当前位置:网站首页>Shrimp skin test surface treated
Shrimp skin test surface treated
2022-06-24 21:00:00 【comeoncode】
It was sorted out before , Give this year's students a reference ! If something goes wrong , Welcome to correct ! come on. !
The shrimp skin test noodles have been treated
Catalog
3、 ... and 、 Algorithm problem
One 、 Basic knowledge of
1、 operating system
Process scheduling algorithm :
First come, first served 、 Time slice rotation 、 The shortest work is preferred 、 The shortest remaining time is preferred 、 Highest response ratio 、 Multilevel feedback queue scheduling algorithm
2、 data structure
3、 computer network
(1)TCP How to ensure reliable transmission
The checksum 、 Confirm response + Serial number 、 Over time retransmission 、 flow control 、 Congestion control
TCP Four waves TIME_WAIT
At the third wave , The server sends FIN To the client , Then the client sends it again ACK Command to client , Then enter TIME_WAIT state ,2MSL after , Get into CLOSED state , From the client's point of view , The fourth wave is to tell the server , I received your FIN The signal , Everything is all right , wait for 2MSL To ensure that the server receives ACK, If the server fails to receive because of network fluctuation ACK, Then the server will retransmit FIN The signal . From the perspective of the server, I always say , The fourth wave ensures that the client receives FIN The signal .
- In order to achieve TCP Reliable release of full duplex connection : If the client last sent to the server ACK Confirm that the closing message segment is missing , At this time, the connection between the two is not completely closed , Based on timeout retransmission , The server will send a message to the client again Fin Package request disconnect , If it is closed directly , Then it will be directly followed by RST The package responds to the other party , This will be considered as a mistake by the other party , Cause the connection to fail to close .
- In order to make the old packets disappear in the network due to expiration : Actually, one. TCP The connection can be uniquely identified by a quad :( client IP, client port, Server side IP, Server side port), If the last connection was closed directly , And the second time, it is connected with the same quadruple parameters , The data receiver cannot tell the difference between the two events ; If any old data arrives at the receiving end , The old connection is broken and a new one is made up of the same quads TCP Connection established , Then the old data will be mixed with the new data of this connection and transmitted to the application layer , Cause an abnormality . So wait 2 Maximum message lifetime segment , Ensure that no new connections are established at this time , And make the original packet invalid due to timeout .
TCP、UDP The difference between
- TCP Connection oriented ( If you want to make a call, dial to establish a connection );UDP It's disconnected , That is, you don't need to establish a connection before sending data
- TCP Provide reliable service . in other words , adopt TCP Connect the transmitted data , No mistakes , No loss , No repetition , And arrive in order ;UDP Do your best to deliver , That is, there is no guarantee of reliable delivery
- TCP Byte stream oriented , It's actually TCP Think of data as a stream of unstructured bytes ;UDP It's message oriented
- UDP no congestion control , Therefore, the network congestion will not reduce the transmission rate of the source host ( Useful for real-time applications , Such as IP Telephone , Real time video conference, etc )
- Every one of them TCP Connections can only be point-to-point ;UDP Support one-to-one , One to many , Many to one and many to many interactive communication
- TCP First cost 20 byte ;UDP The cost of the first part is small , Only 8 Bytes
- TCP The logical communication channel of is a full duplex reliable channel ,UDP It's an unreliable channel
Three handshakes
- The first handshake : When establishing a connection , The client sends syn package (syn=x) To the server , And enter SYN_SENT state , Wait for server to confirm ;SYN: Sync sequence number (Synchronize Sequence Numbers).
- The second handshake : Server received syn package , Must confirm customer's SYN(ack=x+1), At the same time, I also send a SYN package (syn=y), namely SYN+ACK package , At this time, the server enters SYN_RECV state ;
- The third handshake : Client receives server's SYN+ACK package , Send confirmation package to server ACK(ack=y+1), This package has been sent , Client and server access ESTABLISHED(TCP Successful connection ) state , Complete three handshakes .
Four waves
- wave 1: When the client has no data to send , Decide to release the connection , Will send a termination message , Active shut down TCP even Pick up , Where the termination control bit FIN=1, Serial number seq=u,u The value of is the last sequence number sent by the previous client +1. At this time, the client enters FIN-WAIT1( Stop waiting 1) state , wait for B The confirmation of .FIN A sequence number will be consumed even if the message segment does not carry data .
- wave 2: After the server receives the message , Send a confirmation message to the client ,ACK=1,ack=u+1,seq=v,v The value of is sent by the server The next serial number +1. At this point the client enters FIN-WAIT-2( Stop waiting 2) state , The server has entered CLOSE-WAIT( Turn off waiting ) shape state , But the connection is not completely released , The server will notify the high-level application layer to end the connection from the client to the server , here TCP In a semi closed state state , The server can send data to the client , But the client cannot send data to the server .
- wave 3: When the server sends the data , When preparing to release the connection, send the connection termination message to the client ,FIN=1, At the same time, you have to resend ACK=1, ack=u+1,seq=w( In the half closed state B Maybe sent some more data , So repeat the confirmation number that has been sent before ack=u+1). At this time, the client enters LAST-ACK state .
- wave 4: After receiving the connection termination message, the client needs to confirm again , In the confirmation message ACK=1,ack=w+1,seq=u+1. send out After that, enter TIME-WAIT( Time waits ) state , Wait for the time set by the timer 2MSL(Maximum Segment Lifetime) After entering CLOSED state , After receiving the confirmation, the server also enters CLOSED state .
Why three handshakes when connecting , When it's closed, it's four waves
- 1. TCP The only reason to establish a connection is to " Three handshakes ", Because the second time " handshake " In the process , What the server sends to the client TCP The message is based on SYN And ACK As a sign bit .SYN Is the request connection flag , Indicates that the server agrees to establish a connection ;ACK It's a confirmation message , Tell the client , The server received its request message . namely SYN Set up connection message and ACK Confirm that the message is received at the same time " handshake " The transmission of , therefore " Three handshakes " No more, no more , Just so that both sides can clearly communicate with each other .
- 2. TCP The reason for releasing the connection is “ Four waves ”, Because FIN Release connection message and ACK Confirm that the received message is from the second time and the third time " handshake " Transmission of . Why are connections transmitted together , When releasing the connection, it needs to be transmitted separately ? When establishing a connection , Passive server end CLOSED Phase in “ handshake ” The stage doesn't require any preparation , Can return directly SYN and ACK message , Start connection . Release connection , Passive server , The connection cannot be released immediately upon receiving the request of the active client to release the connection , Because there is still necessary data to be processed , So the server returns first ACK Acknowledge receipt of message , after CLOSE-WAIT After the stage is ready to release the connection , Before returning FIN Release connection message .
So it is “ Three handshakes ”,“ Four waves ”
Why not connect with two handshakes ?
- 3 The second handshake accomplishes two important functions , Both sides should be ready to send data ( Both sides know that they are ready to ), Also allow both parties to negotiate the initial serial number , This serial number is sent and confirmed during handshake .
- Now change three handshakes to just two , Deadlocks are possible . As an example , Consider computers S and C Communication between , Assume C to S Send a connection request packet ,S Received this group , Concurrent Send confirmation response group . According to the agreement of two handshakes ,S Think the connection has been successfully established , You can start sending data packets . But ,C stay S In case that the reply packet of is lost in the transmission , Will not know S Are you ready to , I do not know! S What kind of serial number to create ,C Even doubted S Whether to receive your own connection request grouping . under these circumstances ,C Think the connection has not been established successfully , Will ignore S Any data sent... Points Group , Only wait for the connection to confirm the reply group . and S After the outgoing packet times out , Send the same packet over and over again . This creates a deadlock .
If a connection has been established , But what to do if the client suddenly fails ?
- TCP There is also a survival timer , obviously , If the client fails , The server can't wait , Waste resources in vain . Every time the server receives a request from the client, it will reset the timer , The time is usually set to 2 Hours , If you haven't received any data from the client in two hours , The server will send a detection segment , After every 75 Send once per second . If you send it in a row 10 Detection messages still don't respond , The server thinks the client is down , Then close the connection .
TCP Congestion control algorithm
- Slow start algorithm : The sender will maintain a Congestion window The variable of ; Just started sending , from 2^0 Start sending , The receiver sends an acknowledgement for each message sent ; Send messages exponentially all the way back , The congestion window also changes , When the threshold is reached , Stop using slow start algorithm , change to the use of sth. Congestion avoidance algorithm
- Congestion avoidance algorithm :
- Add more : When the congestion window exceeds its threshold , Increase by adding , After every round-trip time ( From sending to receiving the confirmation packet ), Add the congestion window value 1; It grows linearly ;
- Multiplication is reduced : While the congestion window keeps growing , When network packet loss occurs , Stop using addition to increase , Use multiplicative reduction instead ; Halve the value of the congestion window as the value of the new threshold , Then the congestion window starts from 2^0 Start , Re execute the slow start algorithm .
- Fast retransmission algorithm :
- Sometimes , Individual message segments will be lost in the network , But in fact, the network is not congested ;
- This will cause the sender to time out and retransmit , And mistakenly believe that the network is congested ;
- The sender mistakenly started the slow start algorithm , And set the congestion window to the minimum 1, Thus, the transmission efficiency is reduced .
- The so-called fast retransmission algorithm is : Enable the sender to retransmit as soon as possible , Instead of waiting for the timeout retransmission timer to timeout and retransmit .
- The receiver is required not to wait for the data to be sent before waiting for confirmation , It's about sending an immediate confirmation ;
- Fast recovery algorithm :


TCP Long short connection , Advantages and disadvantages
So called long connection , Point at a TCP Multiple packets can be sent continuously on the connection , stay TCP During connection hold , If no packets are sent , Both parties need to send test packets to maintain this connection .
Short connection refers to the time when the communication parties have data interaction , Just build a TCP Connect , When the data is sent , Then disconnect this TCP Connect , Each time TCP The connection only completes a pair of CMPP Sending of messages .
At this stage , requirement ISMG The communication mode of long connection must be adopted , Suggest SP And ISMG The communication mode of long connection is adopted .
Application scenarios :
The connection of database is long connection , Frequent communication with short connections can cause socket error , And often socket Creating is also a waste of resources .
WEB Website http The service usually uses short links , Because long connection will consume certain resources for the server , And like WEB The website has so many thousands or even hundreds of millions of clients Using a short connection will save more resources , If you use a long connection , And at the same time
Thousands of users , If each user occupies a connection , You can imagine . So there's a lot of concurrency , But each user doesn't need to use frequency In case of complicated operation, short connection is required .
A long connection 、 Advantages and disadvantages of short connection :
Long connection can save more TCP Set up and shut down operations , Reduce waste , Saving time . For clients that frequently request resources, long connections are suitable . In a long connected application scenario ,client Generally, the terminal will not actively close the connection , When client And server The connection between has not been closed , As clients connect more and more ,server Will keep too many connections . Now server The end needs to take some strategies , Such as closing some connections that haven't been requested for a long time , This can avoid some malicious connections server End service damage ; If conditions permit, you can limit the maximum number of long connections per client , This can completely prevent malicious clients from dragging down the overall back-end services .
Short connections are easier for servers to manage , The existing connections are all useful connections , There is no need for additional controls . But if the customer requests frequently , Will be in TCP A lot of time and bandwidth are wasted on the setup and shutdown of .
cookie and session The difference between
What is? cookie? What is? session?
- cookie On the user's computer , It is used to maintain the information in the user's computer , Until the user deletes . For example, when we log in a certain software on the web page and input the user name and password, if it is saved as cookie, Every time we visit, we don't need to log in to the website . We can save any text in the browser , And we can stop it or delete it anytime and anywhere . We can also disable or edit cookie, But there is one thing you need to be careful not to use cookie To store some privacy data , In case of privacy disclosure
- session It's called conversation information , be located web Server , Mainly responsible for the interaction between visitors and the website , When the browser requests http Address time , Will pass on to web On the server and match the access information , When the website is closed, it means that the session has ended , The website can't access the information , So it can't save permanent data , We can't access and disable websites
difference :
- The data is stored in different locations :cookie The data is stored in the customer's website du On the browser ,session Data playback zhi On the server .
- Different levels of security :cookie Not very safe , Others can analyze the local COOKIE And carry on COOKIE cheating , Should be used in consideration of safety session.
- Performance is used to different degrees :session It will be saved on the server for a certain period of time . When visits increase , It will take up the performance of your server , Consider reducing server performance , Should be used cookie.
- Data storage size is different : Single cookie The saved data cannot exceed 4K, Many browsers limit a site to save at most 20 individual cookie, and session Then the storage and server , Browsers have no restrictions on it
- The conversation mechanism is different :
- session Conversational mechanism :session Session mechanism is a server-side mechanism , It uses something similar to a hash table ( There may also be hash tables ) Structure to hold information .
- cookies Conversational mechanism :cookie Is a small piece of text that the server stores on the local computer , And send it to the same server with each request . Web Server usage HTTP Header will cookie Send to client . On the client terminal , Browser parsing cookie And save it as a local file , The file automatically binds any request from the same server to these cookie.
HTTP and HTTPS The difference between :
- http and https The difference between :
- HTTPS The agreement needs to reach CA (Certificate Authority, Certification authority ) Apply for a certificate , Generally, there are fewer free certificates , So there is a certain cost .( In the past, the official website of Netease was http, And Netease email is https .)
- HTTP It's the hypertext transfer protocol , The message is transmitted in clear text ,HTTPS It is safe SSL Encrypted transport protocol .
- HTTP and HTTPS It USES a completely different connection , The ports are different , The former is 80, The latter is 443.
- HTTP The connection is simple , It's stateless .HTTPS Agreement is made SSL+HTTP The protocol is built for encrypted transmission 、 Network protocol for identity authentication , Than HTTP Security agreement .( Stateless means the sending of packets 、 Transmission and reception are independent of each other . No connection means that both sides of the communication do not maintain any information of each other for a long time .)
HTTP No state 、 What does connectionless mean
HTTP Protocol is stateless , It means that the protocol has no memory for transaction processing , The server does not know what the client status is . in other words , There is no connection between opening a web page on a server and the last web page opened on this server .HTTP Is a stateless connection oriented protocol , Stateless does not mean HTTP Can not keep TCP Connect , Not to mention HTTP It uses UDP agreement ( There is no connection ).
The meaning of no connection It's a limit to only one request per connection . The server completes the client's request , And received the customer's response , disconnect . This way you can save transmission time . Establish connection for request 、 Request to release connection , To release resources as soon as possible to serve other clients , You can add KeepAlive Make up for the problem of no connection
No state A protocol has no memory for transactions , The server does not know what the client status is . That is, we send... To the server HTTP After the request , The server according to the request , Will send us data , however , Finished sending , No information will be recorded . Can pass Cookie and Session To make up for this problem .
HTTP Request method of
HTTP 1.0 There are three request methods , Namely :
(1)GET: Request the specified page information , And return the entity body .
(2)HEAD: Be similar to get request , But there is no specific content in the response returned , For getting headers
(3)POST: Submit data to the specified resource for processing request ( For example, submit a form or upload a file ). Data is contained in the request body .POST Requests may lead to the creation of new resources and / Or modification of existing resources .
HTTP 1.1 Five new request methods are added in :
(1)OPTIONS: Allow clients to view the performance of the server ;
(2)PUT: The data transmitted from the client to the server replaces the content of the specified document ;
(3)DELETE: Request the server to delete the specified page ;
(4)TRACE: Echo requests received by server , Mainly used for testing or diagnosis ;
(5)CONNECT:HTTP/1.1 The protocol is reserved for the proxy server that can change the connection to pipeline mode .
get and post The difference between :
- GET The submitted data will be placed in URL after .POST Put it in Body in .
- GET There is a limit to the size of the data submitted (URL Length limit ).POST There is no limit to .
- GET Submitting data in this way will bring security problems , For example, the user name and password appear in URL in . Pages are cached or accessed by others on this machine , The user's account and password can be obtained from the history .
HTTP Long and short connections of
stay HTTP/1.0 Short connection is used by default in . in other words , Client and server every time HTTP operation , Just one connection , Disconnect at end of task . When a client browser accesses HTML Or other types Web The page contains other Web resources ( Such as JavaScript file 、 image file 、CSS Documents, etc. ), Every time I meet such a Web resources , The browser will recreate a HTTP conversation .
And from HTTP/1.1 rise , Use long connection by default , To maintain connection characteristics . Using long connected HTTP agreement , This line will be added to the response header :
Connection:keep-aliveWith long connections , When a web page is opened , Transport between client and server HTTP Data TCP Connection will not close , When the client accesses this server again , Will continue to use this established connection .Keep-Alive Not permanently connected , It has a hold time , Different server software is available ( Such as Apache) Set this time in . To realize long connection, both client and server need to support long connection .
HTTP Long connection and short connection of protocol , Is essentially TCP Long connection and short connection of protocol .
HTTP1.0 HTTP1.1 HTTP2.0 The difference between
1991 year HTTP/0.9 Support only GET request , Request header is not supported
1996 year HTTP/1.0 Default short connection ( One request, one suggestion TCP Connect , Disconnect after request ), Support GET、POST、 HEAD request
1999 year HTTP/1.1 Default long connection ( once TCP Connections can be requested multiple times ); Support PUT、DELETE Wait for five requests
increase host head , Support virtual host ; Support breakpoint resume function
2015 year HTTP/2.0 Multiplexing , Reduce overhead ( once TCP The connection can handle multiple requests );
Server active push ( All related resources are pushed by one request );
Parsing is based on binary , Fewer parsing errors , More efficient (HTTP/1.X Parsing is based on text );
Header compression , Reduce overhead .
HTTP 0.9 :
(1)、 We only accept GET A request method , No version number specified in communication , The request header is not supported ;
(2)、 In addition, this version does not support POST Method , So the client can't pass too much information to the server ;
HTTP 1.0:(1)、 Support POST、GET、HEAD Three methods ;
(2)、 Only a short connection between the browser and the server is required , Every request from the browser needs to have a... With the server TCP Connect , The server disconnects as soon as it finishes processing the request TCP Connect , The server doesn't track every client and doesn't log past requests ;
HTTP 1.1:(1)、 Five new request methods :PUT、DELETE、CONNECT、TRACE、OPTIONS;
(2)、HTTP 1.1 stay Request There is one more in the message header Host Domain , Convenient for one WEB The server can be on the same IP Create multiple virtual machines with different host names on the address and port number WEB Site ;
(3)、 stay HTTP/1.1 Added in 24 Status response codes :
100-199 Used to specify some actions that the client should take .
200-299 Used to indicate that the request was successful .
300-399 Used for files that have been moved and are often included in the location header information to specify new address information .
400-499 Used to indicate client errors .
500-599 Used to support server errors .
SSL The process of establishing a connection :
- SSL The process of establishing a connection ( Use symmetric encryption to encrypt the transmitted information , Because symmetric encryption is faster ; Use asymmetric encryption to encrypt the transmitted key , Because it's safer )
- The client initiates a connection to the server , Send your supported encryption suite to the server .
- After receiving the message, the server selects an encryption algorithm and HASH Algorithm , At the same time, the certificate is also sent to the client ( The certificate contains the public key )
- After receiving the certificate, the client verifies the validity of the certificate , If it's legal , Then a symmetric key is generated and encrypted with the public key of the certificate and sent to the server .[ The generated symmetric key is used for the transmission encryption of the following information , The process of encrypting the content of the generated symmetric key with the public key and then transmitting it is actually the process of transmitting the content of the key with asymmetric encryption ]
- The server decrypts with the private key after receiving , Take out the symmetric encryption key . So far, the handshake is complete , Later, the ciphertext began to be transmitted
SSL Why should the handshake process use asymmetric secret keys ?
HTTPS Request process :( once HTTPS The request has to be made twice HTTP transmission )
1. Client issue https request , Request the server to establish SSL Connect ;
2. Server received https request , Apply for or make your own digital certificate , Get the public key and the private key of the server , And send the public key to the client ;
3. The client verifies the public key , If the verification fails, a warning will be issued , A random client private key is generated after verification ;
4. The client encrypts the public key and the client private key symmetrically and then transmits them to the server ;
5. After the server receives the encrypted content , Asymmetric decryption through the private key of the server , Get the client private key ;
6. The server encrypts the client private key and content symmetrically , And send the encrypted content to the client ;
7. After the client receives the encrypted content , Symmetric decryption through the client private key , Get the content .
Two-way authentication SSL The specific process of the agreement
① The browser sends a connection request to the security server .
② The server will have its own certificate , And the certificate related information is sent to the client's browser .
③ The client browser checks whether the certificate sent by the server is trusted by itself CA Issued by the center . If it is , Just carry on with the agreement ; If not , The client browser will give the customer a warning message : Warn the customer that this certificate is not trustworthy , Ask the customer if they need to continue .
④ Then the client browser compares the message in the certificate , For example, domain name and public key , Is it consistent with the relevant message just sent by the server , If it's consistent , The client browser recognizes the legitimate identity of the server .
⑤ The server asks the client to send the client's own certificate . After receipt of , The server verifies the client's certificate , If it doesn't pass the verification , Connection refused ; If it passes the verification , The server gets the user's public key .
⑥ The client browser tells the server what communication symmetric cryptography it can support .
⑦ The server sends the password scheme from the client , Choose a password scheme with the highest encryption level , Notify the browser after encrypting with the client's public key .
⑧ Browser for this password scheme , Select a call key , Then use the public key of the server to encrypt and send it to the server .
⑨ The server receives a message from the browser , Decrypt with your own private key , Get a call key .
⑩ The server 、 The next communication of the browser is a symmetric cipher scheme , Symmetric keys are over encrypted .
HTTP Request and response formats :
HTTP The request consists of three parts , Namely :
(1) Request line :
(2) The message header ;
(3) Request body .
HTTP The response consists of four parts , Namely :
(1) Status line ;
(2) The message header ;
(3) Blank line ;
(4) Response Content ;
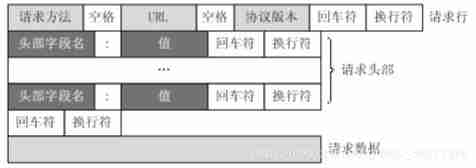

HTTP Common head :
Request Header:
- GET /sample.Jsp HTTP/1.1 // Request line
Host: www.uuid.online/ // The target domain name and port number of the request
- Origin: http://localhost:8081/ // The source domain name and port number of the request ( When cross domain requests , The browser will automatically bring this header )
Referer: https:/localhost:8081/link?query=xxxxx // Request the integrity of the resource URI
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36 // Browser information
Cookie: BAIDUID=FA89F036:FG=1; BD_HOME=1; sugstore=0 // Under the current domain name Cookie
Accept: text/html,image/apng // Represents the type of data the client wants to accept html Or is it png Picture type
Accept-Encoding: gzip, deflate // On behalf of the client can support gzip and deflate Compression of format
Accept-Language: zh-CN,zh;q=0.9 // On behalf of the client can support language zh-CN perhaps zh( It is worth mentioning that q(0~1) Priority weight means priority weight , Do not write default is 1, here zh-CN yes 1,zh yes 0.9)
Connection: keep-alive // Tell the server , The client needs tcp A connection is a long connection
Response Header:
- HTTP/1.1 200 OK // Response status line
- Date: Mon, 30 Jul 2018 02:50:55 GMT // Server time when the server sends resources
- Expires: Wed, 31 Dec 1969 23:59:59 GMT // A more outdated way to verify the cache , With browser ( client ) Time comparison of , Beyond that time, you don't need to cache ( Do not verify with the server ), Suitable for stable version of the web page
- Cache-Control: no-cache // Now the most used way to control caching , Cache verification with the server , Specific view post ”Cache-Control“
etag: "fb8ba2f80b1d324bb997cbe188f28187-ssl-df" // It's usually Nginx Static servers Static file signature sent , Browse in no “Disabled cache” Under the circumstances , Received etag after , The same url The second request will automatically bring “If-None-Match”
- Last-Modified: Fri, 27 Jul 2018 11:04:55 GMT // It is the last modification time of the current resource sent by the server , On next request , If the modification time of the current resource on the server is greater than this time , Just go back to the new resource content
- Content-Type: text/html; charset=utf-8 // If the return is streaming data , We have to tell the browser this header , Otherwise the browser will download the page , And tell the browser it's utf8 code , Otherwise, there may be garbled code
- Content-Encoding: gzip // Tell the client , Should adopt gzip Decoding resources
- Connection: keep-alive // Tell the client server tcp Connection is also a long connection
HTTP Commonly used in the head cache-control
Cache-Control The fields are http General header field in the message , It exists in the request message , It also exists in the response message . Some field values are common , But the specific treatment will also be different .
The caching of web pages is done by HTTP In the header “Cache-control” Controlled
stay Cache-Control in , These values can be combined freely , If multiple values conflict , It also has priority , and no-store The highest priority .
max-age:( We only accept Age Less than max-age value , And there are no expired objects )
max-stale:( Can accept the object of the past , But the expiration time must be less than max-stale value )
min-fresh:( Accept that its new life span is greater than its current Age Follow min-fresh The cache object of the sum of values )
Respond to :public( It can be used Cached Content responds to any user )
private( Only the user who previously requested the content can respond with cached content )
no-cache( Can be cached , But only with WEB After the server has verified its validity , To return to the client )
max-age:( The expiration time of the object included in this response )
ALL: no-store( Caching is not allowed )The default is private. Its function is divided into the following situations according to different ways of browsing :
(1) Open a new window
If specified cache-control The value of is private、no-cache、must-revalidate, Then when you open a new window to access, you will visit the server again . And if you specify max-age value , Then the server will not be accessed again within this value , for example :
Cache-control: max-age=5
After visiting this page 5 Second access will not go to the server
(2) Enter in the address bar
If the value is private or must-revalidate( It is different from what is said on the Internet ), Only the first access will access the server , No more visits in the future . If the value is no-cache, So every time I visit . If the value is max-age, It will not be accessed again until it expires .
(3) Press the back button
If the value is private、must-revalidate、max-age, It won't revisit , And if for no-cache, Then repeat every time
(4) Press the refresh button
Whatever it is worth , They will visit again and again

HTTP The cache of : Cache control and cache verification
Cache control : Switch to control cache , Used to identify whether the cache is enabled in the request or access , What kind of caching method is used .
Cache verification : How to verify the cache , For example, how to define the validity period of the cache , How to ensure that the cache is up-to-date .
- The cache switch is : pragma, cache-control.
- Cache verification has :Expires,Last-Modified,etag.
Cache control :
Pragma
Pragma There are two fields Pragma and Expires.Pragma The value of is no-cache when , Indicates that caching is disabled ,Expires The value of is a GMT Time , Indicates the effective time of the cache .
Pragma It's an old product , Have gradually abandoned , Some websites keep these two fields for downward compatibility . If a message appears at the same time Pragma and Cache-Control when , With Pragma Subject to . At the same time Cache-Control and Expires when , With Cache-Control Subject to . namely Priority from high to low yes Pragma -> Cache-Control -> Expires
Cache verification :
In the cache , We need a mechanism to verify that the cache is valid . For example, the resources of the server have been updated , The client needs to refresh the cache in time ; Or the client's resources are expired , But the resources on the server are still old , There is no need to resend . Cache verification is used to solve these problems , stay http 1.1 in , We mainly focus on Last-Modified and etag These two fields .
Last-Modified
When the server returns resources , The last change time of this resource will pass Last-Modified Field returned to client . The next time the client requests, it passes If-Modified-Since perhaps If-Unmodified-Since close Last-Modified, The server checks whether the time is consistent with the last modification time of the server : If the same , Then return to 304 Status code , Do not return resources ; If not, return 200 And modified resources , And bring new time .
If-Modified-Since and If-Unmodified-Since Is the difference between the :
If-Modified-Since: Tell the server if the time is consistent , Return status code 304
If-Unmodified-Since: Tell the server if the time is inconsistent , Return status code 412etag
It is still flawed to judge simply by the modification time , For example, the last modification time of the file has changed , But the content didn't change . In such a case , We can use etag To deal with it .
etag It's like this : The server computes resources through an algorithm , Get a string of values ( Like a document md5 value ), Then pass the value through etag Return to the client , The next time the client requests, it passes If-None-Match or If-Match Take the value , The server compares and verifies the value : Do not return resources if they are consistent .
If-None-Match and If-Match Is the difference between the :
If-None-Match: Tell the server if it is consistent , Return status code 304, Inconsistent return resource
If-Match: Tell the server if it's inconsistent , Return status code 412
DNS What is the basic process of querying the server (DNS Analytic process )?DNS What is Hijacking ?
DNS Hijacking occurs when the domain name resolves to IP Address time , Is parsed as wrong IP Address
HTTP Hijacking is DNS Resolved domain name IP The address remains the same . Hijacking your request in the process of interacting with the website . The request is returned to you before the website sends you the information .
HTTP The status code


TCP Of keepalive Understand? ? Tell me about it and HTTP Of keep-alive The difference between ?
HTTP Medium is keep-alive,TCP Medium is keepalive,HTTP The middle is marked with a middle line . Case doesn't matter .
http keep-alive And tcp keepalive, It's not the same thing , Different intentions .http keep-alive It's to make tcp Live longer , So that multiple... Can be transmitted on the same connection http, Improve socket The efficiency of . and tcp keepalive yes TCP A test for TCP The preservation mechanism of connection status .
Every http All requests require opening a tpc socket Connect , And disconnect this after using it once tcp Connect .
Use keep-alive Can improve this state , Once TCP Multiple data can be sent continuously during the connection without disconnection . By using keep-alive Mechanism , Can reduce the tcp Number of connection establishment , It also means that we can reduce TIME_WAIT Status connection , In order to improve performance and improve httpd Server throughput .keepalive yes TCP Fresh timer , When both sides of the network are established TCP After the connection , idle idle( There is no data flow between the two parties ) 了 tcp_keepalive_time after , The server kernel then attempts to send the detection package to the client , To judge TCP Connection status ( There is a possibility that the client will crash 、 Forced the application to close 、 Host unavailable etc ). If no response is received (ack package ), Will be in tcp_keepalive_intvl Then try again to send the detection packet , Until I get a message from the other side ack, If you have not received the other side ack, I will try tcp_keepalive_probes Time , The time between each one is here 15s, 30s, 45s, 60s, 75s. If you try to tcp_keepalive_probes, Still haven't received from the other side ack package , Will discard that TCP Connect .TCP Connection default idle time is 2 Hours , Generally set as 30 Enough minutes .
summary :
1、TCP Connections are often long connections in our broad sense , Because it has the ability to send and receive messages continuously at both ends ; Open the keep-alive Of HTTP Connect , It's also a long connection , But it is limited by the agreement itself , The server cannot initiate the application message .
2、TCP Medium keepalive It's used to keep fresh 、 Keep alive ;HTTP Medium keep-alive The mechanism is mainly for the support of TCP Connections live longer , So it is usually called :HTTP persistent connection( Persistent connection ) and HTTP connection reuse( Connection reuse ).
From input URL To show the whole process of the page
- First step : Browser input domain name
- For example, the input :csdn.net/
- The second step : The browser looks up the domain name IP Address , The browser will resolve the entered domain name into the corresponding IP, The process is as follows :
- Find the browser cache : Because browsers usually cache DNS Record a period of time , Time may vary from browser to browser , commonly 2-30 Different minutes , Browser to find these caches , If you have a cache , Go straight back to IP, Otherwise, the next step .
- Find the system cache : Cannot find... In browser cache IP after , The browser will make system calls (windows Medium is gethostbyname), Find local hosts file , If you find , Go straight back to IP, Otherwise, the next step .
- Find router cache : If 1,2 Every step of the query failed , You need to use the network , Routers generally have their own DNS cache , Send the previous request to the router , lookup ISP Service providers cache DNS Server for , If I find IP Then return directly , If not, keep looking .
- recursive query : If the above steps cannot be found , be ISP Of DNS The server will make a recursive query , The so-called recursive query is if the local domain name server queried by the host does not know the name of the queried domain name IP Address , Then the local domain name server uses DNS The identity of the customer , Continue to send query request message to other root domain servers , Instead of letting the host do the next query .( The local domain name server address is through DHPC Protocol get address ,DHPC Is responsible for the distribution of IP Address of the )
- Iterative query : Local domain name server adopts iterative query , It first queries a root domain name server . The query from the local domain name server to the root domain name server generally adopts iterative query . The so-called iterative query is when the root domain name server receives the query request message sent by the local domain name server , Or tell the local domain name server which domain name server to query next , Then the local domain name server performs subsequent queries .( Instead of replacing the local domain name server for subsequent queries ).
- In this case : Root domain name server tells local domain name server , The next top-level domain name server to query net Of IP Address . Local domain name server to top-level domain name server dns.net The query . Top-level domain server dns.net Tell local domain name server , The domain name server that should be queried next time dns.csdn.net Of IP Address . The local domain name server to the permission domain name server dns.csdn.net The query . Domain name server dns.csdn.net Tell local domain name server , Host queried www.csdn.net Of IP Address . The local domain name server finally tells the host .
- The third step : Browser and target server set up TCP Connect
- The host browser passes DNS The target server's IP After the address , Build with server TCP Connect .
- TCP3 Handshake connection : The client where the browser is located sends a connection request message to the server (SYN Mark is 1); After the server receives the message , Agree to establish a connection , Send a confirmation message to the client (SYN,ACK The flags are 1); After the client receives the confirmation message , Send a message to the server again , Confirm that the confirmation message has been received ; Here is the connection between the client and the server TCP Connection established , Start communicating .
- Step four : Browser pass http Protocol send request
- The browser sends a message to the host HTTP-GET Method message request . The request contains the URL, That is to say http://www.csdn.com/ ,KeepAlive, A long connection , also User-Agent User browser operating system information , Coding, etc . It is worth mentioning that Accep-Encoding and Cookies term .Accept-Encoding It is generally used gzip, Transmit after compression html file .Cookies If this is the first visit , The server will be prompted to create user cache information , If not , You can use Cookies Corresponding key value , Find the corresponding cache , The user name is stored in the cache , Passwords and some user settings .
- Step five : Some services will respond to permanent redirection
- There are multiple host sites for large websites , Load balancing or import traffic , Improve SEO ranking , Often not directly back to the request page , It's redirection . The status code returned is not 200OK, It is 301,302 With 3 Redirection code at the beginning , After the browser gets the redirect response , In response message Location Item found redirect address , The browser can be accessed in the first step .
- The role of redirection : Redirection is for load balancing or import traffic , Improve SEO ranking . Use a front-end server to accept requests , Then load it on different hosts , It can greatly improve the business concurrent processing ability of the site ; Redirection can also access multiple domain names , Concentrate on one site ; because com,www.baidu.com Will be considered two websites by search engines , As a result, the number of links per will be reduced, reducing the ranking , Permanent redirection will associate the two addresses , Search engines will think of the same website , So as to improve the ranking .
- Step six : Browser tracking redirect address
- When the browser knows the final access address after resetting , Resend a http request , Same as above .
- Step seven : Server processing request
- The server received a get request , Then process and return a response .
- Step eight : The server sends a message HTML Respond to
- Return status code 200 OK, Indicates that the server can respond to requests , Return message , Because in the headlines Content-type by “text/html”, Browser to HTML In form , Instead of downloading files .
- Step nine : Release TCP Connect
- The host of the browser sends a connection release message to the server , Then stop sending data ;
- The server sends a confirmation message after receiving the release message , Then send the unfinished data on the server ;
- After the server data transmission is completed , Send connection release message to client ;
- After the client receives the message , Send a confirmation , Then wait for a while , Release TCP Connect ;
- Step 10 : The browser displays the page
- The browser does not fully accept all HTML When the document , It's already showing this page , The browser received the returned packet , Render the corresponding data according to the rendering mechanism of the browser . Rendered data , Carry out corresponding page rendering and footstep interaction .
- Step 11 : Browser send get embedded in HTML Other content in
- For example, some style files , picture url,js file url etc. , The browser will go through these url Resend request , The request process is still HTML Read a similar process , Query domain name , Send a request , Redirect etc. . However, these static files can be cached in the browser , Sometimes access to these files does not require a server , Directly from the cache . Some websites also use third parties CDN To host these static files .
sketch JWT Principle and verification mechanism of
Briefly describe what is XSS Attack and CSRF attack ?
XSS(Cross Site Script, Cross-site scripting attacks ) It is an attack way to inject malicious script into the web page to execute malicious script in the user's browser when the user is browsing the web page .
There are two forms of cross site script attack : Reflex attack ( Entice users to click on a link embedded in a malicious script to achieve the target of the attack , At present, there are many attackers using the Forum 、 Microblog post contains malicious script URL It belongs to this way ) and Persistent attack ( Submit the malicious script to the database of the attacked website , When users browse the web , Malicious scripts are loaded from the database into the page for execution ,QQ Earlier versions of mailboxes were used as platforms for persistent cross site scripting attacks ).
resolvent : disinfect ( Escape dangerous characters ) and HttpOnly( To guard against XSS The attacker stole Cookie data ).
CSRF attack (Cross Site Request Forgery, Cross-site request forgery ) It's the attacker who requests , Illegal operation as a legal user ( Such as transfer or posting ).
CSRF The principle is to use the browser Cookie Or the server Session, Stealing user identity .
resolvent :(1) Add token to form (token);(2) Verification Code ;(3) Check... In the request header Referer( As mentioned earlier, anti image theft links are also used in this way ).
SQL Inject : When the server uses request parameters to construct SQL When the sentence is , Malicious SQL Embedded in SQL In the database execution .
To guard against SQL Injection attacks can also be used The way of disinfection , Through regular expressions Verify the request parameters , Besides , Parameter binding It is also a good means , Such a malicious SQL Will be regarded as SQL Instead of the command being executed ,
(2)OSI Seven layer model 、TCP/IP Five floors 、 Four layer model
| OSI Seven layer model | describe | data format | agreement | TCP/IP Five layer model | equipment | TCP/IP Four layer model | agreement | describe |
|---|---|---|---|---|---|---|---|---|
| application layer | Serving applications | HTTP、FTP、TFTP、Telnet、DNS、SMTP | application layer | application layer | DNS、HTTP、WWW、FTP、TFTP、SMTP、Telnet、Usenet | |||
| The presentation layer | Data format conversion 、 Data encryption | JPEG、ASCII、GIF | ||||||
| The session layer | establish 、 Manage and maintain sessions | SQL | ||||||
| Transport layer | establish 、 Manage and maintain end-to-end connections | Data segment | TCP、UDP | Transport layer | Four layer router 、 Four layer switch | Transport layer | TCP、UDP | Provide end-to-end communication |
| The network layer | IP Location and routing | Data packets | IP、ICMP、RIP、IGMP | The network layer | Router 、 Three layer switch | Internetwork layer | ICMP、IP、RIP | Responsible for data packaging 、 Addressing and routing |
| Data link layer | Provides media access and link management | Ethernet frame | ARP、RARP、PPP、CSMA/CD、IEEE802.3 | Data link layer | bridge 、 Ethernet switch 、 network card | Network interface layer | ARP、RARP | Including for collaboration IP A protocol for the transmission of data over an existing network medium |
| The physical layer | The physical layer | Bit stream | EIA/TIA-232 | The physical layer | Repeater 、 A hub 、 Twisted pair |
OSI Advantages of hierarchical model :

4、 database
Transaction isolation level :
Isolation level Dirty reading (Dirty Read) It can't be read repeatedly Fantasy reading (Phantom Read) Uncommitted read (Read uncommitted) Probably Probably Probably Read committed (Read committed) impossible Probably Probably Repeatable (Repeatable read) impossible impossible Probably Serializable (Serializable ) impossible impossible impossible 01:Mysql The default isolation level for is : Repeatable :Repeatable read;
02:oracle In the database , Only support seralizable( Serialization ) Level and Read committed(); The default is Read committed Level ;
MyISAM and InnoDB The difference :
MyISAM Unsupported transaction ,InnoDB Support .MyISAM Row locks are not supported , Only table locks are supported ,InnoDB Support row lock .
InnoDB The specific number of rows is not saved , So when counting the rows, the whole table will be scanned ,MyISAM There is preservation .
myisam The index to the table name +.MYI Save the files separately .innodb Is stored in a table space with the data .
Innodb engine
Innodb The engine provides the database ACID Business Support for , And implemented SQL The standard four isolation levels , For information about database transactions and their isolation levels, see the article database transactions and their isolation levels . The engine also provides row level locks and foreign key constraints , It is designed to handle large capacity database systems , It's actually based on MySQL The complete database system in the background ,MySQL Runtime Innodb Buffer pool will be established in memory , For buffering data and indexes . But the engine doesn't support FULLTEXT Index of type , And it doesn't hold the number of rows in the table , When SELECT COUNT(*) FROM TABLE You need to scan the whole table . When you need to use database transactions , The engine is of course the first choice . Because of the smaller granularity of the lock , Write operations do not lock the entire table , So when concurrency is high , Use Innodb The engine will improve efficiency . But using row level locks is not absolute either , If you are executing a SQL When the sentence is MySQL Can't determine the range to scan ,InnoDB The watch also locks the whole watch .
MyIASM engine
MyIASM yes MySQL Default engine , But it doesn't provide support for database transactions , Row level locks and foreign keys are also not supported , So when INSERT( Insert ) or UPDATE( to update ) Write on data requires locking the entire table , It's less efficient . But and Innodb Different ,MyIASM The number of rows in the table is stored in , therefore SELECT COUNT(*) FROM TABLE Only the saved values need to be read directly without scanning the whole table . If the read operation of the table is far more than the write operation and does not need the support of database transaction , that MyIASM It's also a good choice .
Master slave copy :
Master slave copy , It is used to build a database environment exactly the same as the main database , Called from database ; The main database is generally a quasi real-time business database .
benefits :
1、 The extension of Architecture . More and more business ,I/O Access frequency is too high , A single machine can't satisfy , At this time, do multi library storage , Physical servers added , Increase in load .
2、 Read / write separation , Enable databases to support greater concurrency . The master and the slave are only responsible for their own writing and reading , A great deal of relief X Lock and S Lock contention . It's especially important in reports . Because part of the report sql The sentences are very slow , Cause the watch to lock , Affect front desk service . If the front desk uses master, Report use slave, Then report sql Will not cause front desk lock , Guaranteed the front desk speed .
3、 Do hot data backup , As a backup database , After the main database server fails , Switch to continue working from database , Avoid data loss .
principle :
1. The database has a bin-log Binary , It records everything sql sentence .
2. Our goal is to make the main database bin-log Of documents sql Copy the sentence .
3. Let it in from the data of relay-log Redo these in the log file again sql Sentence can be used .
4. The following master-slave configuration is based on this principle
5. Three threads are needed to operate :
1.binlog Output thread : Whenever there is a slave connection to the master , The main library will create a thread and send binlog Content to from library .
From the library , When replication begins , From the library, two threads will be created for processing :
2. Slave Library I/O Threads : When START SLAVE Statement is executed from the library , Create a... From the library I/O Threads , This thread connects to the main database and requests the main database to send binlog The update records in it are recorded on the slave database . Slave Library I/O The thread reads the main library binlog The output thread sends the updates and copies them to the local file , These include relay log file .
3. From library SQL Threads : Create a... From the library SQL Threads , This thread reads from the library I/O The thread writes relay log Update event and execute .
You can know , For each master-slave replication connection , There are three threads . The master database with multiple slave databases creates one for each slave database connected to the master database binlog Output thread , Each slave has its own I/O Threads and SQL Threads .
Optimism lock 、 Pessimistic locking
Optimism lock When operating a database ( update operation ), The idea is optimistic , Think this operation will not lead to conflict , When operating data , Without any other special treatment ( That is, no lock ), And after the update , To judge whether there is a conflict .
The common method is to add version Field , When updating, compare the first version Whether the value is the same as the current value , The same update , Different means the data is out of date .
Pessimistic locking : Pessimistic lock is when operating data , I think this operation will cause data conflict , So in each operation, we must obtain the lock to operate the same data , This is followed by java Medium synchronized Very similar , So pessimistic lock takes more time . In addition, the optimistic phase locking corresponds to , Pessimistic lock is implemented by the database itself , When it's time to use , We can directly call the relevant statements of the database .
Four characteristics of transaction (ACID):
Uniformity 、 Atomicity 、 Isolation, 、 persistence
The difference between process and thread
Process is the smallest unit of resource allocation , A thread is the smallest unit of program execution ;
The process has its own address space , Every time a process is started , The system will allocate address space to it , Create data tables to maintain code snippets 、 Stack and data segments , Threads have no independent address space , It uses the same address space to share data ;
CPU Switching a thread costs less than switching a process ;
Creating a thread costs less than a process ;
The resources occupied by threads should be ⽐ The process is much less .
5、Linux
Kill process kill
stay Linux/unix Next , Abort a Java There are two ways to process , One is kill -9 pid, One is kill -15 pill( Default ).
SIGNKILL(9) The effect is to kill the process immediately . The signal Can't be blocked , Handling and ignoring .
SIGNTERM(15) The effect is Normal exit process , Before exiting, you can be Blocking or callback processing . And it's Linux default Program interrupt signal ( The default is 15).
6、Java
Two 、 Fundamentals of testing
3、 ... and 、 Algorithm problem
1、 Valid brackets
Given a string containing only three characters :( ,) and *, Write a function to check whether the string is a valid string . Valid strings have the following rules :
- Any left parenthesis ( There must be a corresponding closing bracket ).
- Any closing parenthesis ) There must be a corresponding left parenthesis ( .
- Left parenthesis ( Must precede the corresponding closing bracket ).
- * Can be treated as a single right parenthesis ) , Or a single left parenthesis ( , Or an empty string .
- An empty string is also considered a valid string .
import java.util.*;
public class Solution {
/**
*
* @param s string character string
* @return bool Boolean type
*/
public boolean checkValidString (String s) {
// write code here
if (s.length() == 0 || s == null)
return true;
int left = 0;
int right = 0;
for (int i = 0; i < s.length(); i++){
left += (s.charAt(i) == ')' ? -1 : 1);
right += (s.charAt(s.length()-1-i) == '(' ? -1 : 1);
if (left < 0 || right < 0)
return false;
}
return true;
}
}
2、 Joseph Ring problem
https://blog.csdn.net/github_38571976/article/details/107958784?spm=1001.2014.3001.5502
边栏推荐
- Hosting service and SASE, enjoy the integration of network and security | phase I review
- 2021-09-30
- [普通物理] 光栅衍射
- [suggested collection] time series prediction application and paper summary
- 情绪识别AI竟「心怀鬼胎」,微软决定封杀它!
- It is said that Tencent officially announced the establishment of "XR" department to bet on yuanuniverse; Former CEO of Google: the United States is about to lose the chip competition. We should let T
- 消息称腾讯正式宣布成立“XR”部门,押注元宇宙;谷歌前 CEO:美国即将输掉芯片竞争,要让台积电、三星建更多工厂...
- 浅谈MySql update会锁定哪些范围的数据
- 顺序表的基本操作
- Set up your own website (14)
猜你喜欢

微信小程序自定义tabBar

VMware virtual machine setting static IP

Haitai Advanced Technology | application of privacy computing technology in medical data protection
 [email protected] -Perfmon metric collector listener steps"/>
[email protected] -Perfmon metric collector listener steps"/>JMeter installation plug-in, adding [email protected] -Perfmon metric collector listener steps

I feel that I am bald again when I help my children with their homework. I feel pity for my parents all over the world

Memo mode - game archiving

大一女生废话编程爆火!懂不懂编程的看完都拴Q了

红象云腾完成与龙蜥操作系统兼容适配,产品运行稳定

使用gorm查询数据库时reflect: reflect.flag.mustBeAssignable using unaddressable value
Bridging mode -- law firm
随机推荐
Image panr
The AI for emotion recognition was "harbouring evil intentions", and Microsoft decided to block it!
Visitor model -- generation gap between young and middle-aged people
Steps of JMeter performance test
Otaku can't save yuan universe
JMeter response assertion
Learn together and make progress together. Welcome to exchange
微信小程序中使用vant组件
It is said that Tencent officially announced the establishment of "XR" department to bet on yuanuniverse; Former CEO of Google: the United States is about to lose the chip competition. We should let T
图像PANR
Intermediary model -- collaboration among departments
I just purchased a MySQL database and prompted that there are already instances. The console login instance needs to provide a database account. How do I know the database account.
Selenium crawl notes
顺序栈1.0版本
maptalks:数据归一化处理与分层设色图层加载
微信小程序自定义tabBar
VMware virtual machine setting static IP
Responsibility chain mode -- through interview
Apple, Microsoft and Google will no longer fight each other. They will work together to do a big thing this year
Undo log and redo log must be clear this time