当前位置:网站首页>Spark - LeftOuterJoin 结果条数与左表条数不一致
Spark - LeftOuterJoin 结果条数与左表条数不一致
2022-06-24 07:07:00 【BIT_666】
一.引言
使用 spark lefOuterJoin 寻找下发的 gap,用原始下发 rdd 左join 真实下发后发现最终的结果数与左表不一致,左表数据: 20350,最终数据: 25721。一直以来使用 Hive 都是默认 leftJoin 左表应该与结果一致,所以开始排查。
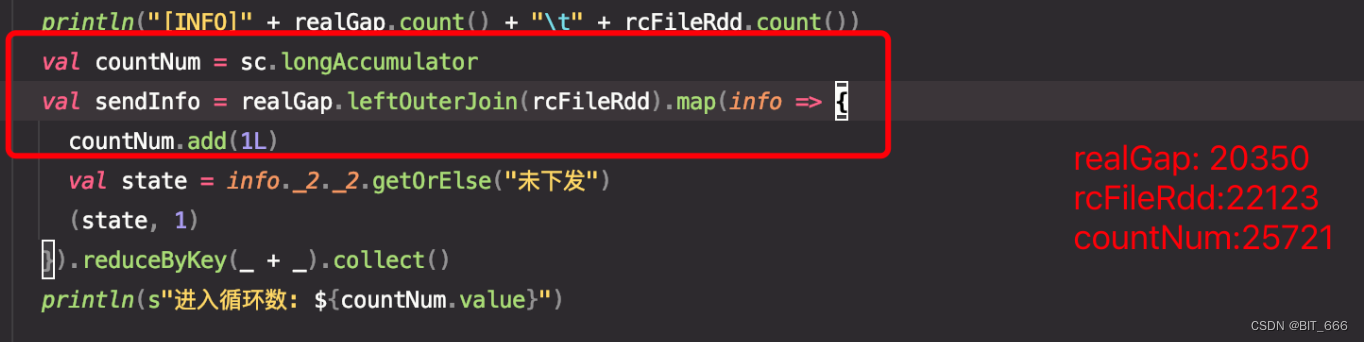
二.问题排查
20350 条变成 25721 条数据,所以大概率是出现了同 key 的情况,分别检查两边的数据,发现左表、右表均有相同的下发记录,所以导致最终进入循环的数目 countNum 超过了左表的行数,为了避免之后再遇到这样的问题,下面遍历下常见的情况,先初始化一个 SaprkContext 并添加 3对 pairRdd,其中 rddA,rddC 存在重复 key,rddB 无重复 key:
val conf = new SparkConf().setAppName("TestLefterJoin").setMaster("local[5]")
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("error")
val rddA = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "6")))
val rddB = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5")))
val rddC = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "7")))1.左表 key 有重复
rddA.leftOuterJoin(rddB).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})左表 (A,1),(A,6) 重复,二者分别与右表的 (A, 1) 匹配,所以分别得到 (A, 1, 1) 和 (A, 6, 1) ,如果右表没有 "A" 的 key,匹配结果是 (A, 1, NULL) 与 (A, 6, NULL)
(B,2,2)
(D,4,4)
(E,5,5)
(A,1,1)
(C,3,3)
(A,6,1)结论:左表有重复 left join 后结果与左表行数一致
2.右表 key 有重复
rddB.leftOuterJoin(rddA).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})将上述 rddA 与 rddB 对调得到右表有重复的结果,(A, 1) 分别有右表 (A, 1) 与 (A, 6) 匹配得到 (A, 1, 1) 与 (A, 1, 6),结果一对多
(A,1,1)
(C,3,3)
(E,5,5)
(B,2,2)
(D,4,4)
(A,1,6)结论:右表有重复 left join 后结果与左表行数不一致,增加行数为右表重复 key 的数 - 1
3.左右表 key 都有重复
rddA.leftOuterJoin(rddC).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})左表 (A,1) 、(A,6) 与右表 (A,1)、(A,7) 直接得到 2x2 四种匹配,比左表多2条数据
(B,2,2)
(C,3,3)
(E,5,5)
(A,1,1)
(D,4,4)
(A,1,7)
(A,6,1)
(A,6,7)结论:左右表有重复 left join 后结果与左表行数不一致, 增加行数为右表重复 key 的数目
4.左表 key 有 null 且重复
val rddANull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "6"), (null, "7"), (null, "8")))
val rddBNull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5")))
rddANull.leftOuterJoin(rddBNull).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})左表的 (null, 7) , (null, 8) 会把 null 当做单独的 key 匹配,所以不影响
(B,2,2)
(E,5,5)
(null,7,NULL)
(C,3,3)
(A,1,1)
(A,6,1)
(D,4,4)结论:左表有重复 null key 不影响 left join 与行数
5.右表 key 有 null 且重复
val rddANull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "6"), (null, "7"), (null, "8")))
val rddCNull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "7"), (null, "8")))
rddCNull.leftOuterJoin(rddANull).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})左表 (null, 8) 与右表 (null,7)、(null,8) 匹配得到两条记录。
(B,2,2)
(C,3,3)
(D,4,4)
(E,5,5)
(null,8,7)
(null,8,8)
(A,1,1)
(A,1,6)
(A,7,1)
(A,7,6)结论:右表有重复 null key 影响 left join 行数,增加数目为右表重复 key 数 - 1
6.左右表都有重复 null key
val rddANull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "6"), (null, "7"), (null, "8")))
rddANull.leftOuterJoin(rddANull).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})两边都有 (null,7)、(null,8) ,和上面正常 key 左右表重复结果相同,多2条记录
(B,2,2)
(D,4,4)
(E,5,5)
(null,7,7)
(null,7,8)
(null,8,7)
(null,8,8)
(A,1,1)
(A,1,6)
(A,6,1)
(A,6,6)
(C,3,3)结论:左右均重复 null key 时影响 left join 行数,其中增加行数为重复 null key的数
Tips:
经过上面3次试验可以看到 null 作为 pairRdd 的 key 在进行 join 时和正常的 key join 时是一样的,唯一的区别是处理这类型的 key 时需要注意非 null 的判断,否则容易报错
7.表中包含纯 null
val rddDNull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "6"), (null, "9"), (null, "10")))
val rddENull = sc.parallelize(Array(("A", "1"), ("B", "2"), ("C", "3"), ("D", "4"), ("E", "5"), ("A", "6"), null))
rddENull.leftOuterJoin(rddDNull).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})
rddDNull.leftOuterJoin(rddENull).foreach(info => {
println(info._1, info._2._1, info._2._2.getOrElse("NULL"))
})不管是左表有纯 null 还是右表有纯 null 或者都有 null,都会报错 NullPoint:

结论:pairRdd 中有纯 null 使用 join 会报错
三.问题修复
上面遍历了重复和 null 的问题,主要导致左join与左表条数不一致的原因还是右表重复key导致,所以问题修复主要是去重:
A.distinct
直接对 rdd 全局去重,但是只能去除相同的 (key, value)
B.groupByKey
将 (key, value1)、(key, value2) .... 相同 key 的 pairRdd 元素聚合
上述两种方法是 PairRdd 常用的去重方法,不过怎么去重还需要结合业务场景,如果确实是相同的多余日志则使用 distinct,如果确实有重复日志且需要聚合信息则采用 groupByKey 、reduceByKey 等聚合方式,当然如果左右表都有重复且场景确需,正常 join 即可。
四.总结
这里 spark pairRdd leftJoin 可能增加结果的行数,使用 spark DataFrame 使用 join 时:
val sqlContext = new SQLContext(sc)
documentDFA.join(documentDFB).select("xxx").where("xxx")
使用 select + where 得到的结果不一定会大于等于左表行数。再回看一下引言的数据,左表数据: 20350,最终数据: 25721,共增加了 5371 行,如果右表单独重复 Xi 个 key,每个 key 重复数目 Mi 个,左右表共重复 Yi 个 key,每个 key 重复数目 Ni 个,按照上面的公式应该满足:

边栏推荐
猜你喜欢

表单图片上传在Chorme中无法查看请求体的二进制图片信息

Telnet port login method with user name for liunx server
The form image uploaded in chorme cannot view the binary image information of the request body

“论解不了数独所以选择做个数独游戏这件事”

every()、map()、forEarch()方法。数组里面有对象的情况

【MySQL从入门到精通】【高级篇】(一)字符集的修改与底层原理

Pymysql inserts data into MySQL and reports an error for no reason

一文讲透,商业智能BI未来发展趋势如何

Wan Weiwei, a researcher from Osaka University, Japan, introduced the rapid integration method and application of robot based on WRS system
![打印出来的对象是[object object],解决方法](/img/fc/9199e26b827a1c6304fcd250f2301e.png)
打印出来的对象是[object object],解决方法
随机推荐
Earthly container image construction tool -- the road to dream
IDEA另起一行快捷键
教程篇(5.0) 08. Fortinet安全架构集成与FortiXDR * FortiEDR * Fortinet 网络安全专家 NSE 5
Liunx Mysql安装
Telnet port login method with user name for liunx server
【NOI模拟赛】寄(树形DP)
【团队管理】测试团队绩效管理的25点小建议
2022.06.23(LC_144,94,145_二叉树的前序、中序、后序遍历)
Pymysql inserts data into MySQL and reports an error for no reason
xargs使用技巧 —— 筑梦之路
input的聚焦后的边框问题
pm2 部署 nuxt3.js 项目
[pytoch basic tutorial 31] youtubednn model analysis
为什么ping不通,而traceroute却可以通
剑指 Offer 55 - I. 二叉树的深度-dfs法
2138. 将字符串拆分为若干长度为 k 的组
2021-05-20computed和watch应用与区别
基于QingCloud的地理信息企业研发云解决方案
表单图片上传在Chorme中无法查看请求体的二进制图片信息
MySQL 因字符集问题插入中文数据时提示代码 :1366