenGL triangle rendering
拦截器和过滤器
卷积神经网络感受野计算指南
Tclsh array operation
Principle and application of database
Unity code imports packages through package manager
This visual analysis library makes it easy for you to play with data science!
Analysis of dropout principle in deep learning